一、算法简介
深度蒙特卡洛算法是一种使用深度神经网络来进行蒙特卡洛估计的强化学习算法,它最早于2020年在《DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning》被提出用于解决斗地主问题。
深度蒙特卡洛算法使用深度网络拟合每个时刻,智能体状态和采取每种动作的价值函数,即Q value,所以其属于value base 类方法。
1.网络结构
以斗地主问题为例,编码网络由两部分组成,1.对(合法的)出牌动作的编码。2.对玩家手牌和历史出牌信息的编码。
出牌动作编码网络用于对出牌动作对应的矩阵进行特征提取,它的输入是一种出牌动作对应的矩阵,这种出牌动作可以来自当前智能体的所有合法的出牌组合,这种设计的优点有 1.使得模型不需要动作掩码就能对非法动作进行屏蔽,2.适用于于较大动作空间的情况,并且不会因为动作空间的增大而导致参数量明显增加。3.模型能对智能体做出的动作有更深的理解,因为动作也具有了丰富特征,而不仅仅一种one-hot向量。这种对动作的深刻理解有益于其对未曾见过的动作的估计的泛化。如3KKK的牌型很好,即使未见过动作3JJJ,其也能对动作价值有良好的评估。
玩家手牌和历史出牌信息的编码网络用于编码玩家当前持有的手牌,和其余玩家已经打出的手牌,记住已经打出的手牌对于斗地主之类部分可观测的马尔可夫决策过程有重要意义。
两种编码网络对信息进行提取后最终会合并输入一个全连接网络再次进行深层特征提取后最终输出一个形如 1x1 的值,由于编码网络中已经含有状态S和可能采取的动作A,故编码网络输出的值可以作为当前状态s下采取动作a的Q值。遍历所有合法的动作a,就可得agent在当前状态下采取任意动作的Q值。

2.算法更新方式
2.1采样
DMC算法采样类似于DQN,也使用epsilon-greedy方法:以epsilon 的概况v采取随机动作,以1-epsilon的概率采取Q值最大的动作。
2.2损失函数
不同于DQN的每一步获得奖励,自举的对Q值的估计,DMC算法只在每局结束时获得所有的奖励。DMC使用均方差 MSE loss对Q值进行更新。这使得DMC的Q值是无偏估计,但同时也有着高方差的问题,在原文中通过并行采样缓解。
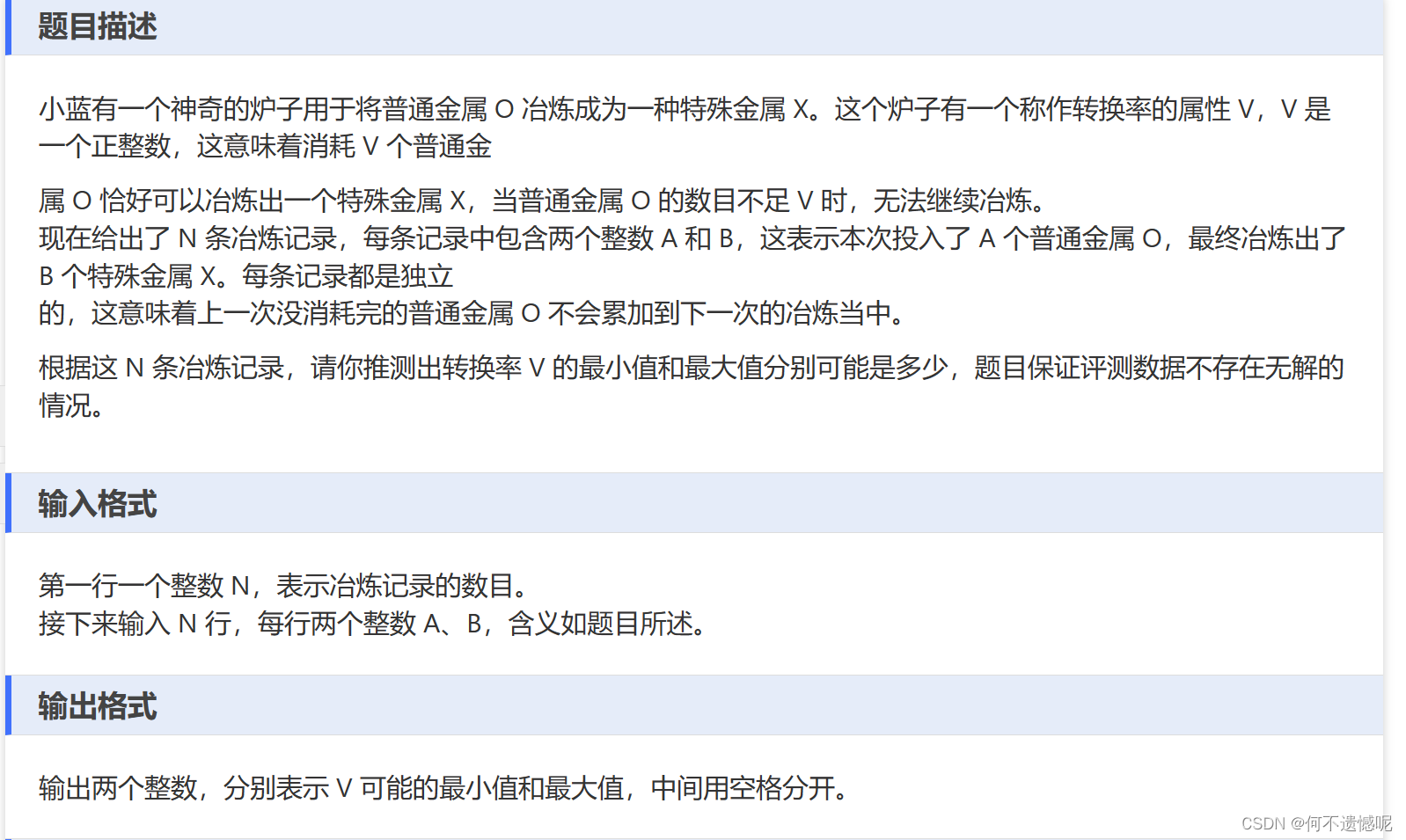
二 使用DMC解决“吹牛”游戏
1.游戏规则
两个玩家、每人三个骰子、游戏开始后,两人同时投骰子,每个人只能看自己的点数。根据自己的点数,轮流喊出自己认为的两人骰子的最大公约数。如先手喊出 2个6,代表两人的六个骰子中至少有两个6点的骰子,后手要么喊出比先手更大的公约数,如3个6,4个5等,要么选择不相信,然后进入结算阶段,如果结算阶段发现两个人骰子中至少有2个6点骰子,则先手胜如果没有则后手胜利。
另外,点数为1的骰子可以作为任意点数参与结算。
2.状态空间和动作空间
动作空间很明确,从1个1 到6个6,外加一个不相信,共37个动作
状态空间,在未结算阶段,由自己的点数和历史动作组成,在结算阶段由自己和对方点数和历史动作组成。
3.环境代码
可以适配DMC算法的吹牛环境代码如下,实现了 reset step等方法,可以对动作和状态编码,根据结局胜负给双方正负奖励。
class BoastingEnv:
def __init__(self, objective):
self.env_id_ran = random.randint(0, 100)
self.objective = objective
self.last_action = None
self.agent_names = ["firsthand", "secondhand"] # AGENT_NAMES#['agent0','agent1']
self.acting_player_position = None
self.player_0 = [1, 5, 2]#[random.randint(0, 5) for i in range(3)]
self.player_1 = [0, 5, 1]#[random.randint(0, 5) for i in range(3)]
self.action_history = np.zeros((4, 6, 7)) # ((6 * 6 + 1, 2))
self.end_action = np.zeros((6, 7))
self.end_action[0, 6] = 1
# self.action_queue
self.infoset0 = {"player_position": "firsthand",
'pos_name': 'firsthand',
"legal_action": self.get_legal_action(),
"player_points": self.get_point_mat(self.obs2state(self.player_0)),
"other_points": np.zeros((6, 7)),
"card_play_action_seq": np.zeros((2, 6 * 7 * 2))}
self.infoset1 = {"player_position": "secondhand",
'pos_name': 'secondhand',
"legal_action": self.get_legal_action(),
"player_points": self.get_point_mat(self.obs2state(self.player_1)),
"other_points": np.zeros((6, 7)),
"card_play_action_seq": np.zeros((2, 6 * 7 * 2))
}
logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.DEBUG,
filename='test.log',
filemode='a')
self.logger = logging.getLogger('inference')
def update_action_seq(self, action):
self.action_history = np.concatenate((self.action_history, action.reshape(1, action.shape[0], action.shape[1])))
self.action_history = self.action_history[1:, :, :]
def get_acting_player_position(self):
if self.acting_player_position == None:
self.acting_player_position = 'firsthand'
elif self.acting_player_position == 'firsthand':
self.acting_player_position = 'secondhand'
else:
self.acting_player_position = 'firsthand'
def obs2state(self, points):
return points#[p - 1 for p in points]
def get_legal_action(self, fist_hand_reset=False):
