练习一:
根据下面这段文本,爬取所有的JavaXX
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台。
代码:
public class Test8 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本," +
"目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版本是Java17," +
"相信在未来不久Java17也会逐渐登上历史舞台。";
//创建正则表达式对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//创建文本匹配器对象
Matcher m = p.matcher(str);
//利用循环获取
while(m.find()) {
String s = m.group();
System.out.println(s);
}
}
}注:m.find()会返回一个布尔类型的值,若找到符合正则表达式要求的内容,则会返回true,并且底层方法还会将指针指到该内容的第一个字符和最后一个字符的下一位,它每下一次执行如果返回true还会将指针再指向下一个符合正则表达式要求的内容,它指向符合要求的内容后,m.group()就可以截取指针指向的内容并返回一个字符串。
运行结果:

练习二:
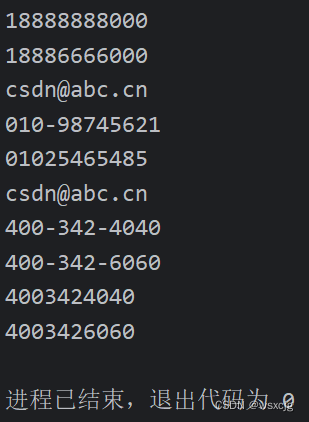
编写代码,将下面文本中的电话、邮箱、座机电话、热点电话都爬取出来
在CSDN学习编程,
电话:18888888000,18886666000
联系邮箱:csdn@abc.cn
座机电话:010-98745621,01025465485
邮箱:csdn@abc.cn
热线电话:400-342-4040,400-342-6060,4003424040,4003426060
代码:
public class Test9 {
public static void main(String[] args) {
String text = "在CSDN学习编程,\n" +
"电话:18888888000,18886666000\n" +
"联系邮箱:csdn@abc.cn\n" +
"座机电话:010-98745621,01025465485\n" +
"邮箱:csdn@abc.cn\n" +
"热线电话:400-342-4040,400-342-6060,4003424040,4003426060";
//电话的正则表达式
String phoneRegex = "1[3-9]\\d{9}";
//邮箱的正则表达式
String emailRegex = "\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2}";
//座机电话的正则表达式
String lanlineRegex = "0\\d{2,3}\\-?[1-9]{4,9}";
//热线电话的正则表达式
String hotPhoneRegex = "400-?[1-9]\\d{2}-?[1-9]\\d{3}";
//整合全部正则表达式
String regex = phoneRegex + "|" + emailRegex + "|" + lanlineRegex + "|" + hotPhoneRegex;
//创建正则表达式对象
Pattern p = Pattern.compile(regex);
//创建文本匹配器对象
Matcher m = p.matcher(text);
//利用循环输出
while(m.find()) {
String str = m.group();
System.out.println(str);
}
}
}运行结果:
练习三:带条件爬取
编写代码按需求爬取下面这段文本:
java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。
需求1:爬取版本号为8,11,17的Java文本,但是只要Java不显示版本号,正确的输出 结果为:JavaJavaJavaJava。
需求2:爬取版本号为8,11,17的Java文本,正确爬取结果为:Java8Java11Java17Java17。
需求3:爬取除了版本号为8,11,17的Java文本,正确的输出结果为:java。
代码:
public class Test10 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版本是Java17," +
"相信在未来不久Java17也会登上历史舞台。";
//需求1:爬取版本号为8,11,17的Java文本,但是只要Java不显示版本号
//正确的输出 结果为:Java Java Java Java。
System.out.println("------需求1------");
//正则表达式为
String regex1 = "Java(?=8|11|17)";//?可以理解为前面的Java,=表示在Java后面跟随的数据,最后获取的时候只获取前半部分
//创建正则表达式对象
Pattern p = Pattern.compile(regex1);
//创建文本匹配器对象
Matcher m = p.matcher(str);
//利用循环输出结果
while(m.find()) {
String s = m.group();
System.out.println(s);
}
//需求2:爬取版本号为8,11,17的Java文本
//正确爬取结果为:Java8 Java11 Java17 Java17。
System.out.println("------需求2------");
//正则表达式为
String regex2 = "Java(?:8|11|17)";//?可以理解为前面的Java,=表示在Java后面跟随的数据,最后获取的时候只获取前半部分
//创建正则表达式对象
p = Pattern.compile(regex2);
//创建文本匹配器对象
m = p.matcher(str);
//利用循环输出结果
while(m.find()) {
String s = m.group();
System.out.println(s);
}
//需求3:爬取除了版本号为8,11,17的Java文本
//正确的输出结果为:Java。
System.out.println("------需求3------");
//正则表达式为
String regex3 = "Java(?!8|11|17)";//?可以理解为前面的Java,=表示在Java后面跟随的数据,最后获取的时候只获取前半部分
//创建正则表达式对象
p = Pattern.compile(regex3);
//创建文本匹配器对象
m = p.matcher(str);
//利用循环输出结果
while(m.find()) {
String s = m.group();
System.out.println(s);
}
}
}运行结果:

练习四:贪婪和非贪婪爬取
(前情提要:贪婪爬取是在爬取的时候尽可能的多获取数据,非贪婪爬取是尽可能的少获取数据,比如在abbbbbbbbbbaaaaaaaaaa中ab+贪婪爬取会得到abbbbbbbbbb,非贪婪爬取会得到ab,Java当中,默认是贪婪爬取,如果在数量词+ * 后加上问号 ? 那么此时就是非贪婪爬取)
编写代码按需求爬取下面这段文本:
java自从95年问世以来,abbbbbbbbbbaaaaaaaaaa,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。
代码:
public class Test11 {
public static void main(String[] args) {
String str = " java自从95年问世以来,abbbbbbbbbbaaaaaaaaaa," +
"经历了很多版本,目前企业中使用最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版本是Java17," +
"相信在未来不久Java17也会登上历史舞台。";
//贪婪爬取
//编写正则表达式
String regex1 = "ab+";
//创建正则表达式对象
Pattern p = Pattern.compile(regex1);
//创建文本匹配器对象
Matcher m = p.matcher(str);
//利用循环输出结果
while(m.find()) {
String s = m.group();
System.out.println("贪婪爬取结果:" + s);
}
//非贪婪爬取
//编写正则表达式
String regex2 = "ab+?";
//创建正则表达式对象
p = Pattern.compile(regex2);
//创建文本匹配器对象
m = p.matcher(str);
//利用循环输出结果
while(m.find()) {
String s = m.group();
System.out.println("非贪婪爬取结果:" + s);
}
}
}运行结果: