创建时间:2024-04-08
最后编辑时间:2024-04-10
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名初三学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
那就让我们开始吧!
well…最近发生了点事,一个月没更了eeeww…现在回归咯!
之前讲过似然函数和极大似然估计,蛮详细的,如果不了解的话建议先去瞅一眼()因为 EM 基本就是建立在极大似然估计的基础上的。
传送门:【初中生讲机器学习】12. 似然函数和极大似然估计:原理、应用与代码实现
嗯,EM 算法(中文名期望最大化算法,英文全称 Expectation-Maximum)一篇肯定是写不完的()这一篇计划先把它的思想(原理)和一部分数学原理讲完,后面还会讲它的收敛性以及更复杂的一些数学,再在高斯混合模型中应用一下,and 推广到 GEM…大概是这么个安排!噢然后也会把代码手搓一下嘿嘿嘿(毕竟不能只调包 emm)。((
好,我们先来看个例子,看看 EM 算法的应用场景,并引出一些更深层的问题…
有 100 个人,有男有女,但男女比例未知。我们知道这 100 个人的身高数据,但不知道每个身高数据对应的是男生还是女生,现在的任务是,通过这些身高数据把这些人分出男女。
很好,我估计有些童鞋已经看出来了,这不就聚类咩((不是我觉得我要变成括号姐了,我打字总爱在后面跟一堆括号(((
我们先明确三点:
首先,这个问题本质上还是估计模型参数的事,只不过采用的方法和之前讲的 “纯的极大似然估计” 不太一样。
其次,对于上面这个例子,男生和女生的身高都呈正态分布,但这两个正态分布间没有直接关系。
第三,由于涉及到两个对象,且两个对象(数量)的比例关系未知,且两个对象的分布都是正态分布,so 这个模型的求解就是把两个对象的(数量)比例关系和这两个正态分布的参数(均值和方差)解出来。
一张图形象地展示一下数据可能的分布:
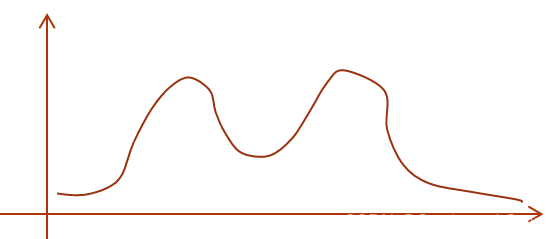
这里补充一下,这个例子的求解,或者说 EM 算法的求解都必然涉及到极大似然估计,而极大似然估计的结果是否可信 & 可用,很大程度上取决于一开始选定的概率分布模型。举个例子,上面的问题中(每种性别的)身高分布很显然是正态分布 or 最接近正态分布,但如果我没有选择正态分布作为概率分布模型,而是选了比如二项分布(虽然略显抽象),那最后解出来的参数必定严重偏离实际。究其根本,还是那句 “模型已定,参数未知”,即,极大似然估计好用,是建立在概率分布模型选择正确的基础上的(选择正确 = 这个概率模型在某参数下的分布能够比较好的拟合实际数据的分布,且符合一些先验知识)。所以,选择一个能够准确描述数据分布的概率分布模型,是后续所有的基础。
errr 如果你没理解这段话的意思,可以先去看一下极大似然估计的流程~
呃,啊,才发现《补充一下》好像补充了不止一下()。。。拉回主线,继续看上面那个问题。
这个问题有两个难点。
第一,涉及到两个对象。 显然,如果这 100 人是同一性别,那事情就好办了,直接极大似然估计一顿搞,把均值和方差解出来就是了。可是现在有两个性别,“一顿搞” 显然是行不通的。
第二,只有数据,没有标签。 不难想到,如果有标签,这就变成一个分类问题了,
好了,现在我们开始接近 EM 算法的核心了。
“没有标签”,或者说 “标签未被观测到”,有一个特定的词——隐变量(或者叫潜变量,latent variable),即那些无法被直接观察到的变量。对于这个问题,“男” or “女”,就是隐变量。
极大似然估计是用在所有变量都是观测变量的情况下的,而 EM 算法则是用在含有隐变量的问题当中的,这也解释了为什么 EM 算法经常用于聚类问题中(简单来讲是因为聚类问题中每个类都是隐变量,如果都是观测变量的话那就直接极大似然估计开搞了()())。(括号姐继续输出括号啊不是((
好了,现在问题来了,我们前边说目标是得出男生和女生的身高(两个正态分布)的均值和方差对吧,but…
要想估计概率分布模型的参数,得先知道有哪些样本属于这个分布;反过来,(对于这个问题)只有知道了概率分布模型的参数,才能知道哪些样本属于这个分布。。。
ok,循环论证了属于是(((
emm so 这波怎么玩,,,,
没错!参数和样本两个总有一个得妥协一下,样本那边估计是没啥可能了,不知道隐变量就是不知道,所以只能让参数这边妥协一下了。。。
