本博客参考官方文档进行介绍,全网仅此一家进行中文翻译,走过路过不要错过。
官方网址:https://docs.nvidia.com/cuda/cuda-c-programming-guide/
本文档分成多个博客进行介绍,在本人专栏中含有所有内容:
https://blog.csdn.net/qq_33345365/category_12610860.html
CUDA 12.4为2024年3月2日发表,本专栏开始书写日期2024/4/8,当时最新版本4.1
本人会维护一个总版本,一个小章节的版本,总版本会持续更新,小版本会及时的调整错误和不合理的翻译,内容大部分使用chatGPT 4翻译,内容不引用文献,请自行去文档查看
开始编辑时间:2024/4/8;最后编辑时间:2024/4/8
CUDA 12.4文档1:使用GPU好处&CUDA&可扩展编程模型
第一章 使用GPU好处
图形处理单元(GPU)在相似的价格和功耗范围内,比CPU提供更高的指令吞吐量和内存带宽。许多应用都利用了这些更高的能力,使得在GPU上运行的速度比在CPU上更快。其他计算设备,如FPGA,也非常节能,但比GPU提供的编程灵活性要少得多。
"图形"这个限定词源于二十年前GPU最初创造时的情况,它当时被设计为一种专门的处理器,用来加速图形渲染。由于市场对实时、高清、3D图形的需求不断增长,它已经发展成为一种通用处理器,不仅仅用于图形渲染,还用于处理许多其他工作负载。
GPU和CPU之间的这种能力差异存在是因为它们设计的目标不同。CPU设计为尽可能快地执行一系列的操作,称为线程,并可以并行执行几十个这样的线程,而GPU则设计为能并行执行成千上万个线程(通过分摊较慢的单线程性能来实现更大的吞吐量)。
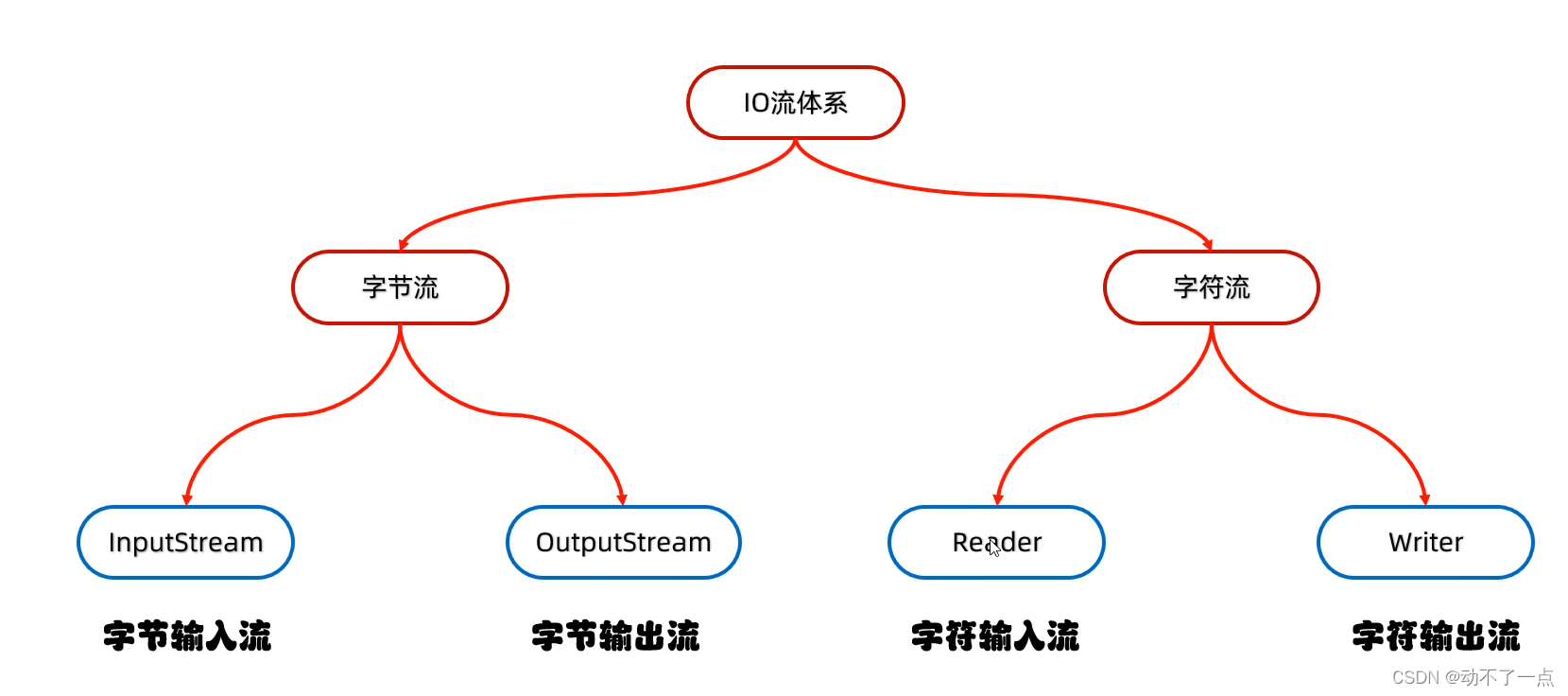
GPU专门为高度并行计算设计,因此设计上更多的晶体管用于数据处理,而不是数据缓存和流控。图示图1展示了CPU和GPU的芯片资源分布的示例。

图1:GPU将更多的晶体管用于数据处理
比如,将更多的晶体管用于数据处理,例如浮点计算,对于高度并行计算是有益的;GPU可以通过计算来隐藏内存访问的延迟,而不是依赖大型数据缓存和复杂的流控来避免长时间的内存访问延迟,这两者在晶体管方面都很昂贵。
通常情况下,一个应用会有并行部分和顺序部分的混合,所以系统是用GPU和CPU混合设计的,以便最大化整体性能。具有高度并行性的应用程序可以利用GPU的大规模并行性质,以实现比在CPU上更高的性能。
第二章 CUDA: 通用并行计算和平台和编程模型
2006年11月,NVIDIA®推出了CUDA®,这是一个通用的并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎,以比在CPU上更有效的方式解决许多复杂的计算问题。
CUDA配备了一个软件环境,允许开发人员使用C++作为高级编程语言。如图2所示,CUDA还支持其他语言、应用程序编程接口或基于指令的方法,例如FORTRAN,DirectCompute,OpenACC等。

图2:GPU计算应用。CUDA旨在支持多种语言和应用编程接口。
第三章 可扩展编程模型
多核CPU和众核GPU的出现意味着主流处理器芯片现在已经是并行系统。挑战在于开发能够透明地扩展其并行性以利用越来越多的处理器核心的应用软件,就像3D图形应用程序透明地扩展其并行性到拥有大量不同核心数量的众核GPU一样。
CUDA并行编程模型旨在克服这个挑战,同时也让熟悉如C等标准编程语言的程序员能够轻松上手。
它的核心是三个关键的抽象概念 - 线程组的层次结构、共享内存和屏障同步 - 这些都以一套最小化的语言扩展简单地暴露给程序员。
这些抽象提供了精细的数据并行性和线程并行性,这些都嵌套在粗粒度的数据并行性和任务并行性中。他们指导程序员将问题分割成可以由线程块并行独立解决的粗粒度子问题,以及将每个子问题进一步细分成可以由块内所有线程协同并行解决的更细小的部分。
这种分解在允许线程在解决每个子问题时进行协作的同时保留了语言表达性,并且同时使其具有自动可扩展性。实际上,每一个线程块都可以按任何顺序在GPU中的任何可用的多处理器上进行调度,同时或顺序执行,这样一个编译后的CUDA程序就可以在任何数量的多处理器上执行,就如图3所示,只有运行时系统需要知道物理多处理器的数量。
这种可扩展的编程模型让GPU架构能够通过简单地扩展多处理器和内存分区的数量来覆盖广泛的市场范围:从高性能的游戏爱好者使用的GeForce GPU和专业的Quadro和Tesla计算产品,到各种价格实惠的主流GeForce GPU。
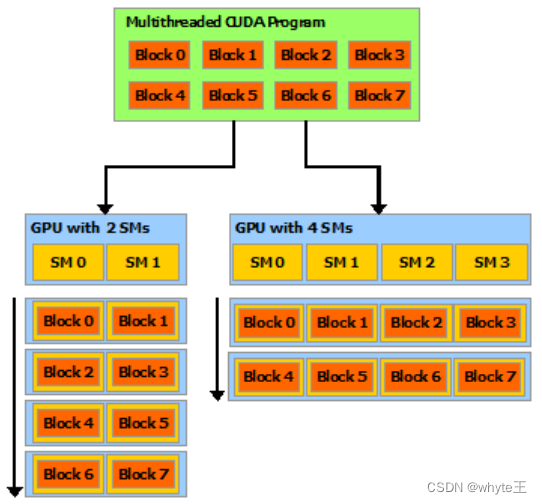
图3:自动扩展
注意:GPU是围绕一组流多处理器(SMs)构建的。一个多线程程序被划分为独立执行的线程块,以便拥有更多多处理器的GPU会自动用比拥有较少多处理器的GPU更短的时间来执行程序。