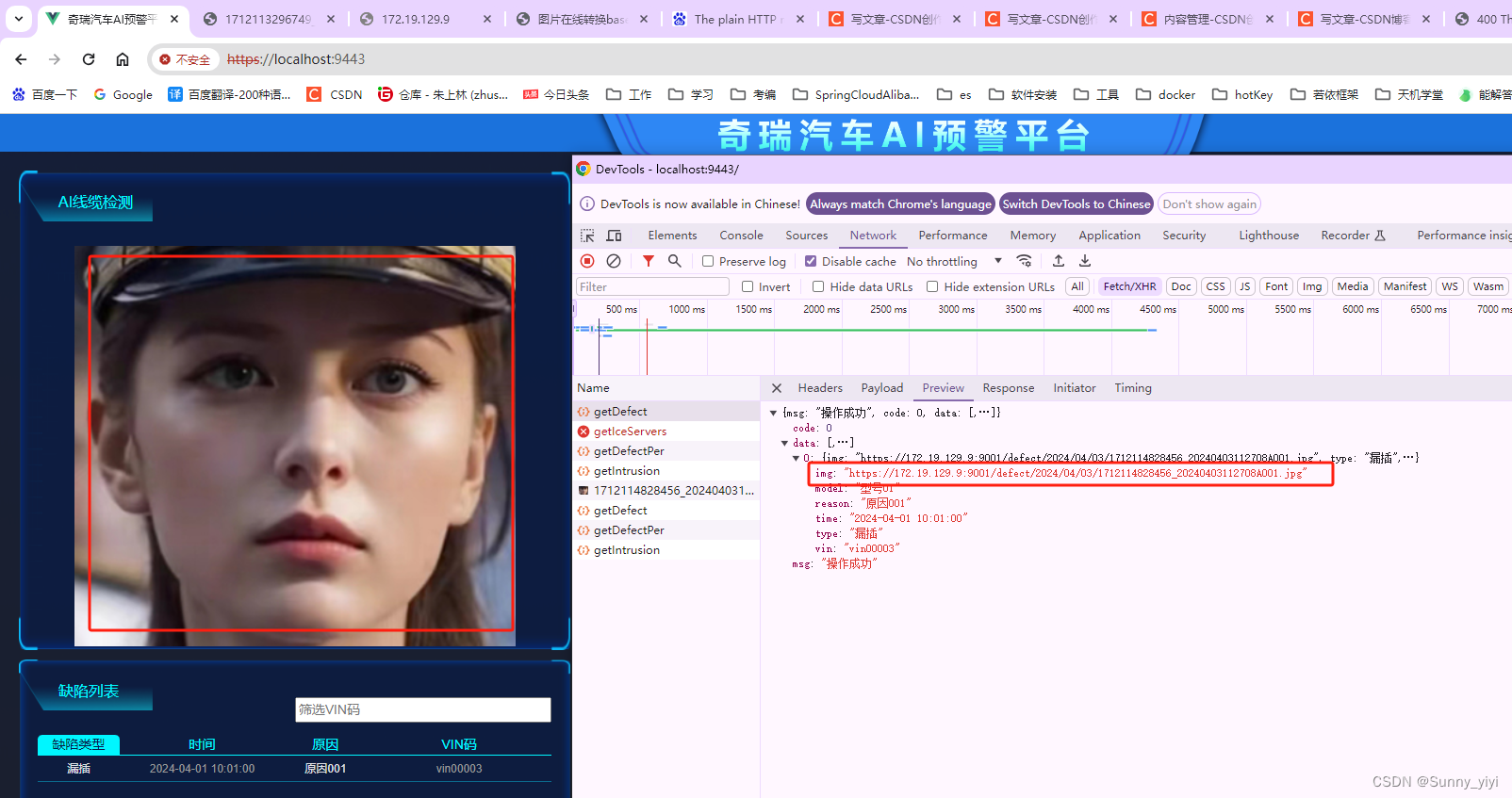
创建数据库并指定hdfs存储位置
create database myhive2 location ‘/myhive2’;
使用location关键字,可以指定数据库在HDFS的存储路径。
Hive的库在HDFS上就是一个以.db结尾的目录
默认存储在:
/user/hive/warehouse内
当你为Hive表指定一个LOCATION时,你告诉Hive这个表的数据应该存放在HDFS的哪个位置。这个位置是HDFS命名空间中的一个目录,它可能跨越多个数据节点。Hive和HDFS会协同工作,确保当查询这个表时,数据可以从正确的节点上被检索和处理。
可以通过LOCATION关键字在创建的时候指定存储目录
删除一个数据库
删除空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive;
强制删除数据库,包含数据库下面的表一起删除
drop database myhive2 cascade;
创建表
CREATE [EXTERNAL]TABLE [IF NOT EXISTS]table_name
[(col_name data_type [COMMENT col_comment],..)
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment],..)
[CLUSTERED BY (col_name,col_name,...
[SORTED BY (col_name [ASC IDESC],..)INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- EXTERNAL,创建外部表
- PARTITIONED BY,分区表
- CLUSTERED BY,分桶表
- STORED AS,存储格式
- LOCATION,存储位置
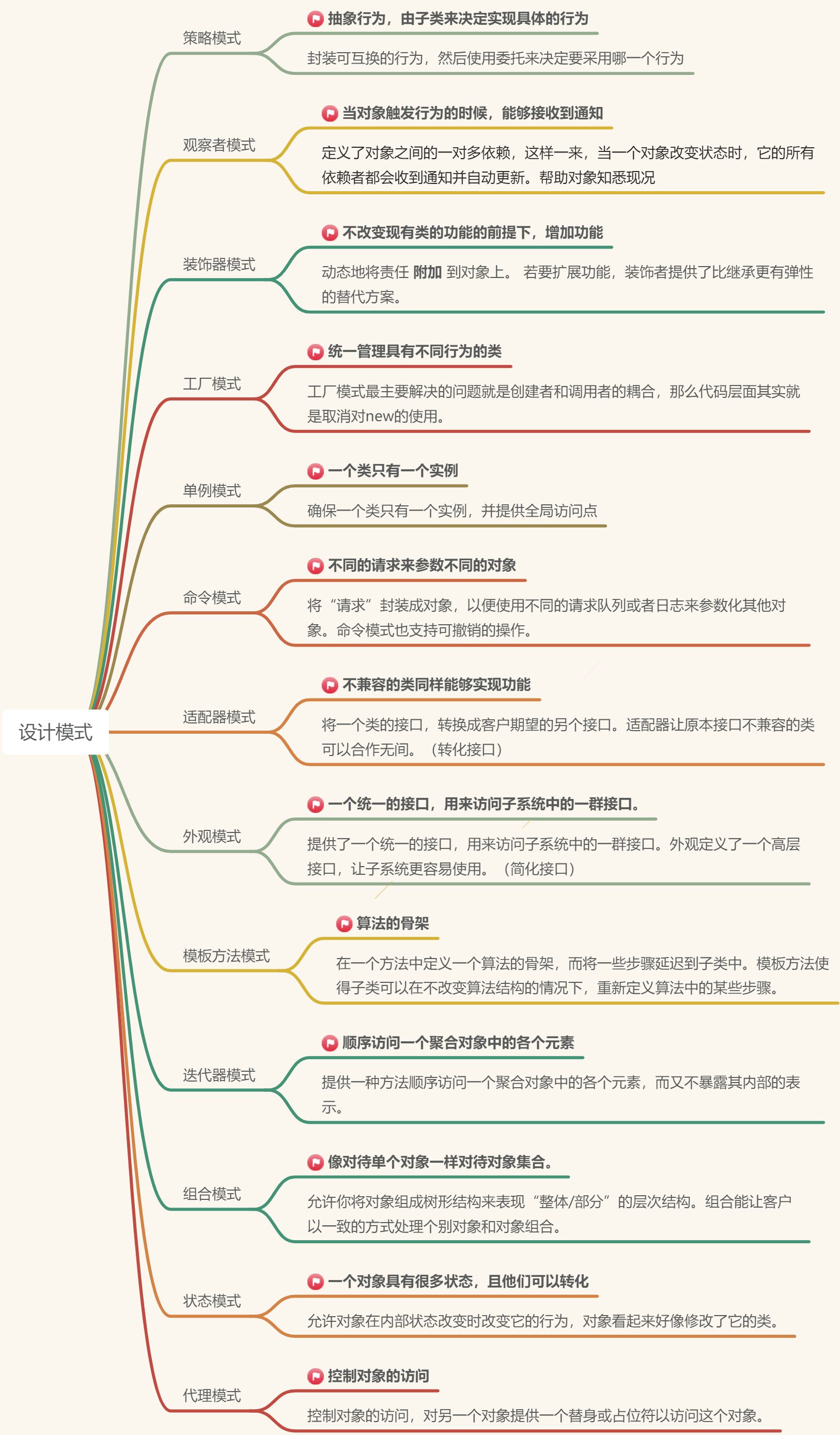
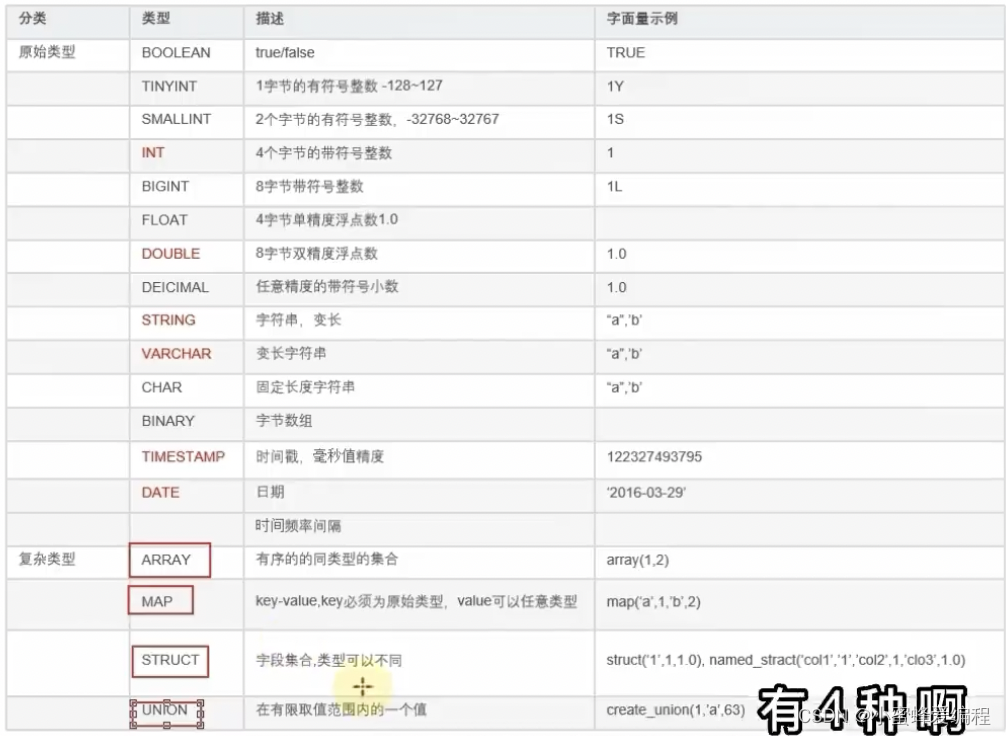
hive数据类型
hive表分类:
(1)内部表
内部表(CREATE TABLE table_name…)
未被external关键字修饰的即是内部表,即普通表。内部表又称管理表,内部表数据存储的位置由
hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据
(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
(2)外部表
外部表(CREATE EXTERNAL TABLE table_name…LOCATION…)
被external关键字修饰的即是外部表,即关联表。
外部表是指表数据可以在任何位置,通过LOCATION关键字指定。数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。这意味着我们可以:
- 先创建表,再在表对应路径创建数据
- 先在对应目录创建数据,再创建表
所以,表和数据是独立的,在删除外部表的时候,仅仅是删除元数据(表的信息),不会删除数据本身。
(3)分区表
(4)分桶表
表的hdfs文件默认分隔符
在hdfs上,hive表数据文件的默认分隔符是"\001",是一个ascii码值,在一些文本文件中显示为SOH,键盘打不出来,cat也看不出来。
设置hive表的分隔符
当然,分隔符我们是可以自行指定的。
在创建表的时候可以自己决定:
create table if not exists stu2(id int name string) row format delimited fields terminated by ‘\t’;
·row format delimited fields terminated by ‘\t’:表示以\t分隔
我们可以指定数据库.表名来指定在哪个数据库中创建表,如下:myhive.stu2

在hive的关系型数据库中,mysql记录的元数据一般在TBLS表中,元数据存储在TBLS中,hive数据存储在hdfs中,虽然他们看起来都是用sql操作,但hdfs存储的数据操作通过map reduce执行的。
查看表属性(eg:属于内部表or外部表…)
desc formatted 表名
返回有个table tyep字段指示了表类型,内部表市MANAGERED_TABLE,外部表市EXTERNAL_TABLE
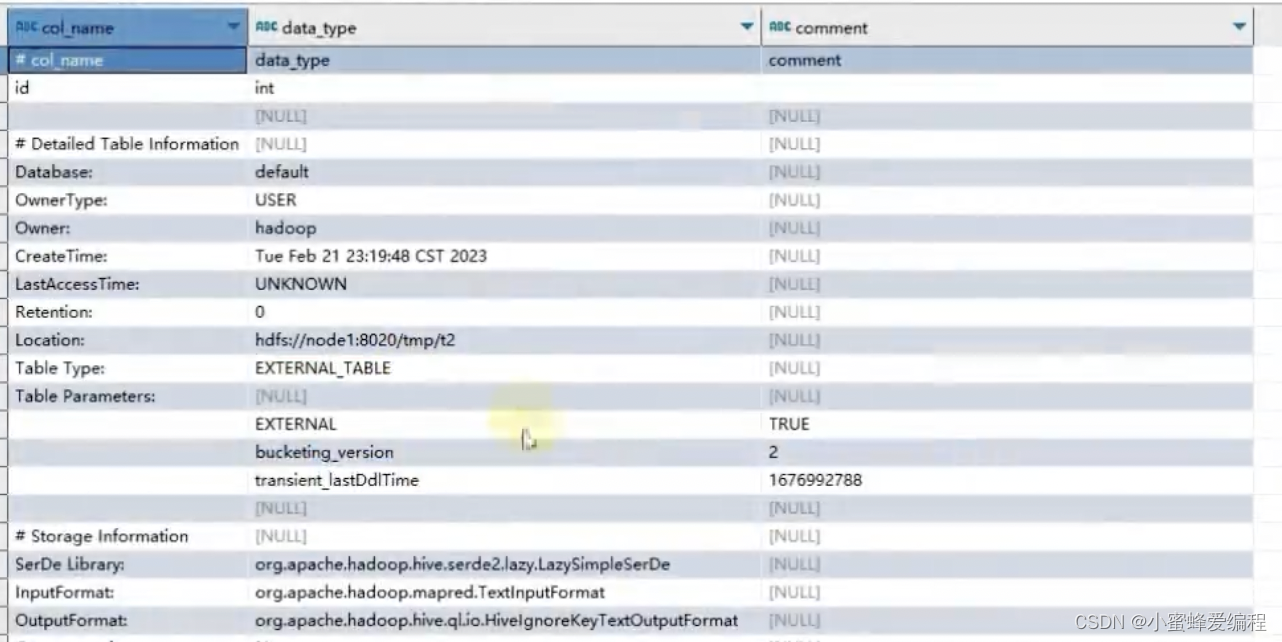
内外部表转换
- 内部表转外部表
alter table stu set tblproperties(‘EXTERNAL’=‘TRUE’); - 外部表转内部表
alter table stu set tblproperties(‘EXTERNAL’=‘FALSE’);
通过stu set tblproperties:来修改属性
要注意:('EXTERNAL=‘FALSE’)或(‘EXTERNAL’=‘TRUE’)为固定写法,区分大小写!!!
使用LOAD从外部加载数据到表中
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename;
这里local参数如果带,则INPATHA需要使用本地文件系统的格式(带file://),表示从本地加载数据,overwrite则覆盖已存数据
需要注意的是,如果是从hdfs加载而非本地,会直接将hdfs路径的文件移动到表指定的路径,源路径的数据会不再存在,另外overwrite字段表示以当前数据为准,以前的表中数据会被清除。
值得注意的是这种方式加载不走mapreduce,因此会比较快,而下面提到的insert相关的都会走map reduce,涉及到资源申请分配,会慢些
数据加载-INSERT SELECT语法
除了load加载外部数据外,我们也可以通过SQL语句,从其它表中加载数据。
语法:
INSERT [OVERWRITE INTO]TABLE tablename1 [PARTITION (partcoll=val1,partcol2=val2 …)[IF NOT EXISTS]]select_statement1 FROM from_statement;
将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
示例:
INSERT INTO TABLE tbl1 SELECT FROM tbl2;
INSERT OVERWRITE TABLE tbl1 SELECT FROM tbl2;
hive表数据导出-insert overwrite方式
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等
语法:insert overwrite [local] directory ‘path’ select_statement FROM from_statement
- 将查询的结果导出到本地-使用默认列分隔符
insert overwrite local directory ‘/home/hadoop/export1’ select * from test_load - 将查询的结果导出到本地-指定列分隔符
insert overwrite local directory ‘/home/hadoop/export2’ row format delimited fields terminated by ‘\t’
select * from test load; - 将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory ‘/tmp/export’ row format delimited fields terminated by ‘\t’ select * from
test_load;
hive表数据导出-hive shell
基本语法:(hive -f/ -e执行语句或者sql脚本 >> file_path)
bin/hive -e “select * from myhive.test_load;” > /home/hadoop/export3/export4.txt
bin/hive -f export.sql > /home/hadoop/export4/export4.txt
export.sql里面存放sql语句
hive分区表
所谓分区表,就是按某个字段作为分区依据,字段值相同的数据存储在同一个分区中,如按日期进行分区,同一个日期的存同一个分区(一般对应同一个文件目录),而分区也存在多层级,只用一个字段分区为单层级,如果我们先按年分区,年分区下又有月或者更多的像按日分区,那么就是多层级分区表
创建分区表
分区表的使用
基本语法:
create table tablename (…) partitioned by(分区列列类型,…)
row format delimited fields terminated by ‘’;

上图中示例不管是创建还是加载,都是没有包含分区列的,但实际上我们的表中会包含分区的列,此外从数据加载到分区表中,partition (month=‘202006’)表示加载到指定分区202006中,而不是从数据内容中读取202006的数据,数据里面是没有month列的,一般有几个分区则hdfs对应的表路径下有几个文件夹

多层级的分区表是按分区顺序创建的目录

对分区表的操作,像插入,是需要指定到具体每一个层级的分区才会操作成功
分桶表
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
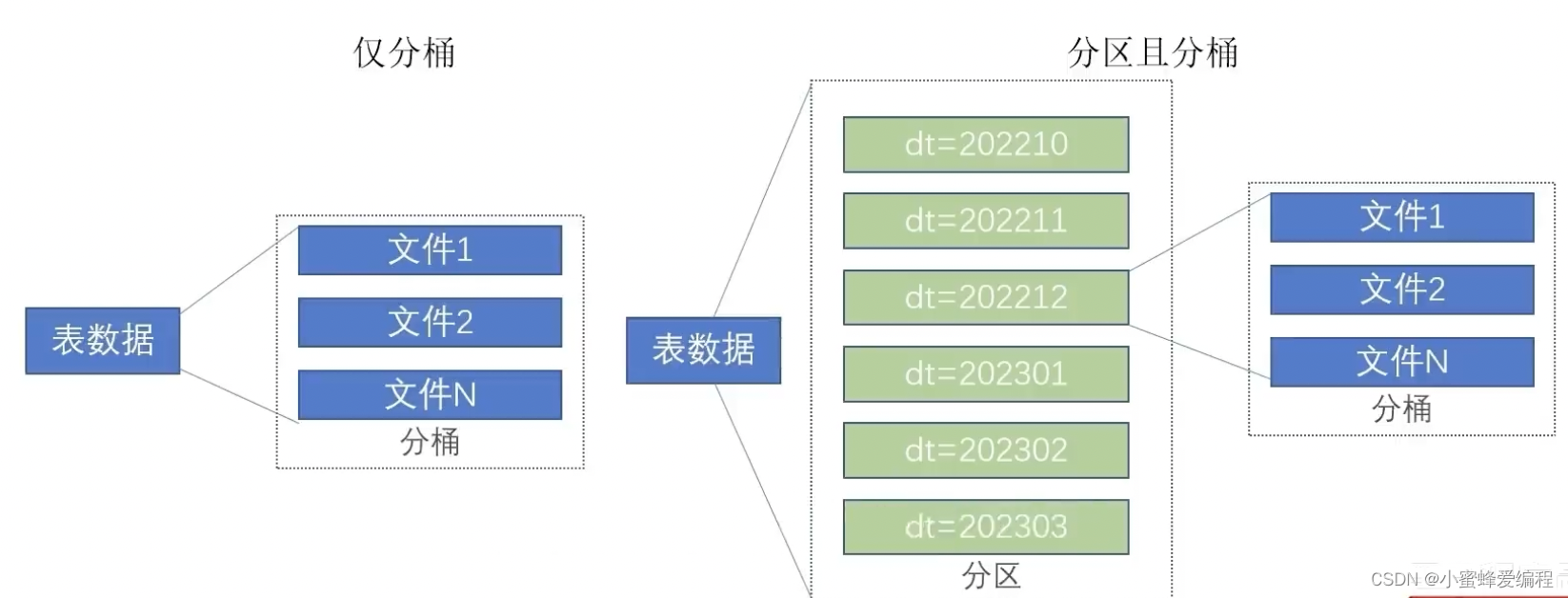
开启分桶表
- 开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true; - 创建分桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by ‘\t’;
上面按c_id列进行分桶
需要注意的是,分桶表不能直接通过load加载,常用的方法是通过临时表加载数据,再通过select insert into方法来插入到分桶表

这里需要注意的是,建表用的是clustered by,插入是cluster by
之所以不能通过load来加载分桶表数据,是因为load不涉及map reduce计算,它只是单纯的文件的操作,而分桶涉及到对指定列进行hash取模计算,会触发map reduce计算,因此需要用select insert into,进行hash取模的目的是为了确定分到哪个桶文件,分桶表对单值过滤会有效率比较高的提升,基于分桶列双表join时效率也更高,同时本身已经基于分桶id分过组了
表修改操作
表重命名
alter table old_table_name rename to new_table_name;
如:alter table score4 rename to score5;
修改表属性值
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:
:(property._name=property_value,property_name=property._value,·…)
如:ALTER TABLE table_name SET TBLPROPERT工ES(“EXTERNAL”=“TRUE”);修改内外部表属性
如:ALTER TABLE table_name SET TBLPROPERTIES(‘comment’=new_comment);修改表注释
其余属性可参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
添加分区
ALTER TABLE tablename ADD PARTITION (month=‘201101’);
新分区是空的没数据,需要手动添加或上传数据文件
修改分区值
ALTER TABLE tablename PARTITION (month=‘202005)RENAME TO PARTITION (month=201105’);
需要注意这里修改分区后,hdfs中文件并不会改名,只是元数据中会记录分区名201105对应的文件名是原来那个文件名
删除分区
ALTER TABLE tablename DROP PARTITION (month=201105’);
只是删除元数据,数据还在
添加列
ALTER TABLE table_name ADD COLUMNS (v1 int,v2 string);
修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;
删除表
DROP TABLE tablename;
清空表
TRUNCATE TABLE tablename;
ps:只可以清空内部表
array类型操作
如下数据文件,有2个列,locations列包含多个城市:
说明:name与locations.之间制表符分隔,locations中元素之间逗号分隔

如果我们想将locations直接当成数据操作计算,就需要用到array类型。
array类型的建表操作如下:

上面COLLECTION ITEMS TERMINATED BY ','表示array类型元素的分隔符是,逗号
加载之后就可以使用数组了

同时,我们也可以通过hive内置函数size来获得数组大小

我们也可以通过一些函数来判断数组中的值

map类型操作
map类型也就是常见的key-value类型
map类型建表语句

上面创建一个string类型的key,string类型的value的map类型,map键值对之间用"#"分隔,key和value之间用:分隔
创建好之后,就可以用类似python里面字典的方式去使用
查询map中指定key

取出map所有key
使用函数map_keys(mymap)可以取出mymap的所有key,返回array

取出map所有value,返回array
使用map_values(mymap)获取所有value数组

获取map大小
使用size(mymap)可获取map大小
select size(mymap) from myhive.test_map
查询指定数据是否在map中
需要注意不能直接判断指定key或value是否存在于map中,但可以借助ARRAY_CONTAINS判断,也可以判断返回数组大小

Struct类型
struct类型可以在一个列中再构建子列,如下案例,假如我们数据中有name和age信息,同时有id编号,我们可以用一个将name和age视为一个people_info列,在其下还有name列和age列
struct应用数据格式案例如下:

struct 建表语句案例如下

我们可以使用.来取struct的成员

与array和map类型不同,struct类型没有对应函数
hive SELECT 查询基本语法
如下,hive查询基本语法与mysql中基本相同,bu’y不一样的是下图中cluster by部分,跟排序相关的

一些基础查询案例如下:
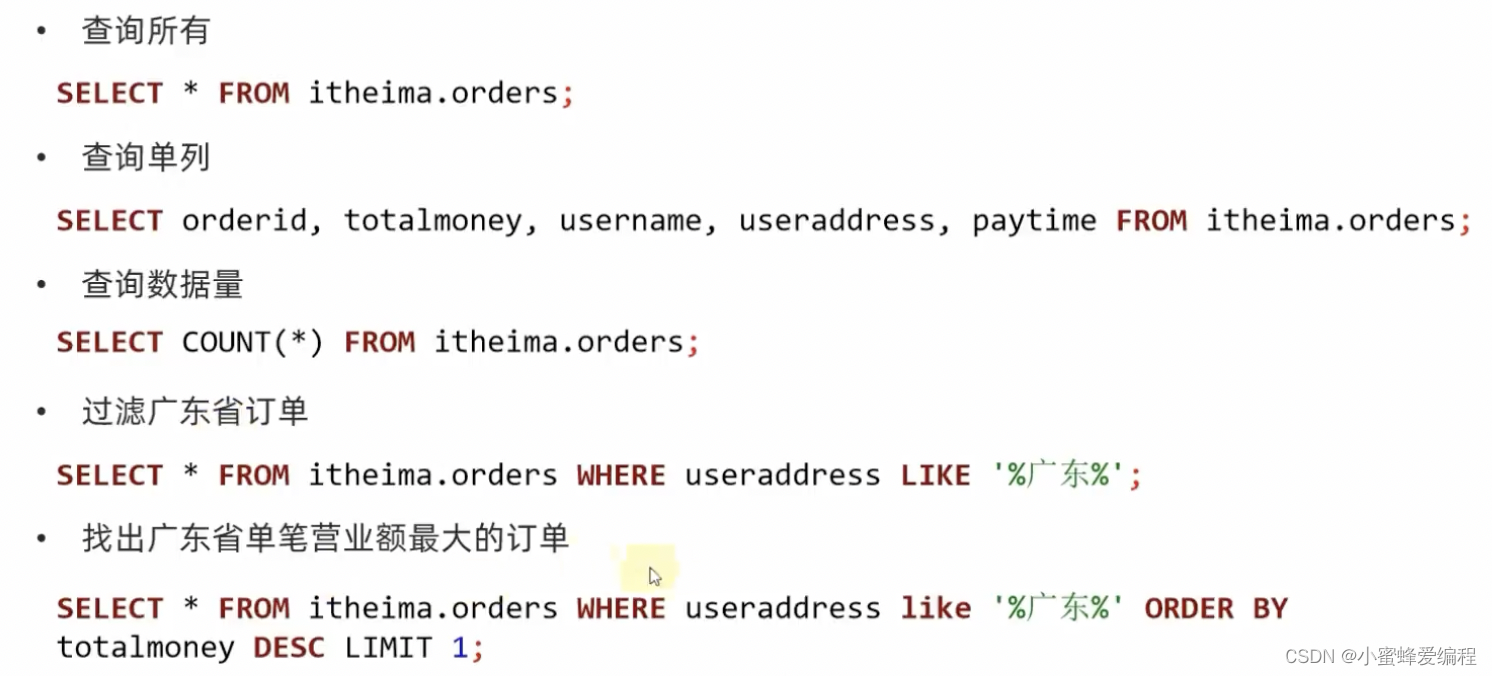
上面用like来进行模糊匹配,表示useraddress中包含广东字段的都会被选中,%在前表示忽略广东前的字符串,在后面表示忽略广东后的字符,只要包含子串广东即可,如果我们不想忽略所有,只想忽略一个,可以用_下划线代替
一些结合内置计算的查询案例如下:

值得注意的是上面最后一个查询用having进行过滤,对按userid分组后,每个分组内平均值大于10000消费的数据进行过滤,与where用法类似,但where不能用于聚合函数之后的结果,只能用在聚合函数之前,having通常跟随group by在其之后使用
join操作

RLIKE正则匹配
hive sql中提供了RLIKE支持正则匹配
常见正则匹配符号
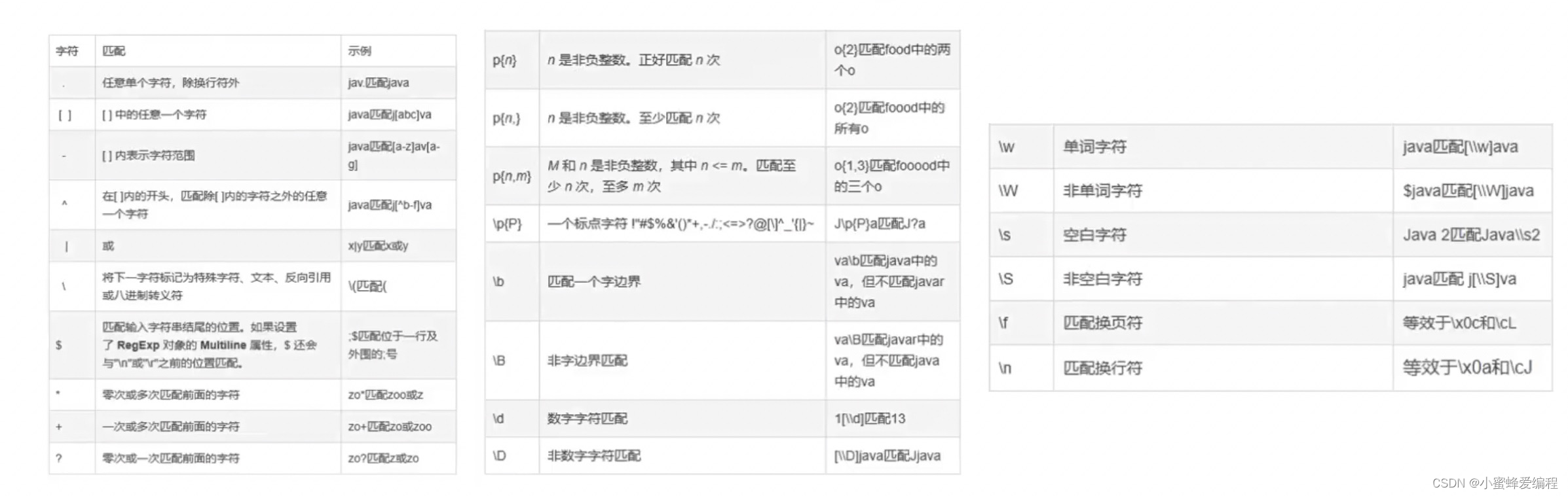
通过组合正则符号,可以灵活实现匹配,如.匹配任意字符,*匹配人员数量,则 .*匹配任意数量字符,包括空,下面来看几个例子

上面第一个sql用.*就实现了我们之前用like模糊匹配%的作用,第三个用[]匹配括号里面的任一个字符,\S去除非空白字符,这里需要注意,所有的\前面都需要加个\,第四个\S后面用{4}限定4个,[0-9]表示匹配0-9之间的任意数字,再用{3}限定匹配个数,其他匹配可参考正则规则自行组合。
UNION联合
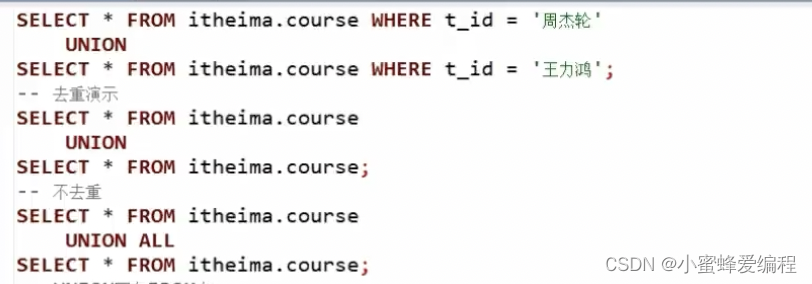
UNION用于将多个SELECT语句的结果组合成单个结果集。
每个select语句返回的列的数量和名称必须相同。否则,将引发架构错误。
union基础语法:

UNION默认会对相同的行做去重,如果不想去重,需要加上ALL,联合的结果按行来组合
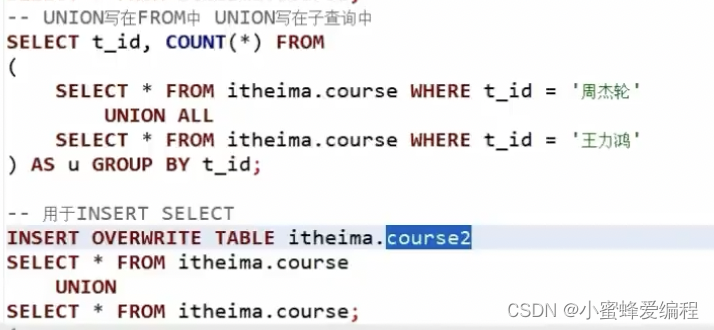
任何可以用select的地方,返回列相同,都可以用union
Hive数据抽样
对表进行随机抽样是非常有必要的。
大数据体系下,在真正的企业环境中,很容易出现很大的表,比如体积达到TB级别。
对这种表一个简单的SELECT*都会非常的慢,哪怕LIMIT10想要看1O条数据,也会走MapReduce流程
这个时间等待是不合适的。
Hiv提供的快速抽样的语法,可以快速从大表中随机抽取一些数据供用户查看。
TABLESAMPLE函数
进行随机抽样,本质上就是用TABLESAMPLE函数
语法1,基于随机分桶抽样
SELECT … FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname rand())
·y表示将表数据随机划分成y份(y个桶)
·x表示从y里面随机抽取x份数据作为取样
·colname表示随机的依据基于某个列的值
·rand()表示随机的依据基于整行
colname和rand二选一
示例:
SELECT username,orderId,totalmoney FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON username);
SELECT FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON rand());
注意:
·使用colname作为随机依据,则其它条件不变下,每次抽样结果一致
·使用rand()作为随机依据,每次抽样结果都不同
通常场景用rand比较快,分桶表的话如果刚好是按colname分桶,用colname比较快
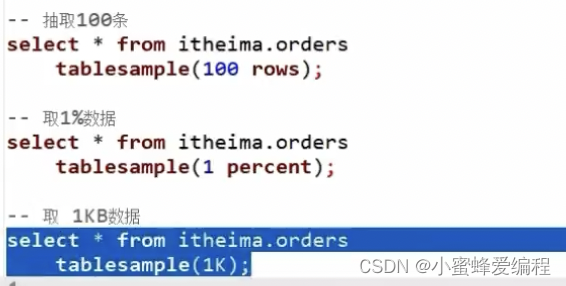
语法2,基于数据块抽样
SELECT … FROM tbl TABLESAMPLE(num ROWS
num PERCENT
num(K|MG));
·num ROWS表示抽样num条数据
·num PERCENT表示抽样num百分百比例的数据
·num(K|M|G)表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
注意:
使用这种语法抽样,条件不变的话,每一次抽样的结果都一致
即无法做到随机,只是按照数据顺序从前向后取
Virtual Columns虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
·INPUT_FILE_NAME,显示数据行所在的具体文件
·BLOCK_OFFSET_INSIDE FILE,显示数据行所在文件的偏移量
·ROW OFFSET INSIDEBLOCK,显示数据所在HDFS块的偏移量,此虚拟列需要设置:SET hive.exec.rowoffset=true才可使用

虚拟列也可以用在where、group by等语句中,根据INPUT_FILE_NAME分组实际上就是分桶。
HIVE函数
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions);
详细的函数使用可以参阅:
·官方文档
(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-MathematicalFunctions)
- 使用show functions查看当下可用的所有函数;
- 通过describe function extended funcname来查看函数的使用方式。
内置函数 - 数值函数
几个常用数值函数示例:
-取整函数:round
返回double类型的整数值部分(遵循四舍五入)
select round (3.1415926):
–指定精度取整函数:round(double a,intd返回指定精度d的double类型
select round(3.1415926, 4);
–取随机数函数:rand每次执行都不一样返回一个0到1范围内的随机数
select rand();
–指定种子取随机数函数:rand(int seed)得到一个稳定的随机数序列
select rand(3);
一求数字的绝对值
select abs(-3):
–得到pi值(小数点后15位精度)
select pi();
内置函数 - 集合函数 COLLECTION FUNCTIONS
以下是hive全部集合函数

