原文链接:
BM25和语言模型的改进研究
摘要:
近期关于搜索引擎排名函数的研究报告指出,BM25和带Dirichlet平滑的语言模型有所改进。本研究通过在INEX 2009维基百科语料库上训练,然后在INEX 2010和9个TREC语料库上测试,比较了9种最新的排名函数(BM25、BM25+、BM25T、BM25-adpt、BM25L、 T F b δ o p × I D TF_{b\delta op \times ID} TFbδop×ID、LM-DS、LM-PYP和LM-PYP-TFIDF)。研究发现,一旦使用粒子群优化进行训练,这些函数的性能差异很小,反馈相关性有效,词干提取有效,但目前仍不清楚哪种函数总体上最佳。分类和主题描述:
H.3.3 [信息存储和检索]:信息搜索和检索 - 搜索过程。一般术语
算法、测量、性能、实验。关键词:
相关性排名、文档检索、拖延
1. 引言
自从搜索引擎诞生以来,其精确度已经有了显著提升。最初,这些改进难以量化,因为每个研究者都使用自己的文档集合。NIST通过引入TREC [4] 解决了许多早期问题。在TREC的检索实验中,所有参与者使用相同的文档和查询。参与者被要求为每个查询提交一个最相关文档的排名列表,即一个运行。NIST将每个运行的前n个结果汇总,并请信息专家评估哪些文档与哪些查询相关——这个过程称为池化评估。评估结果被用来使用标准度量衡量每个运行的性能。NIST提供了生成度量的软件,以及文档和查询,使得研究人员能够进行可重复的实验室实验,随后出现了其他评估论坛,如NTCIR [6]、INEX [3] 和 FIRE [14]。这些语料库继续被用来展示改进。
阿姆斯特朗等人 [1, 2] 表明,尽管研究仍在继续,但自20世纪90年代中期BM25 [23] 排序函数引入以来,没有证据表明排名有任何改进。特罗特曼和基尔 [28] 认为这是因为BM25在TREC语料库上的表现接近人类水平。
可以合理推测,商业搜索引擎的精确度仍在不断提高。但它们面临的问题不同。对于TREC的检索实验,实践者需要根据给定的文档和查询生成一个运行。相反,商业搜索引擎拥有查询日志、点击日志和用户档案。商业搜索引擎的查询特征与TREC截然不同。TREC的查询独特且具有代表性,而商业搜索引擎会看到重复的查询,并能针对每个查询进行优化。
商业和学术搜索引擎都会遇到新查询,并需要生成排名结果列表。这个列表可能成为进一步重新排序结果的管道输入,即结果重新排名。典型的重新排名可能由学习排名算法生成。在这个研究中,我们关注的是这个管道的第一阶段:给定文档和查询,生成结果的初始排名列表,即TREC运行。
TREC中看到的许多运行不仅仅是简单排名函数的结果,而是由其他过程(如词干提取、停止词处理、字段加权、反馈相关性等)组成的管道。我们没有实验涉及这种多样的可能性,因为穷举所有可能性是不可行的。我们的主要兴趣是选择一个默认的排名函数,期望它在任何地方都能表现良好,然后让实践者通过添加或不添加额外过滤器到管道中进行进一步调整。然而,我们对阿姆斯特朗等人的结果感兴趣,即我们问:
近年来,排名函数的精度是否有所提高?我们通过实现和测试一些声称改进BM25的最新排名函数来探讨这个问题。我们测试每个函数,加入相关反馈、词干提取和停用词,结果显示虽然对BM25的改进看似存在,但这些改进很小,目前还不清楚哪个排名函数总体上最优。
2. 实验条件
本研究旨在检验近年来信息检索中的改进情况。为了保证可复现性,实验使用了TREC和INEX提供的资源。
具体来说,我们使用INEX 2009的维基百科语料库进行训练,然后在INEX 2010语料库以及TREC 1-8上进行测试。查询通常使用主题标题,但在TREC 4中只有描述字段,因此我们使用了这些描述。
我们使用ATIRE搜索引擎[27]实现这些函数,其源代码是公开的,并且我们对其进行了扩展。我们将BM25作为比较基准。
我们使用平均未插值精确度(MAP)作为评估指标,结果列表中记录了1000个文档。通常在某个点会截断结果,但我们选择晚些截断,因为我们寻找的是任何改进的证据,而不仅仅是少数几个结果的证据。MAP定义为查询集中的每个查询的平均精确度的平均值,
M A P = ∑ q ∈ Q A P q Q MAP = \frac{{\sum}_{q \in Q}AP_{q}}{Q} MAP=Q∑q∈QAPq
其中
A P q = ∑ n = 1 L f q p Δ P q I q relevant N q AP_{q} = \frac{{\sum}_{n = 1}^L f_{q}^{p}}{\Delta P_{q}} \frac{I_{q}\text{ relevant}}{N_{q}} APq=ΔPq∑n=1LfqpNqIq relevant
N q r N_{qr} Nqr是查询 q q q的已知相关文档数量, L L L是结果列表的长度(最多1000), L n L_{n} Ln是结果列表中第 n n n个位置的文档, P q m P_{q^m} Pqm是该位置的精确度(在点 n n n找到的相关文档数除以 n n n)。
我们不针对特定系统做出声明,而是针对特定系统中的排名函数。因此,与TREC和INEX上见过的最佳成绩相比并不重要——但我们注意到INEX的参考运行使用了ATIRE的BM25、词干提取,但没有反馈和停用词。
3. BM25
BM25常被用作基准,我们在此也采用。问题在于,许多BM25的实现不同,比较的是类似BM25的函数。我们选择使用ATIRE版本的BM25作为基准。
3.1 ATIRE BM25
选择ATIRE版本的BM25是为了避免出现负数。其实现由Trotman等人[27]给出:
r s v q = ∑ r ≤ q log ( N d f i ) ⋅ ( k 1 + 1 ) ⋅ r f i d k 1 ⋅ ( 1 − b + b ⋅ . . . ⋅ ( L d L d a t a ) ) + t f s t rsv_{q} = \sum_{r \leq q} \log\left( \frac{N}{df_{i}} \right) \cdot \frac{(k_{1} + 1) \cdot rf_{id}}{k_{1} \cdot (1 - b + b \cdot ... \cdot (\frac{L_{d}}{L_{data}}))} + tf_{st} rsvq=r≤q∑log(dfiN)⋅k1⋅(1−b+b⋅...⋅(LdataLd))(k1+1)⋅rfid+tfst