于是,我们不妨,先随便设一个初始参数! 比如,我们假设,注意是假设,男生身高的均值是 175,方差是 2(方差是我随便编的,估计不准),女生是多少多少。然后,我们把现有的样本按照人为设定的初始参数分男女。第一次分完之后,我们不就有带标签的数据了嘛!then,我们再用这些带标签的数据更新概率分布模型的参数(也就是用这些观测变量计算出两个正态分布的新的均值和方差),并且,因为新的参数是根据真是样本算出来的,所以一般情况下会比初始人为设定的参数更能反映真实情况(当然排除初始参数特别离谱的情况)。这样一次接着一次不断迭代,直到模型参数趋近于稳定(即变化程度小于某个阈值)。
放一张图,虽然不是这个例子,但是迭代的方式是一样的。

okkk,你估计已经发现了一些问题——咱这是给出了一个还算合理的初始值 175,但是要是我偏不,我就假设男生身高均值 160,女生身高均值 175(这显然不合理),那这个模型直接错误率高达 90% 了,这可咋办?EM 算法对初始值很敏感啊。
好好好,我们必须得面对问题()()的确,EM 算法对初始值敏感,但是我们可以依据大量的先验知识来设定一个相对合理的初始值,也可以在聚类完毕后用一些有标签的数据测试一下模型(比如上面的例子,在 EM 算法运行结束之后,把现实中的一些真实的男女身高数据带进训练好的模型中,看看准确率),也可以选取多个初始值,看最终运行结果然后挑出一个,等等。
不过要是你执意和先验知识反着来()()那我觉得有问题的就不是模型了(啊不过我怎么觉得这像是我会干出来的事((doge(抽象)
好嘞!上面这些就是对 EM 算法通俗易懂的解释()()下面嘛…数学总是绕不开的咯~
(不过不会一下子上强度的()()主要是那样我容易 explode()(
emm,既然都讲到数学了,我们总归得把上面的例子 “抽象” 一下。
现有 n n n 个概率分布(简称 “分布”),记作 f 1 , f 2 , . . . , f n f_1, f_2, ..., f_n f1,f2,...,fn,我们每次从这 n n n 个概率分布中随机抽取数据。
从第 j ( 1 ≤ j ≤ n ) j \ (1≤j≤n) j (1≤j≤n) 个分布中抽取数据的概率是 w j w_j wj.
第 j j j 个分布的参数是 p a r a j para_j paraj.
我们获得了 k k k 个来自这 n n n 个分布的样本 x 1 , x 2 , . . . , x k x_1, x_2, ... , x_k x1,x2,...,xk.
我们的任务是,根据已有的这些样本,估计参数 w , p a r a j ( 1 ≤ j ≤ n ) w, para_j (1≤j≤n) w,paraj(1≤j≤n) 最有可能的取值。
注:在男女生身高的例子中,分布 = 正态分布, n = 2 , k = 100 n = 2, k = 100 n=2,k=100.
well,如果感觉有点过于抽象了(),结合上面的身高问题的例子解释一下:
身高问题中的分布是正态分布。
n
=
2
n = 2
n=2,两个正态分布对应男女生的身高分布(即观测变量的概率分布);
我们假设第一个正态分布代表男生的身高分布,第二个正态分布代表女生的身高分布,那么从第一个正态分布中抽取数据的概率
w
1
w_1
w1 和从第二个正态分布中抽取数据的概率
w
2
w_2
w2 的比值
w
1
w
2
\frac {w_1} {w_2}
w2w1 对应的就是男女生的人数之比(这个比例关系最初是不知道的,
w
w
w 也是待求参数之一)。
两个正态分布的参数都是均值和方差。
获得的
k
=
100
k = 100
k=100 个数据就是 100 个人的身高,但注意我们不知道每个身高对应的是男是女。
最终任务:参数估计。
怎么说,又是 parameter estimate)))
okay,不过现在既然要搞数学,就不再用那个具体的身高(正态分布)例子了,用这个抽象出来的一般化模型。我们接下来要做的是找到通用的求解方法,即在任何可能的概率分布的情况下都适用的方法(或者说走一遍 EM 算法一般化的求解过程)。
噢对了,由于参数 w , p a r a j ( 1 ≤ j ≤ n ) w, \ para_j (1≤j≤n) w, paraj(1≤j≤n) 太多了,每次都列一大堆的话会很乱,所以我们把它们统一成 θ \theta θ,即 θ = ( w , p a r a j ( 1 ≤ j ≤ n ) ) \theta = (w, \ para_j (1≤j≤n)) θ=(w, paraj(1≤j≤n)).
前面说过,EM 和极大似然估计很相似,所以我们也仿照极大似然估计那里的思想。——让已经出现的数据的出现概率最大的参数就是最优参数。
写出关于参数
θ
\theta
θ 的似然函数
L
(
θ
)
L(\theta)
L(θ),其中
p
(
x
i
∣
θ
)
p(x_i|\theta)
p(xi∣θ) 就是数据
x
i
x_i
xi 在参数
θ
\theta
θ 下出现的概率。
L
(
θ
)
=
∏
i
=
1
k
p
(
x
i
∣
θ
)
L(\theta) = \prod_{i = 1}^{k} \ p(x_i|\theta)
L(θ)=i=1∏k p(xi∣θ)
(p.s. 如果这里和下面的公式不理解的话建议补一下极大似然估计())
然后,我们引入隐变量
z
z
z(可以理解为身高问题中的 “性别”)。
因为每个隐变量代表一种可能的(但未知的)情况,那所有隐变量就覆盖了全部可能的情况。由全概率公式我们得到:
P
(
A
)
=
P
(
A
∣
B
)
+
P
(
A
∣
C
)
+
.
.
.
P(A) = P(A|B)+P(A|C)+...
P(A)=P(A∣B)+P(A∣C)+...,其中
B
,
C
,
.
.
.
B, C, ...
B,C,... 覆盖了整个概率空间。
简单的例子,
P
(
h
e
i
g
h
t
=
175
)
=
P
(
h
e
i
g
h
t
=
175
∣
g
e
n
d
e
r
=
b
o
y
)
+
P
(
h
e
i
g
h
t
=
175
∣
g
e
n
d
e
r
=
g
i
r
l
)
P(height = 175) = P(height = 175|gender = boy) + P(height = 175|gender = girl)
P(height=175)=P(height=175∣gender=boy)+P(height=175∣gender=girl)
于是,我们可以进一步推出:
L
(
θ
)
=
∏
i
=
1
k
p
(
x
i
∣
θ
)
=
∏
i
=
1
k
(
∑
z
p
(
x
i
,
z
∣
θ
)
)
L(\theta) = \prod_{i = 1}^{k} \ p(x_i|\theta)= \prod_{i = 1}^{k} \ (\sum_{z} p(x_i, z|\theta))
L(θ)=i=1∏k p(xi∣θ)=i=1∏k (z∑p(xi,z∣θ))
then,我们按照概率的计算规则,把
x
i
,
z
x_i, z
xi,z 的联合概率改写为条件概率的形式。
这个式子不难理解,
θ
\theta
θ 条件下
x
i
,
z
x_i, z
xi,z 共同发生的概率等于
θ
\theta
θ 下
z
z
z 发生的概率乘上
θ
,
z
\theta, z
θ,z 发生的时候
x
x
x 发生的概率。
(因为
x
i
x_i
xi 和
z
z
z 显然不满足独立性假设,所以不能用
p
(
x
i
,
z
∣
θ
)
=
p
(
x
i
∣
θ
)
×
p
(
z
∣
θ
)
p(x_i, z|\theta) = p(x_i|\theta)×p(z|\theta)
p(xi,z∣θ)=p(xi∣θ)×p(z∣θ) 来计算)
L
(
θ
)
=
∏
i
=
1
k
(
∑
z
p
(
z
∣
θ
)
p
(
x
i
∣
z
,
θ
)
)
L(\theta) =\prod_{i = 1}^{k} \ (\sum_{z} \ p(z|\theta) \ p(x_i|z,\theta))
L(θ)=i=1∏k (z∑ p(z∣θ) p(xi∣z,θ))
ok,接下来按照套路把连乘改成求和就 ok 了。
L
(
θ
)
=
∑
i
=
1
k
log
∑
z
p
(
z
∣
θ
)
p
(
x
∣
z
,
θ
)
L(\theta) = \sum_{i = 1}^{k} \ \log\sum_{z} \ p(z|\theta) \ p(x|z,\theta)
L(θ)=i=1∑k logz∑ p(z∣θ) p(x∣z,θ)
我们的任务就是求出:
θ
=
a
r
g
m
a
x
θ
(
∑
i
=
1
k
log
∑
z
p
(
z
∣
θ
)
p
(
x
∣
z
,
θ
)
)
\theta = arg \ max_\theta \bigg ( \sum_{i = 1}^{k} \ \log\sum_{z} \ p(z|\theta) \ p(x|z,\theta) \bigg)
θ=arg maxθ(i=1∑k logz∑ p(z∣θ) p(x∣z,θ))
也就是,我们要让括号里这坨东西最大化。
可是,,,这玩意怎么最大化??求偏导?你确定我们要对一个里面套着 sigma 的 log 求偏导,,,
嗯,偏导是肯定不可能了,并且有些情况下可能根本就求不出偏导。
so,我们得换条路了,EM 给我们指出的路是——迭代!
换言之,既然我没法一下子就找到最优参数,那我就一遍遍更新参数,一点点接近最优参数嘛!
ok 那么,怎么迭代。
L
(
θ
)
=
∑
i
=
1
k
log
∑
z
p
(
z
∣
θ
)
p
(
x
∣
z
,
θ
)
L(\theta) = \sum_{i = 1}^{k} \ \log\sum_{z} \ p(z|\theta) \ p(x|z,\theta)
L(θ)=∑i=1k log∑z p(z∣θ) p(x∣z,θ) 是我们要最大化的式子,所以我们希望每次新计算出来的
L
(
θ
n
+
1
)
L(\theta_{n+1})
L(θn+1) 比上次的
L
(
θ
n
)
L(\theta_n)
L(θn) 大,让他俩做个差:
注意,
L
(
θ
n
)
L(\theta_n)
L(θn) 是已经计算出来的(如果
n
=
0
n=0
n=0,则是最初随机选取的参数),所以下式最右边的一项是已知的。
L
(
θ
n
+
1
)
−
L
(
θ
n
)
=
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
−
log
(
x
i
∣
θ
n
)
)
L(\theta_{n+1})-L(\theta_n) = \sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1}) \ - \ \log \ (x_i|\theta_n) \bigg)
L(θn+1)−L(θn)=i=1∑k (logz∑ p(z∣θn+1) p(x∣z,θn+1) − log (xi∣θn))
当然,我们现在并不能确定这个式子一定大于 0,即现在还不能判定 EM 算法是否收敛,不过先往下算着,算完之后总会有惊喜的()()。
ok 然后到了各位喜闻乐见的恒等变形出奇迹环节了:
L
(
θ
n
+
1
)
−
L
(
θ
n
)
=
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
−
log
(
x
i
∣
θ
n
)
)
=
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
x
i
,
θ
n
)
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
log
(
x
i
∣
θ
n
)
)
L(\theta_{n+1})-L(\theta_n) = \sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1}) \ - \ \log(x_i|\theta_n) \bigg) \\ =\sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \log(x_i|\theta_n) \bigg)
L(θn+1)−L(θn)=i=1∑k (logz∑ p(z∣θn+1) p(x∣z,θn+1) − log(xi∣θn))=i=1∑k (logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − log(xi∣θn))
至于为什么要这么搞()过会你就知道了。简单来讲,
p
(
z
∣
x
i
,
θ
n
)
p(z|x_i, \theta_n)
p(z∣xi,θn) 代表的是在 “数据是
x
i
x_i
xi” & “上次算出的参数
θ
n
\theta_n
θn” 的情况下,隐变量
z
z
z 出现的概率(也就是说我们计算出了隐变量的分布)。
联系身高问题,“
z
z
z 的分布” 代表的就是性别分布(即男女占比)。
好,接下来,按照恒等变形的惯例(bushi)(好吧我随便编的,估计没有这个惯例),既然前边这一项加入了 p ( z ∣ x i , θ n ) p(z|x_i, \theta_n) p(z∣xi,θn),那后边那项也最好加入 p ( z ∣ x i , θ n ) p(z|x_i, \theta_n) p(z∣xi,θn).
嗯,这不还是全概率公式嘛,和上面讲的把
p
(
x
i
∣
θ
)
p(x_i|\theta)
p(xi∣θ) 变形为
∑
z
p
(
x
i
,
z
∣
θ
)
\sum_{z} p(x_i, z|\theta)
∑zp(xi,z∣θ) 的套路是一样的,也就是说:
log
(
x
i
∣
θ
n
)
=
∑
z
[
log
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
\log(x_i|\theta_n) = \sum_z [\log(x_i|\theta_n)] \ p(z|x_i, \theta_n)
log(xi∣θn)=z∑[log(xi∣θn)] p(z∣xi,θn)
代入原式中得到:
L
(
θ
n
+
1
)
−
L
(
θ
n
)
=
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
x
i
,
θ
n
)
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
∑
z
[
log
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
)
L(\theta_{n+1})-L(\theta_n) = \sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log(x_i|\theta_n)] \ p(z|x_i, \theta_n) \bigg)
L(θn+1)−L(θn)=i=1∑k (logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[log(xi∣θn)] p(z∣xi,θn))
ok,很好,现在我们得到了【充分变形】后的式子:
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
x
i
,
θ
n
)
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
∑
z
[
log
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
)
\sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log(x_i|\theta_n)] \ p(z|x_i, \theta_n) \bigg)
i=1∑k (logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[log(xi∣θn)] p(z∣xi,θn))
嗯,,,,,怎么感觉现在问题变得更大了。。。不过先别着急,数学总是神奇的()
来介绍一个在 EM 算法中非常重要的不等式——Jensen 不等式!
Jensen 不等式的主要内容用一句话就可以概括:对于一个凹函数
F
F
F(二阶导数大于 0 的函数,比如一个开口向上的二次函数),函数的期望大于等于期望的函数,凸函数反之。即对于一个凹函数,有:
E
[
F
(
x
)
]
≥
F
[
E
(
x
)
]
E[F(x)] \ge F[E(x)]
E[F(x)]≥F[E(x)]
哦对了,我发现国内高数教材和国外高数教材对凹凸函数的定义似乎是相反的,我这里用的是国外的定义,大概可以理解为长得像 a > 0 a>0 a>0 的二次函数的函数,也就是二阶导数 F ′ ′ > 0 F''>0 F′′>0 的函数是凹函数;二阶导数 F ′ ′ < 0 F'' < 0 F′′<0 的函数时凸函数。
emmm 这个不等式有点抽象,我们用一张图来直观感受一下:
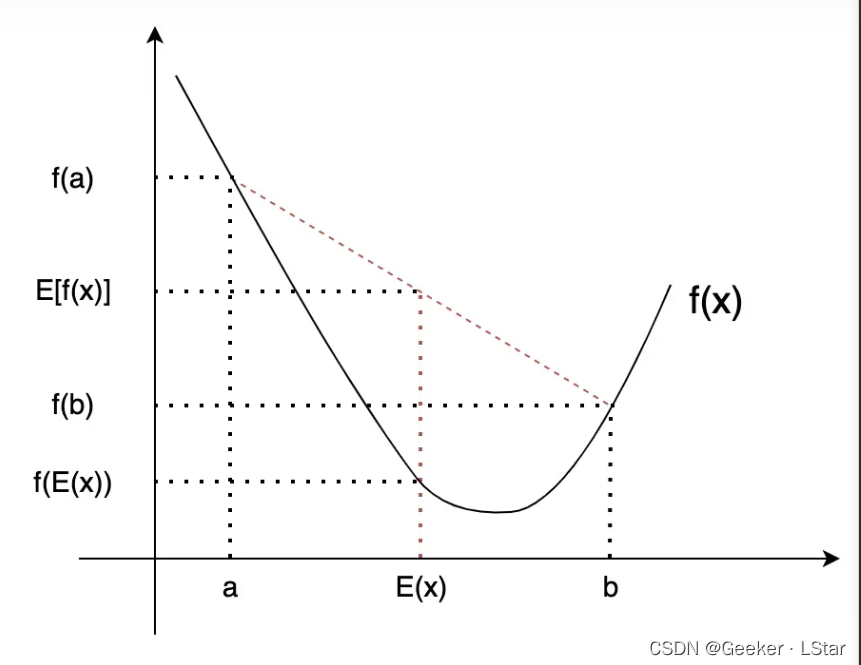
图中已经把几个重要的点对应的横纵坐标都写出来了,不难发现,对于凹函数,函数的期望总是大于等于期望的函数。
好吧,我不打算在这里证明 Jensen 不等式,现在的关键问题是这个不等式是怎么和上面那一大串 abstract 的式子扯上关系的?
我们不妨再把那个式子粘过来(
∑ i = 1 k ( log ∑ z p ( z ∣ x i , θ n ) p ( z ∣ θ n + 1 ) p ( x ∣ z , θ n + 1 ) p ( z ∣ x i , θ n ) − ∑ z [ log ( x i ∣ θ n ) ] p ( z ∣ x i , θ n ) ) \sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log(x_i|\theta_n)] \ p(z|x_i, \theta_n) \bigg) i=1∑k (logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[log(xi∣θn)] p(z∣xi,θn))
后面那部分不用管,因为
θ
n
,
x
i
\theta_n, x_i
θn,xi 是已知的,后面那块其实就是
log
(
x
i
∣
θ
n
)
\log (x_i|\theta_n)
log(xi∣θn),是可以求出具体值的,现在主要就是前面那块。
咱之前说什么来着,log 里面套 sigma 难以求偏导对吧,而 jensen 不等式就是来解决这个问题的!
观察一下 jensen 不等式,它能把 E 和 F(表示求期望和求函数值)给换个位置,那我们合理猜测一下,它是不是也能把 log ∑ z p ( z ∣ x i , θ n ) p ( z ∣ θ n + 1 ) p ( x ∣ z , θ n + 1 ) p ( z ∣ x i , θ n ) \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} log∑z p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) 中的 log 和 sigma 给换个位置呢?这样不就解决不好求偏导的问题了嘛!!
答案是可以的。and log \log log(实际上这里用的是 ln \ln ln)是个凸函数(它的二阶导数为 − 1 x 2 < 0 -\frac{1}{x^2}<0 −x21<0,所以直接用 jensen 不等式就行。
我们得到:
log
∑
z
p
(
z
∣
x
i
,
θ
n
)
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
≥
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
\log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \\ \ge \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)}
logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1)≥z∑ p(z∣xi,θn) logp(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1)
带回原式:
L
(
θ
n
+
1
)
−
L
(
θ
n
)
=
∑
i
=
1
k
(
log
∑
z
p
(
z
∣
x
i
,
θ
n
)
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
∑
z
[
log
p
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
)
≥
∑
i
=
1
k
(
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
∑
z
[
log
p
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
)
=
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
−
∑
z
[
log
p
(
x
i
∣
θ
n
)
]
p
(
z
∣
x
i
,
θ
n
)
=
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
p
(
x
i
∣
θ
n
)
\begin{align} & L(\theta_{n+1})-L(\theta_n) \\ & = \sum_{i = 1}^{k} \ \bigg ( \log\sum_{z} \ p(z|x_i, \theta_n) \ \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log p(x_i|\theta_n)] \ p(z|x_i, \theta_n) \bigg) \\ & \ge \sum_{i = 1}^{k} \ \bigg ( \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log p(x_i|\theta_n)] \ p(z|x_i, \theta_n) \bigg) \\ & =\sum_{i = 1}^{k} \ \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n)} \ - \ \sum_z [\log p(x_i|\theta_n)] \ p(z|x_i, \theta_n) \\ & = \sum_{i = 1}^{k} \ \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n) \ p(x_i|\theta_n)} \end{align}
L(θn+1)−L(θn)=i=1∑k (logz∑ p(z∣xi,θn) p(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[logp(xi∣θn)] p(z∣xi,θn))≥i=1∑k (z∑ p(z∣xi,θn) logp(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[logp(xi∣θn)] p(z∣xi,θn))=i=1∑k z∑ p(z∣xi,θn) logp(z∣xi,θn)p(z∣θn+1) p(x∣z,θn+1) − z∑[logp(xi∣θn)] p(z∣xi,θn)=i=1∑k z∑ p(z∣xi,θn) logp(z∣xi,θn) p(xi∣θn)p(z∣θn+1) p(x∣z,θn+1)
好!!!在我崩溃的前一秒我们搞出来了这坨东西!
最后的结果就是:
L
(
θ
n
+
1
)
−
L
(
θ
n
)
≥
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
p
(
x
i
∣
θ
n
)
L(\theta_{n+1})-L(\theta_n) \ge \sum_{i = 1}^{k} \ \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n) \ p(x_i|\theta_n)}
L(θn+1)−L(θn)≥i=1∑k z∑ p(z∣xi,θn) logp(z∣xi,θn) p(xi∣θn)p(z∣θn+1) p(x∣z,θn+1)
也就是:
L
(
θ
n
+
1
)
≥
L
(
θ
n
)
+
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
z
∣
θ
n
+
1
)
p
(
x
∣
z
,
θ
n
+
1
)
p
(
z
∣
x
i
,
θ
n
)
p
(
x
i
∣
θ
n
)
L(\theta_{n+1}) \ge L(\theta_n)+\sum_{i = 1}^{k} \ \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n) \ p(x_i|\theta_n)}
L(θn+1)≥L(θn)+i=1∑k z∑ p(z∣xi,θn) logp(z∣xi,θn) p(xi∣θn)p(z∣θn+1) p(x∣z,θn+1)
我们把等号右边那一大坨东西记作
B
(
θ
n
+
1
,
θ
n
)
B(\theta_{n+1}, \theta_n)
B(θn+1,θn),也就是说我们有:
L
(
θ
n
+
1
)
≥
B
(
θ
n
+
1
,
θ
n
)
L(\theta_{n+1}) \ge B(\theta_{n+1}, \theta_n)
L(θn+1)≥B(θn+1,θn)
称
B
(
θ
n
+
1
∣
θ
n
)
B(\theta_{n+1}|\theta_n)
B(θn+1∣θn) 为
L
(
θ
n
+
1
)
L(\theta_{n+1})
L(θn+1) 的下边界函数。
那么,我们之前【让
L
(
θ
n
+
1
)
L(\theta_{n+1})
L(θn+1) 变大】的目标就变成了【让下边界函数
B
(
θ
n
+
1
∣
θ
n
)
B(\theta_{n+1}|\theta_n)
B(θn+1∣θn) 变大】。
这很好理解吧,
L
(
θ
n
+
1
)
L(\theta_{n+1})
L(θn+1) 始终是大于等于
B
(
θ
n
+
1
∣
θ
n
)
B(\theta_{n+1}|\theta_n)
B(θn+1∣θn) 的,所以
B
B
B 变大了,
L
L
L 自然也就变大了。
很好,刚才我们一直在把事情变复杂,现在终于又(以一种非常好的形式)变简单回来了!
