Diffusion models代码解读:入门与实战
前言:作为内容生产重要的一部分,生成相似图像是一项有意义的工作,例如很多内容创作分享平台单纯依赖用户贡献的图片已经不够了,最省力的方法就是利用已有的图片生成相似的图片作为补充。这篇博客详细解读基于Stable Diffusion生成相似图片的原理和代码。
目录
原理详解
代码实战
环境安装
代码运行
参数解读
快速体验
效果展示
代码解读
模型加载
图像加噪
分类器引导
原理详解
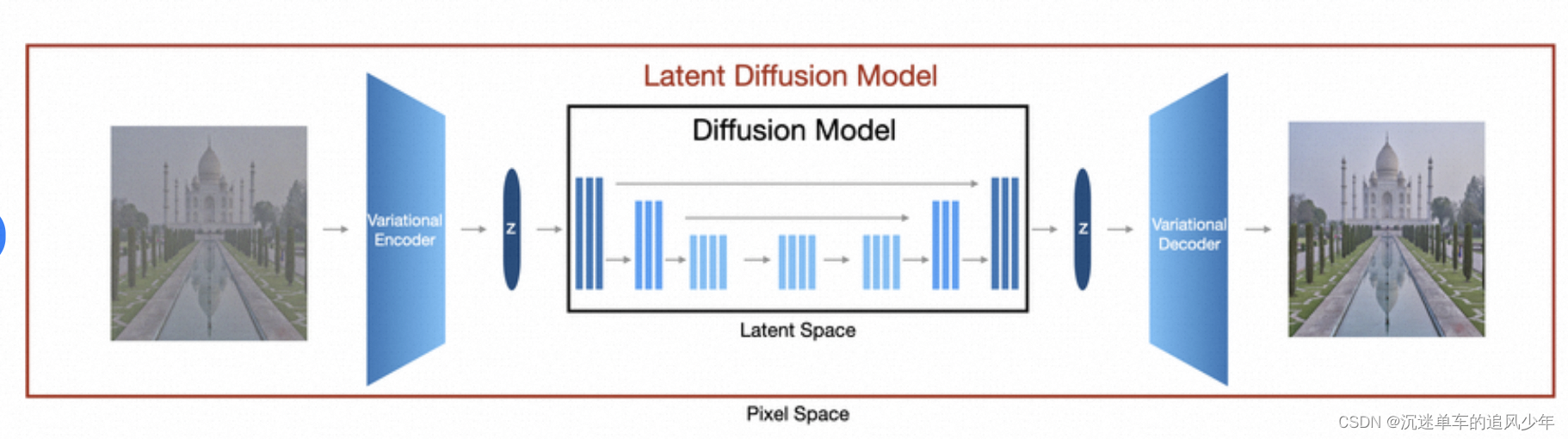
首先读者需要熟悉Stable Diffusion的原理,这部分的可以参考我之前的博客:
Diffusion models代码实战:从零搭建自己的扩散模型_diffusion model 自己-CSDN博客
在Stable Diffusion 中,latent域注入了text condition;在相似图像生成的任务中,把这个text condition替换成Image conditon:
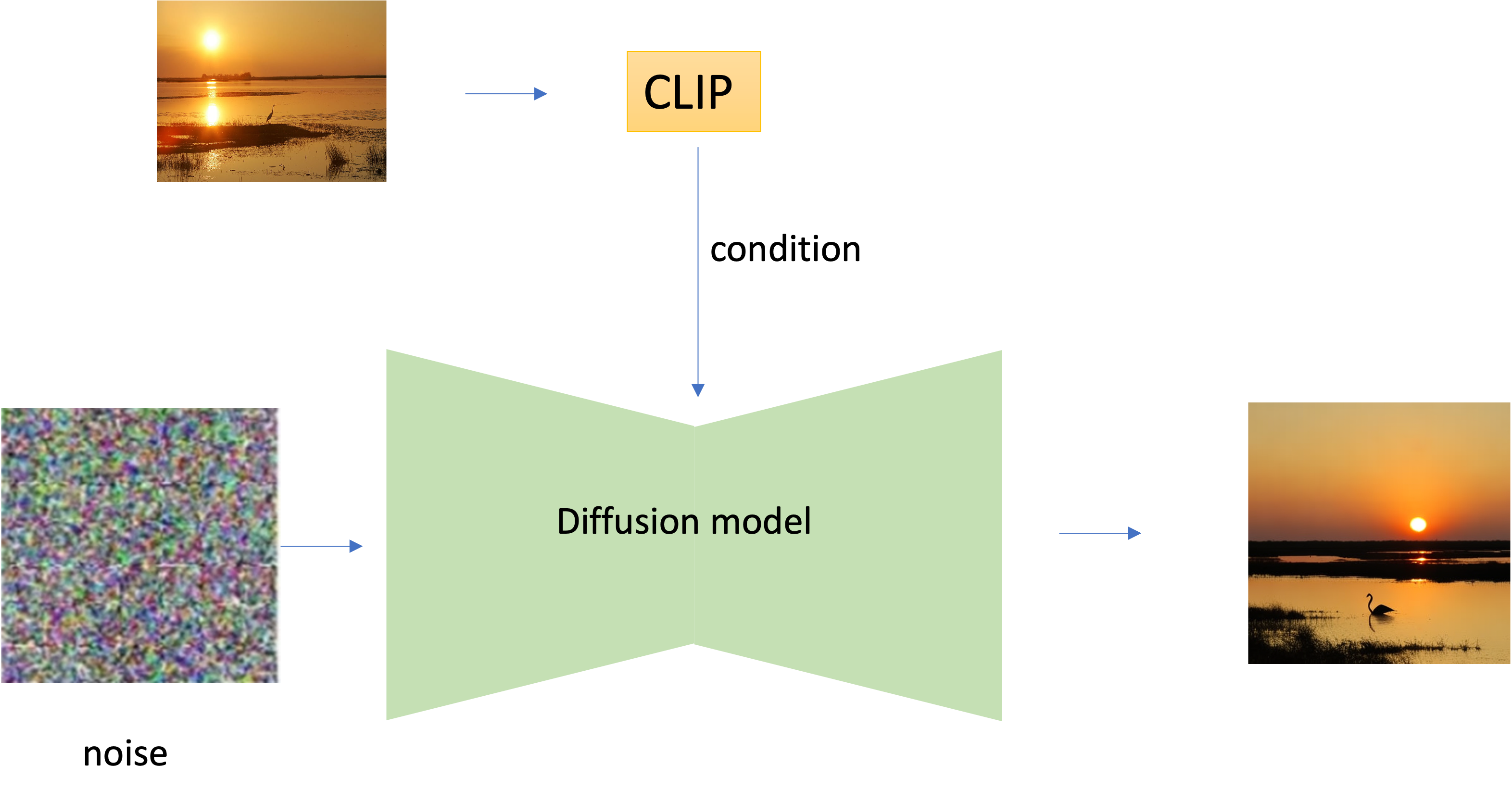
推理的时候,会先在图片中加入噪声,这个添加噪声的程度会用noise_level参数控制。然后把这个加噪过的图片embedding输入到模型中。
原理就这么简单……
代码实战
环境安装
pip install git+https://github.com/lllcho/image_variation.git
pip install modelscope代码运行
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
from PIL import Image
from image_variation import modelscope_warpper
model = 'damo/cv_image_variation_sd'
pipe = pipeline('image_variation_task', model=model, device='gpu',auto_collate=False,model_revision='v1.1.0')
out=pipe('https://vision-poster.oss-cn-shanghai.aliyuncs.com/lllcho.lc/data/test_data/sunset-landscape-sky-colorful-preview.jpg')
imgs=out[OutputKeys.OUTPUT_IMGS]
imgs[0].save(f'result.jpg')参数解读
pipeline调用时的可调参数:
num_inference_steps: int, 默认为20
guidance_scale:float, 默认5.0
num_images_per_prompt:默认为1,每次调用返回几张图,可根据显存大小调整
seed:默认为None,int类型,取值范围[0, 2^32-1]
height::默认值512
width:默认值512
noise_level: int,默认值为0, 取值范围[0,999],表示像输入图像中加入噪声,值越大噪声越多,生成结果与输入图像的相似度越低快速体验
https://modelscope.cn/studios/iic/image_variation/summary
效果展示
输入的图像:

输出的图像


代码解读
代码地址:https://modelscope.cn/studios/iic/image_variation/summary
模型加载
scheduler = UniPCMultistepScheduler(beta_start=0.00085,beta_end=0.012,beta_schedule='scaled_linear')
vae = AutoencoderKL.from_pretrained(ckpt_dir, subfolder='vae')
vae.eval()
unet = UNet2DConditionModel.from_pretrained(ckpt_dir, subfolder='unet')
cond_model, preprocess_train, preprocess_val = open_clip.create_model_and_transforms('ViT-H-14',
pretrained=osp.join(ckpt_dir,'CLIP-ViT-H-14-laion2B-s32B-b79K/open_clip_pytorch_model.bin') 图像加噪
对输入的图片embedding加噪后输入到模型中:
def noise_image_embeddings(self,image_embeds,noise_level,generator=None):
noise = randn_tensor(image_embeds.shape, generator=generator, device=image_embeds.device, dtype=image_embeds.dtype)
noise_level = torch.tensor([noise_level] * image_embeds.shape[0], device=image_embeds.device)
meanstd=torch.from_numpy(np.load(self.norm_file)[None]).to(device=image_embeds.device, dtype=image_embeds.dtype)
mean,std=torch.chunk(meanstd,2,dim=1)
#scale
image_embeds-=mean
image_embeds/=std
image_embeds=self.scheduler.add_noise(image_embeds,noise,noise_level)
#unscale
image_embeds*=std
image_embeds+=mean
return image_embeds分类器引导
和text condition 一样,这里也有“negative prompt”的分类器引导。
图像的“negative prompt”是用masked image替代的,maked image用了一个图片值全0的图片表示:
mask=torch.ones(2,1,height//8,width//8,device=self.device,dtype=self.dtype)
masked_img=torch.zeros(2,3,height,width,device=self.device,dtype=self.dtype)
masked_image_latents = self.vae.encode(masked_img).latent_dist.sample()
masked_image_latents = masked_image_latents * self.vae.config.scaling_factor
mask=mask.repeat(num_images_per_prompt,1,1,1)
masked_image_latents=masked_image_latents.repeat(num_images_per_prompt,1,1,1)完整的推理代码如下:
@torch.no_grad()
def __call__(self,
image,
num_inference_steps=20,
guidance_scale=5.0,
num_images_per_prompt=1,
seed=None,
height=512,
width=512,
noise_level: int=0,
):
if seed is None:
seed=random.randint(0,2**32-1)
set_seed(seed)
self.scheduler.set_timesteps(num_inference_steps, device=self.device)
timesteps = self.scheduler.timesteps
mask=torch.ones(2,1,height//8,width//8,device=self.device,dtype=self.dtype)
masked_img=torch.zeros(2,3,height,width,device=self.device,dtype=self.dtype)
masked_image_latents = self.vae.encode(masked_img).latent_dist.sample()
masked_image_latents = masked_image_latents * self.vae.config.scaling_factor
mask=mask.repeat(num_images_per_prompt,1,1,1)
masked_image_latents=masked_image_latents.repeat(num_images_per_prompt,1,1,1)
latents = randn_tensor((num_images_per_prompt,4,height//8,width//8),device=self.device, generator=None,dtype=self.dtype)
latents = latents * self.scheduler.init_noise_sigma
cond_image=image
clip_img=self.preprocess(read_img(cond_image).convert('RGB')).unsqueeze(0)
cond_embedding=self.cond_model.encode_image(clip_img.to(self.device,self.dtype)).to(self.dtype)
cond_embedding=cond_embedding.repeat(num_images_per_prompt,1,1)
if noise_level>0:
cond_embedding=self.noise_image_embeddings(cond_embedding,noise_level)
cond_embedding=torch.cat([cond_embedding*0,cond_embedding])
for i, t in enumerate(timesteps):
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
noise_pred = self.unet(latent_model_input,t,encoder_hidden_states=cond_embedding,cross_attention_kwargs={}).sample
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, t, latents, **{}).prev_sample
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents.to(self.dtype)).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
image = (image * 255).round().astype("uint8")
imgs=[Image.fromarray(img) for img in image]
return imgs