Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Sketch3D:用于草图到3D生成的样式一致性指南
Abstract. Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Recently, image-to-3D approaches have achieved significant results with a natural image as input. However, it is not always possible to access these enriched color input samples in practical applications, where only sketches are available. Existing sketch-to-3D researches suffer from limitations in broad applications due to the challenges of lacking color information and multi-view content. To overcome them, this paper proposes a novel generation paradigm Sketch3D to generate realistic 3D assets with shape aligned with the input sketch and color matching the textual description. Concretely, Sketch3D first instantiates the given sketch in the reference image through the shape-preserving generation process. Second, the reference image is leveraged to deduce a coarse 3D Gaussian prior, and multi-view style-consistent guidance images are generated based on the renderings of the 3D Gaussians. Finally, three strategies are designed to optimize 3D Gaussians, i.e., structural optimization via a distribution transfer mechanism, color optimization with a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Extensive visual comparisons and quantitative analysis illustrate the advantage of our Sketch3D in generating realistic 3D assets while preserving consistency with the input.
最近,图像到3D的方法已经取得了显着的结果与自然图像作为输入。然而,在实际应用中并不总是能够访问这些丰富的颜色输入样本,其中只有草图可用。现有的草图到3D的研究受到限制,在广泛的应用,由于缺乏颜色信息和多视图内容的挑战。为了克服这些问题,本文提出了一种新的生成范式Sketch3D生成逼真的3D资产与输入草图对齐的形状和颜色匹配的文本描述。具体地说,Sketch3D首先通过形状保持生成过程在参考图像中实例化给定的草图。其次,利用参考图像推导出粗略的3D高斯先验,并基于3D高斯的渲染生成多视图风格一致的引导图像。最后,设计了三种优化3D高斯分布的策略,即:通过分布传递机制的结构优化、具有直接MSE损失的颜色优化和具有基于CLIP的几何相似性损失的草图相似性优化。广泛的视觉比较和定量分析说明了我们的Sketch3D在生成逼真的3D资产,同时保持与输入的一致性方面的优势。
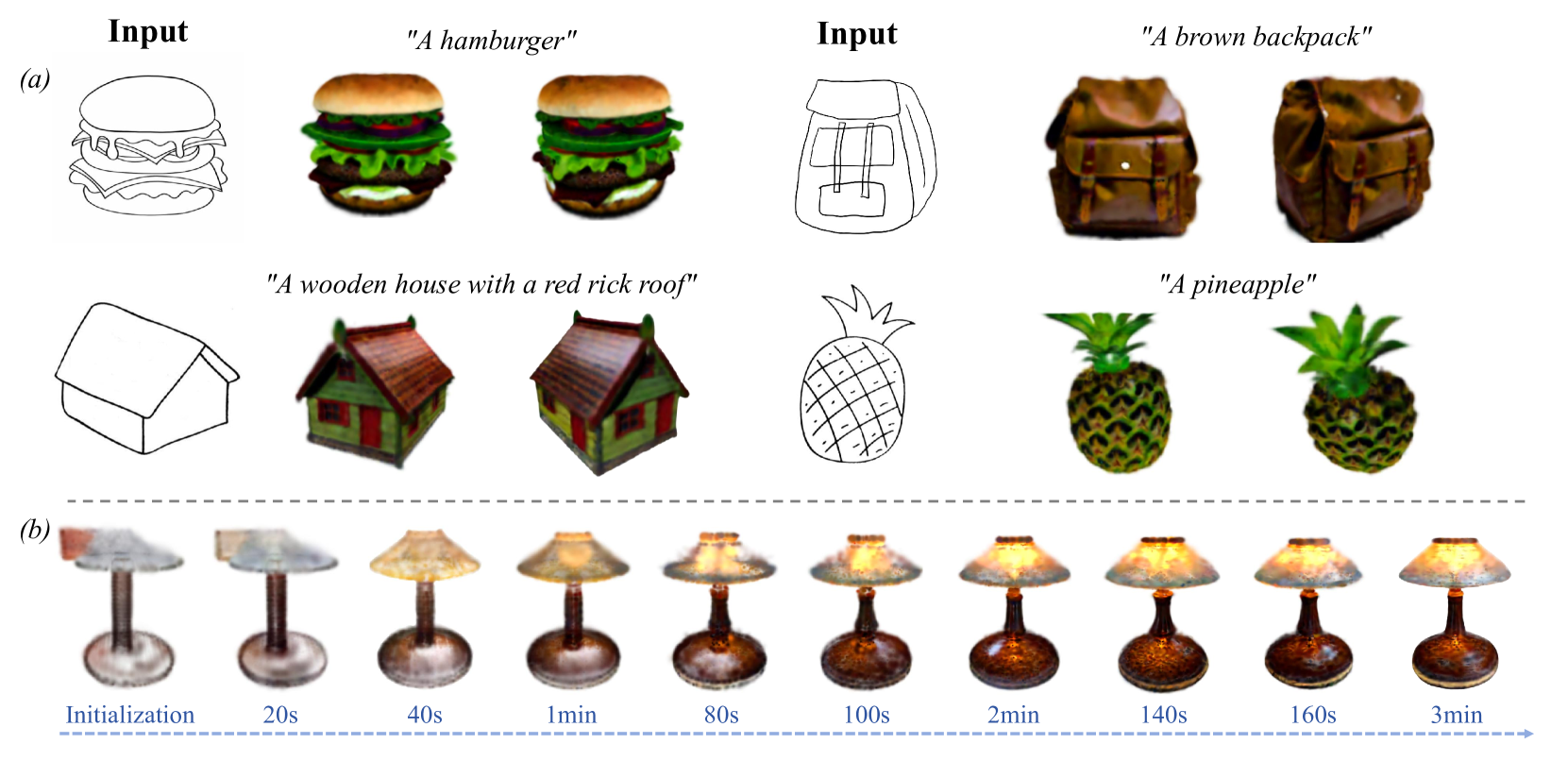
Figure 1. Sketch3D aims at generating realistic 3D Gaussians with shape consistent with the input sketch and color aligned with textual description. (a) The novel-view generation results of four objects based on the input sketch and the text prompt. (b) Given a sketch of a lamp and text prompt “A textural wooden lamp”, the 3D Gaussians progressively changes throughout the generation process. Our method can complete this generation process in about 3 minutes.
图1. Sketch3D旨在生成逼真的3D高斯模型,其形状与输入草图一致,颜色与文本描述一致。(a)基于输入草图和文本提示的四个对象的新视图生成结果。(b)给定一个灯的草图和文本提示“纹理木灯”,3D高斯在整个生成过程中逐渐变化。我们的方法可以在大约3分钟内完成这个生成过程。
1.Introduction
3D content generation is widely applied in various fields (Li et al., 2023b), including animation, movies, gaming, virtual reality, and industrial production. A 3D asset generative model is essential to enable non-professional users to easily transform their ideas into tangible 3D digital content. Significant efforts have been made to develop image-to-3D generation (Yu et al., 2021; Huang et al., 2023b; Liu et al., 2023a; Zhang et al., 2023c), as it enables users to generate 3D content based on color images. However, several practical scenarios provide only sketches as input due to the unavailability of colorful images. This is particularly true during the preliminary stages of 3D product design, where designers rely heavily on sketches. Despite their simplicity, these sketches are fundamental in capturing the core of the design. Therefore, it is crucial to generate realistic 3D assets according to the sketches.
3D内容生成广泛应用于各种领域(Li等人,2023 b),包括动画、电影、游戏、虚拟现实和工业生产。3D资产生成模型对于使非专业用户能够轻松地将其想法转换为有形的3D数字内容至关重要。已经做出了大量努力来开发图像到3D生成(Yu等人,2021; Huang等人,2023 b; Liu等人,2023 a; Zhang等人,2023 c),因为它使用户能够基于彩色图像生成3D内容。然而,由于彩色图像不可用,一些实际场景仅提供草图作为输入。在3D产品设计的初始阶段尤其如此,设计师在很大程度上依赖草图。尽管它们很简单,但这些草图是捕捉设计核心的基础。因此,根据草图生成逼真的3D资产至关重要。
Inspired by this practical demand, studies (Lun et al., 2017; Zhang et al., 2021; Kong et al., 2022; Sanghi et al., 2023) have endeavored to employ deep learning techniques in generating 3D shapes from sketches. Sketch2model (Zhang et al., 2021) employs a view-aware generation architecture, enabling explicit conditioning of the generation process based on viewpoints. SketchSampler (Gao et al., 2022b) proposed a sketch translator module to exploit the spatial information in a sketch and generate a 3D point cloud conforming to the shape of the sketch. Furthermore, recent works have explored the generation or editing of 3D assets containing color through sketches. Several (Wu et al., 2023; Qi et al., 2023) proposed a sketch-guided method for colored point cloud generation, while others (Mikaeili et al., 2023; Lin et al., 2023a) proposed a 3D editing technique to edit a NeRF based on input sketches. Despite these research advancements, there are still limitations hindering their widespread applications. First, generating 3D shapes from sketches typically lacks color information and requires training on extensive datasets. However, the trained models are often limited to generating shapes within a single category. Second, the 3D assets produced through sketch-guided generation or editing techniques often lack realism and the process is time-consuming.
受这种实际需求的启发,研究(Lun et al,2017; Zhang et al,2021; Kong et al,2022; Sanghi et al,2023)已经开始采用深度学习技术从草图生成3D形状。Sketch 2 model(Zhang et al,2021)采用了一种视图感知的生成架构,可以基于视点对生成过程进行显式调节。SketchSampler(Gao et al,2022 b)提出了一种草图转换器模块,用于利用草图中的空间信息并生成符合草图形状的3D点云。此外,最近的工作已经探索了通过草图生成或编辑包含颜色的3D资产。一些人(Wu等人,2023; Qi等人,2023)提出了一种用于彩色点云生成的草图引导方法,而其他人(Mikaeili等人,2023; Lin等人,2023 a)提出了一种基于输入草图编辑NeRF的3D编辑技术。 尽管这些研究取得了进展,但仍然存在阻碍其广泛应用的限制。首先,从草图生成3D形状通常缺乏颜色信息,并且需要在大量数据集上进行训练。然而,经过训练的模型通常仅限于生成单个类别内的形状。其次,通过草图引导生成或编辑技术生成的3D资产通常缺乏真实感,并且该过程非常耗时。
These challenges inspire us to consider: Is there a method to generate 3D assets where the shape aligns with the input sketch while the color corresponds to the textual description? To address these shortcomings, we introduce Sketch3D, an innovative framework designed to produce lifelike 3D assets. These assets exhibit shapes that conform to input sketches while accurately matching colors described in the text. Concretely, a reference image is first generated via a shape-preserving image generation process. Then, we initialize a coarse 3D prior using 3D Gaussian Splatting (Yi et al., 2023), which comprises a rough geometric shape and a simple color. Subsequently, multi-view style-consistent guidance images can be generated using the IP-Adapter (Ye et al., 2023). Finally, we propose three strategies to optimize 3D Gaussians: structural optimization with a distribution transfer mechanism, color optimization using a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Specifically, the distribution transfer mechanism is employed within the SDS loss of the text-conditioned diffusion model, enabling the optimization process to integrate both the sketch and text information effectively. Furthermore, we formulate a reasonable camera viewpoint strategy to enhance color details via the ℓ2-norm loss function. Additionally, we compute the �2 distance between the mid-level activations of CLIP. As Figure 1 shows, our Sketch3D provides visualization results consistent with the input sketch and the textual description in just 3 minutes. These assets are readily integrable into software such as Unreal Engine and Unity, facilitating rapid application deployment.
这些挑战启发我们思考:是否有一种方法可以生成3D资产,其中形状与输入草图对齐,而颜色与文本描述对应?为了解决这些缺点,我们引入了Sketch3D,这是一个旨在产生逼真的3D资产的创新框架。这些资源显示的形状符合输入草图,同时准确匹配文本中描述的颜色。具体地,首先经由形状保持图像生成处理来生成参考图像。然后,我们使用3D高斯溅射(Yi等人,2023)初始化粗略的3D先验,其包括粗略的几何形状和简单的颜色。随后,可以使用IP适配器生成多视图样式一致的引导图像(Ye等人,2023)。 最后,我们提出了三种策略来优化3D高斯:结构优化与分布转移机制,颜色优化使用一个简单的MSE损失和草图相似性优化与基于CLIP的几何相似性损失。具体而言,分布传递机制内SDS损失的文本条件扩散模型,使优化过程中,集成草图和文本信息有效。此外,我们制定了一个合理的摄像机视点策略,通过 ℓ2 范数损失函数来增强颜色细节。此外,我们还计算了CLIP中间激活之间的 �2 距离。如图1所示,我们的Sketch3D在短短3分钟内就提供了与输入草图和文本描述一致的可视化结果。这些资产可轻松集成到虚幻引擎和Unity等软件中,从而促进应用程序的快速部署。
To assess the performance of our method on sketches and inspire future research, we collect a ShapeNet-Sketch3D dataset based on the ShapeNet dataset (Chang et al., 2015). Considerable experiments and analysis validate the effectiveness of our framework in generating 3D assets that maintain geometric consistency with the input sketch, while the color aligns with the textual description. Our contributions can be summarized as follows:
为了评估我们的方法在草图上的性能并激励未来的研究,我们收集了基于ShapeNet数据集的ShapeNet-Sketch 3D数据集(Chang et al,2015)。大量的实验和分析验证了我们的框架在生成与输入草图保持几何一致性的3D资产方面的有效性,而颜色与文本描述一致。我们的贡献可归纳如下:
- •
We propose Sketch3D, a novel framework to generate realistic 3D assets with shape aligned to the input sketch and color matching the text prompt. To the best of our knowledge, this is the first attempt to steer the process of sketch-to-3D generation using a text prompt with 3D Gaussian splatting. Additionally, we have developed a dataset, named ShapeNet-Sketch3D, specifically tailored for research on sketch-to-3D tasks.
·我们提出了Sketch 3D,这是一个新的框架,用于生成逼真的3D资产,其形状与输入草图对齐,颜色与文本提示匹配。据我们所知,这是第一次尝试使用具有3D高斯飞溅的文本提示来引导草图到3D生成的过程。此外,我们还开发了一个名为ShapeNet-Sketch 3D的数据集,专门针对草图到3D任务的研究。 - •
We leverage IP-Adapter to generate multi-view style-consistent images and three optimization strategies are designed: a structural optimization using a distribution transfer mechanism, a color optimization with ℓ2-norm loss function and a sketch similarity optimization using CLIP geometric similarity loss.
·我们利用IP-Adapter生成多视点风格一致的图像,并设计了三种优化策略:使用分布传递机制的结构优化、使用 ℓ2 范数损失函数的颜色优化和使用CLIP几何相似性损失的草图相似性优化。 - •
Extensive qualitative and quantitative experiments demonstrate that our Sketch3D not only has convincing appearances and shapes but also accurately conforms to the given sketch image and text prompt.
·大量的定性和定量实验表明,我们的Sketch 3D不仅具有令人信服的外观和形状,而且准确地符合给定的草图图像和文本提示。
2.Related Work 2.相关工作
2.1.Text-to-3D Generation
2.1.文本到3D的生成
Text-to-3D generation aims at generating 3D assets from a text prompt. Recent developments in text-to-image methods (Saharia et al., 2022; Ramesh et al., 2022; Rombach et al., 2022) have demonstrated a remarkable capability to generate high-quality and creative images from given text prompts. Transferring it to 3D generation presents non-trivial challenges, primarily due to the difficulty in curating extensive and diverse 3D datasets. Existing 3D diffusion models (Jun and Nichol, 2023; Nichol et al., 2022b; Gao et al., 2022a; Gupta et al., 2023; Zhang et al., 2023b; Lorraine et al., 2023; Zheng et al., 2023a; Ntavelis et al., 2023) typically focus on a limited number of object categories and face challenges in generating realistic 3D assets. To accomplish generalizable 3D generation, innovative works like DreamFusion (Poole et al., 2022) and SJC (Wang et al., 2023a) utilize pre-trained 2D diffusion models for text-to-3D generation and demonstrate impressive results. Following works continue to enhance various aspects such as generation fidelity and efficiency (Chen et al., 2023a; Lin et al., 2023b; Wang et al., 2023b; Huang et al., 2023a; Liu et al., 2023c; Tang et al., 2023a; Tsalicoglou et al., 2023; Zhu and Zhuang, 2023; Yu et al., 2023), and explore further applications (Zhuang et al., 2023; Armandpour et al., 2023; Singer et al., 2023; Raj et al., 2023; Xia and Ding, 2020; Xia et al., 2022). However, the generated contents of text-to-3D method are unpredictable and the shape cannot be controlled according to user requirements.
文本到3D生成旨在从文本提示生成3D资产。文本到图像方法的最新发展(Saharia等人,2022; Ramesh等人,2022; Rombach等人,2022)已经证明了从给定的文本提示生成高质量和创造性图像的显著能力。将其转移到3D生成带来了不小的挑战,主要是由于难以管理广泛而多样化的3D数据集。现有的3D扩散模型(Jun和Nichol,2023; Nichol等人,2022 b; Gao等人,2022 a; Gupta等人,2023; Zhang等人,2023 b; Lorraine等人,2023; Zheng等人,2023 a; Ntavelis等人,2023)通常集中于有限数量的对象类别,并在生成逼真的3D资产时面临挑战。为了实现可推广的3D生成,DreamFusion(Poole et al,2022)和SJC(Wang et al,2023 a)等创新作品利用预训练的2D扩散模型进行文本到3D生成,并展示了令人印象深刻的结果。 后续工作继续提高各方面,如生成保真度和效率(Chen等,2023 a; Lin等,2023 b; Wang等,2023 b; Huang等,2023 a; Liu等,2023 c; Tang等,2023 a; Tsalicoglou等,2023; Zhu和Zhuang,2023; Yu等人,2023),并探索进一步的应用(Zhuang等人,2023; Armandpour等人,2023; Singer等人,2023; Raj等人,2023; Xia和Ding,2020; Xia等人,2022)。然而,文本到3D方法生成的内容是不可预测的,形状不能根据用户的要求进行控制。
2.2.Sketch-to-3D Generation
2.2.草图到3D的生成
Sketch-to-3D generation aims to generate 3D assets from a sketch image and possible text input. Since sketches are highly abstract and lack substantial information (Schlachter et al., 2022), generating 3D assets based on sketches becomes a challenging problem. Sketch2Model (Zhang et al., 2021) introduces an architecture for view-aware generation that explicitly conditions the generation process on specific viewpoints. Sketch2Mesh (Guillard et al., 2021) employs an encoder-decoder architecture to represent and adjust a 3D shape so that it aligns with the target external contour using a differentiable renderer. SketchSampler (Gao et al., 2022b) proposes a sketch translator module to utilize the spatial information within a sketch and generate a 3D point cloud that represents the shape of the sketch. Sketch-A-Shape (Sanghi et al., 2023) proposes a zero-shot approach for sketch-to-3D generation, leveraging large-scale pre-trained models. SketchFaceNeRF (Lin et al., 2023a) proposes a sketch-based 3D facial NeRF generation and editing method. SKED (Mikaeili et al., 2023) proposes a sketch-guided 3D editing technique to edit a NeRF. Overall, existing sketch-to-3D generation methods have several limitations. First, generating 3D shapes from sketches invariably produces shapes without color information and needs to be trained on large-scale datasets, yet the trained models are typically limited to making predictions on a single category. Second, the 3D assets generated by the sketch-guided generation or editing techniques often lack realism, and the process is relatively time-consuming. Our method, incorporating the input text prompt, is capable of generating 3D assets with shapes consistent with the sketch and color aligned with the textual description.
草图到3D生成旨在从草图图像和可能的文本输入生成3D资产。由于草图是高度抽象的,缺乏大量的信息(Schlachter等人,2022),基于草图生成3D资产成为一个具有挑战性的问题。Sketch 2 Model(Zhang et al,2021)引入了一种视图感知生成的架构,该架构明确地将生成过程限制在特定的视点上。Sketch 2 Mesh(Guillard等人,2021)采用编码器-解码器架构来表示和调整3D形状,以便使用可微分渲染器与目标外部轮廓对齐。SketchSampler(Gao等人,2022 b)提出了一个草图转换器模块,用于利用草图中的空间信息并生成表示草图形状的3D点云。Sketch-A-Shape(Sanghi et al,2023)提出了一种用于草图到3D生成的零拍摄方法,利用大规模预训练模型。 SketchFaceNeRF(Lin等人,2023a)提出了一种基于草图的3D面部NeRF生成和编辑方法。SKED(Mikaeili等人,2023)提出了一种草图引导的3D编辑技术来编辑NeRF。总体而言,现有的草图到3D生成方法具有若干限制。首先,从草图生成3D形状总是会生成没有颜色信息的形状,并且需要在大规模数据集上进行训练,但经过训练的模型通常仅限于对单个类别进行预测。其次,由草图引导的生成或编辑技术生成的3D资产通常缺乏真实感,并且该过程相对耗时。我们的方法,结合输入文本提示,是能够生成3D资产的形状一致的草图和颜色对齐的文字描述。
3.Method
In this section, we first introduce two preliminaries including 3D Gaussian Splatting and Controllable Image Synthesis (Sec. 3.1). Subsequently, we systematically propose our Sketch3D framework (Sec. 3.2), which is progressively introduced (Sec. 3.3–3.5).
在这一节中,我们首先介绍两种算法,包括3D高斯溅射和可控图像合成(第二节)。3.1)。随后,我们系统地提出了我们的Sketch 3D框架(第二节)。3.2),这是逐步推出(第二。3.3-3.5)。
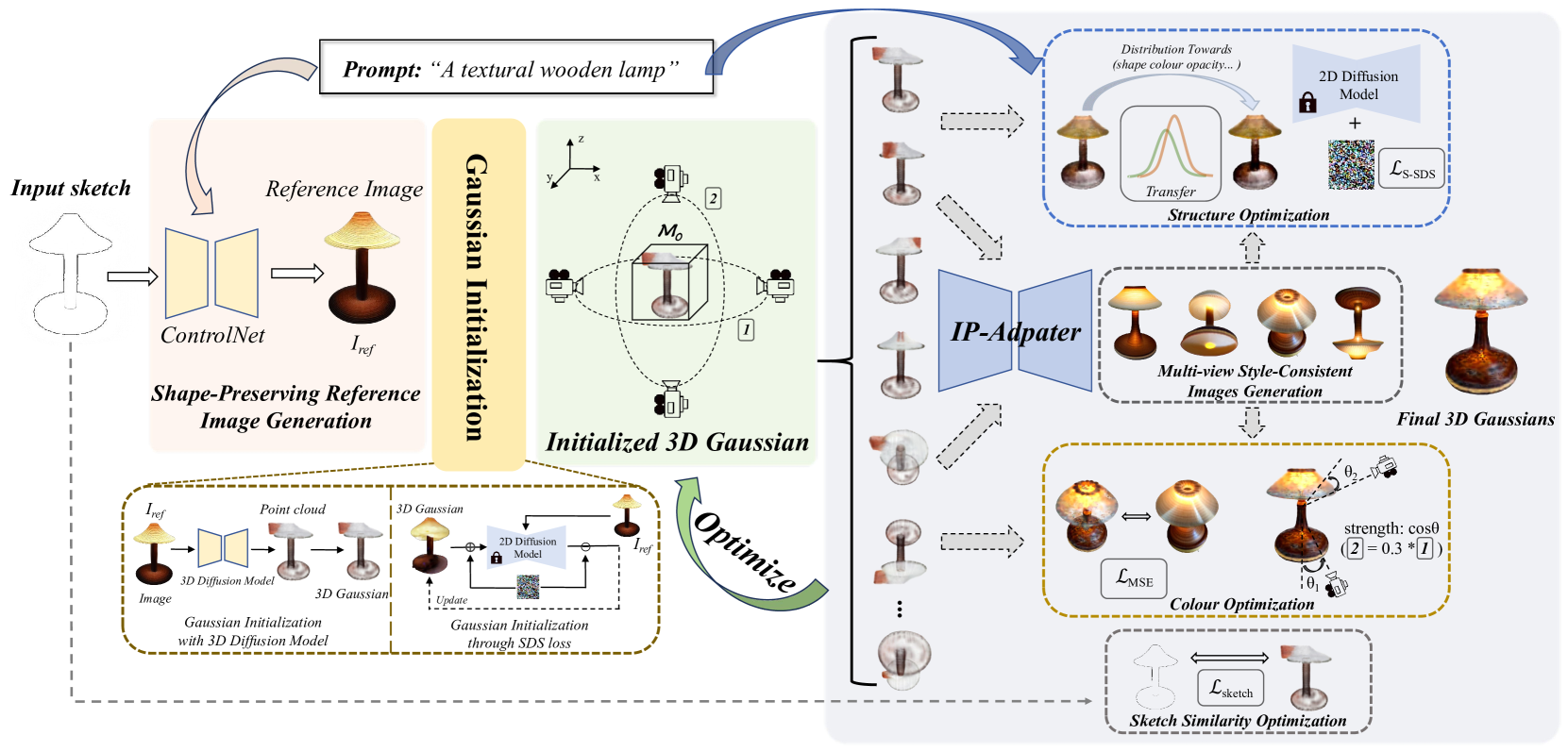
Figure 2.Pipeline of our Sketch3D. Given a sketch image and a text prompt as input, we first generate a reference image �ref using ControlNet. Second, we utilize the reference image �ref to initialize a coarse 3D prior �0, which is represented using 3D Gaussians. Third, we render the 3D Gaussians into images from different viewpoints using a designated camera projection strategy. Based on these, we obtain multi-view style-consistent guidance images through the IP-Adapter. Finally, we formulate three strategies to optimize �0: (a) Structural Optimization: a distribution transfer mechanism is proposed for structural optimization, effectively steering the structure generation process towards alignment with the sketch. (b) Color Optimization: based on multi-view style-consistent images, we optimize color with a straightforward MSE loss. (c) Sketch Similarity Optimization: a CLIP-based geometric similarity loss used as a constraint to shape towards the input sketch.
图2.我们的Sketch3D管道。给定一个草图图像和一个文本提示作为输入,我们首先使用ControlNet生成一个参考图像 �ref 。其次,我们利用参考图像 �ref 来初始化使用3D高斯表示的粗略3D先验 �0 。第三,我们使用指定的摄像机投影策略将3D高斯渲染成来自不同视点的图像。在此基础上,我们通过IP适配器获得多视图风格一致的引导图像。最后,我们制定了三种策略来优化 �0 :(a)结构优化:提出了一种用于结构优化的分布传递机制,有效地将结构生成过程转向与草图对齐。(b)色彩优化:基于多视图风格一致的图像,我们以简单的MSE损失优化色彩。(c)草图相似性优化:基于CLIP的几何相似性损失,用作对输入草图形状的约束。
3.1.Preliminaries
3D Gaussian Splatting. 3D Gaussian Splatting (3DGS) (Kerbl et al., 2023) represents a novel method for novel-view synthesis and 3D scene reconstruction, achieving promising results in both quality and real-time processing speed. Unlike implicit representation methods such as NeRF (Mildenhall et al., 2021), 3D Gaussians represents the scene through a set of anisotropic Gaussians, defined with its center position �∈ℝ3, covariance 𝚺∈ℝ7, color 𝐜∈ℝ3, and opacity �∈ℝ1. The covariance matrix 𝚺=𝐑𝐒𝐒⊤𝐑⊤ describes the configuration of an ellipsoid and is implemented via a scaling matrix 𝐒 and a rotation matrix 𝐑. Each Gaussian centered at point (mean) � is defined as:
3D高斯散射3D高斯溅射(3DGS)(Kerbl等,2023)代表了一种用于新视图合成和3D场景重建的新方法,在质量和实时处理速度方面都取得了令人满意的结果。与NeRF(Mildenhall等人,2021)等隐式表示方法不同,3D高斯通过一组各向异性高斯表示场景,定义为中心位置 �∈ℝ3 ,协方差 𝚺∈ℝ7 ,颜色 𝐜∈ℝ3 和不透明度 �∈ℝ1 。协方差矩阵 𝚺=𝐑𝐒𝐒⊤𝐑⊤ 描述椭圆体的配置,并且经由缩放矩阵 𝐒 和旋转矩阵 𝐑 来实现。以点(平均值) � 为中心的每个高斯定义为:
| (1) | �(�)=𝐞−12�⊤𝚺−1�, |
where � represents the distance between � and the query point. A ray � is cast from the center of the camera and the color and density of the 3D Gaussians that the ray intersects are computed along the ray. In summary, �(�) is multiplied by � in the blending process to construct the final accumulated color:
其中 � 表示 � 与查询点之间的距离。从相机的中心投射光线 � ,并沿该光线沿着计算与该光线相交的3D高斯的颜色和密度。总之,在混合过程中将 �(�) 乘以 � 以构建最终的累积颜色:
| (2) | �(�)=∑�=1������(��)∏�=1�−1(1−���(��)), |
where � means the number of samples on the ray �, �� and �� denote the color and opacity of the �-th Gaussian.
其中 � 表示光线上的样本数 � , �� 和 �� 表示 �-th 高斯的颜色和不透明度。
Controllable Image Synthesis. In the field of image generation, achieving control over the output remains a great challenge. Recent efforts (Li et al., 2019; Zhao et al., 2023; Li et al., 2023a) have focused on increasing the controllability of generated images by various methods. This involves increasing the ability to specify various attributes of the generated images, such as shape and style. ControlNet (Zhang et al., 2023a) and T2I-adapter (Mou et al., 2023) attempt to control image creation utilizing data from different visual modalities. Specifically, ControlNet is an end-to-end neural network architecture that controls a diffusion model (Stable Diffusion (Rombach et al., 2022)) to adapt task-specific input conditions. IP-Adapter (Ye et al., 2023) and MasaCtrl (Cao et al., 2023) leverage the attention layer to incorporate information from additional images, thus achieving enhanced controllability over the generated results.
可控图像合成。在图像生成领域,实现对输出的控制仍然是一个巨大的挑战。最近的努力(Li et al,2019; Zhao et al,2023; Li et al,2023 a)集中在通过各种方法提高生成图像的可控性。这涉及到增加指定所生成图像的各种属性(如形状和样式)的能力。ControlNet(Zhang等人,2023 a)和T2 I适配器(Mou等人,2023)试图利用来自不同视觉模态的数据控制图像创建。具体来说,ControlNet是一种端到端的神经网络架构,它控制扩散模型(Stable Diffusion(Rombach et al,2022))以适应特定于任务的输入条件。IP-Adapter(Ye et al,2023)和MasaCtrl(Cao et al,2023)利用注意力层来整合来自其他图像的信息,从而增强对生成结果的可控性。
3.2.Framework Overview 3.2.框架概述
Given a sketch image and a corresponding text prompt, our objective is to generate realistic 3D assets that align with the shape of the sketch and correspond to the color described in the textual description. To achieve this, we confront three challenges:
给定草图图像和相应的文本提示,我们的目标是生成与草图形状一致并与文本描述中描述的颜色对应的逼真3D资产。为实现这一目标,我们面临三个挑战:
- •
How to solve the problem of missing information in sketches?
·如何解决草图中缺少信息的问题? - •
How to initialize a valid 3D prior from an image?
·如何从图像初始化有效的3D先验? - •
How to optimize 3D Gaussians to be consistent with the given sketch and the text prompt?
·如何优化3D高斯曲线,使其与给定的草图和文本提示一致?
Inspired by this motivation, we introduce a novel 3D generation paradigm, named Sketch3D, comprising three dedicated steps to tackle each challenge (as illustrated in Figure 2):
受此动机的启发,我们引入了一种名为Sketch3D的新型3D生成范式,包括三个专门的步骤来解决每个挑战(如图2所示):
- •
Step 1: Generate a reference image based on the input sketch and text prompt (Sec. 3.3).
·第1步:根据输入草图和文本提示生成参考图像(第2节)3.3)。 - •
Step 2: Derive a coarse 3D prior using 3D Gaussian Splatting from the reference image (Sec. 3.4).
·步骤2:使用3D高斯溅射从参考图像导出粗略的3D先验(第2节)。3.4)。 - •
Step 3: Generate multi-view style-consistent guidance images through IP-Adapter, introducing three strategies to facilitate the optimization process (Sec. 3.5).
第三步:通过IP适配器生成多视图风格一致的引导图像,引入三种策略来促进优化过程(第12节)。3.5)。
3.3.Shape-Preserving Reference Image Generation
3.3.形状保持参考图像生成
For image-to-3D generation, sketches offers very limited information, when served as a visual prompt compared with RGB images. They lack color, depth, semantic information, etc., and only contain simple contours.
对于图像到3D的生成,与RGB图像相比,草图作为视觉提示时提供的信息非常有限。它们缺乏颜色、深度、语义信息等,并且仅包含简单的轮廓。
To solve the above problems, our solution is to create a shape-preserving reference image from a sketch �s and a text prompt y. The reference image adheres to the outline of the sketch, while also conforming to the textual description. To achieve this, we leverage an additional image conditioned diffusion model �2� (e.g., ControlNet (Zhang et al., 2023a)) to initiate sketch-preserving image synthesis (Chen et al., 2023b). Given time step �, a text prompt y, and a sketch image �s, �2� learn a network �^� to predict the noise added to the noisy image �� with:
为了解决上述问题,我们的解决方案是从草图 �s 和文本提示y创建形状保持参考图像。参考图像符合草图的轮廓,同时也符合文本描述。为了实现这一点,我们利用附加的图像条件扩散模型 �2� (例如,ControlNet(Zhang等人,2023 a))启动草图保留图像合成(Chen等人,2023 b)。给定时间步长 � 、文本提示y和草图图像 �s 、 �2� ,学习网络 �^� 以预测添加到有噪声图像 �� 的噪声,其中:
| (3) | ℒ=𝔼�0,�,y,�s,�∼𝒩(0,1)[‖�^�(��;�,y,�s)−�‖22], |
where ℒ is the overall learning objective of �2�. Note that there are two conditions, i.e., sketch �s and text prompt y, and the noise is estimated as follows:
其中 ℒ 是 �2� 的总体学习目标。注意,存在两个条件,即,草图 �s 和文本提示y,噪声估计如下:
| (4) | �^�(��;�,y,�s)= | ��(��;�) | ||
| +�*(��(��;�,y,�s)−��(��;�)), |
where � is the scale of classifier-free guidance (Nichol et al., 2022a). In summary, �2� can quickly generate a shape-preserving colorful image �ref that not only follows the sketch outline but also respects the textual description, which facilitates the subsequent initialization process.
其中 � 是无分类器指南的量表(Nichol等人,2022 a)。综上所述, �2� 可以快速生成既遵循草图轮廓又尊重文本描述的保形彩色图像 �ref ,便于后续的初始化过程。
3.4.Gaussian Representation Initialization
3.4.高斯表示法
A coarse 3D prior can efficiently offer a solid initial basis for subsequent optimization. To facilitate image-to-3D generation, most existing methods rely on implicit 3D representations such as Neural Radiance Fields (NeRF) (Tang et al., 2023b) or explicit 3D representations such as mesh (Qian et al., 2023). However, NeRF representations are time-consuming and require high computational resources, while mesh representations have complex representational elements. Consequently, 3D Gaussian representation, being simple and fast, is chosen as our initialized 3D prior �0.
粗略的3D先验可以有效地为后续优化提供坚实的初始基础。为了促进图像到3D的生成,大多数现有方法依赖于隐式3D表示,例如神经辐射场(NeRF)(Tang等人,2023 b)或显式3D表示,例如网格(Qian等人,2023)。然而,NeRF表示是耗时的,需要高的计算资源,而网格表示具有复杂的表示元素。因此,选择简单且快速的3D高斯表示作为我们的初始化3D先验 �0 。
Gaussian Initialization with 3D Diffusion Model. 3D Gaussians can be easily converted from a point cloud, so a simple idea is to first obtain an initial point cloud and then convert it to 3D Gaussians (Yi et al., 2023). Therefore, it can be transformed into an image-to-point cloud problem. Currently, many 3D diffusion models use text to generate 3D point clouds (Nichol et al., 2022b). However, we initialize 3D Gaussians �0 from 3D diffusion model �3� (e.g., Shap-E (Jun and Nichol, 2023)) based on the image �ref.
3D扩散模型的高斯分布。3D高斯可以很容易地从点云转换,因此一个简单的想法是首先获得初始点云,然后将其转换为3D高斯(Yi等人,2023)。因此,它可以转化为一个图像到点云的问题。目前,许多3D扩散模型使用文本来生成3D点云(Nichol等人,2022 b)。然而,我们从3D扩散模型 �3� 初始化3D高斯模型 �0 (例如,Shap-E(Jun和Nichol,2023))基于图像 �ref 。
Gaussian Initialization through SDS loss. Alternatively, we can also initialize a Gaussian sphere and optimize it into a coarse Gaussian representation through SDS loss (Tang et al., 2023a). First, we initialize the 3D Gaussians with random positions sampled inside a sphere, with unit scaling and no rotation. At each step, we sample a random camera pose � orbiting the object center, and render the RGB image �RGB� of the current view. Stable-zero123 (Stability AI, 2023) is adopted as the 2D diffusion prior � and the images �RGB� are given as input. The SDS loss is formulated as:
通过SDS损失的高斯分布。或者,我们也可以初始化高斯球,并通过SDS损失将其优化为粗略的高斯表示(Tang等人,2023 a)。首先,我们用球体内的随机采样位置初始化3D高斯,单位缩放,没有旋转。在每一步中,我们对围绕对象中心的随机相机姿态 � 进行采样,并渲染当前视图的RGB图像 �RGB� 。采用Stable-zero 123(Stability AI,2023)作为2D扩散先验 � ,并且给出图像 �RGB� 作为输入。SDS损失公式为:
| (5) | ∇�ℒSDS=𝔼�,�,�[(��(�RGB�;�,�ref,Δ�)−�)∂�RGB�∂�], |
where ��(⋅) is the predicted noise by the 2D diffusion prior �, and Δ� is the relative camera pose change from the reference camera. Finally, we can obtain a coarse Gaussian representation �0 based on the optimization of the 2D diffusion prior �.
其中 ��(⋅) 是2D扩散先验 � 的预测噪声,而 Δ� 是相对于参考相机的相对相机姿态变化。最后,我们可以基于2D扩散先验 � 的优化来获得粗略的高斯表示 �0 。
3.5.Style-Consistent Guidance for Optimization
3.5.风格一致的优化指导
The coarse 3D prior �0 is roughly similar in shape to the input sketch, and its color is not completely consistent with the text description. Specifically, the geometric shape generated in Sec. 3.4 may not exactly fit the outline shape of the input sketch �s, and there is a certain deviation. For example, the input sketch is an upright, cylinder-like, symmetrical lamp, but the coarse 3D Gaussian representation might be a slightly curved, asymmetrical lamp. Moreover, the initial color generated in Sec. 3.4 may not be consistent with the description of the input text. Faced with these problems, we introduce IP-Adapter to generate multi-view style-consistent images as guidance. First, we propose a transfer mechanism in the structural optimization process, which can effectively guide the structure of the 3D Gaussian representation to align with the input sketch outline. Second, we utilize a straightforward MSE loss to improve the color quality, which can effectively align the 3D Gaussian representation with the input text description. Third, we implement a CLIP-based geometric similarity loss as a constraint to guide the shape towards the input sketch.
粗略的3D先验图 �0 在形状上与输入草图大致相似,并且其颜色与文本描述不完全一致。具体地说,在第二节中生成的几何形状。3.4可能与输入草图 �s 的轮廓形状不完全吻合,存在一定的偏差。例如,输入草图是一个直立的圆柱形对称灯,但粗略的3D高斯表示可能是一个略微弯曲的非对称灯。此外,在Sec. 3.4可能与输入文本的描述不一致。针对这些问题,本文引入IP-Adapter生成多视点风格一致的图像作为指导。首先,我们提出了一种在结构优化过程中的转移机制,它可以有效地引导三维高斯表示的结构与输入草图轮廓对齐。 其次,我们利用一个简单的MSE损失来提高颜色质量,这可以有效地将3D高斯表示与输入文本描述对齐。第三,我们实现了一个基于CLIP的几何相似性损失作为一个约束,以引导形状对输入草图。
Multi-view Style-Consistent Images Generation. Due to the rapid and real-time capabilities of Gaussian splatting, acquiring multi-view renderings becomes straightforward. If we can obtain guidance images from these renderings, corresponding to the current viewing angles, they would serve as effective guides for optimization. To achieve this, we introduce the IP-Adapter (Ye et al., 2023), which incorporates an additional cross-attention layer for each cross-attention layer in the original U-Net model to insert image features. Given the image features ��, the output of additional cross-attention 𝐙 is computed as follows:
多视图样式一致的图像生成。由于高斯溅射的快速和实时能力,获取多视图渲染变得简单。如果我们能够从这些渲染图中获得与当前视角相对应的指导图像,它们将作为优化的有效指导。为了实现这一点,我们引入了IP适配器(Ye et al,2023),它为原始U-Net模型中的每个交叉注意层添加了一个额外的交叉注意层,以插入图像特征。给定图像特征 �� ,附加交叉关注 𝐙 的输出计算如下:
| (6) | 𝐙=Attention(𝐐,𝐊�,𝐕�)=Softmax(𝐐𝐊�⊤�)𝐕�, |
where 𝐐=𝐙𝐖𝐪, 𝐊�=��𝐖�′ and 𝐕�=��𝐖�′ are the query, key, and values matrices from the image features. 𝐙 is the query features, and 𝐖�′ and 𝐖�′ are the corresponding trainable weight matrices.
其中 𝐐=𝐙𝐖𝐪 、 𝐊�=��𝐖�′ 和 𝐕�=��𝐖�′ 是来自图像特征的查询、键和值矩阵。 𝐙 是查询特征, 𝐖�′ 和 𝐖�′ 是对应的可训练权重矩阵。
This enhancement enables us to generate multi-view style-consistent images based on the two image conditions of the reference image and the content images, as shown in Figure 3. Specifically, herein we use Stable-Diffusion-v1-5 (Rombach et al., 2022) as our diffusion model basis. Given the reference image �ref and multi-view splatting images as the content images �c, the guidance images �g are estimated as follows:
这种增强使我们能够基于参考图像和内容图像这两种图像条件生成多视图风格一致的图像,如图3所示。具体而言,本文中我们使用Stable-Diffusion-v1-5(Rombach et al,2022)作为我们的扩散模型基础。给定参考图像 �ref 和多视点飞溅图像作为内容图像 �c ,如下估计引导图像 �g :
| (7) | �g=�(�ref,�c,�,�), |
where � is the generator of IP-Adapter, � is the sampling time step of inference, and � ∈ [0, 1] is a hyper-parameter that determines the control strength of the conditioned content image �c.
其中 � 是IP适配器的生成器, � 是推断的采样时间步长,并且 � ∈ [0,1]是确定条件内容图像 �c 的控制强度的超参数。

Figure 3.For each object, the first row shows content images and the second row shows guidance images. Given reference image �ref generated by ControlNet and content images �c rendered from the 3D Gaussians, we generate the guidance images �g as the multi-view style-consistent images.
图3.对于每个对象,第一行显示内容图像,第二行显示指导图像。给定由ControlNet生成的参考图像 �ref 和从3D高斯渲染的内容图像 �c ,我们生成引导图像 �g 作为多视图样式一致的图像。
Camera Projection Progressively. As shown in Figure 2, during the process of Gaussian splatting, our camera projection strategy involves encircling horizontally and vertically. To ensure the stylistic consistency of the generated guidance images, we perform a rotation every 30 degrees for each circle, thereby calculating the guidance images under a progressively changing viewpoint.
摄像机投影逐步进行。如图2所示,在高斯溅射过程中,我们的相机投影策略包括水平和垂直环绕。为了确保生成的引导图像的风格一致性,我们对每个圆每30度旋转一次,从而在逐渐变化的视点下计算引导图像。
Structural Optimization. For image-to-3D generation, when selecting the diffusion prior for SDS loss, existing approaches usually use a diffusion model with image as condition (e.g., Zero-123 (Liu et al., 2023b)). However, we choose to use a diffusion model with text as a condition (e.g., Stable Diffusion (Rombach et al., 2022)). Because the former does not perform well in generating 3D aspects of the invisible parts of the input image, while the latter demonstrates better optimization effects in terms of details and the invisible sections. However, we have to ensure that the reference image plays an important role in the optimization process, so we propose a mechanism of distribution transfer and then use it in subsequent SDS loss calculations. Given guidance images �g and splatting images �c, the transferred images �t are estimated as follows:
结构优化。对于图像到3D生成,当选择SDS损失的扩散先验时,现有方法通常使用以图像为条件的扩散模型(例如,Zero-123(Liu等人,2023 b))。然而,我们选择使用以文本为条件的扩散模型(例如,稳定扩散(Rombach等人,2022))。因为前者在生成输入图像的不可见部分的3D方面表现不佳,而后者在细节和不可见部分方面表现出更好的优化效果。但是,我们必须确保参考图像在优化过程中发挥重要作用,因此我们提出了一种分布转移机制,然后将其用于后续的SDS损失计算。在给定引导图像 �g 和飞溅图像 �c 的情况下,如下估计所传送的图像 �t :
| (8) | �t=�(�g)(�c−�(�c)�(�c))+�(�g), |
where �(⋅) is the mean operation, �(⋅) is the variance operation. The distribution transformation brought about by the transfer mechanism can bring the distribution of splatting images closer to the distribution of guidance images. In this way, we obtain the transfer image �t after distribution migration through guidance image �g and splatting image �c. To update the 3D Gaussian parameters �(�,Σ,�,�), we choose to use the publicly available Stable Diffusion (Rombach et al., 2022) as 2D diffusion model prior � and compute the gradient of the SDS loss via:
其中 �(⋅) 是均值运算, �(⋅) 是方差运算。由传送机构带来的分布变换可以使飞溅图像的分布更接近引导图像的分布。以这种方式,我们通过引导图像 �g 和飞溅图像 �c 获得分布迁移之后的传送图像 �t 。为了更新3D高斯参数 �(�,Σ,�,�) ,我们选择使用公开可用的稳定扩散(Rombach等人,2022)作为2D扩散模型先验 � ,并通过以下方式计算SDS损失的梯度:
| (9) | ∇�ℒS−SDS=𝔼�,�[(�^�(�t;�,�,�s)−�)∂�t∂�], |
where �t is the transfer image, y is text prompt, �^� is similar to Equation 4, � is the sampling time step, �s is the input sketch. In conclusion, through the tailored 3D structural guidance, our Sketch3D can mitigate the problem of geometric inconsistencies.
其中 �t 是传输图像,y是文本提示, �^� 类似于等式4, � 是采样时间步长, �s 是输入草图。总之,通过定制的3D结构指导,我们的Sketch3D可以减轻几何不一致的问题。
Color Optimization. Although through the above structural optimization, we already obtain a 3D Gaussian representation whose geometric structure is highly aligned with the input sketch, some color details still need to be enhanced. To improve the image color quality, we propose to use a simple MSE loss to optimize the 3D Gaussian parameters �. We optimize the splatting image �c to align with the guidance image �g.
色彩优化。虽然通过上述结构优化,我们已经获得了几何结构与输入草图高度一致的3D高斯表示,但一些颜色细节仍然需要增强。为了改善图像颜色质量,我们提出使用简单的MSE损失来优化3D高斯参数 � 。我们优化飞溅图像 �c 以与引导图像 �g 对准。
| (10) | ℒCol=�pose*�linear‖�g−�c‖22, |
where �linear is the linearly increased weight during optimization, calculated by dividing the current step by the total number of iteration steps. �g represents the guidance images obtained from controllable IP-Adapter and �c represents the splatting images from 3D Gaussian. The MSE loss is fast to compute and deterministic to optimize, resulting in fast refinement. Note that �pose is a parameter that changes with viewing angle, as shown in Figure 2, in the horizontal rotation perspective, the value of �pose is cos(�azimuth), in the vertical rotation perspective, the value of �pose is 0.3*cos(�elevation).
其中 �linear 是优化期间线性增加的权重,通过将当前步骤除以迭代步骤的总数来计算。 �g 表示从可控IP适配器获得的引导图像, �c 表示来自3D高斯的飞溅图像。MSE损失的计算速度快,优化确定性强,因此可以快速细化。注意, �pose 是随视角变化的参数,如图2所示,在水平旋转视角下, �pose 的值为 cos(�azimuth) ,在垂直旋转视角下, �pose 的值为 0.3*cos(�elevation) 。
Sketch Similarity Optimization. To ensure that the shape of the sketch can directly guide the optimization of 3D Gaussians, we use the image encoder of CLIP to encode both the sketch and the rendered images, and compute the �2 distance between intermediate level activations of CLIP. CLIP is trained on various image modalities, enabling it to encode information from both images and sketches, without requiring further training. CLIP encodes high-level semantic attributes in the last layer since it was trained on both images and text. One intuitive approach involves leveraging CLIP’s semantic-level cosine similarity loss to use the sketch as a supervisory signal for the shape of rendered images. However, this form of supervision is quite weak. Therefore, to measure a effective geometric similarity loss between the sketch and rendered image, ensuring that the shape of rendered images is more consistent with the input sketch, we compute the �2 distance between the mid-level activations (Vinker et al., 2022) of CLIP:
草图相似性优化。为了确保草图的形状可以直接指导3D高斯的优化,我们使用CLIP的图像编码器对草图和渲染图像进行编码,并计算CLIP中间级激活之间的 �2 距离。CLIP在各种图像模式上进行训练,使其能够对图像和草图中的信息进行编码,而无需进一步的训练。CLIP在最后一层编码高级语义属性,因为它是在图像和文本上训练的。一种直观的方法是利用CLIP的语义级余弦相似性损失,将草图用作渲染图像形状的监督信号。然而,这种监督形式相当薄弱。 因此,为了测量草图和渲染图像之间的有效几何相似性损失,确保渲染图像的形状与输入草图更一致,我们计算CLIP的中级激活之间的 �2 距离(Vinker等人,2022):
| (11) | ℒsketch=�sketch*‖����4(��)−����4(��)‖22, |
where �sketch is a coefficient that controls the weight, ����4(⋅) is the ���� encoder activation at layer 4. Specifically, we use layer 4 of the ResNet101 CLIP model.
其中 �sketch 是控制权重的系数, ����4(⋅) 是层4处的 ���� 编码器激活。具体来说,我们使用ResNet101 CLIP模型的第4层。
4.Experiments
In this section, we first introduce the experiment setup in Sec. 4.1, then present qualitative visual results compared with five baselines and report quantitative results in Sec. 4.2. Finally, we carry out ablation and analytical studies to further verify the efficacy of our framework in Sec. 4.3.
在本节中,我们首先介绍第二节中的实验设置。4.1,然后将定性视觉结果与五个基线进行比较,并在第4.2节中报告定量结果。4.2.最后,我们进行了消融和分析研究,以进一步验证我们的框架的有效性。4.3.
4.1.Experiment Setup 4.1.实验装置
ShapeNet-Sketch3D Dataset. To evaluate the effectiveness of our method and benefit further research, we have collected a comprehensive dataset comprising 3D objects, synthetic sketches, rendered images, and corresponding textual descriptions, which we call ShapeNet-Sketch3D. It contains object renderings of 10 categories from ShapeNet (Chang et al., 2015), and there are 1100 objects in each category. Rendered images from 20 different views of each object are rendered in 512×512 resolution. We extract the edge map of each rendered image using a canny edge detector. The textual descriptions corresponding to each object were derived by posing questions to GPT-4-vision about their rendered images, leveraging its advanced capabilities in visual analysis. Currently, there are no datasets available for paired sketches, rendered images, textual descriptions, and 3D objects. Our dataset serves as a valuable resource for research and experimental validation in sketch-to-3D tasks.
ShapeNet-Sketch 3D数据集。为了评估我们的方法的有效性并有利于进一步的研究,我们收集了一个全面的数据集,包括3D对象,合成草图,渲染图像和相应的文本描述,我们称之为ShapeNet-Sketch 3D。它包含来自ShapeNet的10个类别的对象渲染(Chang et al,2015),每个类别中有1100个对象。来自每个对象的20个不同视图的渲染图像以 512×512 分辨率渲染。我们使用Canny边缘检测器提取每个渲染图像的边缘图。通过向GPT-4-vision提出关于其渲染图像的问题,利用其在视觉分析方面的高级功能,获得了与每个对象对应的文本描述。目前,没有可用于成对草图、渲染图像、文本描述和3D对象的数据集。我们的数据集是草图到3D任务的研究和实验验证的宝贵资源。
Implementation Details. In the shape-preserving reference image generation process, we use control-v11p-sd15-canny (Zhang et al., 2023a) as our diffusion model �2�. In the Gaussian initialization process, we initialize our Gaussian representation with the 3D diffusion model and utilize Shap-E (Jun and Nichol, 2023) as our 3D diffusion model �3�. In the multi-view style-consistent images generation process, we use the stable diffusion image-to-image pipeline (Ye et al., 2023), with a control strength of 0.5. Moreover, we generate two sets of guidance images in two surround modes every 30 steps. In structural optimization, we use stablediffusion-2-1-base (Rombach et al., 2022). The total training steps are 500. For the 3D Gaussians, the learning rates of position � and opacity � are 10−4 and 5×10−2. The color � of the 3D Gaussians is represented by the spherical harmonics (SH) coefficient, with a learning rate of 1.5×10−2. The covariance of the 3D Gaussians is converted into scaling and rotation for optimization, with learning rates of 5×10−3 and 10−3. We select a fixed camera radius of 3.0, y-axis FOV of 50 degree, with the azimuth in [0, 360] degrees and elevation in [0, 360] degrees. The rendering resolution is 512×512 for Gaussian splatting. All our experiments can be completed within 3 minutes on a single NVIDIA RTX 4090 GPU with a batch size of 4.
实施细节。在形状保持参考图像生成过程中,我们使用control-v11 p-sd 15-canny(Zhang et al,2023 a)作为我们的扩散模型 �2� 。在高斯初始化过程中,我们使用3D扩散模型初始化高斯表示,并使用Shap-E(Jun和Nichol,2023)作为3D扩散模型 �3� 。在多视图风格一致的图像生成过程中,我们使用稳定的扩散图像到图像流水线(Ye等人,2023),控制强度为0.5。此外,我们每30步生成两组环绕模式的引导图像。在结构优化中,我们使用稳定扩散-2-1-基(Rombach et al,2022)。总训练步数为500步。对于3D高斯,位置 � 和不透明度 � 的学习率是 10−4 和 5×10−2 。3D高斯的颜色 � 由球谐(SH)系数表示,学习率为 1.5×10−2 。 3D高斯的协方差被转换为缩放和旋转以进行优化,学习率为 5×10−3 和 10−3 。我们选择固定的摄像机半径3.0,y轴FOV为50度,方位角为[0,360]度,仰角为[0,360]度。对于高斯溅射,渲染分辨率为 512×512 。我们所有的实验都可以在3分钟内在单个NVIDIA RTX 4090 GPU上完成,批量大小为4。
Baselines. We extensively compare our method Sketch3D against five baselines: Sketch2Model (Zhang et al., 2021), LAS-Diffusion (Zheng et al., 2023b), Shap-E (Jun and Nichol, 2023), One-2-3-45 (Liu et al., 2023d), and DreamGaussian (Tang et al., 2023a). We do not compare with NeRF based methods, as they typically require a longer time to generate. Sketch2Model is the pioneering method that explores the generation of 3D meshes from sketches and introduces viewpoint judgment to optimize shapes. LAS-Diffusion leverages a view-aware local attention mechanism for image-conditioned 3D shape generation, utilizing both 2D image patch features and the SDF representation to guide the learning of 3D voxel features. Shap-E is capable of generating 3D assets in a short time, but requires extensive training on large-scale 3D datasets. One-2-3-45 employs Zero123 to generate results of the input image from different viewpoints, enabling the rapid creation of a 3D mesh from an image. DreamGaussian integrates 3D Gaussian Splatting into 3D generation and greatly improves the speed.
基线。我们将我们的方法Sketch 3D与五种基线进行了广泛比较:Sketch 2 Model(Zhang等人,2021),LAS扩散(Zheng等人,2023 b),Shap-E(Jun和Nichol,2023),One-2-3-45(Liu等人,2023 d)和DreamGaussian(Tang等人,2023 a)。我们不与基于NeRF的方法进行比较,因为它们通常需要更长的时间来生成。Sketch 2 Model是探索从草图生成3D网格并引入视点判断以优化形状的开创性方法。LAS扩散利用视图感知的局部注意机制来生成图像调节的3D形状,利用2D图像块特征和SDF表示来指导3D体素特征的学习。Shap-E能够在短时间内生成3D资产,但需要在大规模3D数据集上进行广泛的训练。One-2-3-45使用Zero 123从不同的视点生成输入图像的结果,从而能够从图像快速创建3D网格。 DreamGaussian将3D高斯溅射集成到3D生成中,大大提高了速度。
4.2.Comparisons
Qualitative Comparisons. Figure 4 displays the qualitative comparison results between our method and the five baselines, while Figure 1 shows novel-view images generated by our method. Sketch3D achieves the best visual results in terms of shape consistency and color generation quality. As illustrated in Figure 4, the sketch image and the reference image generated in Section 3.3 are chosen as inputs for the latter three baselines. For the same object, the reference image used by the latter three baselines and our method is identical. First, Sketch2Model and LAS-Diffusion only generate shapes and lack color information. Second, Shap-E can generate a rough shape and simple color, but the color details are blurry. Third, One-2-3-45 and DreamGaussian often produce inconsistent shapes and lack color details. All of these results demonstrate the superiority of our method. Additionally, Sketch3D is capable of generating realistic 3D objects in about 3 minutes.
定性比较。图4显示了我们的方法和五个基线之间的定性比较结果,而图1显示了我们的方法生成的新视图图像。Sketch 3D在形状一致性和颜色生成质量方面实现了最佳的视觉效果。如图4所示,第3.3节中生成的草图图像和参考图像被选为后三个基线的输入。对于同一物体,后三个基线和我们的方法使用的参考图像是相同的。首先,Sketch 2 Model和LAS-Diffusion只生成形状,缺乏颜色信息。其次,Shap-E可以生成粗略的形状和简单的颜色,但颜色细节模糊。第三,One-2-3-45和DreamGaussian通常会产生不一致的形状,并且缺乏颜色细节。所有这些结果都证明了我们的方法的优越性。此外,Sketch 3D能够在大约3分钟内生成逼真的3D对象。

Figure 4.Qualitative comparisons between our method and Sketch2Model (Zhang et al., 2021), LAS-Diffusion (Zheng et al., 2023b), Shap-E (Jun and Nichol, 2023), One-2-3-45 (Liu et al., 2023d) and DreamGaussian (Tang et al., 2023a). The input sketches includes sketch images, exterior contour sketches and hand-drawn sketches. Our method achieves the best visual results regarding shape consistency and color generation quality compared to other methods.
图4.我们的方法与Sketch 2 Model(Zhang et al,2021),LAS扩散(Zheng et al,2023 b),Shap-E(Jun和Nichol,2023),One-2-3-45(Liu et al,2023 d)和DreamGaussian(Tang et al,2023 a)之间的定性比较。输入的草图包括草图图像、外部轮廓草图和手绘草图。与其他方法相比,我们的方法在形状一致性和颜色生成质量方面实现了最佳的视觉效果。
Quantitative Comparisons. In Table 1 , we use CLIP similarity (Radford et al., 2021) and structural similarity index measure(SSIM) to quantitatively evaluate our method. We randomly select 5 objects from each category in our ShapeNet-Sketch3D dataset, choose a random viewpoint for each object, and then average the results across all objects. We calculate the CLIP similarity between the final rendered images and the reference image, as well as between the final rendered images and the text prompt. Moreover, we also calculate the SSIM similarity between the final rendered images and the reference image. The results show that our method can better align with the input sketch shape and correspond to the input textual description.
定量比较。在表1中,我们使用CLIP相似性(拉德福等人,2021)和结构相似性指数测度(SSIM)来定量评估我们的方法。我们从ShapeNet-Sketch 3D数据集中的每个类别中随机选择5个对象,为每个对象选择一个随机视点,然后对所有对象的结果进行平均。我们计算最终渲染图像和参考图像之间以及最终渲染图像和文本提示之间的CLIP相似度。此外,我们还计算最终渲染图像和参考图像之间的SSIM相似度。实验结果表明,该方法能够更好地与输入草图形状对齐,并与输入文本描述相对应。
Table 1.Quantitative comparisons on CLIP similarity and Structural Similarity Index Measure (SSIM) with other methods. All these experiments were conducted on our ShapeNet-Sketch3D dataset.
表1. CLIP相似性和结构相似性指数测度(SSIM)与其他方法的定量比较。所有这些实验都在我们的ShapeNet-Sketch 3D数据集上进行。
| Method 方法 | CLIP-Similarity CLIP相似性 | SSIM ↑ | |
|---|---|---|---|
| pic2pic ↑ | pic2text ↑ | ||
| Sketch2Model | 0.597 | 0.232 | 0.712 |
| LAS-Diffusion LAS扩散 | 0.638 | 0.254 | 0.731 |
| Shap-E 形状E | 0.642 | 0.268 | 0.734 |
| One-2-3-45 1-2-3-45 | 0.667 | 0.281 | 0.722 |
| DreamGaussian | 0.724 | 0.294 | 0.793 |
| Sketch3D (Ours) Sketch 3D(我们的) | 0.779 | 0.321 | 0.818 |
4.3.Ablation Study and Analysis
4.3.消融研究和分析
Distribution transfer mechanism in structural optimization. As shown in Figure 5, the distribution transfer mechanism aligns the shape more closely with the input sketch, leading to a coherent structure and color. It demonstrates the mechanism’s effectiveness in steering the generated shape towards the input sketch.
结构优化中的分配转移机制。如图5所示,分布传输机制将形状与输入草图更紧密地对齐,从而产生连贯的结构和颜色。它证明了该机制在将生成的形状转向输入草图方面的有效性。

Figure 5.Ablation study. Two different angles are selected for each object. Red boxes show details.
图5.消融研究。为每个对象选择两个不同的角度。红框显示详细信息。
MSE loss in color optimization. As illustrated in Figure 5, it is evident that the MSE loss contributes to reducing color noise, leading to a smoother overall color appearance. It prove that MSE loss is able to enhance the quality of the generated color.
颜色优化中的MSE损失。如图5所示,很明显,MSE损失有助于减少颜色噪声,从而导致更平滑的整体颜色外观。实验证明,均方误差损失能够提高生成颜色的质量。
CLIP geometric similarity loss in sketch similarity optimization. As shown in Figure 5, the CLIP geometric similarity loss enables the overall shape to more closely align with the shape of the input sketch. This illustrates that the �2 loss in the intermediate layers of CLIP can act as an shape constraint.
草图相似性优化中的CLIP几何相似性损失。如图5所示,CLIP几何相似性损失使整体形状与输入草图的形状更紧密地对齐。这说明CLIP的中间层中的 �2 损失可以充当形状约束。
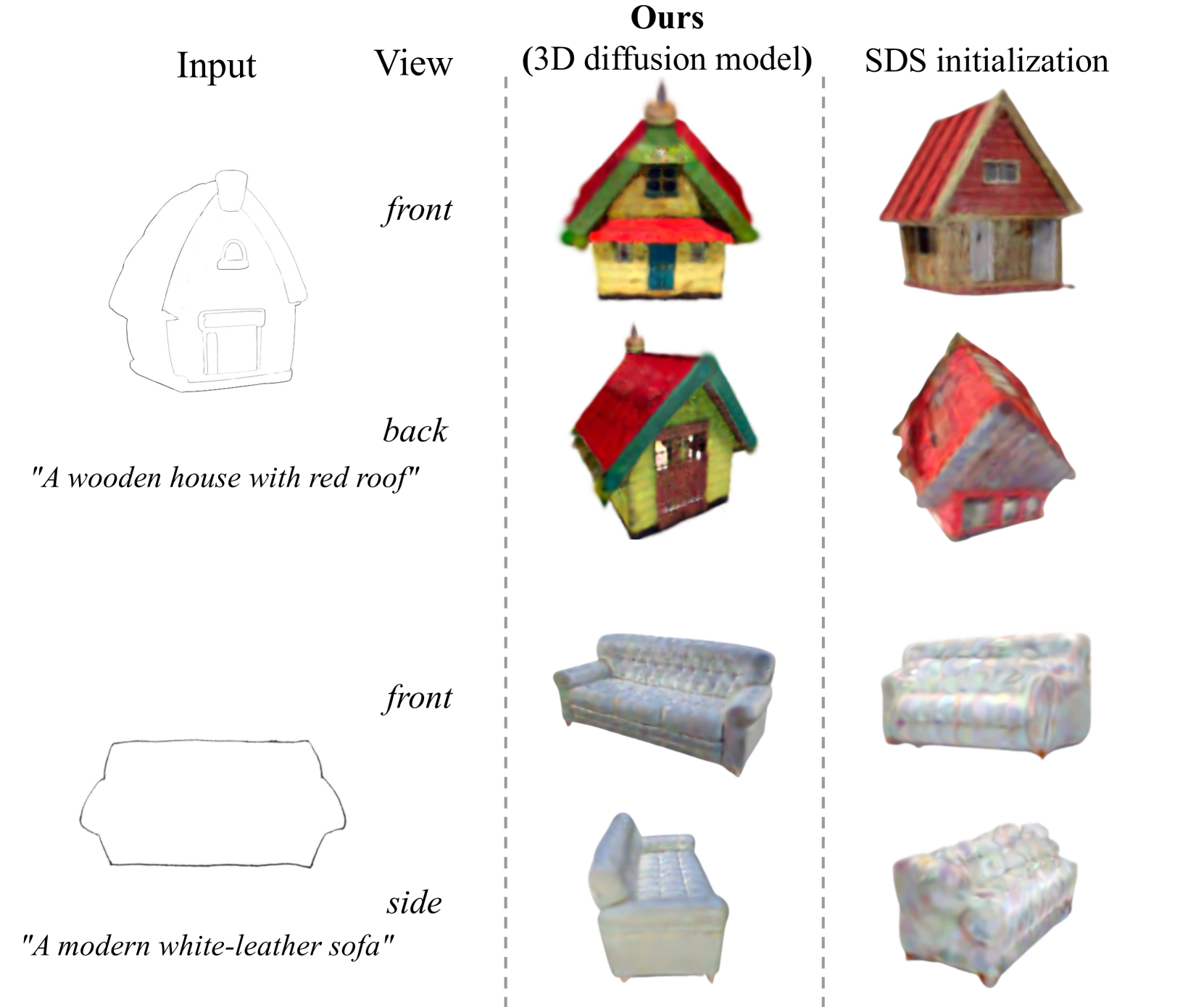
Figure 6.Analytical study of the initialization approach of the 3D Gaussian Representation.
图6.三维高斯表示的初始化方法的分析研究。
Gaussian initialization through SDS loss. As shown in Figure 6, we conducted analytical experiments on the Gaussian initialization method to explore which initialization method is better. It can be seen that Gaussian initialization through SDS loss shows good 3D effects only in the visible parts of the input reference image, while problems of blurriness and color saturation exist in the invisible parts. However, the approach of Gaussian initialization with a 3D diffusion model exhibits better realism from all viewing angles.
通过SDS丢失进行高斯初始化。如图6所示,我们对高斯初始化方法进行了分析实验,以探索哪种初始化方法更好。可以看出,通过SDS损失的高斯初始化仅在输入参考图像的可见部分中显示出良好的3D效果,而在不可见部分中存在模糊和颜色饱和度的问题。然而,具有3D扩散模型的高斯初始化的方法从所有视角表现出更好的真实感。
Hand-drawn sketch visualization results. As shown in Figure 7, to explore the fidelity of outcomes generated from user’s freehand sketches, we visualizes some of the generated results from hand-drawn sketches. We randomly selects three non-artist users to draw three sketches and provides corresponding text prompt. The results show that our method can also achieve good generation quality and consistency for hand-drawn sketches.
手绘草图可视化结果。如图7所示,为了探索从用户的手绘草图生成的结果的保真度,我们可视化了从手绘草图生成的一些结果。我们随机选择三个非艺术家用户绘制三幅草图,并提供相应的文本提示。实验结果表明,该方法也能获得较好的手绘草图生成质量和一致性。
User Study. We additionally conducts a user study to quantitatively evaluate Sketch3D against four baseline methods (LAS-Diffusion, Shap-E, One-2-3-45 and DreamGaussian). We invites 9 participants and presents them with each input and the corresponding 5 generated video results, comprising a total of 10 inputs and the corresponding 50 videos. We ask each participant to rate each video on a scale from 1-5 based on fidelity and consistency criteria. Table 2 shows the results of the user study. Overall, our Sketch3D demonstrates greater fidelity and consistency compared to other four baselines.
用户研究。我们还进行了一项用户研究,以定量评估Sketch 3D与四种基线方法(LAS扩散,Shap-E,One-2-3-45和DreamGaussian)的关系。我们邀请了9名参与者,并向他们展示了每个输入和相应的5个生成的视频结果,总共包括10个输入和相应的50个视频。我们要求每个参与者根据保真度和一致性标准对每个视频进行1-5级评分。表2显示了用户研究的结果。总体而言,与其他四个基线相比,我们的Sketch 3D表现出更高的保真度和一致性。
Table 2.User Study on fidelity and consistency evaluation.
表2.关于保真度和一致性评价的用户研究。
| Method 方法 | Fidelity 保真度 | Consistency 一致性 |
|---|---|---|
| LAS-Diffusion LAS扩散 | 1.82 | 2.86 |
| Shap-E 形状E | 2.67 | 2.92 |
| One-2-3-45 1-2-3-45 | 3.22 | 3.58 |
| DreamGaussian | 3.78 | 3.37 |
| Sketch3D | 4.12 | 3.94 |
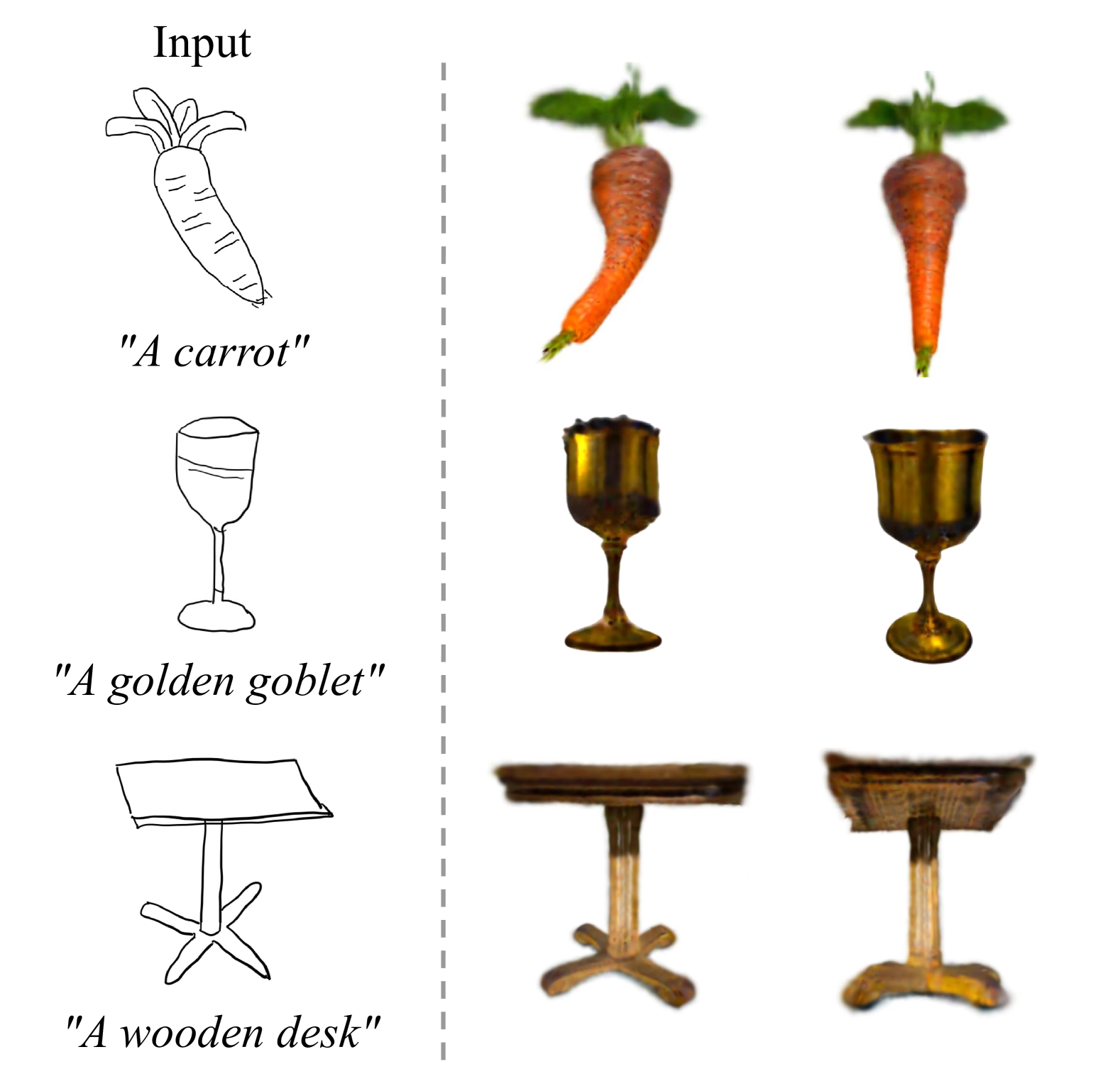
Figure 7.Hand-drawn sketch visualization results.
图7.手绘草图可视化结果。
5.Conclusion
In this paper, we propose Sketch3D, a new framework to generate realistic 3D assets with shape aligned to the input sketch and color matching the text prompt. Specifically, we first instantiate the given sketch to the reference image through the shape-preserving generation process. Second, a coarse 3D Gaussian prior is sculpted based on the reference image, and multi-view style-consistent guidance images could be generated using IP-Adapter. Third, we propose three optimization strategies: a structural optimization using a distribution transfer mechanism, a color optimization using a straightforward MSE loss and a sketch similarity optimization using CLIP geometric similarity loss. Extensive experiments demonstrate that Sketch3D not only has realistic appearances and shapes but also accurately conforms to the given sketch and text prompt. Our Sketch3D is the first attempt to steer the process of sketch-to-3D generation with 3D Gaussian splatting, providing a valuable foundation for future research on sketch-to-3D generation. However, our method also has several limitations. The quality of the reference image depends on the performance of ControlNet, so when the image quality generated by the ControlNet is poor, it will affect our method and impact the overall generation quality. Additionally, for particularly complex or richly detailed sketches, it is difficult to achieve control over the details in the output results.
在本文中,我们提出了Sketch3D,一个新的框架来生成逼真的3D资产与形状对齐的输入草图和颜色匹配的文本提示。具体来说,我们首先通过形状保持生成过程将给定的草图实例化到参考图像。其次,基于参考图像构建粗糙的3D高斯先验,利用IP适配器生成多视点风格一致的制导图像。第三,我们提出了三种优化策略:使用分布传递机制的结构优化,使用简单的MSE损失的颜色优化和使用CLIP几何相似性损失的草图相似性优化。大量的实验表明,Sketch3D不仅具有逼真的外观和形状,而且准确地符合给定的草图和文本提示。 我们的Sketch3D是第一次尝试用3D高斯溅射来引导草图到3D生成的过程,为未来草图到3D生成的研究提供了有价值的基础。然而,我们的方法也有一些局限性。参考图像的质量取决于ControlNet的性能,因此当ControlNet生成的图像质量较差时,它会影响我们的方法并影响整体生成质量。此外,对于特别复杂或细节丰富的草图,很难控制输出结果中的细节。






![[CTF]使用浏览器firefox插件伪装IP地址](https://img-blog.csdnimg.cn/img_convert/740a5f4a61c0b5c1f2972cc5b696079d.png)