对于给定的查询 q q q,检索状态值 r s v q rsv_{q} rsvq是单个术语 t t t的分数之和。 N N N是语料库中的文档数, d f t df_{t} dft是包含术语 t t t的文档数(文档频率), t f M tf_{M} tfM是文档 d d d中术语 t t t出现的次数。
L d L_{d} Ld 是文档的长度(以词计), L a v g L_{avg} Lavg 是文档平均长度。有两个调整参数: b b b 和 k 1 k_{1} k1。
这个公式与Robertson等人[22]的公式在几个方面有所不同。Robertson等人的函数中的 k 3 k_{3} k3成分考虑了查询中出现多次的术语,而这个函数假设查询中的每个术语都是唯一的。Robertson等人的函数中的 k 2 k_{2} k2参数考虑了查询长度,当他们设置 k 2 = 0 k_{2} = 0 k2=0时,与ATIRE的作者保持一致。
排名函数中最显著的差异在于IDF部分的改变。Robertson等人使用了Robertson-Sparck Jones的IDF:
I D F t = log N − d f t + 0.5 ( d f t + 0.5 ) IDF_{t} = \log\frac{N - df_{t} + 0.5}{( df_{t} + 0.5 )} IDFt=log(dft+0.5)N−dft+0.5
当 d f t > N / 2 df_{t} > N/2 dft>N/2时,这会产生负分值,而ATIRE使用了Robertson-Walker的IDF N d f t \frac{N}{df_{t}} dftN,当 d f t df_{t} dft接近 N N N时,它趋向于零。这种改变是直观的。如果整个集合根据 r s v q rsv_{q} rsvq进行排名,对于包含超过一半文档的术语的1个词查询,Robertson-Sparck Jones的IDF会将不包含该术语的文档排名高于包含的文档,而ATIRE函数始终认为包含该术语的文档比不包含的更相关。
ATIRE实现的BM25在多种场景中已被证明有效,且由独立作者[18]证实。
3.2 BM25L
Lv和Zhai[12]观察到,BM25的文档长度归一化 ( L d L a v g ) \left( \frac{L_{d}}{L_{avg}} \right) (LavgLd) 不公平地偏向于较短的文档。Singhal等人[26]早些时候针对余弦排名也提出了类似的观点。为了解决这个问题,Lv和Zhai在他们的BM25L函数中进行了处理,其推导如下:
他们从一个不允许负值的不同的BM25开始,仅在IDF部分有所不同:
r s v q = ∑ t ∈ q log ( N + 1 d f 2 + 0.5 ) ⋅ ( k 1 + 1 ) ⋅ f s f k 1 ( ( 1 − b ) + b ⋅ ( L d L d a t ) 1 ) + ϵ f s f d rsv_{q} = \sum_{t \in q} \log\left( \frac{N + 1}{df_{2} + 0.5} \right) \cdot \frac{( k_{1} + 1 ) \cdot f_{sf}}{k_{1}( (1 - b) + b \cdot \left( \frac{L_{d}}{L_{dat}} \right)_{1} ) + \epsilon_{f_{sfd}}} rsvq=t∈q∑log(df2+0.5N+1)⋅k1((1−b)+b⋅(LdatLd)1)+ϵfsfd(k1+1)⋅fsf
他们重新排列得到:
r s v q = ∑ i ∈ q log ( N + 1 d f 2 + 0.5 ) ⋅ ( k 1 + 1 ) ⋅ c i d k 1 + c i d rsv_{q} = \sum_{i \in q} \log\left( \frac{N + 1}{df_{2} + 0.5} \right) \cdot \frac{( k_{1} + 1 ) \cdot c_{id}}{k_{1} + c_{id}} rsvq=i∈q∑log(df2+0.5N+1)⋅k1+cid(k1+1)⋅cid
其中:
c t d = t f t d 1 − b + b ⋅ ( L t d L a p g ) c_{td} = \frac{tf_{td}}{1 - b + b \cdot \left( \frac{L_{td}}{L_{apg}} \right)} ctd=1−b+b⋅(LapgLtd)tftd
这是本节讨论的其他函数中常见的重新排列。
对于BM25L,Lv和Zhai关注影响这个 c M c_{M} cM组件,以避免过度惩罚长文档。他们通过添加一个正常数 δ \delta δ来实现这一点。这使得函数更倾向于小数值(即大的分母,等效于大的 L d L_{d} Ld值或长文档)。
他们的最终公式,BM25L,给出如下:
r s v q = ∑ t ∈ q log ( N + 1 d f t + 0.5 ) ⋅ ( k 1 + 1 ) ⋅ ( c t d + δ ) k 1 + ( c t d + δ ) rsv_{q} = \sum_{t \in q} \log\left( \frac{N + 1}{df_{t} + 0.5} \right) \cdot \frac{( k_{1} + 1 ) \cdot ( c_{td} + \delta )}{k_{1} + ( c_{td} + \delta )} rsvq=t∈q∑log(dft+0.5N+1)⋅k1+(ctd+δ)(k1+1)⋅(ctd+δ)
他们展示了BM25L在包括GOV2、WT10G、WT2G、Robust04和TREC-8在内的多个TREC集合上优于BM25。
对于 δ \delta δ的最佳值,他们在所有实验中都得到了0.5。
3.3 BM25+
Lv和Zhai在后续的研究中指出,长文档的惩罚不仅限于BM25,其他排名函数也会出现类似问题。他们提出了一种通用解决方案,即对单个词项出现的贡献下限。无论文档多长,一个搜索词的单次出现至少会对检索状态值贡献一个常数。
他们与BM25L的处理方式不同,他们在乘以IDF(他们也进行了调整)之前,先将 δ 加到 t f f d tf_{fd} tffd 部分。
他们使用TREC GOV2、WT100g、WT2G和Robust04集合,展示了BM25+在所有情况下都优于BM25。他们建议,δ 值为1在各个集合中都有效。
3.4 BM25-adpt
在关于BM25的不同工作中,Lv和Zhai注意到全局的 k l k_{l} kl 可能不如针对每个词项的 k l k_{l} kl 有效,并试图直接从索引中识别出词项特定的 k l k_{l} kl 值。这使得他们的排名函数能够在不同集合间转移,无需重新训练。
他们运用信息增益和随机性理论来解决这个问题。从至少看到一次词项出现的概率,给定0次或更多次出现和查询开始:
p ( 1 ∣ 0 , q ) = d f r + 0.5 N + 1 p(1 | 0, q) = \frac{df_{r} + 0.5}{N + 1} p(1∣0,q)=N+1dfr+0.5
然后他们推导出看到一次额外出现的概率:
p ( r + 1 ∣ r , q ) = d f r + 1 + 0.5 d f r + 1 p(r + 1 | r, q) = \frac{df_{r + 1} + 0.5}{df_{r} + 1} p(r+1∣r,q)=dfr+1dfr+1+0.5
在函数的任何点上,信息增益可以通过从 r r r 次出现到 r + 1 r + 1 r+1 次出现的变化,减去初始概率来计算:
G q r = log 2 ( d f r + 1 + 0.5 d f r + 1 ) − log 2 ( d f r + 0.5 N + 1 ) G_{q}^{r} = \log_{2}\left( \frac{df_{r + 1} + 0.5}{df_{r} + 1} \right) - \log_{2}\left( \frac{df_{r} + 0.5}{N + 1} \right) Gqr=log2(dfr+1dfr+1+0.5)−log2(N+1dfr+0.5)
对于 d f r df_{r} dfr,他们不使用词频 t f t d tf_{td} tftd,而是基于长度归一化后的词频定义。具体来说,他们定义 d f r df_{r} dfr 如下:
d f r = { ∣ D t i o , g e r − a s ∣ r > 1 ∣ D t i o , g e r − a s ∣ N r = 0 df_{r} = \left\{\begin{matrix} \left| D_{tio,ger - as} \right| & r > 1 \\ \frac{\left| D_{tio,ger - as} \right|}{N} & r = 0 \end{matrix} \right. dfr={∣Dtio,ger−as∣N∣Dtio,ger−as∣r>1r=0
即对于基础情况 r = 0 r = 0 r=0,使用集合中的文档数;当 r = 1 r = 1 r=1 时,使用文档频率;对于其他情况, ∣ D t ∣ c t , d ≥ r − 0.5 ∣ \left| D_{t | c_{t,d} \geq r - 0.5} \right| Dt∣ct,d≥r−0.5 ,即包含词项 t t t 且长度归一化词频 c M c_{M} cM 大于 r r r(四舍五入后)的文档数,记为 ∣ D t ∣ \left| D_{t} \right| ∣Dt∣。
为了计算 k l k_{l} kl,他们将信息增益函数与BM25得分函数对齐,然后求解 k k k,得到词项特定的 k 1 ′ k_{1}^{\prime} k1′:
k 1 ′ = argmin k 1 ∑ i = 0 T ( G 0 r G d 2 − ( k 1 + 1 ) ⋅ r k 1 + r ) 2 k_{1}^{\prime} = \mathop{\operatorname{argmin}}\limits_{{k_{1}}}{\sum}_{i = 0}^T{\left( \frac{G_{0}^{r}}{G_{d}^{2}} - \frac{\left( k_{1} + 1 \right) \cdot r}{k_{1} + r} \right)}^{2} k1′=k1argmin∑i=0T(Gd2G0r−k1+r(k1+1)⋅r)2
他们可以从索引中完全计算 k 1 ′ k_{1}^{\prime} k1′,因为所有参数都在其中,但他们建议预先计算这些值并存储在索引中,每个词项一个。
最后,将 k 1 ′ k_{1}^{\prime} k1′ 代入 BM25 的词频项,并用 G q 1 G_{q}^{1} Gq1 替换 IDF 值:
ran q = ∑ i ∈ q G q 1 ⋅ ( k 1 ′ + 1 ) ⋅ f p q k 1 ′ ⋅ ( ( 1 − b ) + b ⋅ ( L d L d + p β ) ) + ϵ f p q t {\operatorname{ran}}_{q} = \sum_{i \in q}G_{q}^{1} \cdot \frac{(k_{1}^{{\prime}} + 1) \cdot f_{pq}}{k_{1}^{{\prime}} \cdot ((1 - b) + b \cdot (\frac{L_{d}}{L_{d + p_{\beta}}})) + \epsilon_{f_{pq}t}} ranq=i∈q∑Gq1⋅k1′⋅((1−b)+b⋅(Ld+pβLd))+ϵfpqt(k1′+1)⋅fpq
吕 & 赵在 TREC-8、WT10g 和 WT2g 上测试了这个函数,结果表明它优于 BM25。
3.5 BM25T
吕 & 赵稍后在 [13] 中提出了一种计算术语特定 k l k_{l} kl 参数的对数-逻辑方法,仍然直接从索引中得出。他们首先定义了一个术语的精英集 C n C_{n} Cn,即包含该术语的所有文档集合。在该集合中,他们建议长度归一化后的词频贡献应与具有更高长度归一化词频贡献的文档比例成正比。然后,他们使用对数矩估计方法来估计术语特定的 k 1 , k 1 ′ k_{1},k_{1}^{{\prime}} k1,k1′,如下:
k 1 ′ = arg min k 1 ( g x 2 − ∑ D ∈ C ω log ( c t d ) + 1 d f t ) 2 k_{1}^{{\prime}} = \arg\min_{k_{1}} \left( g_{x_{2}} - \frac{\sum_{D \in C_{\omega}}\log(c_{td}) + 1}{df_{t}} \right)^{2} k1′=argk1min(gx2−dft∑D∈Cωlog(ctd)+1)2
其中 c b d c_{bd} cbd 如方程
(7) 所定义, g k 1 g_{k_{1}} gk1 定义为:
g k z = { k 1 if log ( k 1 ) ≠ 1 k 1 − 1 otherwise g_{k_{z}} = \begin{cases} k_{1} & \text{if } \log(k_{1}) \neq 1 \\ k_{1} - 1 & \text{ otherwise} \end{cases} gkz={k1k1−1if log(k1)=1 otherwise
他们使用牛顿-拉弗森法求解此 k 1 ′ k_{1}^{{\prime}} k1′,然后将其代入方程 (5) 中,得到 BM25T。他们认为,当文档频率较小时,这种估计 k 1 k_{1} k1 的方法可能不稳定。为解决这个问题,他们引入了 BM25C,它使用所有查询中看到的所有术语的平均 k 1 ′ k_{1}^{{\prime}} k1′(这在实际中是未知的),以及 BM25Q,它使用当前查询中所有术语的平均 k 1 ′ k_{1}^{{\prime}} k1′。
在 WT2G、WT10G、AP 和 Robust04 的测试中,这些函数表现优于 BM25。然而,哪种最好尚不清楚。在这个研究中,我们尝试了 BM25T,即 3.6 倍的 T F l ⋅ 8 − p × I D F TF_{l \cdot 8 - p} \times IDF TFl⋅8−p×IDF。
Rousseau & Vazirgiannis [25] 建议,为了模型在文档中观察到一个术语额外出现的非线性增益,应使用对数函数:
T F l − t d = 1 + ln ( 1 + ln ( t f t d ) ) TF_{l - td} = 1 + \ln(1 + \ln(tf_{td})) TFl−td=1+ln(1+ln(tftd))
遵循 BM25+ 的做法,他们添加了 δ 以确保 0 次和 1 次出现之间有足够的间隙。他们称之为 TFs:
T F δ − t d = t f t d + δ TF_{\delta - td} = tf_{td} + \delta TFδ−td=tftd+δ
对于文档长度归一化,他们更喜欢 BM25 中的分母部分,即方程 (7) 中的项,他们称之为 T F p TF_{p} TFp:
KaTeX parse error: Undefined control sequence: \* at position 39: …d}}{1 - b + b_{\̲*̲} \left( \frac{…
使用它们的组合规则,得到结合了 T F I {\mathrm{TF}}_{\mathrm{I}} TFI、 T F δ {\mathrm{TF}}_{\mathrm{\delta}} TFδ和 T F P {\mathrm{TF}}_{\mathrm{P}} TFP 的 T F i ⋄ P {\mathrm{TF}}i{{\diamond}}_{\mathrm{P}} TFi⋄P,定义为:
最后,加入逆文档频率(IDF)成分,他们使用的是:
I D F t = log N + 1 d f t IDF_{t} = \log\frac{N + 1}{df_{t}} IDFt=logdftN+1
我们假设使用自然对数,因此得到 T F F δ p × I D F {\mathrm{TF}}_{\mathrm{F}\delta\mathrm{p}} \times \mathrm{IDF} TFFδp×IDF的表达式为:
res = ∑ i ≠ j ln N + 1 d f i { 1 + ln ( 1 + ln ( r i , j 1 − b + b + s ^ ) ⋃ k = r i , j k − b ) ) } \operatorname{res} = {\sum}_{i \neq j}\ln\frac{N + 1}{df_{i}}\left\{1 + \ln\left( 1 + \ln\left( \frac{r_{i,j}}{1 - b + b} + \widehat{s}){\bigcup}_{k = r_{i,j}}^{k - b} \right) \right) \right\} res=∑i=jlndfiN+1{1+ln(1+ln(1−b+bri,j+s )⋃k=ri,jk−b))}
在Robust04和WT10g的实验中, T F F δ c p × I D F {\mathrm{TF}}_{\mathrm{F\delta cp}} \times \mathrm{IDF} TFFδcp×IDF和其他函数组合表明,TFB@pXID优于BM25。
4. 语言模型
Petri等人[17]提供了包含文档和查询长度先验的Dirichlet平滑语言模型的推导,我们使用这个推导。
Puurula[20]研究了语言模型的改进,展示了语言模型在三个方面有所提升:Pitman-Yor过程平滑、TFxIDF特征加权和基于模型的反馈。前两者在4.2节和4.3节中讨论,后者在5.2节中讨论。4.1 LM-DS
Dirichlet平滑是将集合模型和文档模型之间进行插值的标准方法。Petri等人[17]的推导如下:
r s v q = L q ⋅ log ( μ L d + μ ) + ∑ t ∈ q t f τ q ⋅ log ( t f t d μ ⋅ L c c f t + 1 ) rsv_{q} = L_{q} \cdot \log\left( \frac{\mu}{L_{d} + \mu} \right) + {\sum}_{t \in q}tf_{\tau q} \cdot \log\left( \frac{tf_{td}}{\mu} \cdot \frac{L_{c}}{cf_{t}} + 1 \right) rsvq=Lq⋅log(Ld+μμ)+∑t∈qtfτq⋅log(μtftd⋅cftLc+1)
其中 L q L_{q} Lq是查询的长度, μ \mu μ是一个调整参数, t f k q tf_{kq} tfkq是查询中某个术语出现的次数, L c L_{c} Lc是以术语为单位的集合长度, c f t cf_{t} cft是该术语在集合中出现的次数。在.GOV和TREC 7+8的实验中,这个函数(LM-DS)表现优于BM25。
4.2 LM-PYP
Pitman-Yor过程(PYP)用于概率建模遵循幂律分布的情况。对PYP的推断可以通过结合幂律折扣和Dirichlet平滑语言模型来高效近似[15,20]。这个折扣通过以下方式应用到术语频率上:
t f t d ′ = max ( t f t d − g ⋅ t f t d g , 0 ) tf_{td}^{{\prime}} = \max\left( tf_{td} {-} g \cdot tf_{td}{}^{g},0 \right) tftd′=max(tftd−g⋅tftdg,0)
其中 g g g是折扣参数。这个折扣应用于排名函数中使用的所有术语频率,包括文档长度的计算, L d ′ L_{d}^{{\prime}} Ld′。
Puurula使用这个折扣和文档长度先验[1]:
prior prior d = log ( 1 − L d ′ L d + μ ) \operatorname{prior}{\operatorname{prior}}_{d} = \log\left( 1 {-} \frac{L_{d}^{{\prime}}}{L_{d} + \mu} \right) priorpriord=log(1−Ld+μLd′)
其中 μ \mu μ是平滑参数。
对于查询中的每个术语,使用折扣后的术语频率,以及该术语在集合中出现的次数(集合频率, c f i cf_{i} cfi),以及以术语为单位的集合长度 L c L_{c} Lc,来计算该术语对查询的影响, r s v s q rsv_{sq} rsvsq:
r s v t q = t f t q ⋅ log ( t f t d ′ ⋅ L c μ c ⋅ c ⋅ f t + 1 ) rsv_{tq} = tf_{tq} \cdot \log\left( \frac{tf_{td}^{\prime} \cdot L_{c}}{\mu_{c} \cdot c \cdot f_{t}} + 1 \right) rsvtq=tftq⋅log(μc⋅c⋅fttftd′⋅Lc+1)
将这个与查询长度 L q L_{q} Lq 结合,得到LM-PYP的公式:
r s v q = L q ⋅ log ( 1 − L d ′ L d + u ) + ∑ t ∈ q t f t q ′ ⋅ log ( t f t d ′ ′ ⋅ L c μ ⋅ c ⋅ f t + 1 ) rsv_{q} = L_{q} \cdot \log\left( 1 - \frac{L_{d}^{\prime}}{L_{d} + u} \right) + \sum_{t \in q} tf_{tq^{\prime}} \cdot \log\left( \frac{tf_{td^{\prime}}^{\prime} \cdot L_{c}}{\mu \cdot c \cdot f_{t}} + 1 \right) rsvq=Lq⋅log(1−Ld+uLd′)+t∈q∑tftq′⋅log(μ⋅c⋅fttftd′′⋅Lc+1)
在TREC 1-5、FIRE 2008-2011和OHSUMED等实验中,它显示了对LM-DS的改进。
4.3 LM-PYP-TF-IDF
在进行PYP平滑之前,可以将TF-IDF权重应用到所有词频值上。这样可以根据集合特性对词频进行加权[20]。这通过将TF-IDF变换普遍应用于所有频率参数来实现。例如,Pitman-Yor TF-IDF平滑后的词频 t f t d ′ ′ tf_{td}^{\prime\prime} tftd′′ 由TF-IDF加权后的词频 t f t d ′ tf_{td}^{\prime} tftd′ 计算得出:
t f t d ′ ′ = max ( t f t d ′ − g ⋅ t f t d ′ ⋅ g , 0 ) tf_{td}^{\prime\prime} = \max\left( tf_{td}^{\prime} - g \cdot tf_{td}^{\prime \cdot g}, 0 \right) tftd′′=max(tftd′−g⋅tftd′⋅g,0)
其中
t f t d ′ = log ( 1 + t f t d L o u t ) ⋅ log ( N d f t ) tf_{td}^{\prime} = \log\left( 1 + \frac{tf_{td}}{L_{out}} \right) \cdot \log\left( \frac{N}{df_{t}} \right) tftd′=log(1+Louttftd)⋅log(dftN)
其中 L 0 d L_{0d} L0d 是文档的 L θ L_{\theta} Lθ 规范(独特词数)。
文档长度 L d ′ ′ L_{d}^{\prime\prime} Ld′′ 也类似计算:
L d ′ ′ = ∑ t ∈ d t f t d ′ ′ L_{d}^{\prime\prime} = \sum_{t \in d} tf_{td}^{\prime\prime} Ld′′=t∈d∑tftd′′
同时
L d ′ = ∑ t ∈ d t f u d ′ L_{d}^{\prime} = \sum_{t \in d} tf_{ud}^{\prime} Ld′=t∈d∑tfud′
集合平滑和TF-IDF权重有重叠的作用,不应同时使用[20]。使用均匀背景分布进行平滑将方程中的集合频率成分替换为集合中的独特词数 N 0 N_{0} N0,得到与词相关的 r s v rsv rsv 成分:
r s v 1 q = t f 1 q ′ ⋅ log ( t f s q ′ ′ ⋅ N 0 μ + 1 ) rsv_{1q} = tf_{1q}^{\prime} \cdot \log\left( \frac{tf_{sq}^{\prime\prime} \cdot N_{0}}{\mu} + 1 \right) rsv1q=tf1q′⋅log(μtfsq′′⋅N0+1)
其中 t f t q ′ tf_{tq}^{\prime} tftq′ 由查询频率 t f x q tf_{xq} tfxq 和查询的 L 0 L_{0} L0
规范 L θ l L_{{\theta}_{l}} Lθl(查询中的独特词数)计算得出:
t f t q ′ = log ( 1 + t f t q L o q ) ⋅ log ( N d f t ) tf_{tq}^{\prime} = \log\left( 1 + \frac{tf_{tq}}{L_{oq}} \right) \cdot \log\left( \frac{N}{df_{t}} \right) tftq′=log(1+Loqtftq)⋅log(dftN)
L q ′ L_{q}^{\prime} Lq′ 也类似计算:
L q ′ = ∑ t ∈ q t f t q ′ L_{q}^{\prime} = \sum_{t \in q} tf_{tq}^{\prime} Lq′=t∈q∑tftq′
再次使用基于文档长度的先验:
prior d t = log ( 1 − L d ′ ′ L d + μ ) {\operatorname{prior}}_{dt} = \log\left( 1 - \frac{L_{d}^{\prime\prime}}{L_{d} + \mu} \right) priordt=log(1−Ld+μLd′′)
当与查询长度 L g ′ L_{g}^{\prime} Lg′ 结合时,它给出了Pitman-Yor过程TF-IDF排名函数,即LM-PYP-TF-IDF。
rsv q = L q ⋅ log ( 1 − L d n L d + μ ) + ∑ x ∈ q t f u q e ′ log ( c f u q ′ ′ ⋅ N o μ + 1 ) {\operatorname{rsv}}_q = L_q \cdot \log\left(1 - \frac{L_d^n}{L_d + \mu}\right) + \sum_{x \in q}tf_{uq}^{e'}\log\left(\frac{cf_{uq}^{''} \cdot N_o}{\mu} + 1\right) rsvq=Lq⋅log(1−Ld+μLdn)+x∈q∑tfuqe′log(μcfuq′′⋅No+1)
在多个TREC和FIRE语料库上的测试表明,这个函数优于LM-DS,并且经常优于不使用TF乘以IDF平滑的变体。
5. 伪相关反馈
概率排名原则指出,搜索引擎应按最可能到最不可能的相关性对文档进行排序。如果成功,可以进一步处理顶部文档以提高精确度和召回率。一种常见的方法是使用相关反馈。
在完全相关反馈中,搜索引擎向用户展示结果列表,用户选择相关(有时也选择不相关)的文档。这些反馈被用于生成新的结果列表。有多种方法,一些涉及执行新的查询(例如,查询扩展),而另一些则仅根据反馈重新排列结果(例如,查询重新排名)。
1 这些“先验”不是概率先验,它们是与查询词无关的组件,等于背景平滑分布的对数权重。
如果搜索引擎在排序方面有效,那么可以合理假设顶部文档是相关的,而底部文档则不那么相关。因此,用户无需手动标识相关和不相关的文档,因为它们是隐含的。这种反馈方式被称为伪相关反馈。
我们将考察两种伪相关反馈方法:使用KL散度的查询扩展;以及使用截断模型反馈的查询重新排名。
5.1 KL散度
KL散度的目的是识别一个分布中频率与第二个分布的偏离程度。在相关反馈中,该技术用于查找在前k个文档中出现的频率高于语料库统计预测的术语。
给定一个结果列表,首先检查前k个文档(作为单个元文档),计算每个唯一术语的频率。然后,为每个术语计算与语料库语言模型的Kullback-Leibler散度:
D K L ( d ∥ c ) = p ( d ) ⋅ log p ( d ) p ( c ) D_{KL}(d \parallel c) = p(d) \cdot \log\frac{p(d)}{p(c)} DKL(d∥c)=p(d)⋅logp(c)p(d)
其中, d d d是元文档, c c c是语料库。概率使用最大似然估计计算,即观察频率除以观察长度。
然后,元文档中的所有术语按 D K L ( d ∥ c ) D_{KL}(d \parallel c) DKL(d∥c)从高到低排序。选择前m个术语用于查询扩展。有许多不同的方法,但ATIRE中看到的方法基于Rocchio。
在向量空间模型中,Rocchio[24]建议将查询向已知相关文档的质心移动,远离已知非相关文档的质心,但保持原始查询 q i q_i qi。即:
q i + 1 = α q i + β ∑ l = 1 r R l r − γ ∑ j = 1 r R j ‾ r ˉ q_{i + 1} = \alpha q_i + \beta\frac{\sum_{l = 1}^r R_l}{r} - \gamma\frac{\sum_{j = 1}^r \overline{R_j}}{\bar{r}} qi+1=αqi+βr∑l=1rRl−γrˉ∑j=1rRj
其中,新的查询 q i + 1 q_{i + 1} qi+1是原始查询的 α \alpha α比例,是r个相关文档的质心的 β \beta β比例,而远离 r ˉ \bar{r} rˉ个非相关文档的 γ \gamma γ距离。
ATIRE组合忽略了非相关文档,因为它们无法确定 ( γ = 0 ) (\gamma = 0) (γ=0),并且设置 α = β = 1 \alpha = \beta = 1 α=β=1。
Robertson等人[21]假设结果列表底部的文档是非相关的。然而,非相关文档的另一个来源是未出现在结果列表中的文档。我们留待未来的工作来确定使用非相关文档在反馈中是否有效。
总结来说,ATIRE的相关反馈方法通过从文档集合中使用KL散度计算的前k个文档中添加旧查询 q i q_i qi的前n个术语,生成新的查询 q i + 1 q_{i+1} qi+1。这可能导致反馈查询中出现相同的术语多次,但假设排名函数会处理这个问题。随着新术语的添加,这是查询扩展。
5.2 剪枝模型反馈
Puurula[20]建议将每个术语的查询频率重新计算为前k个文档的语言模型和文档的语言模型之间的线性插值。由于这种方法不向查询添加新术语,它是查询重新排名(尽管是通过进行第二次搜索)。出于效率考虑,该模型仅使用前k个文档,并且只使用查询中出现的术语。这两种策略在基于语言模型的伪相关反馈中很常见。
搜索引擎计算的语言模型分数是对数概率,因此在使用前需要转换出来,
t f t q ′ = ( 1 − λ ) t f t q l q + λ ∑ d ≤ k e i π v q r + s v t q + μ v d t d Z tf_{tq}^{{\prime}} = (1 {-} \lambda)\frac{tf_{tq}}{l_{q}} + \lambda{\sum}_{d {\leq} k}\frac{e^{i\pi v}q^{r + sv_{tq} + \mu v_{d}t{}_{d}}}{Z} tftq′=(1−λ)lqtftq+λ∑d≤kZeiπvqr+svtq+μvdtd
其中 R R R是前k个文档的集合, λ \lambda λ是一个调整参数, Z Z Z是一个归一化因子,
Z = ∑ d ∈ B ∑ t ∈ d e x w q + r x v q q + μ r l o r d Z = {\sum}_{d {\in} B}{\sum}_{t {\in} d}e^{xw_{q} + rxv_{qq} + \mu rlor_{d}} Z=∑d∈B∑t∈dexwq+rxvqq+μrlord
归一化因子 Z Z Z的定义是为了高效计算,通过遍历查询中每个术语 t t t在倒排索引中的前k个文档。新的查询长度 L q ′ L_{q}^{{\prime}} Lq′由 t f t q ′ tf_{tq}^{{\prime}} tftq′分数的和计算得出。
这种方法已应用于第4.2节和4.3节的Pitman-Yor和TFxIDF Pitman-Yor语言模型。在早期的TREC和FIRE集合上测试时,通常优于无反馈的相同函数。
6. 实验
第3和4节讨论了许多排名函数,第5节讨论了两种不同的反馈方法。尽管ATIRE反馈方法可以应用于任何函数,但语言模型反馈方法依赖于rsv分数是对数概率,而BM25和相关函数不产生这样的分数。
6.1 训练
每个排名函数都使用2009年68个主题的标题字段在INEX维基百科文档集合上进行训练。这个维基百科集合是2008年10月8日的备份,包含2,666,190篇文章,转换为XML并使用2008-w40-2版本的YAGO进行注释。它大约有50.07GB大小,在INEX上被广泛使用。
在所有情况下,最佳参数都是通过粒子群优化(64个粒子,20代,ω⁻=0.4,ϕₚ=0.3,ϕ₉=0.2)找到的。对于BM25函数,b的搜索范围为0到1,δ也为0到1;而kl的搜索范围为0到3(所有到小数点一位)。对于LM-DS,μ的搜索范围为100到3000。对于LM-PYP,g的搜索范围为0到0.9,步长为0.1(到一位小数),μ的范围为100到3000。对于LM-PYP-TFIDF,μ的搜索范围为0到1,g的范围为0.000到0.009,步长为0.001(到一位有效数字)。
表1列出了每个排名函数的最佳参数。第1列列出了函数,第2列给出了学习到的参数。训练结果显示,如果要看到对BM25的改进,这些改进可能不会来自排名函数。这些改进可能来自诸如词干提取或相关反馈之类的召回增强工具,或者像停止这样的减少假阳性的工具,或者二元组和邻近处理。或者,用于计算MAP的二元评估可能不足以衡量这些排名函数之间看到的微妙重新排序,正如Trotman和Keeler所提出的那样。
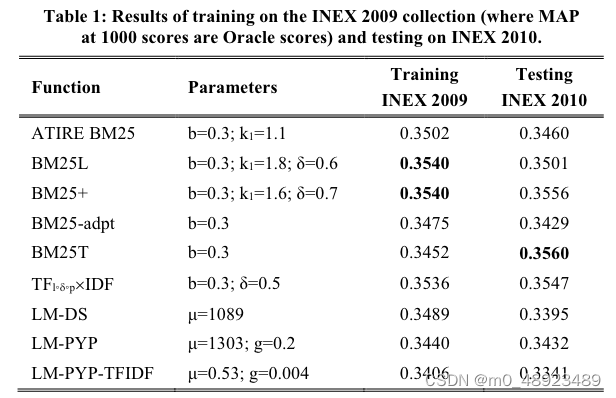
表 1:在INEX 2009集合上进行训练(1000个得分的MAP为Oracle分数)并在INEX 2010上进行测试的结果。
6.2 同一文档不同查询
为了衡量在未训练查询上的性能,我们使用表1中的排名函数和参数对INEX 2010主题对同一文档集合进行测试。使用52个主题的标题字段。结果在表1的最后列中显示。例如,使用 k l = 1.1 k_{l} = 1.1 kl=1.1和 b = 0.3 b = 0.3 b=0.3的ATIRE BM25在INEX 2009上训练并在INEX 2010上测试时,MAP得分为0.3460。得分最高的函数是BM25T,MAP为0.3560(加粗显示)。不同排名函数之间的变化仍然很小,这一点再次引人注目。
6.3 不同文档不同查询
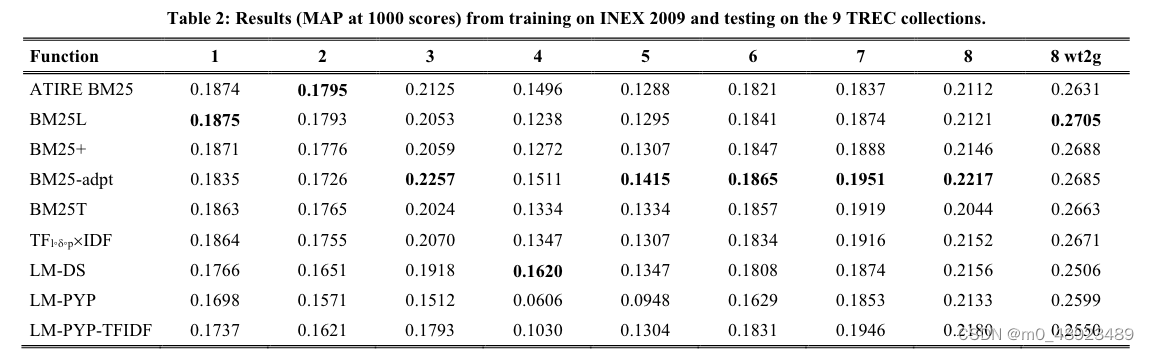
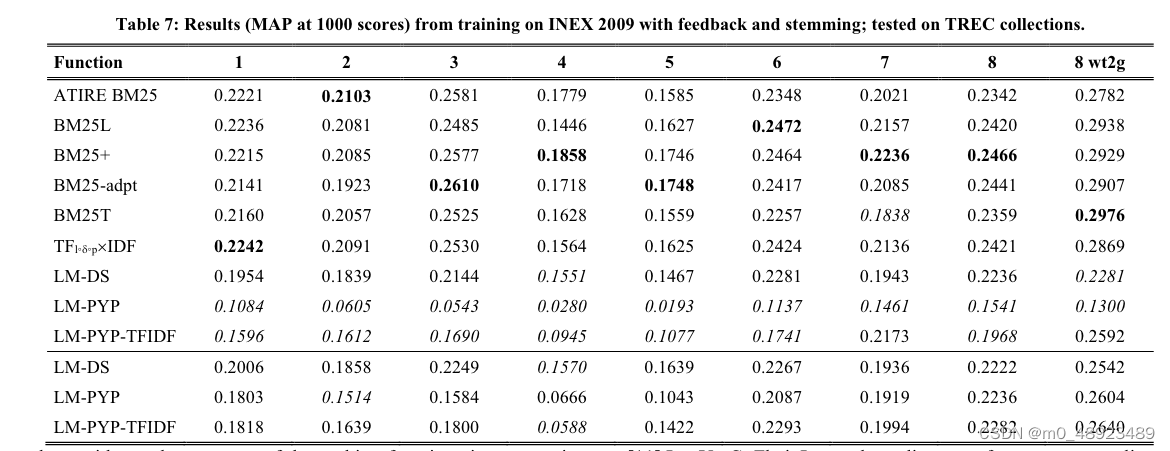
为了评估排名函数的可移植性,我们使用表1中的排名函数和参数在前8个TREC检索式集合以及TREC 8 wt2g集合上进行了测试。表3列出了使用的主题和文档集合。第一行列出了TREC活动,第二行给出主题编号,第三行提供文档的来源。例如,TREC 7使用了TREC磁盘4和5上的主题351-400,但不包括国会记录文档。标题字段被用作查询(TREC 4没有标题,所以使用描述字段)。表2展示了MAP@1000的分数。第一列是排名函数的名称,第二列及以后的列给出了给定TREC活动的MAP@1000分数。例如,ATIRE BM25在TREC 1上的MAP@1000得分为0.1874。每个TREC活动的最佳分数以粗体显示。
以这种方式测试时,BM25-adpt在9个集合中有5个集合上表现优于其他方法。通常,BM25函数比语言模型表现更好——但ATIRE是基于BM25的搜索引擎设计,而语言模型不是原始作者实现的。
BM25-adpt,它从索引中计算出一个术语特定的 k l k_l kl,似乎可以很容易地在集合间转移,而无需重新训练。
表3:实验中使用的TREC集合。TREC 7和8使用了磁盘4和5,但不包括国会记录。
| TREC | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 wt2g |
|---|---|---|---|---|---|---|---|---|---|
| 主题 | 51- | 101- | 151- | 201- | 251- | 301- | 351- | 401- | 401- |
| 数量 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 450 |
