Zookeeper实现分布式锁
创建临时顺序节点执行create -e -s /znode即可实现分布式锁。
zk中锁的分类
- 读锁(读锁共享):大家都可以读。上锁前提:之前的锁没有写锁
- 写锁(写锁排他):只有得到写锁的才能写。上锁前提:之前没有任何锁
zk的读锁
- 创建一个临时序号节点,节点的数据是read,表示是读锁
- 获取当前zk中序号比自己小的所有节点
- 判断最小节点是否是读锁
- 如果不是读锁的话,则上锁失败,为最小节点设置监听。阻塞等待,zk的watch机制会当最小节点发生变化时通知当前节点,再执行第二步的流程
- 如果是读锁的话,则上锁成功。
zk的写锁
- 创建一个临时序号节点,节点的数据是write,表示写锁
- 获取zk中所有的子节点
- 判断自己是否是最小的节点:
- 如果是,则上写锁成功
- 如果不是,说明前面还有锁,则上锁失败,监听最小节点,如果最小节点有变化,则再执行第二步。
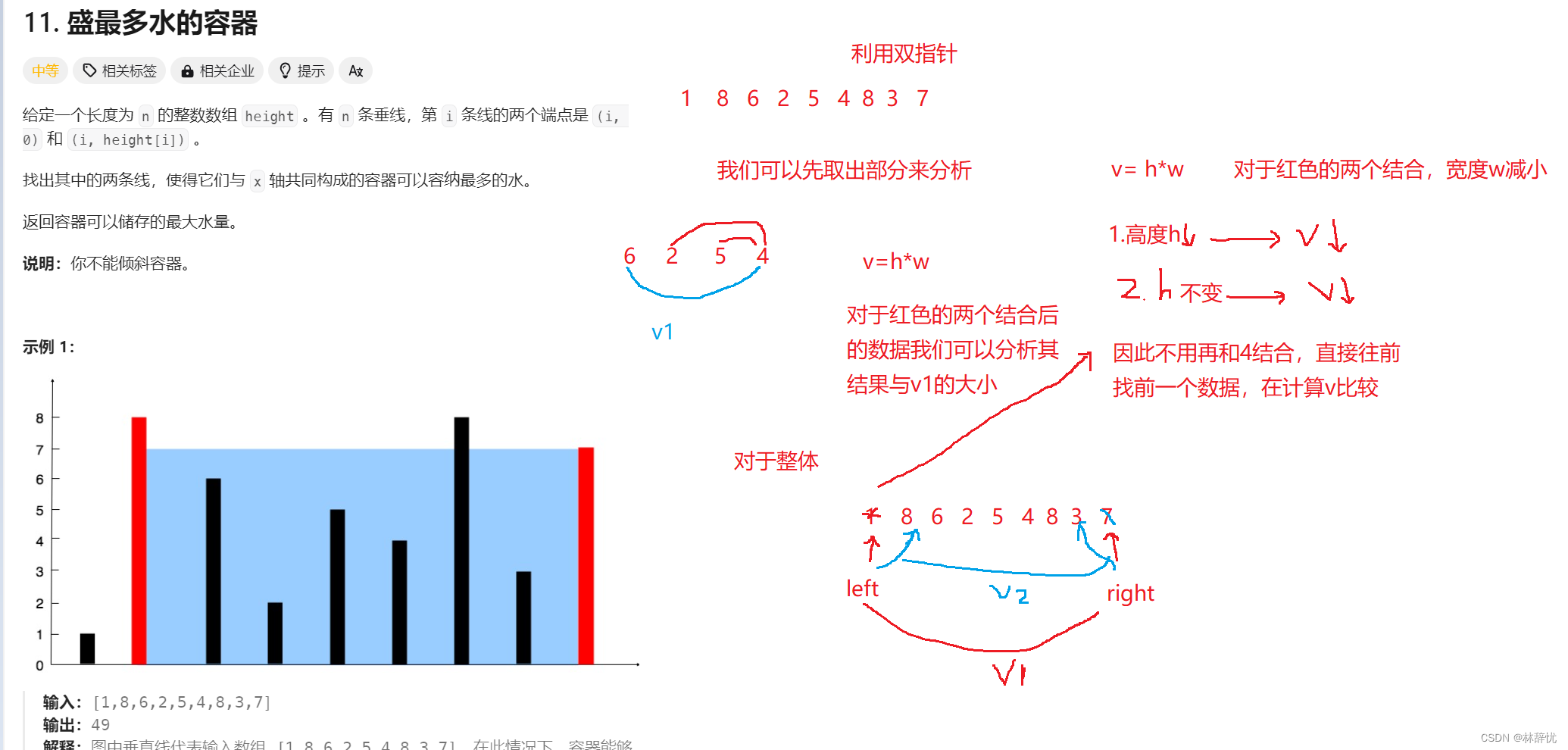
羊群效应
如果有大量的节点都想实现写锁,且最小节点已经实现了锁,那么会有大量节点监听zk中的最小节点,会造成大量节点的并发访问,对zk的压力非常大–羊群效应。
解决方法:将上述的获取写锁的方式,调整为链式监听。
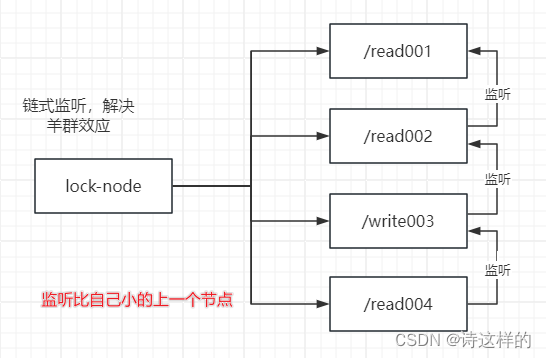
有点类似于 juc 里的写锁获取的方式
Zookeeper中的Watch机制
使用 get -w /znode 参数,可以监听一次 znode 节点的变化,类似于把 Watch注册成了znode 的触发器。当调用create,delete或set时,会触发 znode 上的注册的对应事件,请求 Watch 的客户端就会收到异步通知。
只能监听到当前节点的变化,不能监听到当前节点的子节点的变化
客户端使用了 NIO 通信模式监听服务的调用。
Watch机制的特点
-
一次性
无论是服务端还是客户端,一旦一个 Watcher 被 触 发 ,Zookeeper 都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力 -
轻量
- Watcher 通知只会告诉客户端发生了事件变化,而不会说明事件的具体内容。
- 客户端向服务端注册 Watcher 的时候,并不会把客户端真实的 Watcher 对象实体传递到服务端,仅仅是在客户端请求中使用 boolean 类型属性进行了标记。
-
异步
Watch 机制被触发后,另一端异步的发送事件的变化。由于网络延迟或其他因素导致客户端在不同的时刻监听到事件变化,zookeeper只能保证最终的一致性,而无法保证强一致性。