well,不过问题还可以进一步简化,因为 B B B 中并不是所有项都含有 θ n + 1 \theta_{n+1} θn+1,有些项是对让 B B B 变大没有用的常数,我们可以忽略它们。
B ( θ n + 1 ∣ θ n ) = L ( θ n ) + ∑ i = 1 k ∑ z p ( z ∣ x i , θ n ) log p ( z ∣ θ n + 1 ) p ( x ∣ z , θ n + 1 ) p ( z ∣ x i , θ n ) p ( x i ∣ θ n ) = L ( θ n ) + ∑ i = 1 k ∑ z p ( z ∣ x i , θ n ) log [ p ( z ∣ θ n + 1 ) p ( x ∣ z , θ n + 1 ) ] − ∑ z p ( z ∣ x i , θ n ) log [ p ( z ∣ x i , θ n ) p ( x i ∣ θ n ) ] = ∑ i = 1 k ∑ z p ( z ∣ x i , θ n ) log [ p ( z ∣ θ n + 1 ) p ( x ∣ z , θ n + 1 ) ] = ∑ i = 1 k ∑ z p ( z ∣ x i , θ n ) log p ( x i , z ∣ θ n + 1 ) \begin{align} & B(\theta_{n+1}|\theta_n) = L(\theta_n)+\sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \ \log \frac{p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1})}{p(z|x_i, \theta_n) \ p(x_i|\theta_n)} \\ & = L(\theta_n) + \sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \log \bigg [ p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1}) \bigg] - \sum_{z} \ p(z|x_i, \theta_n) \log \bigg [ p(z|x_i, \theta_n) \ p(x_i|\theta_n) \bigg] \\ & = \sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \log \bigg [ p(z|\theta_{n+1}) \ p(x|z,\theta_{n+1}) \bigg] \\ & =\sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \log p(x_i, z|\theta_{n+1}) \end{align} B(θn+1∣θn)=L(θn)+i=1∑kz∑ p(z∣xi,θn) logp(z∣xi,θn) p(xi∣θn)p(z∣θn+1) p(x∣z,θn+1)=L(θn)+i=1∑kz∑ p(z∣xi,θn)log[p(z∣θn+1) p(x∣z,θn+1)]−z∑ p(z∣xi,θn)log[p(z∣xi,θn) p(xi∣θn)]=i=1∑kz∑ p(z∣xi,θn)log[p(z∣θn+1) p(x∣z,θn+1)]=i=1∑kz∑ p(z∣xi,θn)logp(xi,z∣θn+1)
em,解释一下,第三行的【等号】不是说第二行和第三行相等,而是说让第二行最大化(即让
B
B
B 函数最大化)等价于让第三行最大化,这是因为第二行中的第一项和第三项都不含有
θ
n
+
1
\theta_{n+1}
θn+1 而只含有
θ
n
\theta_n
θn,也就是说它们都是确定的常数,删去它们不会对最终的求解造成影响,so 为了计算简便,我们就把常数都删掉了,留下了最核心的式子:
Q
(
θ
n
+
1
,
θ
n
)
=
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
x
i
,
z
∣
θ
n
+
1
)
Q(\theta_{n+1}, \theta_n) = \sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \log p(x_i, z|\theta_{n+1})
Q(θn+1,θn)=i=1∑kz∑ p(z∣xi,θn)logp(xi,z∣θn+1)
经过一系列复杂的变化,我们现在得到了一个非常好的结果——我们只需要让函数
Q
Q
Q 最大就行了!换言之,我们想要的
θ
n
+
1
\theta_{n+1}
θn+1 可以这么求:
(显然让
Q
Q
Q 最大可以求偏导)
θ
n
+
1
=
a
r
g
m
a
x
θ
Q
(
θ
n
+
1
,
θ
n
)
\theta_{n+1} = arg \ max_\theta \ Q(\theta_{n+1}, \theta_n)
θn+1=arg maxθ Q(θn+1,θn)
也就是说,
θ
n
+
1
\theta_{n+1}
θn+1 就是使得这次迭代的
Q
Q
Q 函数最大的参数~!
然后就一直这么迭代,直到达到停止迭代的条件——
θ
n
+
1
,
θ
n
\theta_{n+1}, \theta_n
θn+1,θn 的差值小于阈值(一个较小的正数),即:
∣
∣
θ
n
+
1
−
θ
n
∣
∣
<
ϵ
1
||\theta_{n+1}-\theta_n||< \epsilon_1
∣∣θn+1−θn∣∣<ϵ1
fine,到此结束~
OK!!!非常完美!我们已经完整推导出了 EM 算法!!