# 动作一共37个,可用 6*7 的矩阵编码表示,并作为之后输入的向量形式
# action_list 从小到大的排列方式
# 先手的选手合法动作中要屏蔽掉结束动作
action_list = [np.zeros((7, 7)) for i in range(37)]
action_list[-1][0, 6] = 1
for i in range(6):
for j in range(6):
if i * 6 + j >= len(action_list):
break
action_list[i * 6 + j][:i + 1, j, ] = 1
action_list = [mat[:6, :] for mat in action_list]
if fist_hand_reset:
return action_list[:-1]
if self.last_action is None:
return action_list
else:
for idx, array in enumerate(action_list):
if np.array_equal(array, self.last_action):
return action_list[(idx + 1) % 37:]
def get_point_mat(self, points):
mat = np.zeros((6, 7))
# print("points",points)
for p in points:
line = 0
while mat[line, p - 1] == 1:
line += 1
mat[line, p] = 1
return mat
def reset(self):
"""重置两个玩家手里的骰子
x_batch 是一批特征(不包括历史动作)。它还编码了动作特征。 [参考斗地主,视点数为手牌、输入所有动作组合、点亮所有合法的动作]
pos_name 是当前环境正在做动作/下一个要做动作的玩家名,是变化的
player_position 是玩家名、是固定的
:return:
"""
self.agent_names = ["firsthand", "secondhand"] # AGENT_NAMES#['agent0','agent1']
self.player_0 =[random.randint(0, 5) for i in range(3)]
self.player_1 = [random.randint(0, 5) for i in range(3)]
print("new_game firsthand dice {} second hand dice {}".format(self.player_0,self.player_1))
self.acting_player_position = 'firsthand'
self.obs = {0: self.player_0, 1: self.player_1}
# print("player1 dice", self.player_1)
legal_actions = [(i, j) for i in range(1, 7) for j in range(1, 7)] + [(1, 7)]
leg_action_mat = np.zeros((6, 7))
leg_action_mat[0, 5] = 1
leg_action_mat[1, 5] = 1 # 两个六
# 将action 并上 state
# state_list = [(for i in len(sorted(self.player_0))]
state_mat = np.zeros((1, 6, 7))
for i in self.player_0:
j = 0
while state_mat[0, j, i] != 0:
j += 1
state_mat[0, j, i] = 1
# todo 先手后手用一个模型还是不同模型???似乎应该用同一个模型?
# history_acts = np.zeros((38, 6, 7))
self.infoset0 = {"player_position": "firsthand",
'pos_name': 'firsthand',
"legal_action": self.get_legal_action(fist_hand_reset=True),
"player_points": self.get_point_mat(self.obs2state(self.player_0)),
"other_points": np.zeros((6, 7)),
"card_play_action_seq": np.zeros((2, 6 * 7 * 2))}
self.infoset1 = {"player_position": "secondhand",
'pos_name': 'secondhand',
"legal_action": self.get_legal_action(),
"player_points": self.get_point_mat(self.obs2state(self.player_1)),
"other_points": np.zeros((6, 7)),
"card_play_action_seq": np.zeros((2, 6 * 7 * 2))
}
return get_obs(self.infoset0) #
def cmd2action(self, cmd):
return cmd
def decide_the_winner(self, action0):
# 进入这个函数说明acting_player_position喊了结束(不信),win_flag
reward = {0: 0, 1: 0}
done = False
last_cmd = self.action_history[-2, :, :]
indices = np.where(last_cmd == 1)
# print('indices',indices)
target_dice_num = len(indices[0])
target_dice_point = int(indices[1][0])
dice_set = self.player_0 + self.player_1
replaced_dice_set = [target_dice_point if dice == 0 else dice for dice in dice_set]
real_dice_count = replaced_dice_set.count(target_dice_point)
# target_dice_count = last_cmd[1][0]
real_less_than_boasting = target_dice_num <= real_dice_count # 代表上家是否赢得比赛
if self.acting_player_position == "firsthand":
reward[0] = -1 if real_less_than_boasting else 1 # 1-win_flag
reward[1] = 1 if real_less_than_boasting else -1 # int(win_flag)
else:
reward[0] = 1 if real_less_than_boasting else -1 # int(win_flag)
reward[1] = -1 if real_less_than_boasting else 1 # 1-win_flag
# print("重置 reward ",reward,replaced_dice_set)
# print("reward", reward)
return reward, True
def step(self, cmd):
"""轮流输入两个各自的动作,并将其动作加入obs中
Arg:
cmd: 长度为2的元组,第一位表示玩家0或者1,第二位为长度为2的元组,表示对应玩家给出的动作,如玩家0,做出动作四个2 (0,(4,2)),
定义'开'动作为(6,7)
Return:
obs: 长为2的字典,每个值是长度为2的元组,第一位为长度为6的列表,表示双方手中的骰子点数,当回合未结束时只可知道自己的三个,形式[1,2,3,0,0,0,],
当做‘开’动作后即揭示双方的骰子如[1,2,3,1,2,3];第二位为双方的历史动作列表 [(0,(4,2),(1,(5,2)]
输入的cmd的玩家为
reward: 收到动作‘开’时,判断胜负,返回双方的奖励,胜1,负-1
"""
action0 = self.cmd2action(cmd)
self.last_action = action0
print("{} {}说 {}个{}".format(self.env_id_ran, self.acting_player_position, np.where(action0 == 1)[0][-1] + 1,
