简述
以下全部代码无法完美对图片、表格等非文字形式的内容转化。要较好的效果需要使用光学字符分析等方法进行转化
我懒,不想将代码模块拆分出来写注释
除代码1中有详细注释外,剩下的代码仅在关键部分进行注释
代码1:小规模文件的转换
代码简介
不使用线程,挨个文件转换格式。
适用于小规模的PDF文件批量转换。
需要自己选择PDF文件(可以全选文件,自动筛选PDF格式)
代码内容
import os, sys # 导入操作系统接口和系统相关的参数和函数
from pdf2docx import Converter # 导入pdf2docx库中的Converter类,用于将PDF文件转换为docx格式
import tkinter as tk # 导入Tkinter库,用于创建图形用户界面
from tkinter import filedialog # 导入Tkinter库中的filedialog模块,用于打开文件对话框
# 定义一个函数,用于将PDF文件转换为docx格式
def convert_pdf_to_docx(file_path):
if os.path.splitext(file_path)[1] == '.pdf': # 检查文件的扩展名是否为.pdf
pdf_filename = os.path.basename(file_path) # 从file_path中提取出文件名(不含路径)
word_name = os.path.splitext(pdf_filename)[0] + ".docx" # 创建新的文件名,将.docx作为扩展名
cv = Converter(pdf_filename) # 创建一个Converter对象,用于转换文件
cv.convert(word_name) # 调用convert方法,将PDF文件转换为docx格式,并将转换后的文件保存为word_name
cv.close() # 关闭转换器对象
print(f"**{pdf_filename}**处理完成") # 打印转换完成的信息
# 创建一个Tkinter窗口,但不显示它
root = tk.Tk()
root.withdraw()
# 使用filedialog模块打开一个文件选择对话框,允许用户选择多个文件
file_paths = filedialog.askopenfilenames(title="选择需要处理的文件")
if len(file_paths) == 0: # 如果没有选择文件,退出程序
sys.exit()
else:
print("待处理文件:") # 打印提示信息
for file_path in file_paths: # 遍历所有选择的文件路径
print(" ", file_path) # 打印每个文件的路径
# 遍历所有选择的文件路径,并调用convert_pdf_to_docx函数进行转换
for file_path in file_paths:
convert_pdf_to_docx(file_path)
print("全部PDF转换完成") # 打印所有PDF文件转换完成的信息功能的执行
选择需要转换的文件
选择你需要转换的文件,可以直接全选
一次只能转换一个文件夹中的全部文件,无法进入到该文件夹的次级文件夹中
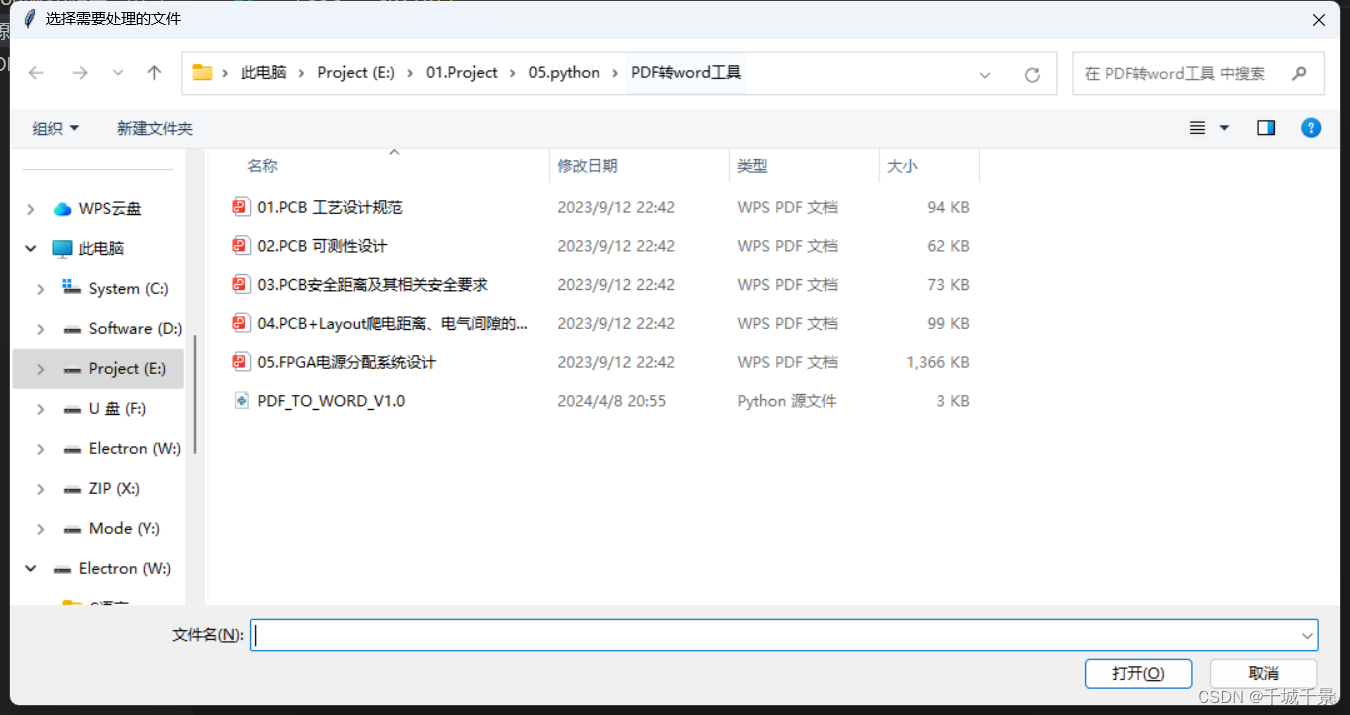
开始转换文件
请注意终端信息窗口,会提示转换进度
转换完成
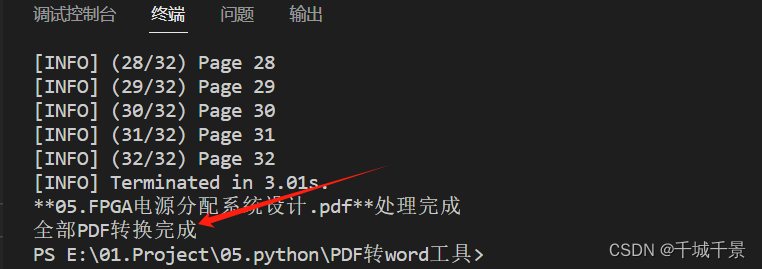
转换效果:

代码2:较大规模文件的转换
更新功能
1.使用多线程模式,一个文件一条线程的转换文件
2.增加时间计算,统计转换文件需要多少时间,方便后继继续优化提高转换速度
详细代码
import os
import sys
from pdf2docx import Converter
import tkinter as tk
from tkinter import filedialog
import threading
import time
# 定义一个函数,用于将PDF文件转换为docx格式
def convert_pdf_to_docx(file_path):
try:
if os.path.splitext(file_path)[1] == '.pdf':
#pdf_filename = os.path.basename(file_path)
#word_name = os.path.splitext(pdf_filename)[0] + ".docx"
cv = Converter(file_path)
cv.convert(os.path.splitext(os.path.basename(file_path))[0] + ".docx")
cv.close()
except Exception as e:
print(f"转换 {os.path.basename(file_path)} 时发生错误: {e}")
# 创建一个Tkinter窗口,但不显示它
root = tk.Tk()
root.withdraw()
# 使用filedialog模块打开一个文件选择对话框,允许用户选择多个文件
file_paths = filedialog.askopenfilenames(title="选择需要处理的文件")
if not file_paths:
sys.exit("没有选择文件,操作取消。")
# 打印待处理的文件
print("待处理文件:")
for file_path in file_paths:
print(" ", file_path)
# 创建一个线程列表用于存储所有的转换线程
threads = []
# 遍历所有选择的文件路径,并创建转换线程
for file_path in file_paths:
thread = threading.Thread(target=convert_pdf_to_docx, args=(file_path,))
threads.append(thread)
# 记录开始时间
start_time = time.time()
# 启动所有的转换线程
for thread in threads:
thread.start()
# 等待所有的转换线程完成
for thread in threads:
time.sleep(0.1)# 暂停程序1毫秒
thread.join()
# 记录结束时间
end_time = time.time()
# 计算并打印转换完成所需的总时间
total_time = end_time - start_time
print(f"所有文件转换完成,总共耗时: {total_time:.2f} 秒。")代码3:超大规模文件的转换
功能的更新
1.引入线程池,控制程序消耗的系统资源
详细代码
import os
import logging
from tkinter import Tk, filedialog
from concurrent.futures import ThreadPoolExecutor, as_completed
from pdf2docx import Converter
# 配置日志格式和级别
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
# 定义一个函数来处理单个PDF文件的转换
def process_pdf_file(pdf_path):
try:
pdf_dir = os.path.dirname(pdf_path)
file_name = os.path.splitext(os.path.basename(pdf_path))[0]
docx_path = os.path.join(pdf_dir, f"{file_name}.docx")
# 转换PDF到Word
cv = Converter(pdf_path)
cv.convert(docx_path, start=0, end=None)
cv.close()
# 记录文件保存的信息
logging.info(f"Converted file saved to {docx_path}")
except Exception as e:
# 如果发生错误,记录错误信息而不是转换成功信息
logging.error(f"Error processing file {pdf_path}: {e}")
# 创建主窗口
root = Tk()
root.withdraw() # 隐藏主界面
# 选择PDF文件
pdf_paths = filedialog.askopenfilenames(title="选择PDF文件", filetypes=[("PDF files", "*.pdf")])
if pdf_paths:
# 创建一个线程池,限制线程数量为CPU核心数
with ThreadPoolExecutor(max_workers=os.cpu_count()*2) as executor:
# 将任务提交到线程池
futures = [executor.submit(process_pdf_file, pdf_path) for pdf_path in pdf_paths]
# 使用as_completed迭代器等待所有任务完成
for future in as_completed(futures):
future.result()
if future.exception() is not None:
logging.error(f"An error occurred: {future.exception()}")
else:
logging.info(f"File processed successfully: {future.result()}")
# 所有文件处理完成后,关闭窗口并退出程序
root.destroy()
else:
logging.info("没有选择PDF文件。")代码4:超快速PDF文件转换
功能更新
只转换文字,对任何图片表格会出现问题
详细代码
import os
import logging
from tkinter import Tk, filedialog
from concurrent.futures import ThreadPoolExecutor, as_completed
import fitz # PyMuPDF
# 配置日志格式和级别
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
# 定义一个函数来处理单个PDF文件的转换
def process_pdf_file(pdf_path):
try:
pdf_dir = os.path.dirname(pdf_path)
file_name = os.path.splitext(os.path.basename(pdf_path))[0]
docx_path = os.path.join(pdf_dir, f"{file_name}.docx")
# 使用PyMuPDF读取PDF内容
pdf = fitz.open(pdf_path)
text = ""
for page in pdf:
text += page.get_text()
pdf.close()
# 将文本写入Word文档(这里需要一个将文本转换为docx格式的函数)
with open(docx_path, 'w', encoding='utf-8') as f:
f.write(text)
# 记录文件保存的信息
logging.info(f"Converted file saved to {docx_path}")
except Exception as e:
# 如果发生错误,记录错误信息而不是转换成功信息
logging.error(f"Error processing file {pdf_path}: {e}")
# 创建主窗口
root = Tk()
root.withdraw() # 隐藏主窗口
# 选择PDF文件
pdf_paths = filedialog.askopenfilenames(title="选择PDF文件", filetypes=[("PDF files", "*.pdf")])
if pdf_paths:
# 创建一个线程池
with ThreadPoolExecutor(max_workers=min(len(pdf_paths), os.cpu_count())) as executor:
# 将任务提交到线程池
futures = [executor.submit(process_pdf_file, pdf_path) for pdf_path in pdf_paths]
# 等待所有任务完成
for future in as_completed(futures):
future.result()
# 所有文件处理完成后,关闭窗口并退出程序
root.destroy()
else:
logging.info("没有选择PDF文件。")批量删除文件夹内的全部word:使用Python批量删除文件夹内的Word-CSDN博客
程序打包方式见我的这个文章:在Vscode中将python打包为exe,超级简单,还能自定义exe的logo_怎么将vscode编写的代码打包成exe-CSDN博客