| 磁盘 | 1 + 2 1+2 1+2 | 1 + 2 1+2 1+2 | 1+2 | 2+3 | 2+4 | 4 + 5 4+5 4+5 | 4 + 5 † 4+5^\dagger 4+5† | 4 + 5 † 4+5^\dagger 4+5† | wt2g |
6.4 反馈
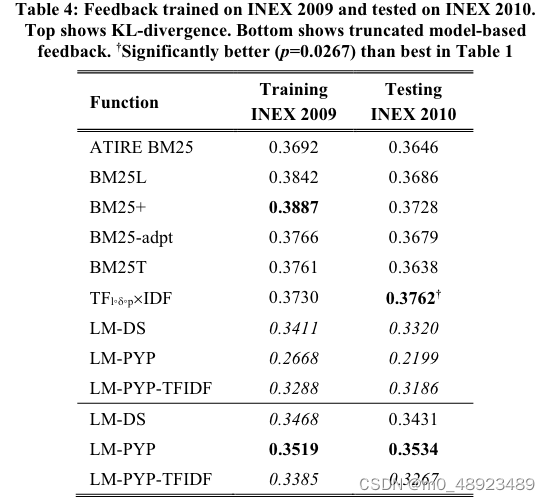
使用表1中的排名函数添加了相关性反馈后,通过50代粒子群优化器重新训练。不仅学习了KL散度反馈算法的 n n n(术语)和 k k k(文档),还学习了两组排名函数参数:第一组是预反馈搜索参数,第二组是后反馈搜索参数。训练使用了INEX 2009,测试使用了INEX 2010。 k k k和 n n n的搜索范围为1到100。
结果在表4的顶部呈现。第一列列出了函数名称,第二列列出了MAP@1000,第三列列出了使用2010主题时这些参数的分数。为了简洁,最优参数(最多8个)被省略。例如,训练期间的最佳分数(以粗体显示)是BM25+,其训练分数为0.3887,测试分数为0.3728。
表4底部展示了语言模型排名算法在使用截断的模型基反馈方法时的分数。搜索 k k k的范围为1到100,而 λ \lambda λ的范围为0到1。
结果显示,使用查询扩展时,基于BM25的排名函数有所改进,但在语言模型函数中没有(加粗强调)。当使用截断模型反馈时,有时会看到语言模型的改进。
表4:在INEX 2009上训练并在INEX 2010上测试的反馈。顶部显示KL散度。底部显示截断模型反馈。'显著优于表I中的最佳结果
(
p
=
0.0267
)
(p = 0.0267)
(p=0.0267)
6.5 词干提取和停用词
文献中可以看到许多不同的词干提取算法,包括简单的s-stripper [5],Porter [19]、Paice [16]、Lovins [9]和Krovetz [7]的算法。还有许多不同的停用词列表,例如NCBI的313词列表,以及Puurula [20]使用的988词列表。
针对每种词干提取器和停用词列表,重新训练每个排名函数和每种反馈机制是不切实际的。然而,可以测试一个排名函数。由于BM25-adpt、BM25T和
LM-DS各自只有一个参数,且在TREC集合上BM25-adpt表现最佳,因此我们选择了它。词干提取和停用词处理都在索引之前进行,因此文档长度不包括停用词,而词频包括所有词形。
表5:在INEX 2009上使用不同词干提取器和停用词列表训练BM25-adpt的结果。分数为1000的MAP。
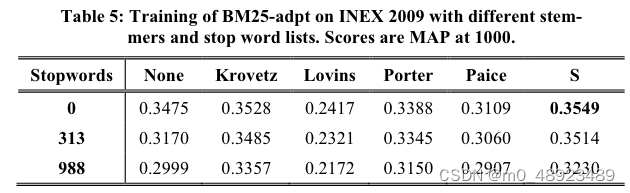
表格显示了在这个集合和这个排名函数上的两种模式:首先,停用词列表越小,性能越好(无停用词最佳);其次,s-stripper比其他方法更有效,表明弱词干提取优于强词干提取。只有Krovetz词干提取器和s-stripper比不进行词干提取更好。其他研究[20]表明,停用词对语言模型和自然语言处理很重要,但我们只测试了BM25-adpt。
6.6 词干提取与反馈
第6.4节表明反馈是有效的,第6.5节表明词干提取也是有效的(并且停止词移除无效)。本节将两者结合。即,使用s-stripper进行词干提取但不移除停用词的索引重新训练排名函数。实验使用INEX 2009集合进行训练,INEX 2010集合进行测试。
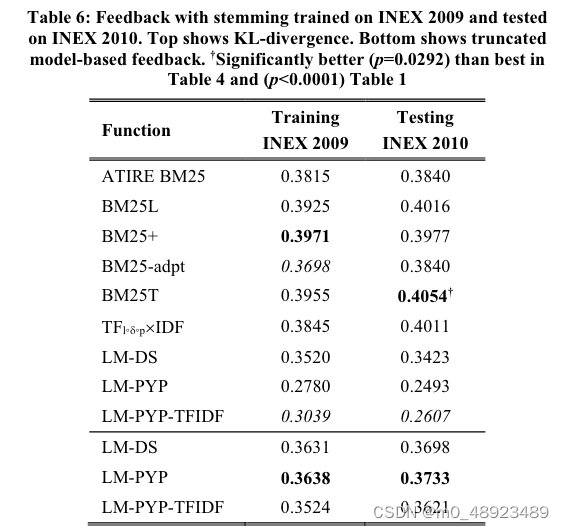
表格6显示了结果。第1列列出函数,第2列是训练时的MAP@1000,第3列是测试时的MAP@1000。表格显示,使用反馈进行词干提取的训练通常比单独使用反馈更好。在BM25-adpt和LM-PYP-TFIDF两种情况下(用斜体表示),情况并非如此。在大多数情况下,测试查询的分数都优于不进行词干提取的情况。
表格6:在INEX 2009上使用反馈进行词干提取训练,然后在INEX 2010上测试。顶部显示KL散度,底部显示截断的模型反馈。'显著优于表4中最佳 ( p = 0.0292 ) (p = 0.0292) (p=0.0292)和表1中 ( p < 0.0001 ) (p < 0.0001) (p<0.0001)。
6.7 词干提取、反馈与TREC
在最后的实验中,我们将第6.6节中学习的参数应用于…
6. 在Table 3中使用s-stemmer并未移除停用词的情况下,对TREC集合进行了测试。结果在Table 7中展示。第一列列出排名函数,第一行是TREC集合,其余单元格给出了该函数在对应集合上的1000个文档的平均精确率(MAP)。每个集合的最佳得分用粗体表示。如果带反馈的词干化表现比函数本身差(Table 3与Table 7对比),则用斜体表示。
之前的趋势仍然存在。词干化似乎有效;语言模型下的查询扩展效果不佳,但BM25下有效;基于模型的截断反馈对语言模型有效。没有明显的最佳函数。
6.8 统计显著性
无节制地执行数百次显著性检验不太可能得出有意义的结果。然而,我们使用了一对一尾t检验来比较Table 1、4和6中的最佳结果。带反馈的效果优于无反馈(p = 0.0267)。带反馈的词干化优于仅反馈(p = 0.0292)。带反馈的词干化优于两者都不使用(p < 0.0001)。未进行任何调整(如Bonferroni校正)。
7. 结论
本研究考察了9种排名函数、2种反馈方法、5种词干算法和2种停用词列表。结果显示,停用词无效,词干化有效,反馈有效,且不使用停用词、词干化和反馈的组合通常会改善基础排名函数。然而,没有
Table 7:使用反馈和词干化在INEX 2009上训练的结果(1000个文档的MAP分数),在TREC集合上测试。
这清楚地表明,没有任何一种排名函数系统上优于其他方法。所有实现都是由一位作者完成,并且融入了一个基于BM25的搜索引擎,这可能对语言建模的性能产生负面影响。由于参数众多,训练过程困难,可能没有找到最佳参数。特别是PYP和PYP-TFIDF中的幂律折旧参数 g g g的敏感性是一个问题。
由于观察到的效应数量众多,对大量排名函数的比较具有探索性,但我们没有发现一种排名函数始终优于其他方法。
我们没有探索这些排名函数在诸如学习排名等场景中的应用——这留待未来的工作。然而,我们注意到在我们的场景中,基于BM25的函数似乎通常优于语言建模。