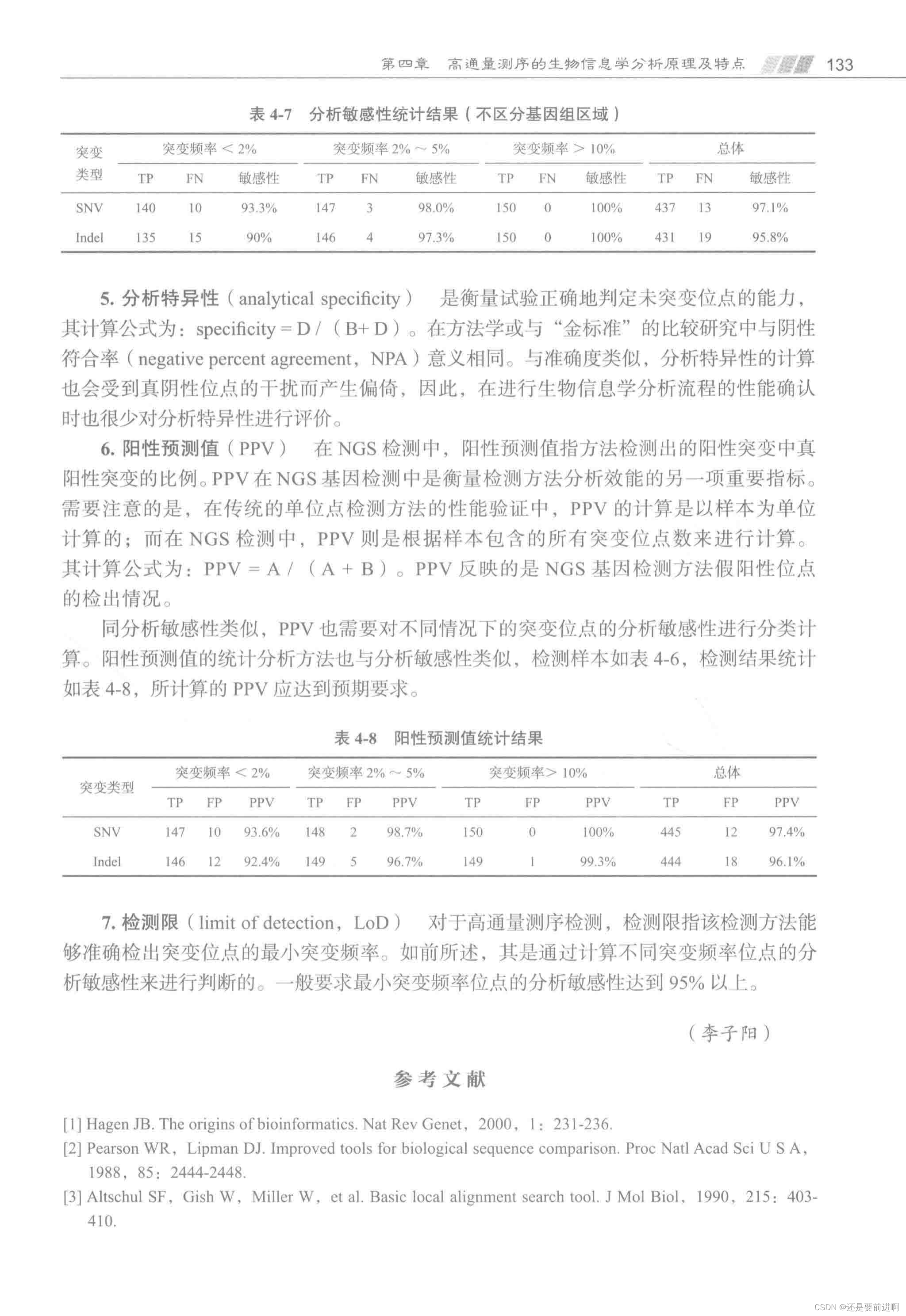
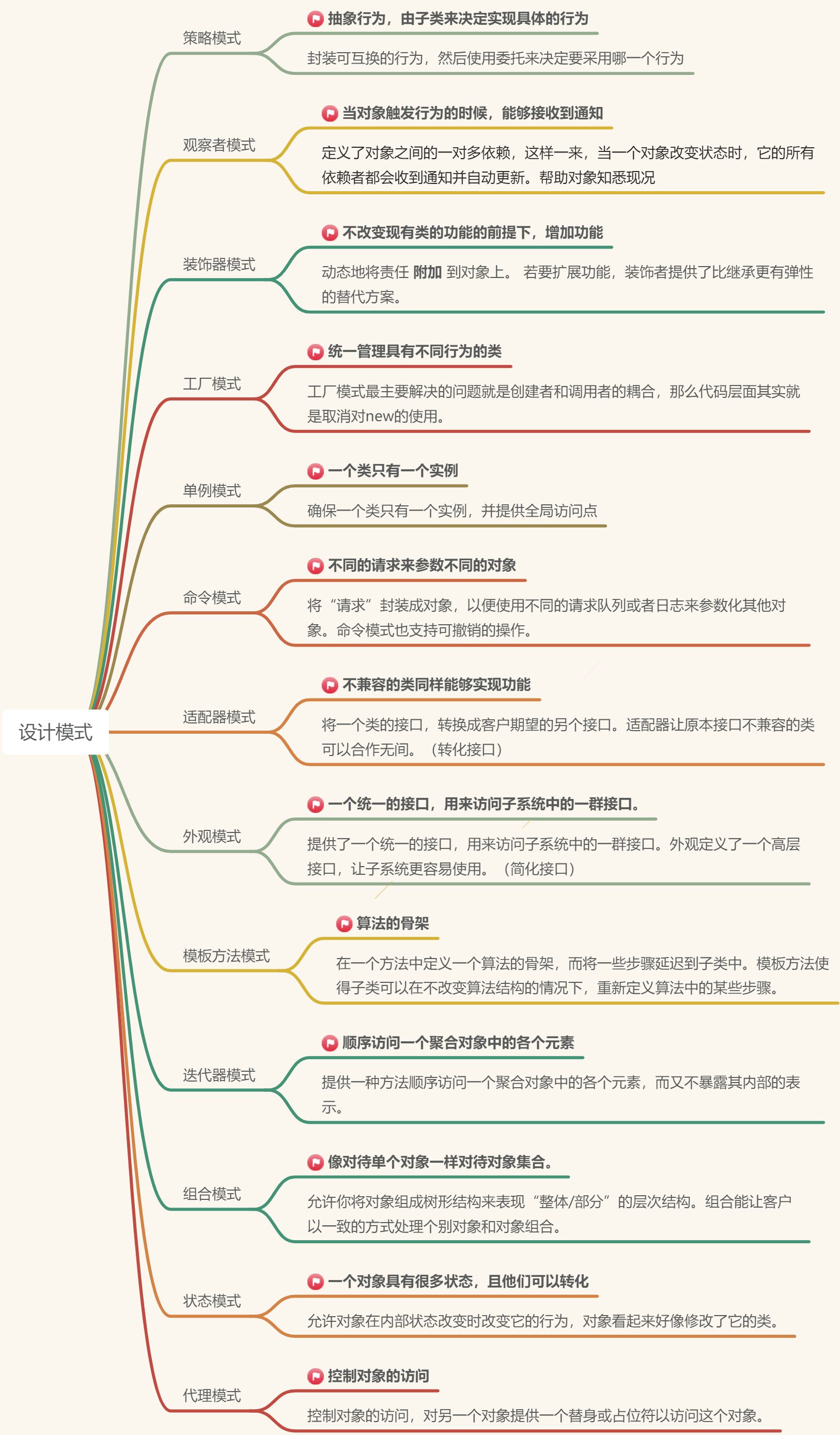
经典机器学习模型(八)梯度提升树GBDT详解
Boosting、Bagging和Stacking是集成学习(Ensemble Learning)的三种主要方法。
Boosting是一族可将弱学习器提升为强学习器的算法,不同于Bagging、Stacking方法,Boosting训练过程为串联方式,弱学习器的训练是有顺序的,每个弱学习器都会在前一个学习器的基础上进行学习,最终综合所有学习器的预测值产生最终的预测结果。
我们之前详细介绍过提升方法中的AdaBoost算法。今天,我们继续来了解下另一种提升方法—梯度提升树GBDT。
传统机器学习(六)集成算法(2)—Adaboost算法原理
1 GBDT原理详解
1.1 初识GBDT
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。
GBDT的原理很简单:
- 所有弱分类器的结果相加等于预测值。
- 每次都以当前预测为基准,下一个弱分类器去拟合
残差(预测值与真实值之间的误差)。 - GBDT的弱分类器使用的是树模型。
注意:实际上每个决策树拟合的都是负梯度,只是当损失函数是均方损失时,负梯度刚好是残差,所以其实残差只是负梯度的一种特例而已,我们后面会详细说明。
下图是一个非常简单的帮助理解的示例,我们用GBDT去预测年龄:
- 第一个弱分类器(第一棵树)预测一个年龄(如20岁),计算发现误差有10岁;
- 第二棵树预测拟合残差,预测值6,计算发现差距还有4岁;
- 第三棵树继续预测拟合残差,预测值3,发现差距只有1岁了;
- 第四课树用1岁拟合剩下的残差,完成。
- 最终,四棵树的结论加起来,得到30岁这个标注答案。

1.2 梯度下降和梯度提升
1.2.1 梯度下降
梯度下降法,我们都比较熟悉。不妨思考这样一个问题,梯度下降法中,为什么在负梯度方向函数值下降最快?
我们目标就是证明负梯度方向函数值下降最快。
假设我们现在处于函数
f
(
x
)
f(x)
f(x)的一个点上,这个点的坐标为
x
⃗
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
\vec{x}=(x_1,x_2,...,x_n)
x=(x1,x2,...,xn),此时函数值为
f
(
x
⃗
)
f(\vec{x})
f(x)。
让我们假设一个下降的方向,这个方向是随机的,我们设这个方向是 l ⃗ = ( l 1 , l 2 , . . . , l n ) \vec{l}=(l_1,l_2,...,l_n) l=(l1,l2,...,ln),那么我们沿着 l ⃗ \vec{l} l下降的意思就是,我们下一步将来到 f ( x ⃗ + l ⃗ ) 。 f(\vec{x}+\vec{l}) 。 f(x+l)。
根据多元函数的一阶泰勒展开公式,我们有:
f
(
x
⃗
+
l
⃗
)
=
f
(
x
⃗
)
+
∑
k
=
1
n
∂
f
∂
x
k
l
k
+
o
(
∣
∣
x
∣
∣
n
)
f(\vec{x}+\vec{l})=f(\vec{x})+\sum_{k=1}^n \frac{\partial f}{\partial x_k}l_k + o(||x||^n)
f(x+l)=f(x)+k=1∑n∂xk∂flk+o(∣∣x∣∣n)
f
(
x
⃗
+
l
⃗
)
−
f
(
x
⃗
)
f(\vec{x}+\vec{l})-f(\vec{x})
f(x+l)−f(x)就是移动后函数值的变化量,也就是说,只要这个值小于零,我们的函数值就在变小。而只要我们可以证明当
l
⃗
\vec{l}
l取到梯度的负方向时这个值小于零且绝对值最大,那么我们就证明了我们的目标。
而
f
(
x
⃗
+
l
⃗
)
−
f
(
x
⃗
)
=
∑
k
=
1
n
∂
f
∂
x
k
l
k
+
o
(
∣
∣
x
∣
∣
n
)
自变量变化值极小的时候
(
∣
∣
l
⃗
∣
∣
极小
)
,我们可以忽略
o
(
∣
∣
x
∣
∣
n
)
而f(\vec{x}+\vec{l})-f(\vec{x})=\sum_{k=1}^n \frac{\partial f}{\partial x_k}l_k + o(||x||^n)\\ 自变量变化值极小的时候(||\vec{l}|| 极小),我们可以忽略o(||x||^n)
而f(x+l)−f(x)=k=1∑n∂xk∂flk+o(∣∣x∣∣n)自变量变化值极小的时候(∣∣l∣∣极小),我们可以忽略o(∣∣x∣∣n)
我们现在仅剩的问题就是如何找到一个方向,使得
∑
k
=
1
n
∂
f
∂
x
k
l
k
\sum_{k=1}^n \frac{\partial f}{\partial x_k}l_k
∑k=1n∂xk∂flk小于零且绝对值最大。
- 我们观察这个式子,它其实是两个向量的数量积,我们知道当两个向量的夹角为0或180度时,该数量积的绝对值取得最大值。
- 而最后一个小于零的条件很容易满足,我们只需要让 l ⃗ = − g r a d f ⃗ \vec{l}=-\vec{grad_f} l=−gradf。这样的话,对于这两个向量来说,他们的每一个维度都互为对方的相反数,因此他们的数量积一定不可能大于零,在实际情况下,他们甚至一直小于零。
- 到这里,我们就证明了当且仅当 l ⃗ \vec{l} l的方向是负梯度方向时,函数值下降最快。
- 因此,使用梯度下降法时为了让函数值下降最快,在参数更新时候就需要沿着负梯度方向更新。
在梯度下降法中,我们经常用 θ 表示参数。 f ( x ⃗ + l ⃗ ) = f ( x ⃗ ) + ∑ k = 1 n ∂ f ∂ x k l k + o ( ∣ ∣ x ∣ ∣ n ) 可以表示为: f ( θ k + 1 ) ≈ f ( θ k ) + ∂ f ( θ k ) ∂ θ k ( θ k + 1 − θ k ) = f ( θ k ) + ∂ f ( θ k ) ∂ θ k ∇ θ 当 ∇ θ = − g r a d f ⃗ = − ∂ f ( θ k ) ∂ θ k 时,下降最快 因此,参数迭代公式 θ k + 1 = θ k + η ∇ θ = θ k − η ∂ f ( θ k ) ∂ θ k 在梯度下降法中,我们经常用\theta表示参数。\\ f(\vec{x}+\vec{l})=f(\vec{x}) + \sum_{k=1}^n \frac{\partial f}{\partial x_k}l_k + o(||x||^n)\\ 可以表示为:f(\theta_{k+1}) \approx f(\theta_{k})+\frac{\partial f(\theta_k)}{\partial \theta_k}(\theta_{k+1}-\theta_k)\\ =f(\theta_{k})+\frac{\partial f(\theta_k)}{\partial \theta_k}\nabla\theta\\ 当\nabla\theta=-\vec{grad_f}=-\frac{\partial f(\theta_k)}{\partial \theta_k}时,下降最快 \\ 因此,参数迭代公式\theta_{k+1}=\theta_k + \eta \nabla\theta =\theta_k - \eta\frac{\partial f(\theta_k)}{\partial \theta_k} 在梯度下降法中,我们经常用θ表示参数。f(x+l)=f(x)+k=1∑n∂xk∂flk+o(∣∣x∣∣n)可以表示为:f(θk+1)≈f(θk)+∂θk∂f(θk)(θk+1−θk)=f(θk)+∂θk∂f(θk)∇θ当∇θ=−gradf=−∂θk∂f(θk)时,下降最快因此,参数迭代公式θk+1=θk+η∇θ=θk−η∂θk∂f(θk)
补充以下泰勒展开公式:

1.2.2 梯度提升原理推导
我们利用一阶泰勒展开公式,对损失函数进行泰勒展开:

在优化
L
(
y
,
F
t
(
x
)
)
L(y,F_t(x))
L(y,Ft(x))的时候:
函数更新公式:
F
t
(
x
)
=
F
t
−
1
(
x
)
−
a
t
∂
L
(
y
,
F
t
−
1
(
x
)
)
∂
F
t
−
1
(
x
)
即
T
t
(
x
)
=
−
a
t
∂
L
(
y
,
F
t
−
1
(
x
)
)
∂
F
t
−
1
(
x
)
所以需要当前的学习器来学习负梯度,这里和
G
B
D
T
中差了一个
a
。
函数更新公式:F_t(x)=F_{t-1}(x)-a_t\frac{\partial L(y,F_{t-1}(x))}{\partial F_{t-1}(x)}\\ 即T_t(x)=-a_t\frac{\partial L(y,F_{t-1}(x))}{\partial F_{t-1}(x)}\\ 所以需要当前的学习器来学习负梯度,这里和GBDT中差了一个a。
函数更新公式:Ft(x)=Ft−1(x)−at∂Ft−1(x)∂L(y,Ft−1(x))即Tt(x)=−at∂Ft−1(x)∂L(y,Ft−1(x))所以需要当前的学习器来学习负梯度,这里和GBDT中差了一个a。
当我们的损失函数为平方损失时候,
L
(
y
,
f
(
x
)
)
=
(
y
−
f
(
x
)
)
2
L(y,f(x))=(y-f(x))^2
L(y,f(x))=(y−f(x))2,此时学习器要学习的负梯度为:
G
B
D
T
中忽略
a
t
,
那么
T
t
(
x
)
=
−
∂
L
(
y
,
F
t
−
1
(
x
)
)
∂
F
t
−
1
(
x
)
这里为了求导方便,损失函数加上
1
2
=
−
∂
1
2
(
y
−
f
(
x
)
)
2
∂
f
(
x
)
f
(
x
)
=
f
t
−
1
(
x
)
=
y
−
f
t
−
1
(
x
)
GBDT中忽略a_t,那么T_t(x)=-\frac{\partial L(y,F_{t-1}(x))}{\partial F_{t-1}(x)}\\ 这里为了求导方便,损失函数加上\frac{1}{2} \\ =-\frac{\partial \frac{1}{2}(y-f(x))^2}{\partial f(x)}_{f(x)=f_{t-1}(x)}\\ =y-f_{t-1}(x)
GBDT中忽略at,那么Tt(x)=−∂Ft−1(x)∂L(y,Ft−1(x))这里为了求导方便,损失函数加上21=−∂f(x)∂21(y−f(x))2f(x)=ft−1(x)=y−ft−1(x)
而
y
−
f
t
−
1
(
x
)
y-f_{t-1}(x)
y−ft−1(x)刚好是残差,因此每个决策树拟合的都是负梯度,只是当损失函数是均方损失时,负梯度刚好是残差,所以其实残差只是负梯度的一种特例而已。
1.2.3 梯度下降VS梯度提升
-
我们已经通过
一阶泰勒展开证明了负梯度方向是下降最快的方向。 -
我们熟悉的梯度下降法是在
参数空间中优化。对于最终的最优解 θ ∗ \theta^* θ∗,是由初始值 θ 0 \theta_0 θ0经过T次迭代之后得到的。
设 θ 0 = − ∂ L ( θ ) ∂ θ 0 ,那么 θ ∗ 表示为 θ ∗ = ∑ t = 0 T a t ∗ [ − ∂ L ( θ ) ∂ θ ] θ = θ t − 1 [ − ∂ L ( θ ) ∂ θ ] θ = θ t − 1 表示 θ 在 θ t − 1 处泰勒展开式的一阶导数 设\theta_0= -\frac{\partial L(\theta)}{\partial \theta_0},那么\theta^*表示为 \\ \theta^*=\sum_{t=0}^T a_t * [-\frac{\partial L(\theta)}{\partial \theta}]_{\theta=\theta_{t-1}} \\ [-\frac{\partial L(\theta)}{\partial \theta}]_{\theta=\theta_{t-1}}表示\theta在\theta_{t-1}处泰勒展开式的一阶导数 设θ0=−∂θ0∂L(θ),那么θ∗表示为θ∗=t=0∑Tat∗[−∂θ∂L(θ)]θ=θt−1[−∂θ∂L(θ)]θ=θt−1表示θ在θt−1处泰勒展开式的一阶导数
-
在
函数空间中,我们也可以借鉴梯度下降的思想,进行最优函数的搜索。对于模型的损失函数 L ( y , F ( x ) ) L(y,F(x)) L(y,F(x)),为了能求出最优的函数 F ∗ ( x ) F^*(x) F∗(x),我们首先也设置初始值 F 0 ( x ) = f 0 ( x ) F_0(x)=f_0(x) F0(x)=f0(x)。 -
以函数 F ( x ) F(x) F(x)为一个整体,与梯度下降法的更新过程一致,假设经过T次迭代得到最优函数 F ∗ ( x ) F^*(x) F∗(x)
F ∗ ( x ) = ∑ t = 0 T f t ( x ) 其中 , f t ( x ) = a t [ − ∂ L ( y , F ( x ) ) ∂ F ( x ) ] F ( x ) = F t − 1 ( x ) F^*(x)=\sum_{t=0}^Tf_t(x) \\ 其中,f_t(x)=a_t[-\frac{\partial L(y,F(x))}{\partial F(x)}]_{F(x)=F_{t-1}(x)} F∗(x)=t=0∑Tft(x)其中,ft(x)=at[−∂F(x)∂L(y,F(x))]F(x)=Ft−1(x) -
可以看到,这里的梯度变量是一个函数,
是在函数空间上求解,而我们以前梯度下降算法是在多维参数空间中的负梯度方向,变量是参数。- 为什么是多维参数,因为一个机器学习模型中可以存在多个参数。
- 而这里的变量是函数,
更新函数通过当前函数的负梯度方向来修正模型,使模型更优,最后累加的模型为近似最优函数。

- Gradient Boosting算法在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最终实现对模型的更新。
梯度提升和梯度下降的区别和联系:
-
两者都是在每一轮迭代中,利用损失函数相对于模型的负梯度方向的信息来对当前模型进行更新
-
只不过在梯度下降中,模型是以参数化形式表示,从而模型的更新等价于参数的更新。
-
而在梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中,从而大大扩展了可以使用的模型种类。
-
梯度提升Gradient Boosting是Boosting中的一大类算法,它的思想借鉴于梯度下降法,其基本原理是根据
当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。采用决策树(通常为CART树)作为弱分类器的Gradient Boosting算法被称为GBDT。

1.3 几个容易混淆的概念
1.3.1 梯度提升和提升树算法
- 提升树利用加法模型与前向分歩算法实现学习的优化过程。
- 当损失函数是
平方误差损失函数和指数损失函数时,每一步优化是很简单的。 - 但对一般损失函数而言,往往每一步优化并不那么容易。针对这一问题,Freidman提出了梯度提升(gradient boosting)算法。这是利用损失函数的负梯度在当前模型的值
[
−
∂
L
(
y
,
F
(
x
)
)
∂
F
(
x
)
]
F
(
x
)
=
F
t
−
1
(
x
)
[-\frac{\partial L(y,F(x))}{\partial F(x)}]_{F(x)=F_{t-1}(x)}
[−∂F(x)∂L(y,F(x))]F(x)=Ft−1(x)作为
提升树算法中残差的近似值,拟合一个梯度提升模型。
1.3.2 梯度提升和GBDT
- 采用决策树作为弱分类器的Gradient Boosting算法被称为GBDT,GBDT中使用的决策树通常为CART。
- GBDT使用梯度提升(Gradient Boosting)作为训练方法。
-
Gradient Boosting是Boosting中的一大类算法,其中包括:GBDT(Gradient Boosting Decision Tree)、XGBoost(eXtreme Gradient Boosting)、LightGBM (Light Gradient Boosting Machine)和CatBoost(Categorical Boosting)等。
-
回归树可以利用集成学习中的Boosting框架改良升级得到提升树,提升树再经过梯度提升算法改造就可以得到GBDT算法,GBDT再进一步可以升级为XGBoost、LightGBM或者CatBoost。
1.4 GBDT回归算法
1.4.1 相关算法
-
当我们采用的基学习器是决策树时,那么梯度提升算法就具体到了梯度提升决策树。
-
GBDT算法又叫MART(Multiple Additive Regression),是一种迭代的决策树算法。
-
GBDT算法可以看成是 M M M棵树组成的加法模型:

回归问题的提升树算法
我们在初识GBDT中就是使用下面的算法,所用损失函数为均方差损失。

GBDT梯度提升算法
- 当损失函数是
平方误差损失函数和指数损失函数时,每一步优化是很简单的。 - 但对一般损失函数而言,往往每一步优化并不那么容易。针对这一问题,Freidman提出了梯度提升(gradient boosting)算法。
《统计学习方法》中的所写梯度提升算法如下图:

上图中一棵树T(x)换成了公式表达,书中解释如下:

1.4.2 GBDT的回归任务常见的损失函数
对于GBDT回归模型,sklearn中实现了四种损失函数
- 均方差’ls’。默认是均方差’ls’。一般来说,如果数据的噪音点不多,用默认的均方差’ls’比较好。
- 绝对损失’lad’
- Huber损失’huber’,如果是噪音点较多,则推荐用抗噪音的损失函数’huber’。
- 分位数损失’quantile’。而如果我们需要对训练集进行分段预测的时候,则采用’quantile’。


2 GBDT算法案例
《统计学习方法》中例8.2给出一个求解回归问题的提升树模型案例。
一个更加复杂的回归问题的案例:GBDT算法原理以及实例理解
GBDT做二分类案例详解:【完善版】深入理解GBDT二分类算法
GBDT做多分类案例详解:深入理解GBDT多分类算法