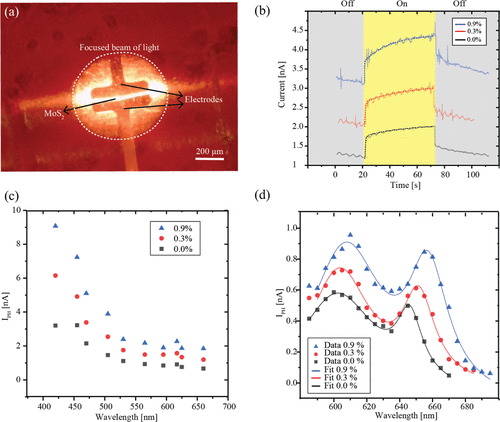
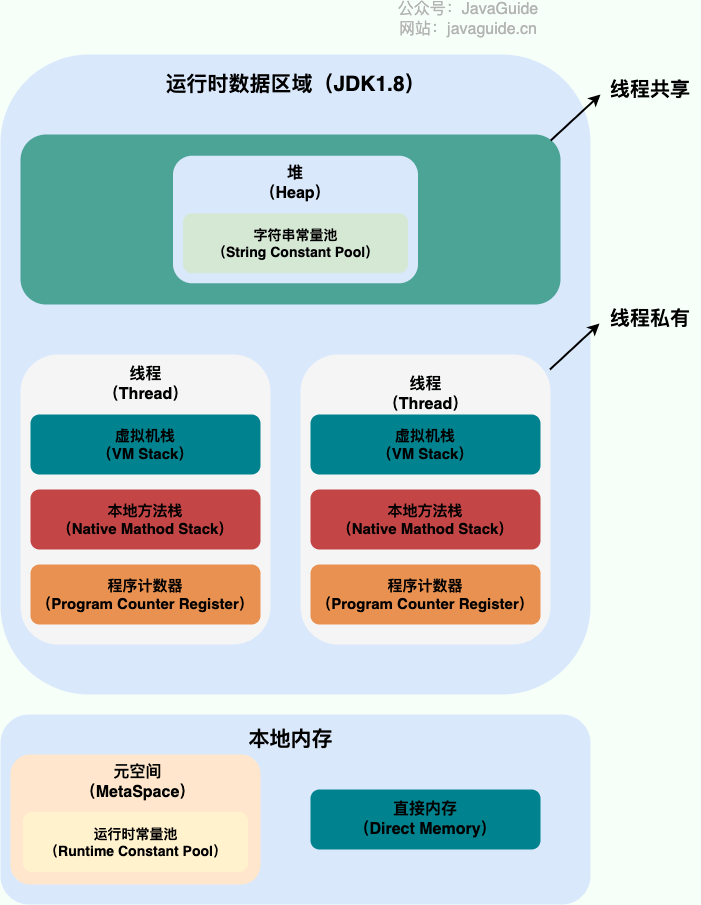
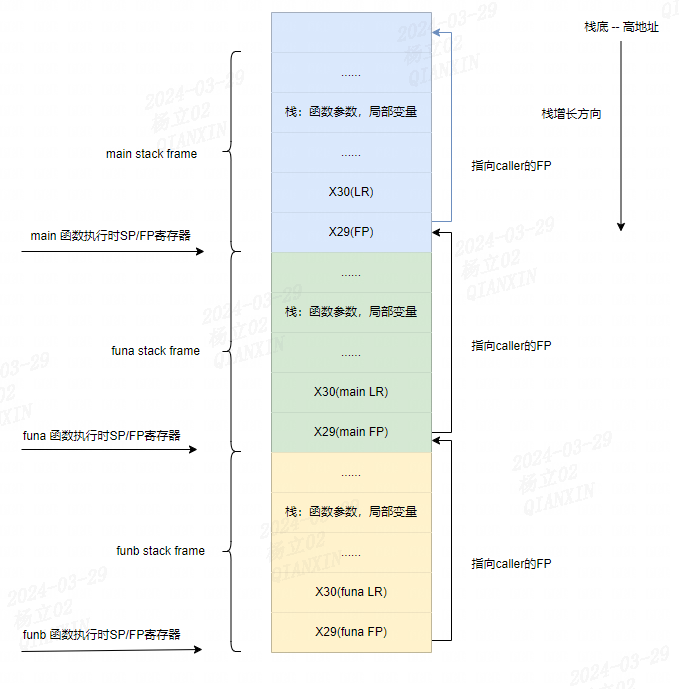
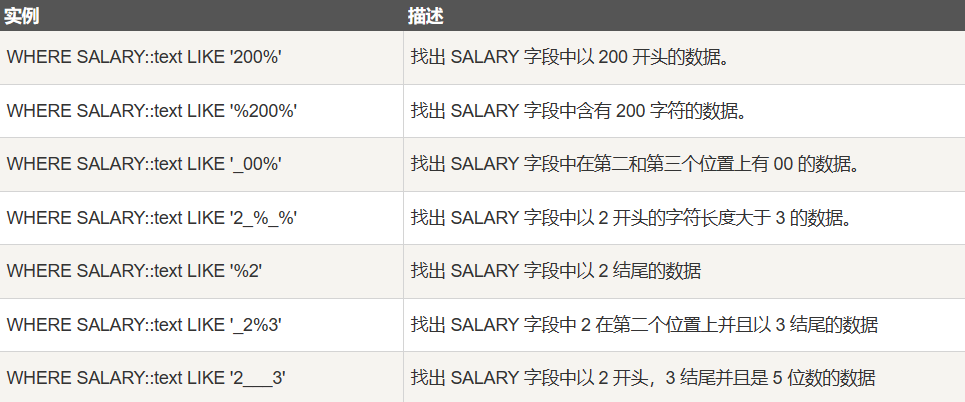
正则表达式中的量词有以下几种:
1. *: 匹配前面的字符0次或多次。
2. +: 匹配前面的字符1次或多次。
3.?: 匹配前面的字符0次或1次。
4. {n}: 匹配前面的字符恰好n次。
5. {n,}: 匹配前面的字符至少n次。
6. {n,m}:匹配前面的字符至少n次,但不超过m次。
以下是使用Python的re模块进行正则表达式匹配的示例代码:
*: 匹配前面的字符0次或多次。(代码演示)

+: 匹配前面的字符1次或多次。(代码演示)

{n}: 匹配前面的字符恰好n次。

{n,}: 匹配前面的字符至少n次。

{n,m}:匹配前面的字符至少n次,但不超过m次

这些段代码中,我们使用了正则表达式中的量词。然后,我们调用re.findall()函数来查找所有匹配的子串,并将结果存储在变量result中。最后,我们打印出结果。
量词是正则表达式中非常有用且强大的工具,可以帮助准确定位和捕获各种文本模式,从而实现更精确的匹配和提取。
加油💪哦熟练掌握它,让你做事事半功一倍二倍。
以上的相关应用可以通过小蜜蜂AI的GPT问答获取更多的示例。网址:https://zglg.work。
(文章对你有用的话。记得点赞➕在看哦😯分享知识也是一种美德)
如有学习上的困惑或问题欢迎评论区留言告诉我们,让我们一起解决共同进步: