一、背景:
在运维paas云平台时有研发反馈客户端访问elasticsearch服务偶发性的出现报错,提示报错如下:
ERROR 1 --- [io-8407-exec-35] c.j.b.c.c.e.s.ElasticOperateServiceImpl : 新增es数据失败
二、问题分析:
报错日志内容核心点如下:
[business-center-msg] [2024-04-09 15:43:26] 2024-04-09 15:43:26.873 ERROR 1 --- [io-8407-exec-35] c.j.b.c.c.e.s.ElasticOperateServiceImpl : 新增es数据失败
[business-center-msg] [2024-04-09 15:43:26]
[business-center-msg] [2024-04-09 15:43:26] org.elasticsearch.ElasticsearchStatusException: Unable to parse response body
[business-center-msg] [2024-04-09 15:43:26] at [2024-04-09 15:43:26] 2024-04-09 15:43:26.882 ERROR 1 --- [io-8407-exec-35] c.j.c.w.c.GlobalExceptionHandler : 【异常信息】
[business-center-msg] [2024-04-09 15:43:26]
[business-center-msg] [2024-04-09 15:43:26] com.jxstjh.common.core.exception.ServiceException: es存储失败:Unable to parse response body
[business-center-msg] [2024-04-09 15:43:26] at com.jxstjh.business.center.commons.es.service.ElasticOperateServiceImpl.insert(ElasticOperateServiceImpl.java:148) ~[business-center-commons-es-1.0-SNAPSHOT.jar!/:na]
[business-center-msg] [2024-04-09 15:43:26] at [business-center-msg] [2024-04-09 15:43:26] Caused by: org.elasticsearch.client.ResponseException: method [PUT], host [http://business-es-service.business-center-prod:9200], URI [/original_message/_create/1777603211016941568?version=-4&timeout=1m], status line [HTTP/1.1 413 Request Entity Too Large]
[business-center-msg] [2024-04-09 15:43:26] <html>
[business-center-msg] [2024-04-09 15:43:26] <head><title>413 Request Entity Too Large</title></head>
[business-center-msg] [2024-04-09 15:43:26] <body>
[business-center-msg] [2024-04-09 15:43:26] <center><h1>413 Request Entity Too Large</h1></center>
[business-center-msg] [2024-04-09 15:43:26] <hr><center>nginx/1.19.10</center>
[business-center-msg] [2024-04-09 15:43:26] </body>
[business-center-msg] [2024-04-09 15:43:26] </html>
[business-center-msg] [2024-04-09 15:43:26] 根据日志报错内容及研发反馈的信息得到如下有用信息:
1、连接elasticsearch服务并请求处理业务是偶发性的提示报错,也就是说明elasticsearch服务是正常的,能正常对外提供服务;
2、日志主要提示报错有Unable to parse response body和nginx服务的413报错;3、日志里是直接连接elasticsearch服务的,但是日志里却提示请求有过一层nginx服务代理;
需要确认的信息:
1、偶发性请求失败报错有什么规律性,或者是特征?
2、确认请求elasticsearch服务是否走了一层nginx代理服务?
疑问1:
通过与研发进行沟通发现是只要请求大小超过1m时就会提示报错的,通过接口调时报错如下:
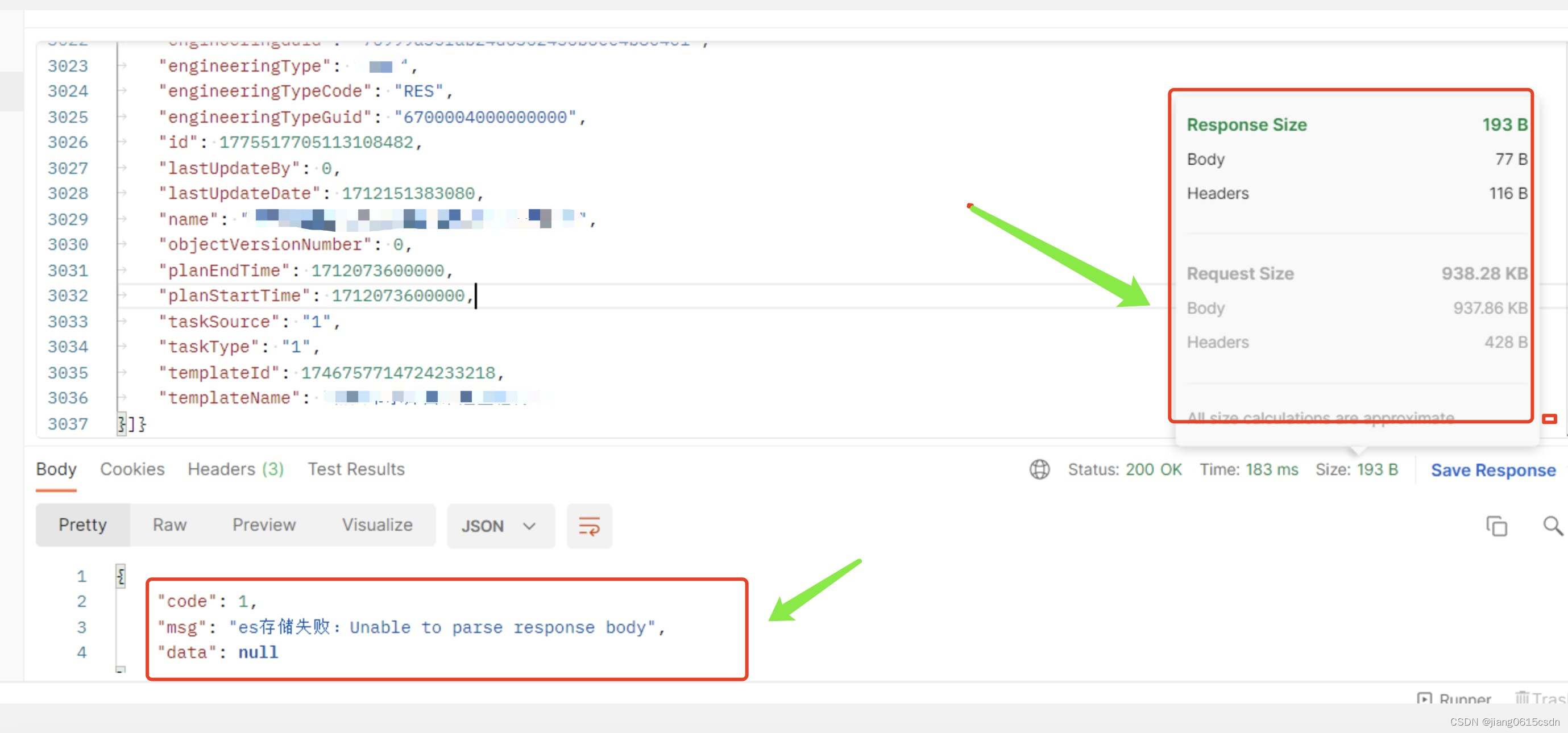
请求正常的接口情况:

疑问2:
检查elasticsearch服务的statfulset控制器yaml文件内容时,确实发现了elasticsearch服务有一层nginx服务做代理,并且时代理了9200端口。

并检查一下elasticsearch服务和nginx服务的配置文件内容:
nginx服务的配置:
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}elasticsearch服务的配置:
[root@business-es-0 config]# cat elasticsearch.yml
cluster.name: "docker-cluster"
network.host: 0.0.0.0
path.data: /data/data
path.logs: /data/logs分析总结:
根据上面的分析可以得出来访问elasticsearch服务出现偶发性的报错,就是因为nginx对http请求有大小的限制,nginx服务默认对http请求有1m大小的限制,elasticsearch服务对http请求有100m的限制。所以需要修复该问题的方式就是将nginx服务的http请求大小配置修改为大于1m的配置就可以了。
三、问题处理:
知道原因之后就好出来了,因为elasticsearch服务是采用statfulset控制器部署的,并且nginx服务的配置文件是因为挂载出来的,现在如果要永久性生效nginx的http请求配置,就需要将nginx配置文件给挂载出来,针对k8s的方式有两种方案:
方案一:
创建一个pvc存储,然后将pvc存储里创建nginx.conf配置文件的内容,但是操作起来麻烦,并且不利于维护;
方案二:
创建configmap组件,并绑定nginx.conf配置文件,操作起来简单,也便以维护;
注:这里选择的是方案二。
1、创建configmap:
这里创建configmap是通过前端操作的,也可以后台操作,这里就说明了

2、修改elasticsearch服务的yaml文件配置:
声明configmap:
volumes:
- name: proxy
configMap:
name: proxy
defaultMode: 420
运用configmap:
volumeMounts:
- name: proxy
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
然后点击保存即可,保存之后会自动重启elasticsaerch集群的。
四、验证:
等待elasticsearch集群重启完成之后,通知研发进行验证即可。结果时可以请求http头大于1m的请求。

到此就分析并处理了该访问elasticsearch服务提示报错问题,希望可以帮助到大家!!!