np.where(action0 == 1)[1][-1]), end=" ")
print("legal_action {} {}".format(len(self.infoset0['legal_action']), len(self.infoset1['legal_action'])))
self.logger.info("{} {}说 {}个{} legal_action {} {}".format(self.env_id_ran, self.acting_player_position,
np.where(action0 == 1)[0][-1] + 1,
np.where(action0 == 1)[1][-1] + 1,
len(self.infoset0['legal_action']),
len(self.infoset1['legal_action'])))
# self.action_history.append(action0)
self.update_action_seq(action0)
reward = {0: 0, 1: 0}
done = False
if np.array_equal(cmd, self.end_action):
# 是否进入结束状态
# print("real dice", self.player_0, self.player_1)
reward, done = self.decide_the_winner(action0)
# dict_keys(['position', 'x_batch', 'z_batch', 'legal_actions', 'x_no_action', 'z'])
if self.acting_player_position == 'firsthand':
# 输出pos_name(下一step要做动作的玩家) 要和 其他信息 对应
# self.infoset0['legal_action'] = self.get_legal_action()
self.infoset1['card_play_action_seq'] = self.action_history
self.infoset1['legal_action'] = self.get_legal_action()
self.get_acting_player_position()
self.infoset1['pos_name'] = self.acting_player_position
obs = get_obs(self.infoset1)
return obs, reward[0], done, {}
else:
self.infoset0['legal_action'] = self.get_legal_action()
self.infoset0['card_play_action_seq'] = self.action_history
self.get_acting_player_position()
self.infoset0['pos_name'] = self.acting_player_position
obs = get_obs(self.infoset0)
return obs, reward[0], done, {}4.效果展示和评估
效果展示
损失函数

获得回报
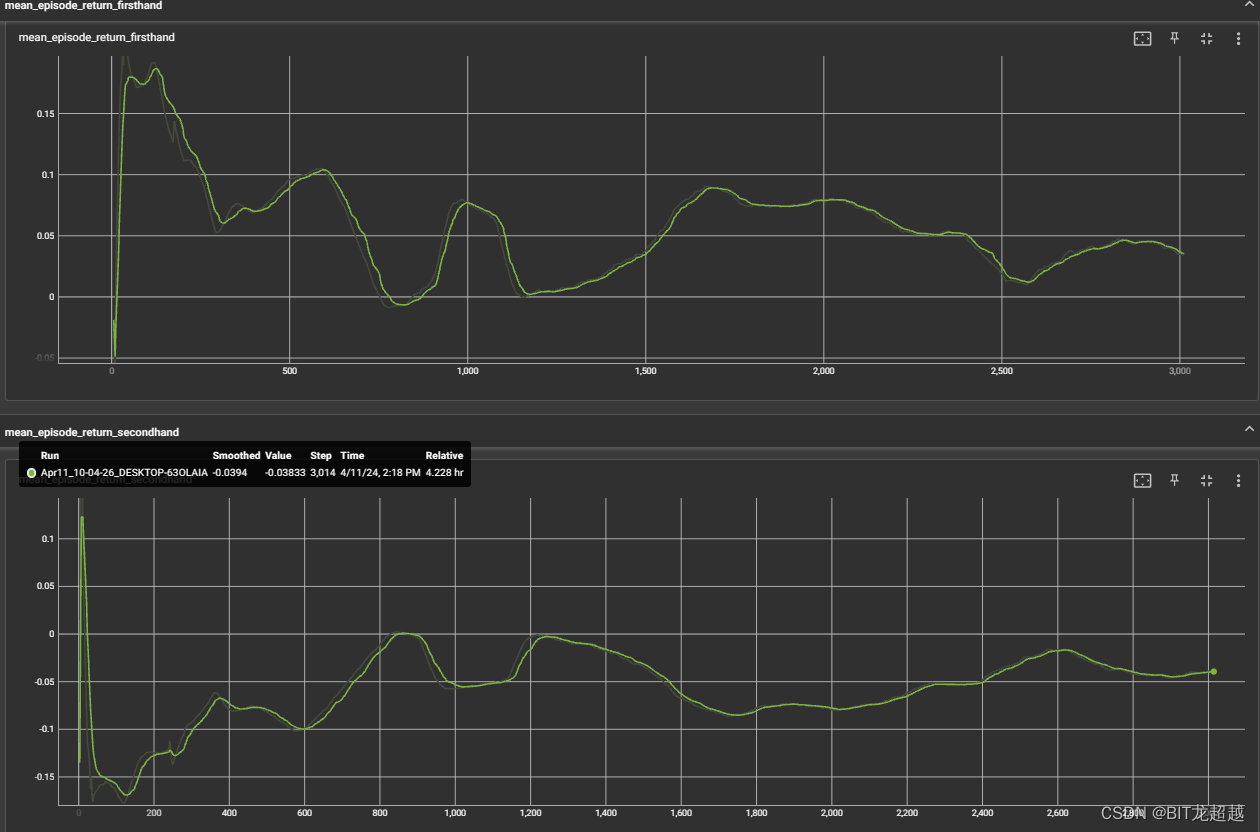 由于两方都是强化学习模型,且网络和更新参数都相同,训练过程中return接近于0较为合理,并且可见,在初期随机探索之后firsthand的return始终保持在大于0的水平,可见改游戏有一定的先手优势。
由于两方都是强化学习模型,且网络和更新参数都相同,训练过程中return接近于0较为合理,并且可见,在初期随机探索之后firsthand的return始终保持在大于0的水平,可见改游戏有一定的先手优势。
推演视频demo
关于我与robot扔骰子玩吹牛被灌了六杯酒这件事
评估
经四小时训练后的先手模型,与笔者对战十局后,笔者胜三局,模型胜七局。对局日志如下,从日志可见模型不仅仅评估每种类型状态出现概率,其动作也具有一定欺骗性。
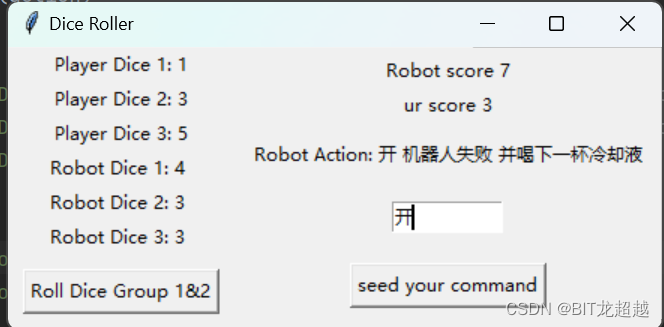
new_game firsthand dice [2, 3, 5] second hand dice [5, 3, 5]
31 firsthand说 2个4 legal_action 36 37
2个5
31 secondhand说 2个5 legal_action 36 26
31 firsthand说 3个4 legal_action 25 26
3个5
31 secondhand说 3个5 legal_action 25 20
31 firsthand说 1个6 legal_action 19 20
new_game firsthand dice [1, 2, 3] second hand dice [3, 0, 0]
31 firsthand说 3个1 legal_action 36 37
4个1
31 secondhand说 4个1 legal_action 36 23
31 firsthand说 1个6 legal_action 17 23
new_game firsthand dice [0, 2, 3] second hand dice [0, 1, 0]
31 firsthand说 2个5 legal_action 36 37
3个1
31 secondhand说 3个1 legal_action 36 25
31 firsthand说 4个1 legal_action 23 25
5个1
31 secondhand说 5个1 legal_action 23 17
31 firsthand说 1个6 legal_action 11 17
new_game firsthand dice [4, 4, 3] second hand dice [4, 2, 1]
31 firsthand说 2个5 legal_action 36 37
开
31 secondhand说 1个6 legal_action 36 25
new_game firsthand dice [0, 2, 3] second hand dice [5, 0, 3]
31 firsthand说 2个5 legal_action 36 37
3个3
31 secondhand说 3个3 legal_action 36 25
31 firsthand说 4个3 legal_action 21 25
4个5
31 secondhand说 4个5 legal_action 21 15
31 firsthand说 1个6 legal_action 13 15
new_game firsthand dice [1, 3, 0] second hand dice [4, 3, 2]
31 firsthand说 2个5 legal_action 36 37
3个5
31 secondhand说 3个5 legal_action 36 25
31 firsthand说 1个6 legal_action 19 25
new_game firsthand dice [4, 4, 5] second hand dice [4, 5, 4]
31 firsthand说 2个5 legal_action 36 37
3个5
31 secondhand说 3个5 legal_action 36 25
31 firsthand说 1个6 legal_action 19 25
new_game firsthand dice [1, 2, 2] second hand dice [3, 1, 0]
31 firsthand说 3个1 legal_action 36 37
4个1
31 secondhand说 4个1 legal_action 36 23
31 firsthand说 5个1 legal_action 17 23
开
31 secondhand说 1个6 legal_action 17 11
new_game firsthand dice [3, 1, 5] second hand dice [5, 1, 4]
31 firsthand说 3个1 legal_action 36 37
3个2
31 secondhand说 3个2 legal_action 36 23
31 firsthand说 1个6 legal_action 22 23
new_game firsthand dice [5, 2, 2] second hand dice [3, 5, 4]
31 firsthand说 2个4 legal_action 36 37
2个5
31 secondhand说 2个5 legal_action 36 26
31 firsthand说 3个5 legal_action 25 26
4个5
31 secondhand说 4个5 legal_action 25 19
31 firsthand说 1个6 legal_action 13 19
new_game firsthand dice [4, 3, 3] second hand dice [1, 3, 5]
31 firsthand说 2个5 legal_action 36 37
3个2
31 secondhand说 3个2 legal_action 36 25
31 firsthand说 3个5 legal_action 22 25
开
31 secondhand说 1个6 legal_action 22 19
三 改进展望
通过与真人对战发现,模型在最开始几局可以凭借欺骗获胜,但在10局之后,人类玩家能够逐渐掌握其动作策略的惯性,及时调整自身策略与之相对。如,玩家发现RL模型在有一个6时往往会叫2个6,真对这一惯性,玩家在确认自己无6的情况下调整策略为直接开牌,取得对局胜利。
对此问题,一种可能的解决方案是,在每局结束时不清空state张量,而将最新state加在旧的张量的最后一维,使模型具有跨对局的记忆能力,以期其获得玩家策略调整时,自身策略随之调整的能力
四 参考文献
[1] Zha, Daochen et al. “DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning.” ICML (2021).