嗯,公式还是太多了()这里给出一个 EM 算法的直观解释,如下图。
很多信息图上已经写的很清楚了,这里再解释一下:
下面那条曲线可以看作
B
(
θ
n
+
1
,
θ
n
)
B(\theta_{n+1}, \theta_n)
B(θn+1,θn),上面那条曲线可以看作
L
(
θ
)
L(\theta)
L(θ)。
B
(
θ
n
+
1
,
θ
n
)
B(\theta_{n+1}, \theta_n)
B(θn+1,θn) 可以看作
L
(
θ
)
L(\theta)
L(θ) 的下界,两个函数在点
θ
=
θ
n
\theta = \theta_n
θ=θn 时相等。由上面讲的 EM 算法的计算,EM 算法找到下一个点
θ
n
+
1
\theta_{n+1}
θn+1 使函数
B
B
B 极大化,也使函数
Q
Q
Q 极大化。
这时由于
L
(
θ
n
+
1
)
≥
B
L(\theta_{n+1}) \ge B
L(θn+1)≥B,函数
B
B
B 增大,
L
L
L 自然也增加。这保证了
L
(
θ
)
L(\theta)
L(θ) 在每次迭代中都是增加的。
then,得到新的参数
θ
n
+
1
\theta_{n+1}
θn+1 后,EM 算法计算新的
B
B
B 函数,然后极大化
B
B
B 函数,
L
(
θ
)
L(\theta)
L(θ) 继续增大。
…
以此类推,直到
L
(
θ
)
L(\theta)
L(θ) 收敛。
不过哦,这张图也说明了一件事——EM 算法不一定能找到全局最大值,但是一定能找到局部最大值。
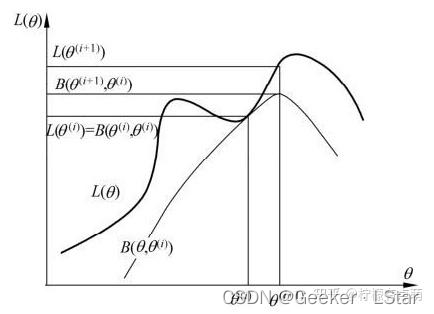
哦,对了,上面的描述其实已经解决了我们最开始不太清楚的问题—— L ( θ ) L(\theta) L(θ) 的收敛性。由于 L ( θ ) L(\theta) L(θ) 每次都是增大的,所以它最终必然会收敛,因为它不可能一直增大。
那么,让我们来总结一下 EM 算法的一般流程。
输入:观测变量数据 ( x 1 , x 2 , . . . , x k ) (x_1, x_2, ..., x_k) (x1,x2,...,xk), 隐变量数据 z z z(数量不确定),条件分布 p i = ( z ∣ x i , θ ) , 1 ≤ i ≤ k p_i = (z|x_i, \theta), \ 1 \le i \le k pi=(z∣xi,θ), 1≤i≤k.
输出:模型参数 θ \theta θ
步骤:
(1) 选择(自定义)模型参数
θ
\theta
θ 的初始值
θ
0
\theta_0
θ0,开始迭代。
(2) E 步:记
θ
n
\theta_n
θn 为第
n
n
n 次迭代参数
θ
\theta
θ 的估计值,在第
n
+
1
n+1
n+1 次迭代的 E 步,计算:
Q
(
θ
n
+
1
,
θ
n
)
=
∑
i
=
1
k
∑
z
p
(
z
∣
x
i
,
θ
n
)
log
p
(
x
i
,
z
∣
θ
n
+
1
)
Q(\theta_{n+1}, \theta_n) = \sum_{i = 1}^{k} \sum_{z} \ p(z|x_i, \theta_n) \log p(x_i, z|\theta_{n+1})
Q(θn+1,θn)=i=1∑kz∑ p(z∣xi,θn)logp(xi,z∣θn+1)
其中 p ( z ∣ x i , θ n ) p(z|x_i, \theta_n) p(z∣xi,θn) 是在给定观测数据 x x x 和当前参数估计 θ n \theta_n θn 下隐变量 z z z 的条件概率分布。
(3) M 步:求使 Q ( θ n + 1 , θ n ) Q(\theta_{n+1}, \theta_n) Q(θn+1,θn) 极大化的参数 θ n + 1 \theta_{n+1} θn+1,即为第 n + 1 n+1 n+1 次迭代的参数的估计值。
(4) 重复(2)(3),直到收敛。
嘿嘿,没错哦,EM 算法,英文 Expectation Maximization Algorithm,它其实说的就是 EM 迭代循环的两步~
最简要的概括如下:
E 步(Expectation) 根据上一步求出来的参数估计值和观测变量的值,求隐变量
z
z
z 的期望,再利用隐变量的估计值求参数的极大似然估计函数。
M 步(Maximization) 求参数的似然函数的极大值,得到新的参数估计值。
E 步和 M 步就这么交替一直到收敛。
最后,放一张特别特别特别能精辟概括 EM 算法的图:
“你怎么不左脚踩右脚,右脚踩左脚飞上天呢”
这说的不就是 EM 嘛!!E 步和 M 步互相依赖交替进行最终上天,啊不是,最终搞定 parameter estimate! (((

嗯!!那么这篇文章就完美收尾啦!下一篇估计会讲 EM 在 GMM(高斯混合模型)中的应用,其实就是这篇的身高问题的推广噢~下一篇见!
嗯,EM 大概用了三天的自习课(的一半)(还有一半在搞托福),最近的自习比较多。
(研究高斯混合模型 搞托福去了(((有没有人好奇我这一篇到底打了多少括号(
这篇文章介绍了 EM 算法的基本思想,并给出了完整的数学推导,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar