各种拟合算法整理
- 1. 最小二乘法
- 2. 霍夫变换
- 3. RANSAC算法
本篇将介绍最小二乘法(Least Square)、霍夫变换(Hough Transform)和RANSAC(random sample consensus,随机抽样一致性算法)算法的原理、应用和代码。
如果已经知道了一组可靠的点,可以直接使用最小二乘法完成拟合;如果点集中包含少量的噪声,建议使用加强版的最小二乘法,霍夫变换以及RANSAC算法;如果点集中包含大量噪声,推荐使用霍夫变换和RANSAC算法。
1. 最小二乘法
最小二乘法是一种常用的数学方法,用于拟合数据点到一个数学模型,并求解模型的参数,使得拟合数据点与模型之间的误差平方和最小化。基础版本的原理如下:
- 拟合模型: 假设有一组数据点 ( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi), 我们希望将这些数据点拟合到一个数学模型 y = f ( x ; θ ) y=f(x ; \theta) y=f(x;θ) , 其中 θ \theta θ 是模型的参数, 可以是一个或多个参数。
- 误差计算: 对于每个数据点 ( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi) , 计算其预测值 y ^ i = f ( x i ; θ ) \hat{y}_{i}=f\left(x_{i} ; \theta\right) y^i=f(xi;θ) 与实际值 y i y_{i} yi 之间的误差, 通常采用平方误差 e i = ( y i − y ^ i ) 2 e_{i}=\left(y_{i}-\hat{y}_{i}\right)^{2} ei=(yi−y^i)2 。
- 最小化误差:最小二乘法的核心思想是通过最小化误差平方和来确定模型的参数,即通过优化问题:
min θ ∑ i = 1 n ( y i − f ( x i ; θ ) ) 2 \min _{\theta} \sum_{i=1}^{n}\left(y_{i}-f\left(x_{i} ; \theta\right)\right)^{2} θmini=1∑n(yi−f(xi;θ))2
求解使得误差平方和最小的参数 θ \theta θ。
也可以这样描述基础版的最小二乘法: 假设有一组数据点
(
x
i
,
y
i
)
\left(x_{i}, y_{i}\right)
(xi,yi),通过这些点拟合出一个直线
a
x
+
b
y
+
c
=
0
ax+by+c=0
ax+by+c=0,其向量
n
=
[
a
,
b
,
c
]
n = [a,b,c]
n=[a,b,c],且
∣
∣
n
∣
∣
2
=
1
||n||_2=1
∣∣n∣∣2=1。可以将最小二乘法理解为通过使数据点到拟合直线的距离和最小化来确定直线的最佳拟合
E
=
∑
i
=
1
n
(
a
x
i
+
b
y
i
+
c
)
2
E=\sum_{i=1}^{n}\left(a x_{i}+b y_{i}+c\right)^{2}
E=∑i=1n(axi+byi+c)2。可以这样描述优化目标:
x
^
=
[
a
^
,
b
^
,
c
^
]
T
=
min
x
∥
A
x
∥
2
2
, s.t.
∥
x
∥
2
=
1
A
=
[
x
1
y
1
1
⋮
⋮
⋮
x
n
y
n
1
]
,
x
=
[
a
,
b
,
c
]
T
\begin{array}{c} \hat{\mathbf{x}}=[\hat{a}, \hat{b}, \hat{c}]^{T}=\min _{\mathbf{x}}\|A \mathbf{x}\|_{2}^{2} \text {, s.t. }\|\mathbf{x}\|_{2}=1 \\ A=\left[\begin{array}{ccc} x_{1} & y_{1} & 1 \\ \vdots & \vdots & \vdots \\ x_{n} & y_{n} & 1 \end{array}\right], \mathbf{x}=[a, b, c]^{T} \end{array}
x^=[a^,b^,c^]T=minx∥Ax∥22, s.t. ∥x∥2=1A=
x1⋮xny1⋮yn1⋮1
,x=[a,b,c]T
目的就是,得到最优的
[
a
,
b
,
c
]
。
[a,b,c]。
[a,b,c]。很明显对于这种问题,结合谱定理和瑞利商,可以知道
a
,
b
,
c
{a,b,c}
a,b,c为矩阵
A
T
A
A^TA
ATA的最小特征值对应的单位特征向量。
对于线性模型为
A
x
=
b
Ax=b
Ax=b的问题,优化目标为:
x
^
=
min
x
∥
A
x
−
b
∥
2
2
,
A
∈
R
n
×
m
,
x
∈
R
m
,
b
∈
R
n
\hat{\mathbf{x}}=\min _{\mathbf{x}}\|A \mathbf{x}-\mathbf{b}\|_{2}^{2}, A \in \mathbb{R}^{n \times m}, \mathbf{x} \in \mathbb{R}^{m}, \mathbf{b} \in \mathbb{R}^{n}
x^=xmin∥Ax−b∥22,A∈Rn×m,x∈Rm,b∈Rn
得,
x
ˉ
=
(
A
T
A
)
−
1
A
T
b
\bar{x} = (A^TA)^{-1}A^Tb
xˉ=(ATA)−1ATb
- 最小二乘法拓展
-
L1正则化最小二乘法
L1正则化是在最小二乘法的基础上加入了L1范数惩罚项,用于对模型参数进行稀疏化,从而达到特征选择的效果。其优化目标为:
min θ ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 p ∣ θ j ∣ \min _{\theta} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}+\lambda \sum_{j=1}^{p}\left|\theta_{j}\right| θmini=1∑n(yi−y^i)2+λj=1∑p∣θj∣
其中 λ λ λ 是正则化参数,控制正则化项对模型的影响, θ θ θ是模型的参数, p p p是参数的数量。通过调节 λ λ λ的大小,可以控制模型的稀疏性,较大的 λ \lambda λ值会导致更多的参数趋向于零(正则化参数越大,模型越稀疏)。特点:L1正则化最小二乘法适用于具有大量特征的数据集,能够进行特征选择,但对于参数估计可能产生偏差
-
L2正则化的最小二乘法
L2正则化是在最小二乘法的基础上加入了L2范数惩罚项,用于控制模型的复杂度,防止过拟合。其优化目标为:
min θ ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 p θ j 2 \min _{\theta} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}+\lambda \sum_{j=1}^{p} \theta_{j}^{2} θmini=1∑n(yi−y^i)2+λj=1∑pθj2
与L1正则化不同的是,L2正则化对参数的惩罚是平方项,因此不会导致参数的稀疏性,而是对参数进行约束,使得参数值相对较小。特点:控制模型复杂度,防止过拟合,对于参数估计不会产生稀疏性。
-
Cauchy型的最小二乘法
Cauchy的最小二乘法是改变了误差函数,使用了Cauchy分布来描述误差,从而提高了对离群值的鲁棒性。Cauchy分布具有较长的尾部,因此对于较大的误差值,Cauchy的最小二乘法会给予较小的权重,使得模型对离群值不敏感。其优化目标为:
min θ ∑ i = 1 n log ( 1 + ( y i − y ^ i ) 2 ) \min _{\theta} \sum_{i=1}^{n} \log \left(1+\left(y_{i}-\hat{y}_{i}\right)^{2}\right) θmini=1∑nlog(1+(yi−y^i)2)
特点:提高了对离群值的鲁棒性,但在数据分布不满足Cauchy分布假设时可能效果不佳。 -
Huber的最小二乘法
Huber最小二乘法是一种对线性回归模型中的异常值具有鲁棒性的方法。它采用了Huber损失函数来代替普通的平方损失函数,以减小异常值对拟合模型的影响。
Huber损失函数定义如下:
L δ ( r ) = { 1 2 r 2 , if ∣ r ∣ ≤ δ δ ( ∣ r ∣ − 1 2 δ ) , if ∣ r ∣ > δ L_{\delta}(r)=\left\{\begin{array}{ll} \frac{1}{2} r^{2}, & \text { if }|r| \leq \delta \\ \delta\left(|r|-\frac{1}{2} \delta\right), & \text { if }|r|>\delta \end{array}\right. Lδ(r)={21r2,δ(∣r∣−21δ), if ∣r∣≤δ if ∣r∣>δ其中 , r = y − y ^ r=y-\hat{y} r=y−y^是残差, δ δ δ是一个阈值参数,用于控制对异常值的惩罚程度。
Huber最小二乘法的优化目标可以表达为:
min β ∑ i = 1 n L δ ( y i − y ^ i ) + λ ∥ β ∥ 2 \min _{\beta} \sum_{i=1}^{n} L_{\delta}\left(y_{i}-\hat{y}_{i}\right)+\lambda\|\beta\|^{2} βmini=1∑nLδ(yi−y^i)+λ∥β∥2
其中 β 是待求解的系数向量, y y y是观测值, y ^ i \hat{y}_{i} y^i是模型预测值, λ λ λ 是正则化参数,用于控制模型的复杂度。Huber最小二乘法与普通的最小二乘法相比,对于小残差采用平方损失,对于大残差则采用线性损失。这样设计的损失函数可以使模型对异常值具有一定的鲁棒性,在一定程度上减少了异常值对模型拟合的影响。
求解Huber最小二乘法通常采用迭代方法,如梯度下降或坐标下降,来优化损失函数并得到最优的系数向量β。
2. 霍夫变换
霍夫变换(Hough Transform)是一种用于检测图像中几何形状的技术,特别适用于检测直线、圆和其他形状。
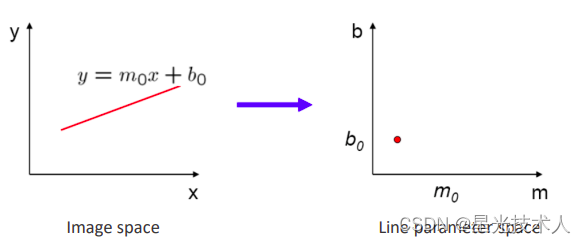
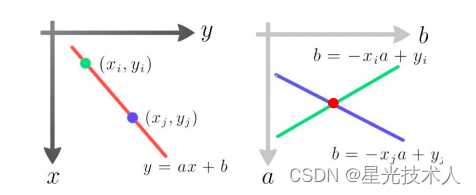
霍夫变换的基础可以这么理解:在坐标系 x o y xoy xoy中的一条直线 y = m 0 x + b 0 y = m_0x + b_0 y=m0x+b0在坐标系 m o b mob mob中可以使用一个点P ( m 0 , b 0 ) (m_0,b_0) (m0,b0)来表示。
霍夫变换的核心是投票累积,霍夫变换的原理步骤如下:
- 参数化表示: 直线可以用极坐标形式表示为 y = m 0 x + b 0 y=m_0x+b_0 y=m0x+b0, m 0 m_0 m0是线的斜率, b 0 b_0 b0是截距
- 参数空间: 对于给定的图像,我们可以构建一个参数空间,其中横轴表示 m m m的取值范围,纵轴表示 b b b的取值范围。
- 投票累积: 对于图像中的每个边缘点,计算它们对应的参数 m m m和 b b b的可能取值,并在参数空间中进行投票。
- 峰值检测: 在参数空间中找到累积投票最高的点,这些点对应的直线就是图像中存在的直线
特点 : 霍夫变换的优点是对于图像中的噪声和缺失部分具有一定的鲁棒性,可以检测到完整或部分可见的几何形状。霍夫变换一般在三个(包含)以下的位置参数的模型中使用,一般工作了2维和3维的数据中。
3. RANSAC算法
- RANSAC算法步骤:
-
随机采样: 从数据集中随机选择一定数量的样本点(最小样本集),用这些样本点来拟合模型。
模型拟合: 使用所选样本点来拟合模型,得到一个候选模型。 -
内点检验: 对于剩余的数据点,计算它们到候选模型的拟合误差,并根据预设的阈值 τ \tau τ判断哪些点是内点(符合模型的点)。阈值 τ \tau τ多通过经验确定。
-
模型评估: 统计内点的数量作为模型的评估指标。
-
迭代更新: 如果当前模型内点数量大于某个阈值,并且模型的评估指标优于之前的模型,则更新最优模型和内点集合;如果内点比例没有达到设置的阈值,就继续从步骤1开始进行迭代,直到达到设定的迭代次数N,从N次迭代的结果中选取内点比例最多的一次,进行模型更新。
-
最优模型: 在迭代结束后,选取内点最多的模型作为最优模型。
-
迭代次数N个取值也有固定的套路,可以根据给定参数选取一个合理的值,不然的话没有一个度量。计算过程如下:
已知,
e
e
e表示噪声点概率,也就是一个点是外点的概率,也就是点集中噪声点的概率;
s
s
s表示拟合这个模型需要的最少点数,线为2,面为3;N为最大迭代次数;
p
p
p为才样本中取值,至少有一次取到的都是内点的概率;因此,有:
(
1
−
(
1
−
e
)
s
)
N
=
1
−
p
(1-(1-e)^s)^N = 1-p \\
(1−(1−e)s)N=1−p
其中,
1
−
e
1-e
1−e表示取出一个点不是噪声点的概率,
(
1
−
e
)
s
(1-e)^s
(1−e)s表示取出的s个点都不是噪声点的概率,
1
−
(
1
−
e
)
s
1-(1-e)^s
1−(1−e)s表示取出的s个点中有噪声,
(
1
−
(
1
−
e
)
s
)
N
(1-(1-e)^s)^N
(1−(1−e)s)N表示完成了N次采样,每次都有噪声点。
得,
N
=
l
o
g
(
1
−
p
)
l
o
g
(
1
−
(
1
−
e
)
s
)
N = {log(1-p) \over log(1-(1-e)^s)}
N=log(1−(1−e)s)log(1−p)
查表就可以得到我们要设置的最大迭代次数N为多大,表如下:

-
RANSAC算法本质:
RANSAC算法的本质是通过随机采样和迭代更新的方式,从包含噪声和异常值的数据中找到最优的模型参数。它通过对内点和外点的区分,能够有效地排除异常值对模型拟合的影响,从而得到更鲁棒的模型。RANSAC的优点在于对异常值具有较好的鲁棒性,能够适应各种数据噪声和异常情况。然而,它的缺点是计算复杂度较高,对于数据量较大的情况可能耗时较长,同时需要事先设置一些参数如采样数量、拟合误差阈值等,不同的参数设置可能会影响算法的性能和结果。
-
C++代码
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
struct Point {
double x;
double y;
};
struct Line {
double slope;
double intercept;
};
Line fitLineRANSAC(const std::vector<Point>& points, int iterations, double threshold) {
srand(time(nullptr));
Line bestLine;
int bestInliers = 0;
for (int i = 0; i < iterations; ++i) {
// Randomly sample two points
int idx1 = rand() % points.size();
int idx2 = rand() % points.size();
while (idx1 == idx2) { // Ensure different points are selected
idx2 = rand() % points.size();
}
const Point& p1 = points[idx1];
const Point& p2 = points[idx2];
// Fit a line using the sampled points
Line candidateLine;
candidateLine.slope = (p2.y - p1.y) / (p2.x - p1.x);
candidateLine.intercept = p1.y - candidateLine.slope * p1.x;
// Count inliers
int inliers = 0;
for (const Point& point : points) {
double error = std::abs(point.y - (candidateLine.slope * point.x + candidateLine.intercept));
if (error <= threshold) {
inliers++;
}
}
// Update best line if this one has more inliers
if (inliers > bestInliers) {
bestInliers = inliers;
bestLine = candidateLine;
}
}
return bestLine;
}
int main() {
std::vector<Point> points = { {1, 2}, {2, 3}, {3, 4}, {4, 5}, {5, 6}, {6, 7}, {7, 8} };
int iterations = 1000;
double threshold = 0.5;
Line fittedLine = fitLineRANSAC(points, iterations, threshold);
std::cout << "Fitted line: y = " << fittedLine.slope << "x + " << fittedLine.intercept << std::endl;
return 0;
}