回溯算法
回溯算法(backtracking algorithm)是一种通过穷举来解决问题的方法,它的核心思想是从一个初始状态出发,暴力搜索所有可能的解决方案,当遇到正确的解则将其记录,直到找到解或者尝试了所有可能的选择都无法找到解为止。
回溯算法通常采用“深度优先搜索”来遍历解空间。
例题1:给定一棵二叉树,搜索并记录所有值为 7 的节点,请返回节点列表。
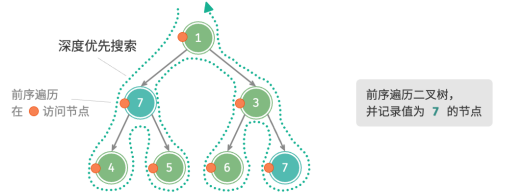
前序遍历这棵树,并判断当前节点的值是否为 7 ,若是,则将该节点的值加入结果列表 res 之中:
// === File: preorder_traversal_i_compact.cpp ===
/* 前序遍历:例题一 */
void preOrder(TreeNode *root) {
if (root == nullptr) {
return;
}
if (root->val == 7) {
// 记录解
res.push_back(root);
}
preOrder(root->left);
preOrder(root->right);
}
尝试与回退
之所以称之为回溯算法,是因为该算法在搜索解空间时会采用“尝试”与“回退”的策略。
当算法在搜索过程中遇到某个状态无法继续前进或无法得到满足条件的解时,它会撤销上一步的选择,退回到之前的状态,并尝试其他可能的选择。
对于例题一,访问每个节点都代表一次“尝试”,而越过叶节点或返回父节点的 return 则表示“回退”。
值得说明的是,回退并不仅仅包括函数返回。
例题2:在二叉树中搜索所有值为 7 的节点,请返回根节点到这些节点的路径。
在例题1代码的基础上,需要借助一个列表 path 记录访问过的节点路径。当访问到值为 7 的节点时,则复制 path 并添加进结果列表 res 。遍历完成后,res 中保存的就是所有的解。代码如下所示:
void preOrder(TreeNode *root) {
if (root == nullptr) {
return;
}
// 尝试
path.push_back(root);
if (root->val == 7) {
// 记录解
res.push_back(path);
}
preOrder(root->left);
preOrder(root->right);
// 回退
path.pop_back();
}
在每次“尝试”中,通过将当前节点添加进 path 来记录路径;而在“回退”前,需要将该节点从 path 中弹出,以恢复本次尝试之前的状态。
可以将尝试和回退理解为“前进”与“撤销”,两个操作互为逆向。

剪枝
复杂的回溯问题通常包含一个或多个约束条件,约束条件通常可用于“剪枝”。
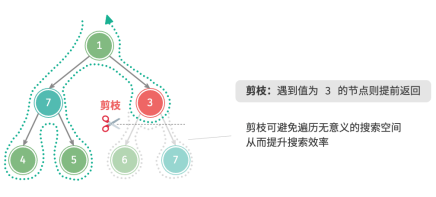
例题3:在二叉树中搜索所有值为 7 的节点,请返回根节点到这些节点的路径,并要求路径中不包含值为 3 的节点。
为了满足以上约束条件,需要添加剪枝操作:在搜索过程中,若遇到值为 3 的节点,则提前返回,不再继续搜索。
void preOrder(TreeNode *root) {
// 剪枝
if (root == nullptr || root->val == 3) {
return;
}
// 尝试
path.push_back(root);
if (root->val == 7) {
// 记录解
res.push_back(path);
}
preOrder(root->left);
preOrder(root->right);
// 回退
path.pop_back();
}
“剪枝”是一个非常形象的名词。如图所示,在搜索过程中,“剪掉”了不满足约束条件的搜索分支,避免许多无意义的尝试,从而提高了搜索效率。
框架代码
接下来,尝试将回溯的“尝试、回退、剪枝”的主体框架提炼出来,提升代码的通用性。
在以下框架代码中,state 表示问题的当前状态,choices 表示当前状态下可以做出的选择:
/* 回溯算法框架 */
void backtrack(State *state, vector<Choice *> &choices, vector<State *> &res) {
// 判断是否为解
if (isSolution(state)) {
// 记录解
recordSolution(state, res);
// 不再继续搜索
return;
}
// 遍历所有选择
for (Choice choice : choices) {
// 剪枝:判断选择是否合法
if (isValid(state, choice)) {
// 尝试:做出选择,更新状态
makeChoice(state, choice);
backtrack(state, choices, res);
// 回退:撤销选择,恢复到之前的状态
undoChoice(state, choice);
}
}
}
基于框架代码来解决例题三。状态 state 为节点遍历路径,选择 choices 为当前节点的左子节点和右子节点,结果 res 是路径列表:
/**
* File: preorder_traversal_iii_template.cpp
* Created Time: 2023-04-16
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 判断当前状态是否为解 */
bool isSolution(vector<TreeNode *> &state) {
return !state.empty() && state.back()->val == 7;
}
/* 记录解 */
void recordSolution(vector<TreeNode *> &state, vector<vector<TreeNode *>> &res) {
res.push_back(state);
}
/* 判断在当前状态下,该选择是否合法 */
bool isValid(vector<TreeNode *> &state, TreeNode *choice) {
return choice != nullptr && choice->val != 3;
}
/* 更新状态 */
void makeChoice(vector<TreeNode *> &state, TreeNode *choice) {
state.push_back(choice);
}
/* 恢复状态 */
void undoChoice(vector<TreeNode *> &state, TreeNode *choice) {
state.pop_back();
}
/* 回溯算法:例题三 */
void backtrack(vector<TreeNode *> &state, vector<TreeNode *> &choices, vector<vector<TreeNode *>> &res) {
// 检查是否为解
if (isSolution(state)) {
// 记录解
recordSolution(state, res);
}
// 遍历所有选择
for (TreeNode *choice : choices) {
// 剪枝:检查选择是否合法
if (isValid(state, choice)) {
// 尝试:做出选择,更新状态
makeChoice(state, choice);
// 进行下一轮选择
vector<TreeNode *> nextChoices{choice->left, choice->right};
backtrack(state, nextChoices, res);
// 回退:撤销选择,恢复到之前的状态
undoChoice(state, choice);
}
}
}
/* Driver Code */
int main() {
TreeNode *root = vectorToTree(vector<int>{1, 7, 3, 4, 5, 6, 7});
cout << "\n初始化二叉树" << endl;
printTree(root);
// 回溯算法
vector<TreeNode *> state;
vector<TreeNode *> choices = {root};
vector<vector<TreeNode *>> res;
backtrack(state, choices, res);
cout << "\n输出所有根节点到节点 7 的路径,要求路径中不包含值为 3 的节点" << endl;
for (vector<TreeNode *> &path : res) {
vector<int> vals;
for (TreeNode *node : path) {
vals.push_back(node->val);
}
printVector(vals);
}
}
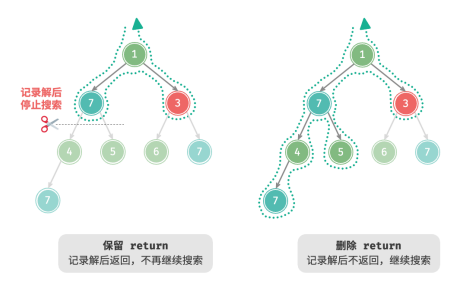
根据题意,我们在找到值为 7 的节点后应该继续搜索,因此需要将记录解之后的 return 语句删除。下图对比了保留或删除 return 语句的搜索过程:
相比基于前序遍历的代码实现,基于回溯算法框架的代码实现虽然显得啰唆,但通用性更好。实际上,许多回溯问题可以在该框架下解决。我们只需根据具体问题来定义 state 和 choices ,并实现框架中的各个方法即可。
常用术语


优点与局限性
回溯算法本质上是一种深度优先搜索算法,它尝试所有可能的解决方案直到找到满足条件的解。这种方法的优点在于能够找到所有可能的解决方案,而且在合理的剪枝操作下,具有很高的效率。
然而,在处理大规模或者复杂问题时,回溯算法的运行效率可能难以接受。
时间:回溯算法通常需要遍历状态空间的所有可能,时间复杂度可以达到指数阶或阶乘阶。
空间:在递归调用中需要保存当前的状态(例如路径、用于剪枝的辅助变量等),当深度很大时,空间需求可能会变得很大。
即便如此,回溯算法仍然是某些搜索问题和约束满足问题的最佳解决方案。对于这些问题,由于无法预测哪些选择可生成有效的解,因此必须对所有可能的选择进行遍历。在这种情况下,关键是如何优化效率,常见的效率优化方法有两种:
剪枝:避免搜索那些肯定不会产生解的路径,从而节省时间和空间。
启发式搜索:在搜索过程中引入一些策略或者估计值,从而优先搜索最有可能产生有效解的路径。
全排列问题
全排列问题是回溯算法的一个典型应用。它的定义是在给定一个集合(如一个数组或字符串)的情况下,找出其中元素的所有可能的排列。

无相等元素的情况
输入一个整数数组,其中不包含重复元素,返回所有可能的排列。
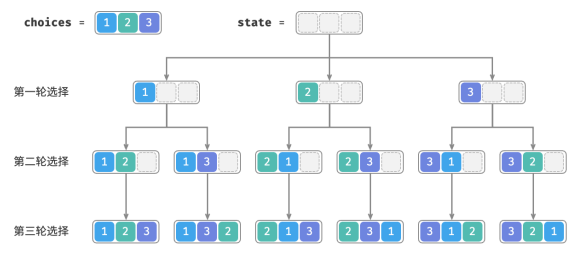
从回溯算法的角度看,可以把生成排列的过程想象成一系列选择的结果。假设输入数组为 [1, 2, 3] ,如果先选择 1 ,再选择 3 ,最后选择 2 ,则获得排列 [1, 3, 2] 。回退表示撤销一个选择,之后继续尝试其他选择。
从回溯代码的角度看,候选集合 choices 是输入数组中的所有元素,状态 state 是直至目前已被选择的元素。请注意,每个元素只允许被选择一次,因此 state 中的所有元素都应该是唯一的。
如图所示,可以将搜索过程展开成一棵递归树,树中的每个节点代表当前状态 state 。从根节点开始,经过三轮选择后到达叶节点,每个叶节点都对应一个排列。
1.重复选择剪枝
为了实现每个元素只被选择一次,考虑引入一个布尔型数组 selected ,其中 selected[i] 表示 choices[i] 是否已被选择,并基于它实现以下剪枝操作:
1.在做出选择 choice[i] 后,就将 selected[i] 赋值为 True ,代表它已被选择。
2.遍历选择列表 choices 时,跳过所有已被选择的节点,即剪枝。
假设第一轮选择 1 ,第二轮选择 3 ,第三轮选择 2 ,则需要在第二轮剪掉元素 1 的分支,在第三轮剪掉元素 1 和元素 3 的分支。
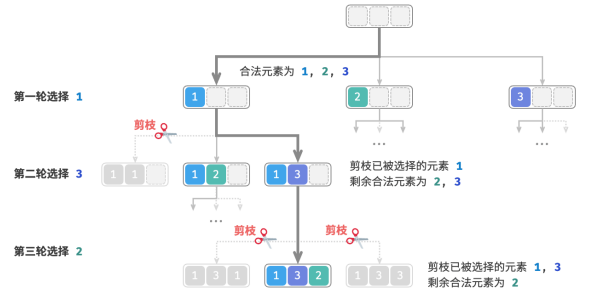
该剪枝操作将搜索空间大小从 𝑂(𝑛^𝑛) 减小至 𝑂(𝑛!) 。
2.代码实现
/**
* File: permutations_i.cpp
* Created Time: 2023-04-24
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:全排列 I */
void backtrack(vector<int> &state, const vector<int> &choices, vector<bool> &selected, vector<vector<int>> &res) {
// 当状态长度等于元素数量时,记录解
if (state.size() == choices.size()) {
res.push_back(state);
return;
}
// 遍历所有选择
for (int i = 0; i < choices.size(); i++) {
int choice = choices[i];
// 剪枝:不允许重复选择元素
if (!selected[i]) {
// 尝试:做出选择,更新状态
selected[i] = true;
state.push_back(choice);
// 进行下一轮选择
backtrack(state, choices, selected, res);
// 回退:撤销选择,恢复到之前的状态
selected[i] = false;
state.pop_back();
}
}
}
/* 全排列 I */
vector<vector<int>> permutationsI(vector<int> nums) {
vector<int> state;
vector<bool> selected(nums.size(), false);
vector<vector<int>> res;
backtrack(state, nums, selected, res);
return res;
}
/* Driver Code */
int main() {
vector<int> nums = {1, 2, 3};
vector<vector<int>> res = permutationsI(nums);
cout << "输入数组 nums = ";
printVector(nums);
cout << "所有排列 res = ";
printVectorMatrix(res);
return 0;
}
2.考虑相等元素的情况
输入一个整数数组,数组中可能包含重复元素,返回所有不重复的排列。
假设输入数组为 [1, 1, 2] 。为了方便区分两个重复元素 1 ,我们将第二个 1 记为 1̂。
上述方法生成的排列有一半是重复的。
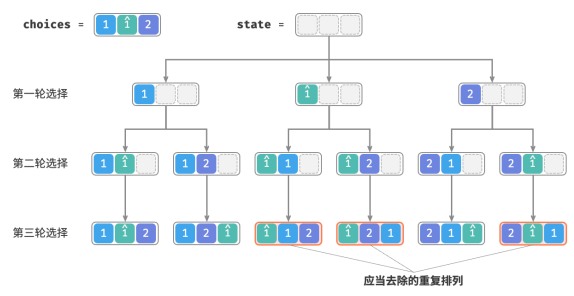
**那么如何去除重复的排列呢?**最直接地,考虑借助一个哈希表,直接对排列结果进行去重。然而这样做不够优雅,因为生成重复排列的搜索分支没有必要,应当提前识别并剪枝,这样可以进一步提升算法效率。
1.相等元素剪枝
在第一轮中,选择 1 或选择1̂是等价的,在这两个选择之下生成的所有排列都是重复的。因此应该把 1̂剪枝。
同理,在第一轮选择 2 之后,第二轮选择中的 1 和 1̂也会产生重复分支,因此也应将第二轮的 1̂剪枝。
从本质上看,目标是在某一轮选择中,保证多个相等的元素仅被选择一次。
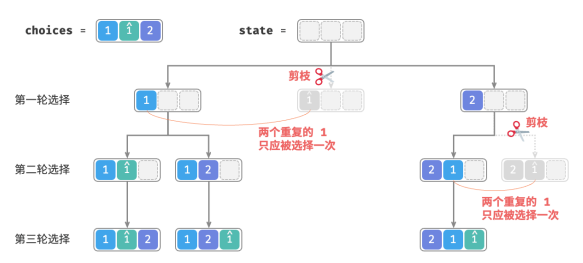
2.代码实现
考虑在每一轮选择中开启一个哈希表 duplicated ,用于记录该轮中已经尝试过的元素,并将重复元素剪枝。
/**
* File: permutations_ii.cpp
* Created Time: 2023-04-24
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:全排列 II */
void backtrack(vector<int> &state, const vector<int> &choices, vector<bool> &selected, vector<vector<int>> &res) {
// 当状态长度等于元素数量时,记录解
if (state.size() == choices.size()) {
res.push_back(state);
return;
}
// 遍历所有选择
unordered_set<int> duplicated;
for (int i = 0; i < choices.size(); i++) {
int choice = choices[i];
// 剪枝:不允许重复选择元素 且 不允许重复选择相等元素
if (!selected[i] && duplicated.find(choice) == duplicated.end()) {
// 尝试:做出选择,更新状态
duplicated.emplace(choice); // 记录选择过的元素值
selected[i] = true;
state.push_back(choice);
// 进行下一轮选择
backtrack(state, choices, selected, res);
// 回退:撤销选择,恢复到之前的状态
selected[i] = false;
state.pop_back();
}
}
}
/* 全排列 II */
vector<vector<int>> permutationsII(vector<int> nums) {
vector<int> state;
vector<bool> selected(nums.size(), false);
vector<vector<int>> res;
backtrack(state, nums, selected, res);
return res;
}
/* Driver Code */
int main() {
vector<int> nums = {1, 1, 2};
vector<vector<int>> res = permutationsII(nums);
cout << "输入数组 nums = ";
printVector(nums);
cout << "所有排列 res = ";
printVectorMatrix(res);
return 0;
}
假设元素两两之间互不相同,则 𝑛 个元素共有 𝑛! 种排列(阶乘);在记录结果时,需要复制长度为 𝑛 的列表,使用 𝑂(𝑛) 时间。因此时间复杂度为 𝑂(𝑛!𝑛) 。
最大递归深度为 𝑛 ,使用 𝑂(𝑛) 栈帧空间。selected 使用 𝑂(𝑛) 空间。同一时刻最多共有 𝑛 个 duplicated ,使用 𝑂(𝑛^2) 空间。因此空间复杂度为 𝑂(𝑛 ^2) 。
3.两种剪枝方法对比
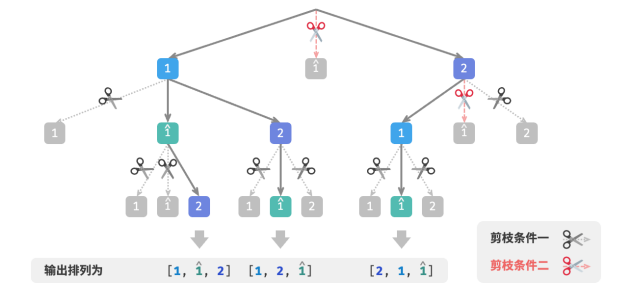
请注意,虽然 selected 和 duplicated 都用于剪枝,但两者的目标不同:
1.重复选择剪枝:整个搜索过程中只有一个 selected 。它记录的是当前状态中包含哪些元素,其作用是避免某个元素在 state 中重复出现。
2.相等元素剪枝:每轮选择(每个调用的 backtrack 函数)都包含一个 duplicated 。它记录的是在本轮遍历(for 循环)中哪些元素已被选择过,其作用是保证相等元素只被选择一次。
两种剪枝条件的作用范围:
子集和问题
无重复元素的情况
给定一个正整数数组 nums 和一个目标正整数 target ,请找出所有可能的组合,使得组合中的元素和等于 target 。给定数组无重复元素,每个元素可以被选取多次。请以列表形式返回这些组合,列表中不应包含重复组合。
例如,输入集合 {3, 4, 5} 和目标整数 9 ,解为 {3, 3, 3}, {4, 5} 。需要注意以下两点:
1.输入集合中的元素可以被无限次重复选取。
2.子集不区分元素顺序,比如 {4, 5} 和 {5, 4} 是同一个子集。
1.参考全排列解法
类似于全排列问题,可以把子集的生成过程想象成一系列选择的结果,并在选择过程中实时更新“元素和”,当元素和等于 target 时,就将子集记录至结果列表。
而与全排列问题不同的是,本题集合中的元素可以被无限次选取,因此无须借助 selected 布尔列表来记录元素是否已被选择。可以对全排列代码进行小幅修改,初步得到解题代码:
/**
* File: subset_sum_i_naive.cpp
* Created Time: 2023-06-21
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:子集和 I */
void backtrack(vector<int> &state, int target, int total, vector<int> &choices, vector<vector<int>> &res) {
// 子集和等于 target 时,记录解
if (total == target) {
res.push_back(state);
return;
}
// 遍历所有选择
for (size_t i = 0; i < choices.size(); i++) {
// 剪枝:若子集和超过 target ,则跳过该选择
if (total + choices[i] > target) {
continue;
}
// 尝试:做出选择,更新元素和 total
state.push_back(choices[i]);
// 进行下一轮选择
backtrack(state, target, total + choices[i], choices, res);
// 回退:撤销选择,恢复到之前的状态
state.pop_back();
}
}
/* 求解子集和 I(包含重复子集) */
vector<vector<int>> subsetSumINaive(vector<int> &nums, int target) {
vector<int> state; // 状态(子集)
int total = 0; // 子集和
vector<vector<int>> res; // 结果列表(子集列表)
backtrack(state, target, total, nums, res);
return res;
}
/* Driver Code */
int main() {
vector<int> nums = {3, 4, 5};
int target = 9;
vector<vector<int>> res = subsetSumINaive(nums, target);
cout << "输入数组 nums = ";
printVector(nums);
cout << "target = " << target << endl;
cout << "所有和等于 " << target << " 的子集 res = " << endl;
printVectorMatrix(res);
return 0;
}
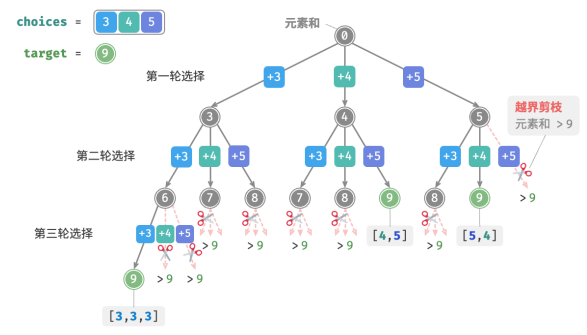
向以上代码输入数组 [3, 4, 5] 和目标元素 9 ,输出结果为 [3, 3, 3], [4, 5], [5, 4] 。虽然成功找出了所有和为 9 的子集,但其中存在重复的子集 [4, 5] 和 [5, 4] 。
这是因为搜索过程是区分选择顺序的,然而子集不区分选择顺序。如图所示,先选 4 后选 5 与先选 5 后选 4 是不同的分支,但对应同一个子集。
为了去除重复子集,一种直接的思路是对结果列表进行去重。但这个方法效率很低,有两方面原因:
1.当数组元素较多,尤其是当 target 较大时,搜索过程会产生大量的重复子集。
2.比较子集(数组)的异同非常耗时,需要先排序数组,再比较数组中每个元素的异同。
2.重复子集剪枝
考虑在搜索过程中通过剪枝进行去重。观察下图,重复子集是在以不同顺序选择数组元素时产生的,
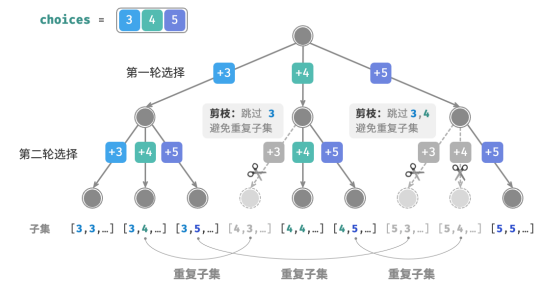
1.当第一轮和第二轮分别选择 3 和 4 时,会生成包含这两个元素的所有子集,记为 [3, 4, … ] 。
2.之后,当第一轮选择 4 时,则第二轮应该跳过 3 ,因为该选择产生的子集 [4, 3, … ] 和第 1. 步中生成的子集完全重复。
在搜索过程中,每一层的选择都是从左到右被逐个尝试的,因此越靠右的分支被剪掉的越多。
1.前两轮选择 3 和 5 ,生成子集 [3, 5, … ] 。
2.前两轮选择 4 和 5 ,生成子集 [4, 5, … ] 。
3.若第一轮选择 5 ,则第二轮应该跳过 3 和 4 ,因为子集 [5, 3, … ] 和 [5, 4, … ] 与第 1 步和第 2 步中描述的子集完全重复。
总结来看,给定输入数组 [ x 1 , x 2 , . . . , x n ] [x_1, x_2, ..., x_n] [x1,x2,...,xn],设搜索过程中的选择序列为 [ x i 1 , x i 2 , . . . , x i m ] [{x_i}_1, {x_i}_2, ..., {x_i}_m] [xi1,xi2,...,xim],则该选择序列需要满足 i 1 ≤ i 2 ≤ . . . ≤ i m i_1 \leq i_2 \leq ... \leq i_m i1≤i2≤...≤im ,不满足该条件的选择序列都会造成重复,应当剪枝。
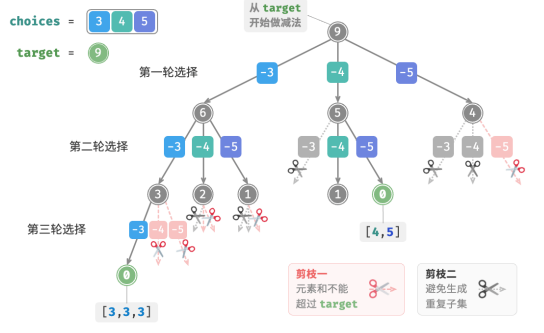
3.代码实现
为实现该剪枝,初始化变量 start ,用于指示遍历起始点。当做出选择 x i x_i xi 后,设定下一轮从索引 𝑖 开始遍历。这样做就可以让选择序列满足 i 1 ≤ i 2 ≤ . . . ≤ i m i_1 \leq i_2 \leq ... \leq i_m i1≤i2≤...≤im ,从而保证子集唯一。
除此之外,还对代码进行了以下两项优化:
1.在开启搜索前,先将数组 nums 排序。在遍历所有选择时,当子集和超过 target 时直接结束循环,因为后边的元素更大,其子集和一定超过 target ;
2.省去元素和变量 total ,通过在 target 上执行减法来统计元素和,当 target 等于 0 时记录解。
/**
* File: subset_sum_i.cpp
* Created Time: 2023-06-21
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:子集和 I */
void backtrack(vector<int> &state, int target, vector<int> &choices, int start, vector<vector<int>> &res) {
// 子集和等于 target 时,记录解
if (target == 0) {
res.push_back(state);
return;
}
// 遍历所有选择
// 剪枝二:从 start 开始遍历,避免生成重复子集
for (int i = start; i < choices.size(); i++) {
// 剪枝一:若子集和超过 target ,则直接结束循环
// 这是因为数组已排序,后边元素更大,子集和一定超过 target
if (target - choices[i] < 0) {
break;
}
// 尝试:做出选择,更新 target, start
state.push_back(choices[i]);
// 进行下一轮选择
backtrack(state, target - choices[i], choices, i, res);
// 回退:撤销选择,恢复到之前的状态
state.pop_back();
}
}
/* 求解子集和 I */
vector<vector<int>> subsetSumI(vector<int> &nums, int target) {
vector<int> state; // 状态(子集)
sort(nums.begin(), nums.end()); // 对 nums 进行排序
int start = 0; // 遍历起始点
vector<vector<int>> res; // 结果列表(子集列表)
backtrack(state, target, nums, start, res);
return res;
}
/* Driver Code */
int main() {
vector<int> nums = {3, 4, 5};
int target = 9;
vector<vector<int>> res = subsetSumI(nums, target);
cout << "输入数组 nums = ";
printVector(nums);
cout << "target = " << target << endl;
cout << "所有和等于 " << target << " 的子集 res = " << endl;
printVectorMatrix(res);
return 0;
}
2.考虑重复元素的情况
给定一个正整数数组 nums 和一个目标正整数 target ,请找出所有可能的组合,使得组合中的元素和等于 target 。给定数组可能包含重复元素,每个元素只可被选择一次。请以列表形式返回这些组合,列表中不应包含重复组合。
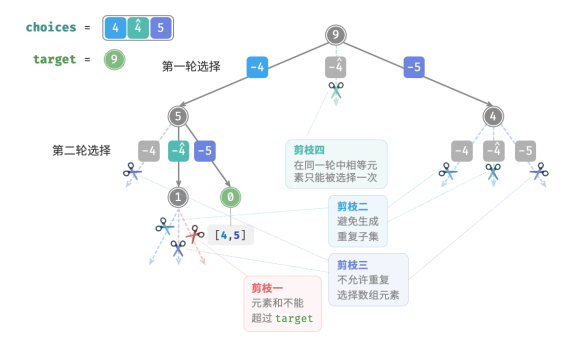
相比于上题,本题的输入数组可能包含重复元素,这引入了新的问题。例如,给定数组 [4, 4, 5] ̂ 和目标元素 9 ,则现有代码的输出结果为 [4, 5], [4, 5] ̂ ,出现了重复子集。
造成这种重复的原因是相等元素在某轮中被多次选择。在下中,第一轮共有三个选择,其中两个都为 4 ,会产生两个重复的搜索分支,从而输出重复子集;同理,第二轮的两个 4 也会产生重复子集。

1. 相等元素剪枝
为解决此问题,需要限制相等元素在每一轮中只能被选择一次。实现方式比较巧妙:由于数组是已排序的,因此相等元素都是相邻的。这意味着在某轮选择中,若当前元素与其左边元素相等,则说明它已经被选择过,因此直接跳过当前元素。
与此同时,本题规定每个数组元素只能被选择一次。幸运的是,也可以利用变量 start 来满足该约束:当做出选择 𝑥_𝑖 后,设定下一轮从索引 𝑖 + 1 开始向后遍历。这样既能去除重复子集,也能避免重复选择元素。
2.代码实现
/**
* File: subset_sum_ii.cpp
* Created Time: 2023-06-21
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:子集和 II */
void backtrack(vector<int> &state, int target, vector<int> &choices, int start, vector<vector<int>> &res) {
// 子集和等于 target 时,记录解
if (target == 0) {
res.push_back(state);
return;
}
// 遍历所有选择
// 剪枝二:从 start 开始遍历,避免生成重复子集
// 剪枝三:从 start 开始遍历,避免重复选择同一元素
for (int i = start; i < choices.size(); i++) {
// 剪枝一:若子集和超过 target ,则直接结束循环
// 这是因为数组已排序,后边元素更大,子集和一定超过 target
if (target - choices[i] < 0) {
break;
}
// 剪枝四:如果该元素与左边元素相等,说明该搜索分支重复,直接跳过
if (i > start && choices[i] == choices[i - 1]) {
continue;
}
// 尝试:做出选择,更新 target, start
state.push_back(choices[i]);
// 进行下一轮选择
backtrack(state, target - choices[i], choices, i + 1, res);
// 回退:撤销选择,恢复到之前的状态
state.pop_back();
}
}
/* 求解子集和 II */
vector<vector<int>> subsetSumII(vector<int> &nums, int target) {
vector<int> state; // 状态(子集)
sort(nums.begin(), nums.end()); // 对 nums 进行排序
int start = 0; // 遍历起始点
vector<vector<int>> res; // 结果列表(子集列表)
backtrack(state, target, nums, start, res);
return res;
}
/* Driver Code */
int main() {
vector<int> nums = {4, 4, 5};
int target = 9;
vector<vector<int>> res = subsetSumII(nums, target);
cout << "输入数组 nums = ";
printVector(nums);
cout << "target = " << target << endl;
cout << "所有和等于 " << target << " 的子集 res = " << endl;
printVectorMatrix(res);
return 0;
}
下展示了数组 [4, 4, 5] 和目标元素 9 的回溯过程,共包含四种剪枝操作。
n 皇后问题
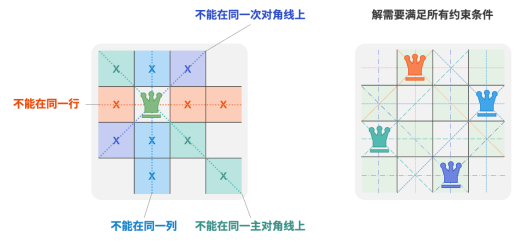
根据国际象棋的规则,皇后可以攻击与同处一行、一列或一条斜线上的棋子。给定 𝑛 个皇后和一个 𝑛 × 𝑛 大小的棋盘,寻找使得所有皇后之间无法相互攻击的摆放方案。
当 𝑛 = 4 时,共可以找到两个解。从回溯算法的角度看,𝑛 × 𝑛 大小的棋盘共有 𝑛^2 个格子,给出了所有的选择 choices 。在逐个放置皇后的过程中,棋盘状态在不断地变化,每个时刻的棋盘就是
状态 state 。

三个约束条件:多个皇后不能在同一行、同一列、同一条对角线上。
1.逐行放置策略
皇后的数量和棋盘的行数都为 𝑛 ,得到推论:棋盘每行都允许且只允许放置一个皇后。
可以采取逐行放置策略:从第一行开始,在每行放置一个皇后,直至最后一行结束。
下图所示为 4 皇后问题的逐行放置过程。受画幅限制,仅展开了第一行的其中一个搜索分支,并且将不满足列约束和对角线约束的方案都进行了剪枝。
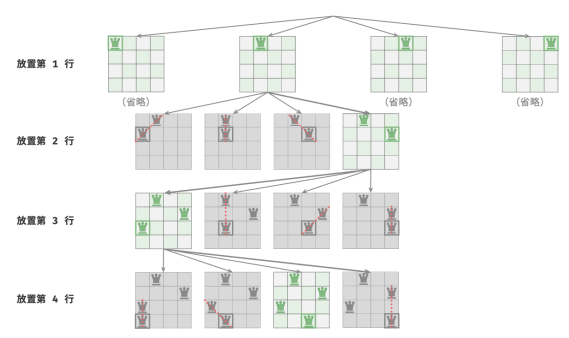
从本质上看,逐行放置策略起到了剪枝的作用,它避免了同一行出现多个皇后的所有搜索分支。
2.列与对角线剪枝
为了满足列约束,可以利用一个长度为 𝑛 的布尔型数组 cols 记录每一列是否有皇后。在每次决定放置前,我们通过 cols 将已有皇后的列进行剪枝,并在回溯中动态更新 cols 的状态。
处理对角线约束:设棋盘中某个格子的行列索引为 (𝑟𝑜𝑤, 𝑐𝑜𝑙) ,选定矩阵中的某条主对角线,发现该对角线上所有格子的行索引减列索引都相等,即对角线上所有格子的 𝑟𝑜𝑤 − 𝑐𝑜𝑙 为恒定值。
也就是说,如果两个格子满足 𝑟𝑜𝑤1 − 𝑐𝑜𝑙1 = 𝑟𝑜𝑤2 − 𝑐𝑜𝑙2 ,则它们一定处在同一条主对角线上。利用该规律,可以借助下图所示的数组 diags1 记录每条主对角线上是否有皇后。
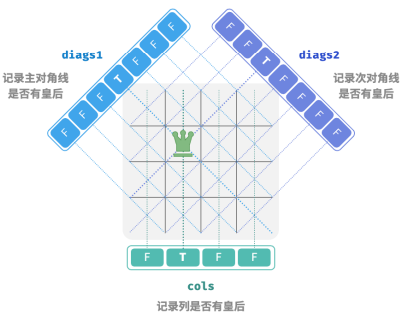
同理,次对角线上的所有格子的 𝑟𝑜𝑤 + 𝑐𝑜𝑙 是恒定值。我们同样也可以借助数组 diags2 来处理次对角线约束。
代码实现
𝑛 维方阵中 𝑟𝑜𝑤 − 𝑐𝑜𝑙 的范围是 [−𝑛 + 1, 𝑛 − 1] ,𝑟𝑜𝑤 + 𝑐𝑜𝑙 的范围是 [0, 2𝑛 − 2] ,所以主对角线和次对角线的数量都为 2𝑛 − 1 ,即数组 diags1 和 diags2 的长度都为 2𝑛 − 1 。
/**
* File: n_queens.cpp
* Created Time: 2023-05-04
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 回溯算法:n 皇后 */
void backtrack(int row, int n, vector<vector<string>> &state, vector<vector<vector<string>>> &res, vector<bool> &cols,
vector<bool> &diags1, vector<bool> &diags2) {
// 当放置完所有行时,记录解
if (row == n) {
res.push_back(state);
return;
}
// 遍历所有列
for (int col = 0; col < n; col++) {
// 计算该格子对应的主对角线和次对角线
int diag1 = row - col + n - 1;
int diag2 = row + col;
// 剪枝:不允许该格子所在列、主对角线、次对角线上存在皇后
if (!cols[col] && !diags1[diag1] && !diags2[diag2]) {
// 尝试:将皇后放置在该格子
state[row][col] = "Q";
cols[col] = diags1[diag1] = diags2[diag2] = true;
// 放置下一行
backtrack(row + 1, n, state, res, cols, diags1, diags2);
// 回退:将该格子恢复为空位
state[row][col] = "#";
cols[col] = diags1[diag1] = diags2[diag2] = false;
}
}
}
/* 求解 n 皇后 */
vector<vector<vector<string>>> nQueens(int n) {
// 初始化 n*n 大小的棋盘,其中 'Q' 代表皇后,'#' 代表空位
vector<vector<string>> state(n, vector<string>(n, "#"));
vector<bool> cols(n, false); // 记录列是否有皇后
vector<bool> diags1(2 * n - 1, false); // 记录主对角线上是否有皇后
vector<bool> diags2(2 * n - 1, false); // 记录次对角线上是否有皇后
vector<vector<vector<string>>> res;
backtrack(0, n, state, res, cols, diags1, diags2);
return res;
}
/* Driver Code */
int main() {
int n = 4;
vector<vector<vector<string>>> res = nQueens(n);
cout << "输入棋盘长宽为 " << n << endl;
cout << "皇后放置方案共有 " << res.size() << " 种" << endl;
for (const vector<vector<string>> &state : res) {
cout << "--------------------" << endl;
for (const vector<string> &row : state) {
printVector(row);
}
}
return 0;
}
逐行放置 𝑛 次,考虑列约束,则从第一行到最后一行分别有 𝑛、𝑛 − 1、…、2、1 个选择,因此时间复杂度为 𝑂(𝑛!) 。实际上,根据对角线约束的剪枝也能够大幅缩小搜索空间,因而搜索效率往往优于以上时间复杂度。
数组 state 使用 𝑂(𝑛 ^2) 空间,数组 cols、diags1 和 diags2 皆使用 𝑂(𝑛) 空间。最大递归深度为 𝑛 ,使用 𝑂(𝑛) 栈帧空间。因此,空间复杂度为 𝑂(𝑛 ^2) 。
学习地址
学习地址:https://github.com/krahets/hello-algo
重新复习数据结构,所有的内容都来自这里。