内置函数 - 类型转换函数
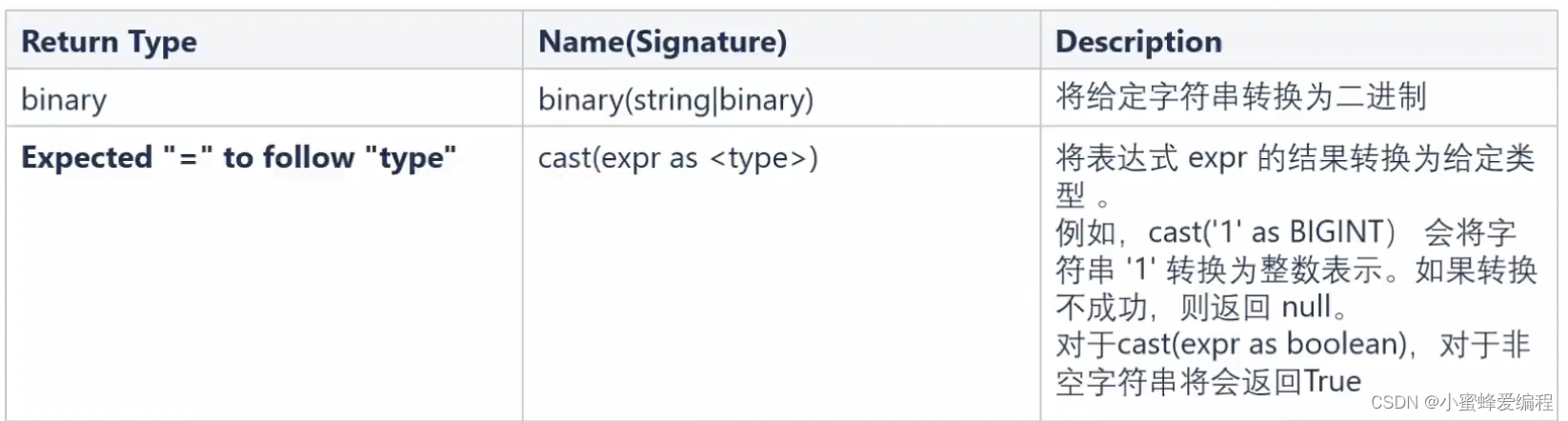
如下示例,需要注意字符串转数值也是不是什么都能转的

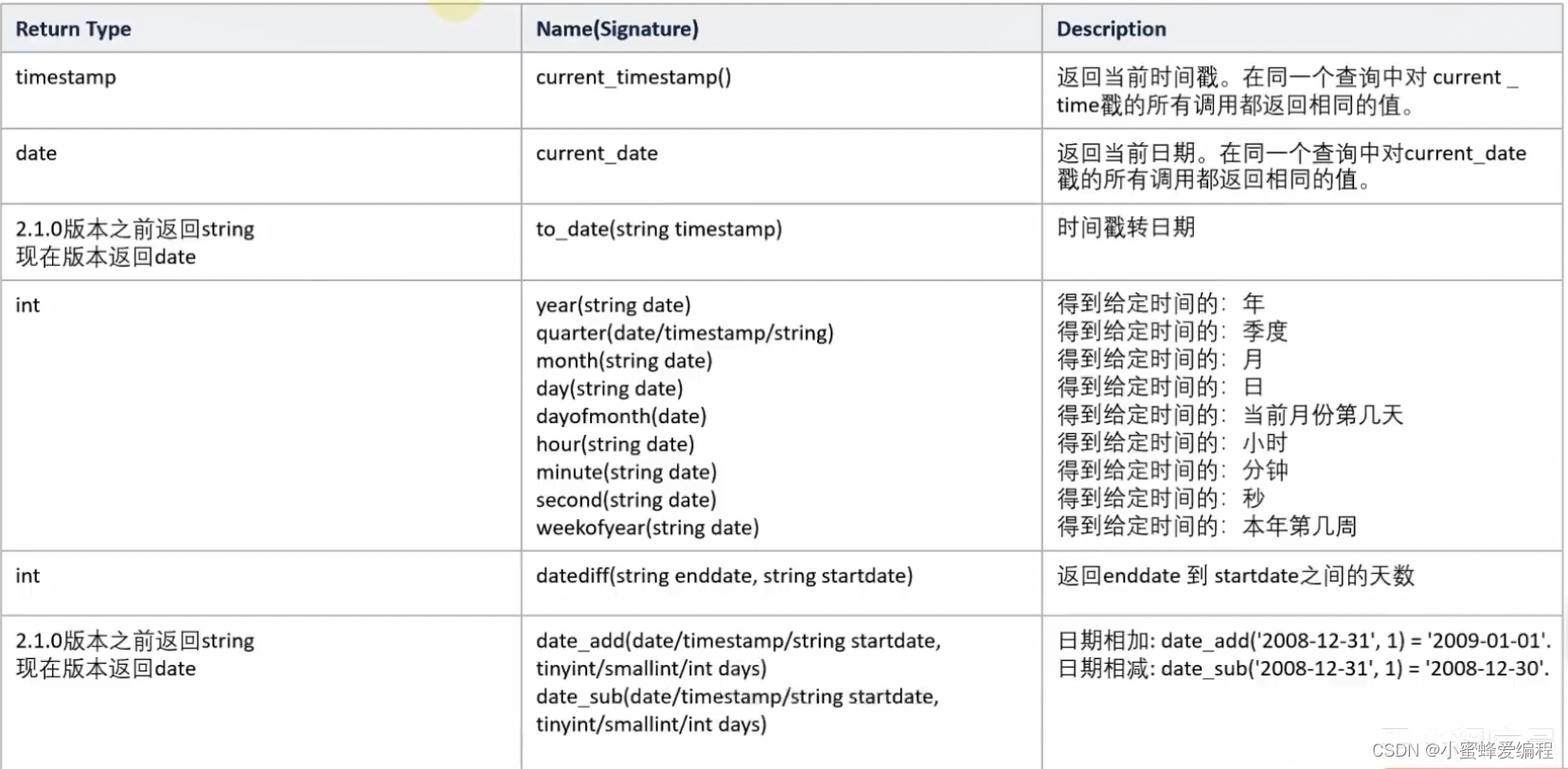
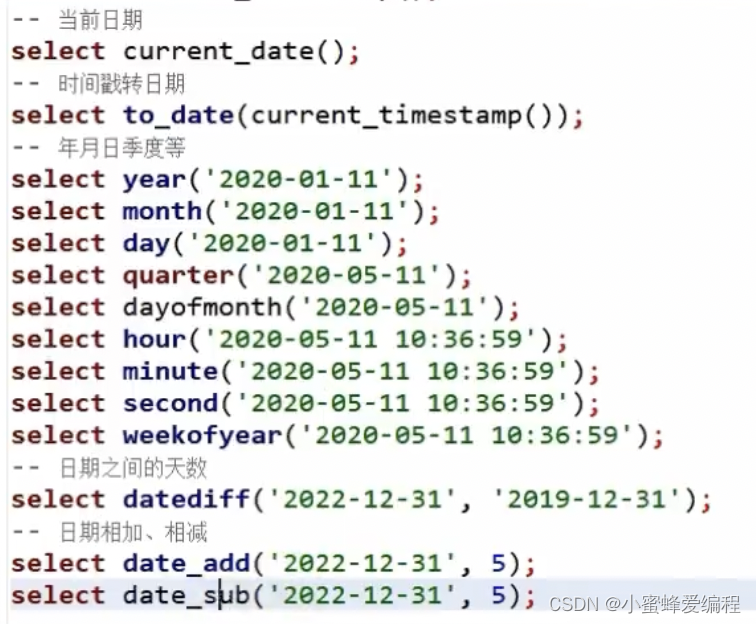
内置函数 – 时间日期函数
部分常用日期函数如下:
内置函数–条件函数
hive的条件函数并不多,以下是全部条件函数列表
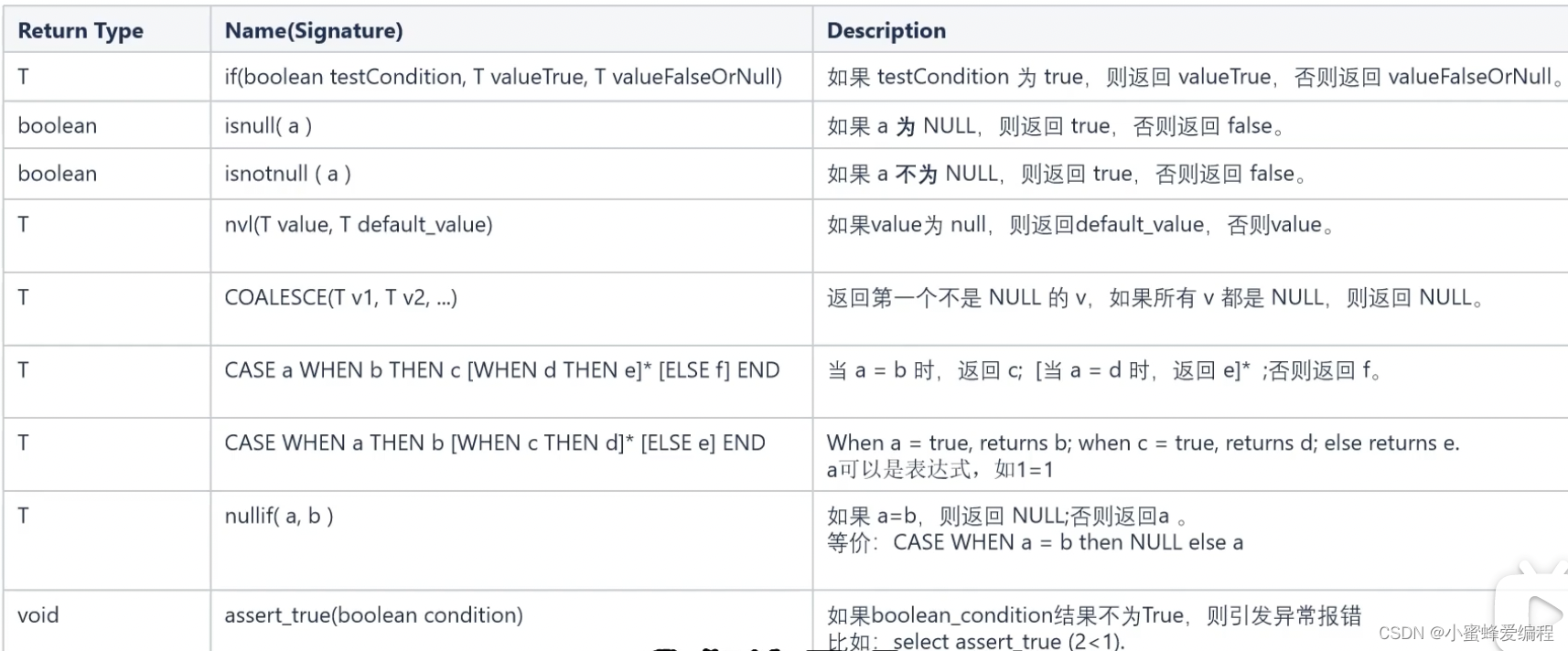
上面的if用法,如果条件为真,返回valueTrue,否则返回valueFalseOrNull

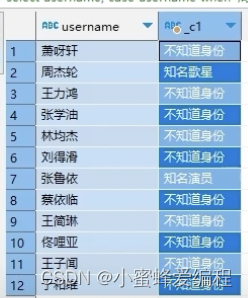
另外,case when的用法中,如下例,会返回username和新增一列对应返回值

coalesce的用法,正如表中描述,返回第一个给定列中不为空的列值并组合成新列,我们也可以给定默认值在参数中,把返回值作为新列,这样就能填充空为默认值。如:
SELECT product_id, COALESCE(commission, 0) AS commission_or_zero FROM sales;
这样commission_or_zero就不会存在空值。
内置函数–字符串函数
下面是部分常用字符串函数

脱敏函数
hive的脱敏函数包含计算hash、加密等,具体可查阅官方文档

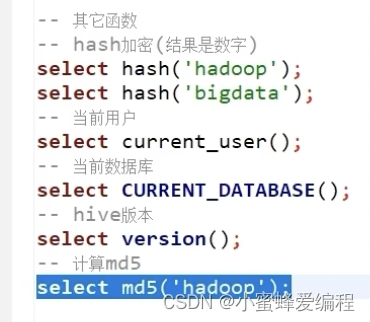
其他常用函数
比较简单,直接看案例即可
hash()
current_user()
current_database()
version()
md5()
ETL概念
从表tb1 查询数据进行数据过滤和转换,并将结果写入到tb2表中的操作
这种操作,本质上是一种简单的ETL行为。
ETL:
·E,Extract,抽取
·T,Transform,转换
·L,Load,加载
从A抽取数据(E),进行数据转换过滤(T),将结果加载到B(L),就是ETL。
BI
BI
Bl:Business Intelligence,商业智能。
指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
简单来说,就是借助工具,可以完成复杂的数据分析、数据统计等需求,为公司决策带来巨大的价值。
所以,一般提到B,我们指代的就是工具软件。常见的B软件很多,比如:
·FineBl
·SuperSet
·PowerBI
·TableAu
FineBI的介绍:https://www.finebi.com/
FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品。FineBI是定位于自助大
数据分析的I工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。
通过fineBi可以连接hive的数据库并将我们的数据进行可视化分析