AIGC实战——StyleGAN
- 0. 前言
- 1. StyleGAN
- 1.1 映射网络
- 1.2 合成网络
- 1.3 自适应实例归一化层
- 1.4 风格混合
- 1.5 随机变化
- 2. StyleGAN 生成样本
- 3. StyleGAN2
- 3.1 权重调制与解调
- 3.2 路径长度正则化
- 3.3 非渐进式增长
- 4. StyleGAN2 生成样本
- 小结
- 系列链接
0. 前言
StyleGAN (Style-Based Generative Adversarial Network) 是于 2018 年提出的一种生成对抗网络 (Generative Adversarial Network, GAN) 架构,该架构建立在 ProGAN 基础之上。实际上,StyleGAN 与 ProGAN 的判别器是相同的,只有生成器发生了变化。本节中,我们将介绍 StyleGAN (Style-Based Generative Adversarial Network) 架构。
1. StyleGAN
在训练生成对抗网络 (Generative Adversarial Network, GAN) 时,通常很难将潜空间中对应于高级属性的向量分离出来,它们通常融合在一起,这意味着虽然调整潜空间中的图像可以使人物具有金色的头发,但这也可能也会无意间改变背景颜色。虽然 ProGAN 能够生成极其逼真的图像,但它也无法解耦潜空间中的特征。如果我们希望完全控制图像的风格,就需要在潜空间中对特征进行解耦。
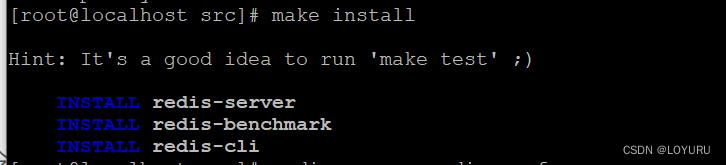
StyleGAN 通过在不同位置将风格向量显式地注入网络来解耦潜空间的特征,包括控制高级特征(例如脸部方向)的向量和控制低级细节特征(例如头发的颜色)的向量。StyleGAN 生成器的整体架构如下图所示,接下来,我们逐步介绍此架构。
`
1.1 映射网络
映射网络 (Mapping Network) 是一个简单的前馈网络,将输入噪声
z
∈
Z
z ∈ \mathcal Z
z∈Z 转换为不同的潜空间
w
∈
W
w ∈ \mathcal W
w∈W。这使得生成器有机会将噪声输入向量分离成不同的特征元素,这些元素可以用于下游的风格生成层解码其特征。
这样做是为了将选择图像风格的过程(映射网络)与生成具有给定风格的图像的过程(合成网络)分开。
1.2 合成网络
合成网络 (Synthesis Network) 是一个生成器,可以根据映射网络提供的风格生成实际图像。风格向量
w
w
w 在不同的位置注入合成网络中,每次通过不同的全连接层
A
i
A_i
Ai 注入,生成两个向量:偏置向量
y
b
,
i
y_{b,i}
yb,i 和缩放向量
y
s
,
i
y_{s,i}
ys,i。这些向量定义了应该在网络中的指定位置注入的特定风格,令合成网络调整特征图以将生成的图像朝指定的风格方向调整,这种调整是通过自适应实例归一化 (adaptive instance normalization, AdaIN) 层实现的。
1.3 自适应实例归一化层
自适应实例归一化 (adaptive instance normalization, AdaIN) 是一种神经网络层,根据风格偏置
y
b
,
i
y_{b,i}
yb,i 和缩放
y
s
,
i
y_{s,i}
ys,i 调整每个特征图
x
i
x_i
xi 的均值和方差。这两个向量的长度与合成网络中的前一卷积层输出的通道数相同。自适应实例归一化的方程如下:
A
d
a
I
N
(
x
i
,
y
)
=
y
x
,
i
x
i
−
μ
(
x
i
)
σ
(
x
i
)
+
y
b
,
i
AdaIN(x_i,y) = y_{x,i}\frac {x_i-\mu(x_i)}{\sigma(x_i)} + y_{b,i}
AdaIN(xi,y)=yx,iσ(xi)xi−μ(xi)+yb,i
自适应实例归一化层确保每个层注入的风格向量仅影响该层的特征,防止风格信息跨层传播,因此潜向量
w
w
w 比原始向量
z
z
z 更具分解性。
由于合成网络基于 ProGAN 架构,因此它采用渐进训练。合成网络中较早的层(图像分辨率为 4 × 4、8 × 8 )的风格向量将影响比后续网络中的层(图像分辨率从 64 × 64 到 1,024 × 1,024 )更整体的特征。这意味着我们不仅可以通过潜向量
w
w
w 完全控制生成的图像,还可以在合成网络的不同位置切换
w
w
w 向量以改变图像的不同细节风格。
1.4 风格混合
风格混合 (Style mixing) 可以确保生成器在训练过程中不能利用相邻风格之间的相关性(即,在每个网络层注入的风格之间尽可能解耦)。对两个潜在向量
(
z
1
,
z
2
)
(z_1,z_2)
(z1,z2) 进行采样,对应于两个风格向量
(
w
1
,
w
2
)
(w_1,w_2)
(w1,w2),而不是仅仅只对单个潜向量 (
z
z
z) 进行采样。然后,在每个层上随机选择 (
w
1
w_1
w1 或
w
2
w_2
w2),以打破向量间可能存在的的任何相关性。
1.5 随机变化
合成器网络在每个卷积层之后添加噪声,以考虑诸如个别头发位置或面部背景之类的随机细节。同样,在不同位置注入噪声会影响图像生成不同细节。
这也意味着合成网络的初始输入可以是一个通过学习得到的常量,而不需要额外的噪声,因为在风格输入和噪声输入中已经包含了足够的随机性,能够生成具有不同变化的逼真图像。
2. StyleGAN 生成样本
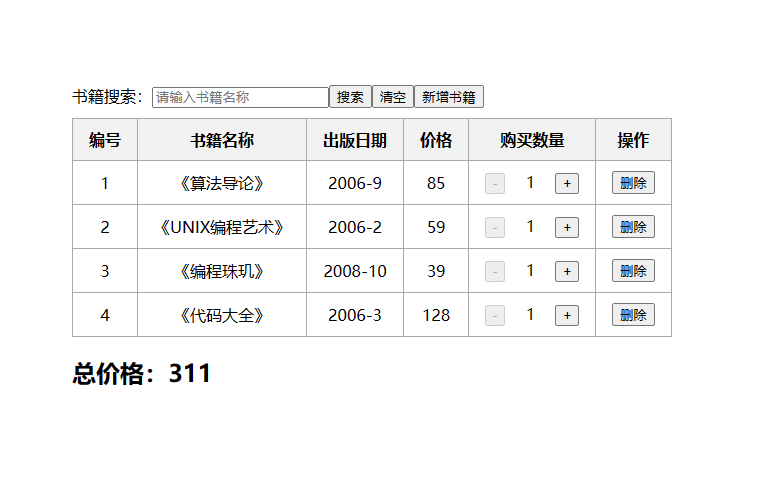
StyleGAN 的图像生成效果如下图所示。

在上图中,图像 A 和图像 B 是使用两个不同的
w
w
w 向量 (
w
A
w_A
wA,
w
B
w_B
wB) 生成两个图像。为了生成合成图像,将图像 A 的
w
w
w 向量
w
A
w_A
wA 通过合成网络进行处理,并在某个时间步,切换为图像 B 的
w
w
w 向量
w
B
w_B
wB。如果切换发生在网络的早期(分辨率为 4 × 4 或 8 × 8 时),则图像B的整体风格(如姿势、脸型和眼镜)会传递到图像 A 上。然而,如果切换发生在网络的晚期,则只有来自图像B的细节风格之处会传递过来(如面部的颜色等细微特征),同时保留了源图像 A 的整体风格。
3. StyleGAN2
StyleGAN2 构建在 StyleGAN 架构的基础上,通过一些关键改进提高了生成图像的质量。值得注意的是,StyleGAN2 并不会受到伪影(图像中的水滴状区域)的影响,这些伪影是由 StyleGAN 中的自适应实例归一化 (adaptive instance normalization, AdaIN) 层引起的。

StyleGAN2 中的生成器和判别器都与 StyleGAN 有所不同,接下来,我们将探讨这两个架构之间的关键差异。
3.1 权重调制与解调
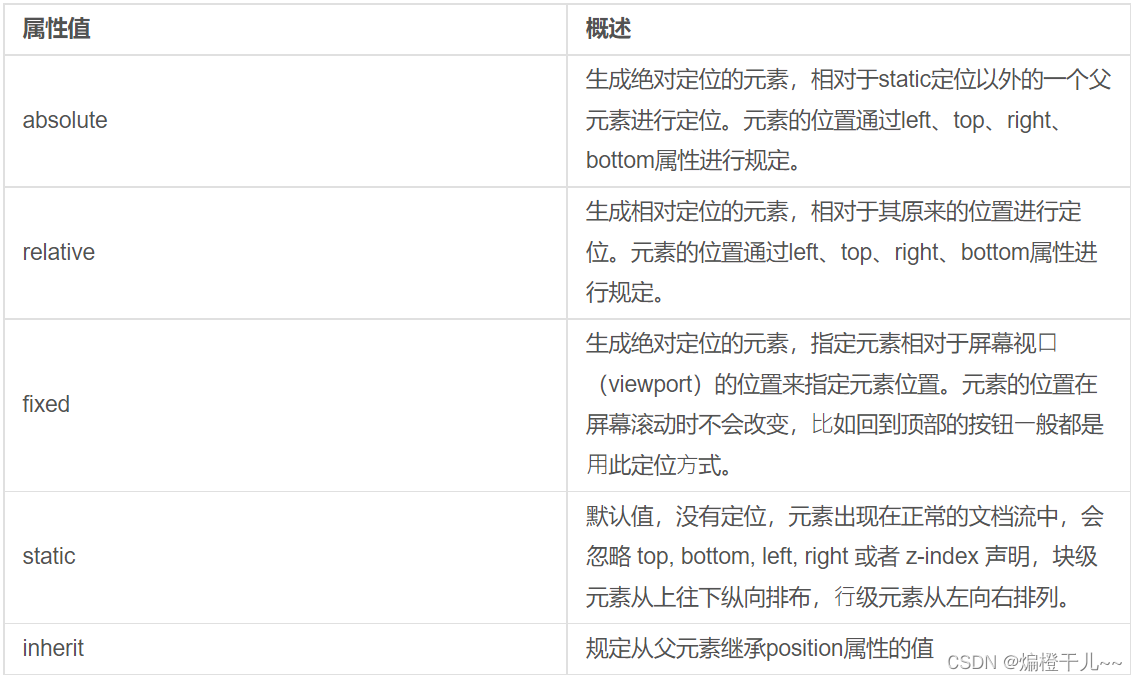
通过移除生成器中的自适应实例归一化 (adaptive instance normalization, AdaIN) 层,并将其替换为权重调制与解调 (Weight Modulation and Demodulation) 步骤,解决了图像伪影问题,如下图所示。
w
w
w 表示卷积层的权重,其在 StyleGAN2 的运行时由调制和解调制步骤直接更新,相比之下,StyleGAN 的 AdaIN 层在图像张量流经网络时对其进行操作。
StyleGAN 中的 AdaIN 层仅仅是一个实例归一化后加样式调制(缩放和偏移),StyleGAN2 是在运行时直接将风格调制和归一化(解调)应用于卷积层的权重,而不是应用于卷积层的输出,如下图所示。使用这一方法能够消除伪影问题,同时使用风格向量保持对图像风格的控制。

在 StyleGAN2 中,每个全连接层A输出一个单独的风格向量
s
i
s_i
si,其中
i
i
i 表示卷积层中的输入通道的索引。然后,将该风格向量应用于卷积层的权重,如下所示:
w
i
,
j
,
k
′
=
s
i
⋅
w
i
,
j
,
k
w_{i,j,k}^{\prime} = si · w_{i,j,k}
wi,j,k′=si⋅wi,j,k
其中,
j
j
j 表示网络层的输出通道索引,
k
k
k 表示空间维度索引。
然后,我们需要对权重进行归一化,使其再次具有单位标准差,以确保训练过程的稳定性,即解调步骤:
w
i
,
j
,
k
′
′
=
w
i
,
j
,
k
′
∑
i
,
k
w
i
,
j
,
k
′
2
+
ε
w_{i,j,k}^{\prime\prime} = \frac {w_{i,j,k}^{\prime}} {\sqrt {{\sum_{i,k}w_{i,j,k}^{\prime }}^2+ε}}
wi,j,k′′=∑i,kwi,j,k′2+εwi,j,k′
其中,
ε
ε
ε 是一个很小的常数值,防止除零错误。
使用权重调制与解调步骤足以防止伪影的出现,同时通过风格向量保持对生成图像的控制,并确保输出的高质量。
3.2 路径长度正则化
StyleGAN2 架构在损失函数中加入了一个额外的惩罚项,称为路径长度正则化 (Path Length Regularization)。
我们希望潜空间尽可能平滑和均匀,这样在潜空间中任何方向上的固定大小步长都会导致图像固定幅度的变化。为了实现这种特性,StyleGAN2 期望最大限度的最小化以下值,以及带有梯度惩罚的 Wasserstein 损失:
E
w
,
y
(
∣
∣
J
w
T
y
∣
∣
2
−
a
)
2
\mathbb E_{w,y} (||J_w^Ty||_2-a)^2
Ew,y(∣∣JwTy∣∣2−a)2
其中,
w
w
w 是由映射网络创建的一组风格向量,
y
y
y 是从
N
(
0
,
I
)
\mathcal N(0, \mathbf I)
N(0,I) 中绘制的一组噪声图像,
J
w
=
∂
g
∂
w
J_w=\frac {∂g}{∂w}
Jw=∂w∂g 是生成器网络相对于风格向量的雅可比矩阵。
∣
∣
J
w
T
y
∣
∣
2
||J_w^Ty||_2
∣∣JwTy∣∣2 可以衡量经过雅可比矩阵给出的梯度变换后图像
y
y
y 的幅度。我们希望它接近常数
a
a
a,该常数动态计算为训练过程中
∣
∣
J
w
T
y
∣
∣
2
||J_w^Ty||_2
∣∣JwTy∣∣2 的指数移动均值。
这个额外的项能够使探索潜空间更加可靠和一致。此外,为了提高效率,损失函数中的正则化项每 16 批数据仅应用一次,这种懒惰正则化的技术不会导致模型性能显著下降。
3.3 非渐进式增长
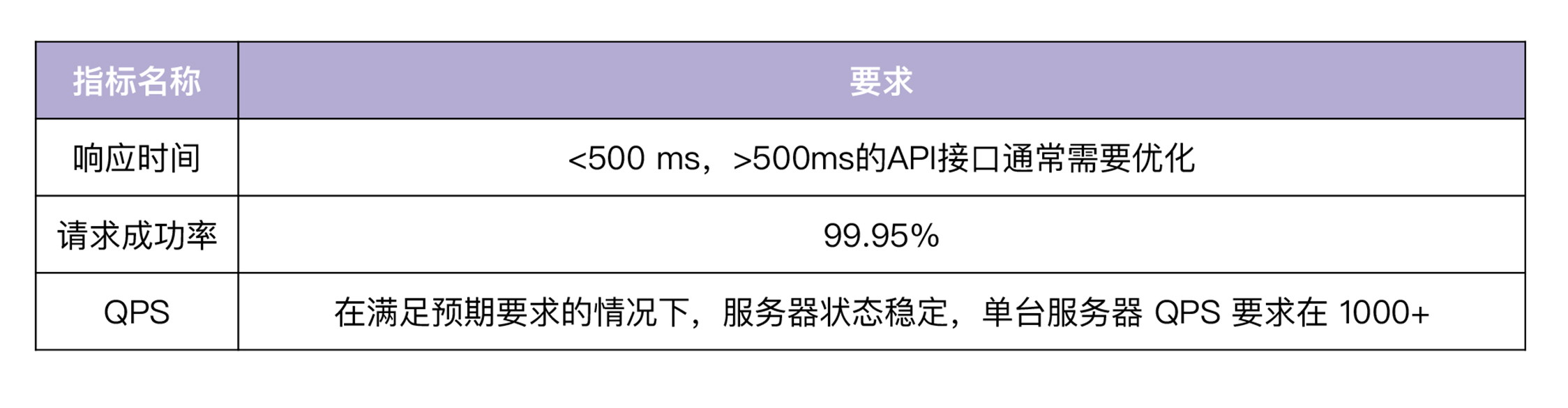
StyleGAN2 不再采用通常的渐进训练机制,而是利用生成器中的跳跃连接和判别器中的残差连接将整个网络作为一个整体进行训练,它不再需要对不同分辨率进行独立训练,也并不需要在训练过程中进行混合。StyleGAN2 中的生成器和判别器块如下图所示。

我们希望 StyleGAN2 能够保留的关键特性是,从学习低分辨率特征开始,并随着训练的进行逐渐改进输出。实践证明了,使用以上架构能够保留这一关键特性,在训练的早期阶段,每个网络从低分辨率层的卷积权重中受益,而跳跃连接和残差连接使更高分辨率层的输出基本上没有受到影响;随着训练的进行,更高分辨率的网络层开始主导,生成器发现了能够改进图像真实性的方式,以欺骗判别器,该过程如下图所示。

4. StyleGAN2 生成样本
下图显示了 StyleGAN2 的输出示例:

小结
StyleGAN 使用用于创建特定风格向量的映射网络,并允许在不同分辨率下注入风格的合成网络,使得模型对图像输出具有更大的控制能力。StyleGAN2 用权重调制和解调步骤代替了 StyleGAN 的自适应实例归一化,并使用如路径正则化等技术。能够在不使用渐近训练模型的情况下,仍保持分辨率逐步提升的特性。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)](
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
AIGC实战——能量模型(Energy-Based Model)
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——Transformer模型
AIGC实战——ProGAN(Progressive Growing Generative Adversarial Network)