http://t.csdnimg.cn/4md5U
上期我们分享了《大模型事实性调查》论文解读的前半部分,这一期为大家带来后面的内容,欢迎阅读交流。
四、事实性分析
在前面的第3节中,论文提供了与评估事实性相关的定量统计数据。在本节中,论文将更深入地探讨在大型语言模型中影响事实性的潜在机制。
4.1事实性分析
本小节深入研究了关于llm的事实性的有趣分析,重点关注那些与评估或增强没有直接关联的方面。具体来说,论文探索了llm处理、解释和产生事实内容的机制。接下来的部分将深入研究llm中事实性的不同维度,从知识存储、感知到管理冲突数据的方法。
4.1.1知识存储
语言模型作为知识库,在其参数中存储关于世界的大量信息。然而,这些知识在llm中的组织结构在很大程度上仍然是神秘的。之前的一项研究中引入了一种称为因果追踪的方法来衡量隐藏状态或激活的间接影响。该技术被用来说明事实知识主要存储在此类模型的早期层前馈网络(FFNs)中。类似地,Geva等人也认为,大量的事实信息被编码在FFN层中。他们将FFN的输入概念化为查询,第一层为键,第二层化为值。因此,FFN的中间隐藏维度可以解释为层内内存的数量,中间隐藏状态代表一个包含每个内存激活值的向量。因此,FFN的最终输出可以理解为激活值的加权和。作者进一步证明,价值向量通常封装了人类可解释的概念和知识。此外,Chen等人发现了一个有趣的发现,即语言模型包含表达多语言知识的语言独立神经元,以及通过应用集成梯度方法传递冗余信息的退化神经元。然而,值得注意的是,上述研究主要集中在个别事实的表现上,而对事实知识如何精确组织和互联的全面理解仍然是一个持续的挑战。
4.1.2知识的完整性和感知性
本小节深入探讨了llm的自我感知的有趣领域,他们辨别自己的知识差距的能力,以及他们内部生成的知识和外部检索到的信息之间的平衡。论文深入研究参数化知识和检索知识之间的二分法,探索这些模型给知识密集型任务的前沿带来的前景和挑战。
Knowledge Awareness。一些研究已经调查了大型语言模型的知识感知,特别是评估llm是否能够准确地估计其自身反应的正确性。这些研究大多将llm视为“黑盒”,促使模型报告其置信水平,或计算模型输出的困惑度,作为响应可能性的指标。Gou等人探索了该模型验证和迭代细化其输出的能力,类似于人类与工具之间的交互方式。作者发现,仅仅依赖自校正而没有外部反馈可以导致边际改善,甚至性能下降。还有一项研究实验使用设置增强或不增强外部文档检索,以确定模型是否识别自己的知识边界。他们的研究结果表明,llm对其事实知识边界的感知不准确,而且往往对自己的反应过于自信。llm往往不能充分利用它们所拥有的知识;然而,检索增强可以在一定程度上弥补这个缺点。Yin等人引入了一个名为“自我感知”的数据集,以测试模型是否识别出他们不知道的东西,包括可回答和不可回答的问题。该实验表明,模型确实具有一些识别自身知识差距的能力,但它们仍与人类的水平相差甚远。GPT-4优于其他模型,指令和上下文学习可以增强模型的鉴别能力。Kadavath等人关注基于语言模型校准的LLM自我评估。他们的研究结果显示,“上述这些都没有”的选项降低了精度,较大的模型显示出更好的校准,而RLHF阻碍了模型的校准水平。然而,简单地调整温度参数就可以纠正这个问题。Azaria和Mitchell通过使用模型的内部状态和隐藏层激活来评估由llm生成的语句的真实性。作者利用前馈神经网络,可以利用隐藏的输出状态对模型是否存在误导性进行分类。
Parametric Knowledge vs Retrieved Knowledge。Yu等人探讨了llm的内部知识是否可以取代检索到的关于知识密集型任务的文档。他们要求llm,如DuuultGPT,直接生成给定问题的上下文,而不是从数据库中检索它们。他们发现生成的文档包含的黄金答案比检索到的顶级文档更多。然后,他们将生成的文档和检索到的文档输入到解码器融合模型,用于知识密集型任务,如open-domian QA,并发现生成的文档比检索到的文档更有效,这表明llm包含足够的知识用于知识密集型任务。
相反,这些观察结果在随后的调查中也被提出了质疑。Kandpal等人强调了llm对在训练前看到的相关文档数量的依赖性。他们认为,回答基于事实的问题的成功与在训练前遇到的包含该问题主题的文档数量高度相关。该研究进一步提出了广泛扩展模型的必要性,以实现在训练数据中表示最小的问题的竞争性能。除了这些问题,Sun等人对使用专门设计的Head-to-Tail基准,批判性地评估llm的事实知识库。结果表明,通过目前可用的llm,对事实知识的理解,特别是与 torso-to-tail实体相关的理解,是次优的。
总之,虽然llm在处理知识密集型任务方面显示出了希望,但它们对训练前信息的依赖和事实准确性的局限性仍然是重大障碍。它强调了在该领域的进一步进步的必要性,以及结合补充方法,如检索增强,以加强在llm中对长尾知识的学习的重要性。
4.1.3语境影响和知识冲突。
本小节研究了LLM的固有参数知识和所提供的上下文知识之间的相互作用,探索了模型利用上下文的能力及其在面对冲突信息时的行为。
Contextual Influence on Generation。一些工作探索了模型利用环境的能力,例如,Li等人观察到,更大的模型倾向于依赖于他们的参数知识,即使在面对反事实的环境时。这表明,随着模型规模的增加,它们可能会对自己的内部知识变得更有信心,这可能会避开外部环境。然而,引入不相关的上下文仍然可以影响它们的输出。可控性(依赖于相关情境)和鲁棒性(抵抗不相关情境)之间的平衡是LLM训练中的一个挑战。研究表明,降低环境噪声可以提高可控性,但对鲁棒性的影响仍有待观察。相比之下,Zhou等人提出了提示模板来指导llm实现更忠诚的文本生成。其中,基于意见的提示被证明是最有效的,这表明当llm被询问到意见时,它们更接近于上下文。有趣的是,该研究发现,使用反事实上下文增强了模型的忠诚度,而来自维基百科等平台的原始上下文可能会导致简单性偏见,导致llm在不严重依赖上下文的情况下回答问题。Chen等人对llm有效利用检索信息的能力进行了综合评估。研究表明,检索到的文档可以提高LLM的性能,但这些文档中的噪声会阻碍它。Yue等人研究了llm生成的内容的性质。他们将生成的内容分为可归属的、矛盾的或推断的参考文献。精细的模型和基于指令的llm都难以准确地评估生成的内容和引用之间的对齐,这强调了确保llm生成与所提供的上下文一致的内容的挑战。Shi等人在来自GSM8K的GSM-IC数据集上研究了llm的可分散性。他们发现,所有的提示技术都会对问题定义中的无关信息做出响应。他们识别了影响模型对无关上下文的敏感性的各种无关信息的各种因素。此外,他们还发现,自我一致性提示和将不相关信息合并到范例中可以提高模型的性能,使它们能够学会忽略不相关信息。
Handling Knowledge Conflicts。一系列的研究对llm在面对冲突信息时的行为感兴趣。Longpre等人引入了知识冲突的概念,其中所提供的上下文与模型的学习信息相矛盾。他们的发现表明,这种冲突导致了预测的不确定性的增加,特别是对于领域内的例子。从T5-60M到11B的跨模型的观察表明,较大的模型倾向于默认它们的参数知识。此外,检索质量与依赖内部知识的倾向之间存在反比关系:证据越不相关,模型就越默认其参数知识。在典型的ODQA模型包括FiD和RAG上进行实验,实验结果显示,与RAG模型相比,FiD模型很少采用记忆法(NQ模型低于3.6%)。相反,FiD主要是根据所提供的证据得出其答案。有趣的是,当面对相互冲突的检索段落时,模型往往倾向于依靠他们的参数知识。有的工作还探索了最近的llm的行为,包括ChatGPT和GPT-4。与较小的lm的发现相反,他们发现llm可以对外部证据高度接受,即使它与他们的参数记忆相矛盾,只要外部证据是连贯和令人信服的记忆相矛盾。此外,llm表现出强烈的确认偏差,特别是当呈现与参数记忆一致的证据时。这种偏见对于被广泛接受的知识来说会变得更加明显。在没有提供相关证据的情况下,llm倾向于表达不确定性。然而,当同时提供相关和不相关的证据时,他们表现出过滤不相关信息的能力。Wang等人认为,LLM不应该仅仅依赖于参数信息或非参数信息,而是授予LLM用户做出知情决策的机构。他们引入了一个框架,包括三个任务((1)上下文知识冲突检测;(2) QA-span知识冲突检测;(3)不同答案生成)模拟知识冲突,并评估llm的行为是否与目标一致。
总之,虽然Li等人和Zhou等人研究强调了使llm更了解环境的挑战和潜在的解决方案,但Yue等人和Xie等人强调了llm的固有偏见和局限性。首要的主题是需要一种平衡的方法,即llm有效地利用其内部知识和外部上下文来产生准确和连贯的输出。
4.2造成事实错误的原因
理解这些事实不准确的根本原因对于细化这些模型并确保它们在现实场景中的可靠应用至关重要。在本小节中,论文将深入研究这些错误的多方面起源,并根据模型操作的阶段对它们进行分类:模型级别、检索级别、生成级别和其他其他原因。表1显示了由不同因素引起的事实误差的例子。
4.2.1 模型级原因Model-level Causes。
本小节深入研究了大型语言模型中导致事实错误的内在因素,这些因素源自其固有的知识和能力。
Domain Knowledge Deficit。该模型可能在特定领域缺乏全面的专业知识,从而导致不准确性。每个LLM基于其所训练的数据都有其局限性。如果LLM在训练过程中没有接触到特定领域的全面数据,那么在查询该领域时,它可能会产生不准确或广义的输出。例如,虽然LLM可能擅长回答一般的科学问题,但当被问及利基科学子领域时,它可能会步履蹒跚。
Outdated Information。该模型对旧数据集的依赖可能使它没有感知到最近的发展或变化。llm是在某种程度上已经过时的数据集上进行训练的。这意味着模型将不知道上次训练更新后的任何事件、发现或变化。例如,ChatGPT和GPT-4都在2021.09之前的数据训练,可能没有感知到之后的事件或进展。
Immemorization。该模型并不总是保留其训练语料库中的知识。虽然llm“记忆”数据是一种误解,但它们确实根据训练形成知识表示。然而,他们可能并不总是从他们的训练参数中回忆起具体的、不那么强调的细节,特别是如果这些细节很少或没有通过多个例子得到加强。例如,ChatGPT已经对维基百科进行了预训练,但它仍然无法回答NaturalQuestions和TriviaQA中的一些问题,这是由维基百科构建的。
Forgetting。该模型可能不会保留其训练阶段的知识,也可能在进行进一步的训练时忘记之前的知识。随着模型对新数据进行进一步的微调或训练,就存在“灾难性遗忘”的风险,他们可能会失去他们以前知道的某些知识。这在神经网络训练中是一个众所周知的挑战,当网络接触到新数据时,它会忘记之前学到的信息,这也发生在大型语言模型中。
Reasoning Failure。虽然该模型可能拥有相关的知识,但有时它可能无法有效地通过推理来回答查询。即使LLM拥有回答问题所必需的知识,它也可能无法在逻辑上将点或理性联系起来。例如,输入中的歧义可能会导致llm的理解失败,从而导致推理错误。
4.2.2检索级别原因 Retrieval-level Causes。
检索过程在决定llm响应的准确性方面起着关键作用,特别是在检索增强设置中。在这一水平上,有几个因素可能导致事实错误:
Insufficient Information。如果检索到的数据没有提供足够的上下文或细节,那么LLM可能难以生成事实响应。由于缺乏全面的证据,这可能会导致通用的,甚至是不正确的输出。
Misinformation Not Recognized by LLMs。llm有时可以接受和传播检索到的数据中存在的错误信息。当模型遇到知识冲突时,检索到的信息与预训练的知识相矛盾,或者多个检索到的文档相互矛盾的时,这尤其令人担忧。例如,一项研究观察到,证据越不相关,该模型就越有可能依赖于其内在知识。最近的研究,也表明llm在检索过程中容易受到错误信息的攻击。
Distracting Information。llm可能会被检索数据中不相关或分散注意力的信息所误导。例如,如果证据中提到了一部“俄罗斯电影”和“导演”,那么LLM可能会错误地推断出“导演是俄罗斯人”。有研究强调了这一漏洞,并指出llm可能会受到令人分心的检索结果的显著影响。他们进一步提出了指令调优作为一种潜在的解决方案,以增强模型更有效地筛选和利用检索结果的能力。
此外,根据Liu等人的研究,在处理长时间的检索输入时,模型在处理输入上下文开始或结束时给出的信息时往往表现出最佳性能。相比之下,当模型从这些广泛的上下文中提取相关数据时,模型的性能可能会显著下降。
Misinterpretation of Related Information。即使检索到的信息与查询密切相关,llm有时也会误解或误解它。虽然在优化检索过程时,这种情况可能不那么频繁,但它仍然是一个潜在的错误来源。例如,在ReAct研究中,当检索过程的改进时,错误率显著下降。
4.2.3推理级别原因 Inference-level Causes。
Snowballing。在生成过程中,随着模型继续生成内容,开始时的一个小错误或偏差可能会加剧。例如,如果一个LLM曲解了一个提示或以一个不准确的前提开始,后续的内容可能会进一步偏离事实
Erroneous Decoding。解码阶段对于将模型的内部表示转换为人类可读的内容至关重要。这一阶段的错误,无论是由于波束搜索错误或次优采样策略等问题,都会导致输出歪曲模型的实际“知识”或意图。这可以表现为不准确、矛盾,甚至是荒谬的陈述。
Exposure Bias。llm是其训练数据的产物。如果他们更频繁地接触到某些类型的内容或措辞,他们可能会倾向于生成类似的内容,即使它不是最真实或最相关的。如果训练数据存在不平衡,或者某些事实场景的代表不足,那么这种偏差尤其明显。在这种情况下,该模型的输出反映的是它的训练暴露,而不是客观的事实。例如,研究表明,llm可以正确识别符合二元性别系统的个体的性别,但它们在确定非二元性别或中性性别时表现不佳。
五、加强(ENHANCEMENT)
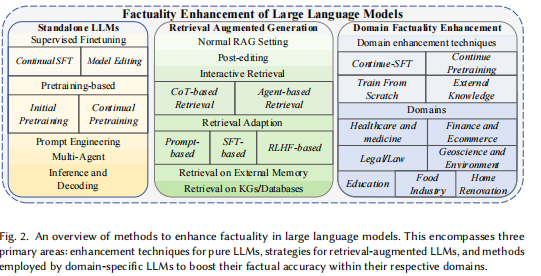
本节讨论在不同阶段增强LLM中的事实性的方法,包括LLM生成、检索增强生成、推理阶段增强和特定于领域的事实性改进,如图2所示。
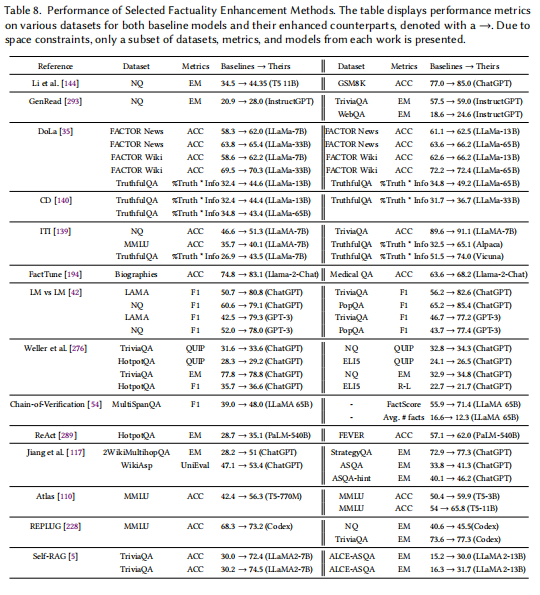
表8总结了增强方法及其各自相对于基线llm的改进。必须认识到,各种研究论文可能采用不同的实验设置,如zero-shot、few-shots或full setting。因此,在检查此表时,需要注意的是,不同方法的性能指标,即使是在同一数据集上评估相同的指标,也可能不能直接比较。
5.1关于独立的LLM的生成
当关注独立的LLM生成时,增强策略可以大致分为三大类:
(1)从无监督语料库提高事实知识(第5.1.1节):这涉及在训练期间细化训练数据,例如通过重复数据删除和强调信息词。本文还探索了主题前缀和句子完成丢失等技术来增强这种方法。
(2)从监督数据中增强事实知识(第5.1.2节):这一类的例子包括监督微调策略,专注于对标签数据进行微调,或集成结构化知识,如知识图谱(KGs),或对模型参数进行精确调整。
(3)从模型中最优地获取事实知识(章节5.1.3,5.1.4,5.1.5):这个类别包括诸如多智能体协作和创新提示等方法。此外,还引入了新的解码方法,如事实-核采样,以进一步提高事实性
一些工作旨在改善大型多模态模型的事实性,论文选择不强调它们。
5.1.1基于预训练。
预训练在为模型提供来自语料库的事实知识方面发挥着关键作用。通过在这一阶段强调策略,该模型的内在事实性可以得到显著增强。这种方法对于解决诸如记忆和遗忘等挑战尤其重要。
Initial Pretraining。在模型的基础预训练过程中所采用的方法。
Lee等人开发了两种不同的工具来用于删除训练数据,解决了当前llm训练集中存在的冗余文本和长重复子字符串的问题。这些工具有效地减少了对模型输出中记忆文本的召回率。值得注意的是,他们通过更少的训练步骤获得了类似的准确性,甚至是更高的准确性。
Sadeq等人介绍了对用于llm预训练的掩码语言模型(MLM)训练目标的修改。他们发现,高频词并不始终有助于模型学习事实知识的能力。为了解决这个问题,他们设计了一种策略,鼓励语言模型在无监督的训练中优先考虑具有信息性的单词。这是通过基于其信息相关性更频繁地屏蔽token来实现的。为了量化这种相关性,他们利用点线互信息(PMI),假设PMI值升高的单词,与相邻的单词相比,可能更具有信息相关性。实验结果表明,这种创新的方法显著地提高了预训练好的语言模型在各种任务中的有效性,包括事实回忆、问题回答、情感分析和自然语言推理。
Continual Pretraining。允许模型逐步改进和更新其知识库的迭代预训练过程。
Lee等人引入TOPICPREFIX作为预处理方法,将句子完成损失作为训练目标。当LM训练语料库被分块时,一些事实句子可能不清楚,特别是当这些句子包含代词(例如,她,他,它)。因此,他们在事实文档中的句子前面添加了TOPICPREFIX(例如,维基百科的文档名称),从而将每个句子转换为一个独立的事实陈述。他们还引入了句子完成损失,目的是使模型能够从整个句子中捕捉事实,而不仅仅是关注子词之间的关联。为了实现,他们为每个句子建立一个支点t,并要求在t之前对所有的token预测损失进行零掩膜。这个支点只在训练阶段需要使用。实验表明,与标准的事实域自适应训练相比,该方法可以进一步减少事实误差。
5.1.2有监督微调SFT。
有监督微调利用标记的数据集来改进模型的性能。这种方法有双重目的:它向模型提供特定的任务或知识基础导向的信息,并解决了记忆和遗忘等挑战。一些研究,如Chung等人,Zhou等人,强调了监督微调在引出基本模型的固有知识方面的关键作用,随后增强其推理能力。
Continual SFT持续的SFT。一种循环微调方法,其中模型使用连续的标记数据集进行一致的细化。
Moiseev等人研究了如何将知识图谱中的结构化知识注入到llm中。该方法包括使用包含关系知识的三联体直接训练t5。以往的方法通常使用提示来描述三联体,然后用掩码语言模型任务来训练llm,但有些三联体并不容易描述。他们比较了三种知识增强微调方法,即在C4语料库上进行MLM训练,在KG三联体中屏蔽主体或对象,在KELM语料库中屏蔽主体或对象。实验表明,后两种方法在closed-book QA任务获得了更好的精确匹配分数。这说明直接基于KG三联体的训练是将知识注入模型的有效方法
Sun等人将负样本和对比学习引入具有MLE损失的监督微调过程。这些负样本的来源要么是来自知识图谱,要么是由大型语言模型生成的。传统的对比学习只能在标记或句子级别发挥作用,但跨度信息的内在价值不容忽视,他们采用命名实体识别来提取关键的跨度数据。训练过程包含了MLE损失、标准对比学习损失和基于跨度的对比学习损失,参数经过微调以优化结果。实验表明,该方法的性能可与基于SOTA KB的方法相媲美,但在效率和可伸缩性方面具有显著的优势。
Yang等人提出了一个基于知识图谱增强的大型语言模型(KGLLMs)的开发框架,它借鉴了已建立的技术。他们详细介绍了各种增强策略,包括训练前的增强,通过整合事实数据来细化输入质量;训练期间的增强,协同文本和结构知识,利用图神经网络和注意机制等工具;多任务学习,注重知识引导的训练前任务,以支持llm的事实知识获取;以及训练后增强,使用知识丰富的数据对特定领域的任务进行微调。此外,还强调了在llm中提示学习的重要性,强调了选择适当的提示模板的重要性。他们还建议将知识图谱作为构建这些模板以利用特定领域的知识的有价值的资源。
FactTune 的目标是利用强化学习来提高LLM的事实性,因此需要对模型生成的内容的事实性进行评分。但是,人类标签成本太高,所以作者使用两种方法来检查LLM生成的内容的事实,即1)基于参考,使用外部知识库检索和Factscore方法进行评分;2)无参考,使用另一个LLM进行评分。然后,他们利用直接偏好优化算法对模型进行优化。在Llama的生物生成任务和医疗QA中,错误率分别降低了50%和20+%。
Model Editing模型编辑。模型编辑是不直接微调模型,而是一种更精确的方法,以增强模型的事实性。通过编辑与事实相关的特定区域,模型可以正确地表达该事实,而不影响其他不相关的知识。目前的编辑方法可以分为权重保留的范式和权重修改的范式。当修改模型的权重时,KN 和ROME 首先分析表示来定位那些潜在的事实错误,然后直接更新相关的权重。同时,KE 和MEND 采用了一个超网络来学习必要的权值变化。虽然有效,但直接更新权值的鲁棒性和泛化仍然是一个有待解决的问题。
Li等人提出了一种被称为推理-时间干预(ITI)的技术,旨在提高大型语言模型的事实准确性。ITI在推理过程中调整模型的激活,以增强反应的真实性。这种方法,归类为激活编辑,是可调的,而且侵入性较小,使它有别于权重编辑技术。从先前的研究中获得灵感,他们利用转向向量,这被证明是有效的风格转移,来指导模型激活。他们详细介绍了一个多步骤的模型选择过程,包括干预强度超参数的校准,查明与truth-telling相关的头部,并确定他们的truth-telling方向。TruthfulQA数据集作为训练和验证的基础,采用了严格的2倍交叉验证来防止数据泄漏。在TruthfulQA基准上的实验表明,ITI将Alpaca的真实性从32.5%提高到65.1%。
5.1.3多代理Multi-Agent。
以协作或竞争的方式参与多个模型,通过它们的集体能力来增强事实性,有助于解决不记忆和推理失败的问题。
Du等人提出了一种方法,通过将不同的llm视为参与多代理辩论的智能代理,来提高语言模型的性能。在这种方法中,多个语言模型的实例呈现并对它们各自的答案和推理过程进行辩论,经过多轮辩论,最终就答案达成共识。如果辩论的答案不能趋同,提示就会被修改,以减少这两个因素的固执。这种方法已被证明可以显著提高各种任务中的数学和推理能力,同时提高生成内容的事实准确性。此外,该方法可以直接应用于现有的黑盒模型,适用于使用相同提示的所有研究任务。
Cohen等人开发了一种事实核查机制。他们将证人被询问其真实性的情况平行,利用LLM从QA数据集收集陈述,这些陈述不是是事实正确的就是不正确的。在语句生成过程中,模型被提供了一个黄金答案,促使它产生准确和不准确的语句,固有地对每个语句进行标记。对于每一对QA对,另一个LLM,作为一个询问者,生成一系列的问题。一个单独的LLM,扮演应答者的角色,回答这些问题。这种反复的提问和回答继续进行,直到审讯者满意,最终得出结论。作者在LAMA、PopQA、NaturalQA 和TriviaQA等数据集上进行了实验。以F1-scores衡量,在所有数据集上,LM vs LM方法始终显著优于基线,从10点到超过20点。
5.1.4新颖提示Novel Prompt。
引入创新的或量身定制的提示,从LLM中提取更真实和精确的响应,可以更好地帮助模型引出其参数中的知识,并提高推理能力。
Yu等人介绍了一种称为Generate-then-Read(GENREAD)的新方法。文档检索器将被LLM生成器所取代。在本文中,系统将提示LLM针对一个给定的问题生成多个上下文文档。作者对这些文档嵌入进行了集群化,并从不同的集群中采样文档,以确保上下文文档的多样性。通过这些生成的上下文演示,llm在知识密集型任务上获得了比从维基百科等外部语料库中检索更好的结果。
Weller等人引入了一个称为QUIP-Score的度量来衡量对预训练数据的依赖性。他们索引维基百科,以迅速确定一个LLM的响应的依赖性。通过使用特定的提示,比如“基于来自维基百科的证据”,他们的目的是唤起LLM对其训练数据集的内容的回忆。除了接地提示,他们还引入了反接地提示,鼓励LLM在不引用其训练数据的情况下做出回应,例如,“不使用维基百科的任何信息。”这种方法背后的动机是相信,引导LLM参考它在训练前获得的更多知识,可以减少不正确信息的产生。为了量化这一基础,他们提出了QUIP-Score度量标准来衡量模型生成的内容和维基百科中最相关的内容之间的相似性。在他们在TQ、NQ、HotpotQA和ELI5等数据集上进行的实验中,结果显示,虽然添加上述提示并没有显著改善传统的QA指标,但它显著提高了QUIP指标上的分数。
Khot等人提出了分解的提示。复杂任务通过提示被分解为多个简单的任务,然后通过特定任务的llm来处理。例如,对于涉及极长输入序列的任务,该技术系统地将输入分解为更短的序列,用于单个处理。值得注意的是,作者观察到,当与检索模块结合时,这种方法显著提高了open domain multi-hop QA任务的性能。
Dhuliawala提出了验证链(CoVe)以减少事实错误。CoVe策略包括模型最初构建一个响应,随后制定验证查询以评估其初始草稿,独立响应这些查询以保持无偏见的答案,并最终产生一个经过验证的答案。CoVe方法包括四个关键阶段: 1)使用LLM基于查询起草一个初始回复,2)生成验证问题的查询和初始答案来查明潜在的错误,3)回答每个验证问题和比较这些答案与初始响应检测差异,4)如果发现差异,产生一个修改后的答案,集成的验证结果。整个过程是通过以不同的方式提示相同的LLM来实现预期的结果来执行的。实验表明,验证链可以减少不同任务中的错误,包括Wikidata的基于列表的问题,closed-book MultiSpanQA和长形文本生成。
5.1.5解码Decoding。
解码方法,如定向搜索和核采样,在指导模型产生既真实和连贯的输出方面发挥着至关重要的作用。通过改进解码过程,可以有效地解决如第4.2.3节所述的挑战,如滚雪球式错误或错误解码。

Chuang等人提出“通过对比层解码”来减轻这些幻觉。这种方法利用了将后期层与早期层投影到词汇表空间中获得的日志差异,利用了llm中已知的事实知识的本地化。本研究的结果表明,DoLa在各种任务中不断增强llm生成内容的真实性,如多项选择和开放生成任务,显示了其在显著提高llm生成准确和真实事实方面的可靠性的潜力。
5.2关于检索-增强的生成Retrieval-Augmented Generation
检索-增强生成(RAG)已经成为一种被广泛采用的方法,以解决独立的llm固有的某些限制,如过时的信息和无法记忆。然而,尽管RAG为一些问题提供了解决方案,但它引入了自己的一系列挑战,包括信息不足和对相关数据的误解,如第4.2.2节所述。本小节深入探讨了为减轻这些挑战而设计的各种策略。在检索增强生成的领域内,增强技术可以大致分为以下几个关键领域:
(1)使用检索文本进行生成的正常设置(第5.2.1节):
(2)交互式检索和生成(第5.2.2节):这里的例子包括将思想链步骤集成到查询检索中,以及使用基于llm的代理框架,该框架利用外部知识api。
(3)将LLM适应于RAG设置(第5.2.3节):这涉及到类似于Peng等人提出的方法,它将一个固定的LLM与一个即插即用的检索模块相结合。另一个值得注意的方法是REPLUG,这是一个检索增强框架,它将LLM视为一个黑盒,并使用语言建模分数对检索模型进行微调。
(4)从附加知识库(第5.2.5节和第5.2.4节)中检索:该类别包括从外部参数记忆或知识图谱中检索的方法,以增强模型的知识库。
5.2.1正常RAG设置
正常RAG设置的工作流程。一个正常的RAG设置的工作原理是检索外部数据,并在生成阶段将其传递给LLM。论文遵循LlamaIndex 和LangChain 提出的框架,将该过程解耦为以下模块和步骤:
(1)文档加载器用于加载来自各种来源的文档。这些加载器可以从不同的位置(private s3 buckets, public website)获取不同类型的文档(HTML、PDF、代码)。
(2)采用Document transformer提取文件的相关部分。这可能涉及将大型文档分割或分割成更小的块。该任务采用了不同的算法,并针对代码或标记等特定文档类型进行了优化。
(3)采用文本嵌入模型来捕获文本的语义意义。
(4)利用向量存储来有效地存储和搜索嵌入物。
(5)检索器,如父文档检索器、自查询检索器和集成检索器,用于从数据库中检索数据。
在这里,父文档检索器允许为每个父文档创建多个嵌入,以检索较小的块,同时维护较大的上下文。自查询检索器将查询的语义部分与其他元数据过滤器分离,从而允许更准确的检索。集成检索器允许从多个来源或使用不同的算法检索文档。
Borgeaud等人建议缩放文本数据库的大小作为缩放语言模型的补充路径,以进行检索。有一个预先收集好的文本数据库,总共有超过5万亿个token。这些块以键-值对的形式存储,每个块作为一个单元,并使用Bert嵌入上的L2距离对键-值数据库中的k-nearest进行相似性检索。输入序列被分割成块,检索转换器(Retro)模型检索类似于前一个块的文本,以改进当前块中的预测。该模型计算输入文本和检索到的文本块之间的交叉注意,以生成更好的答案。
Lazaridou提出了一种方法,利用大规模语言模型的few-shots能力,来增强它们在事实和当前信息方面的基础。从半参数语言模型中提取,该方法在LMs条件下使用基于谷歌搜索来源的数据的few-shots提示。对于任何给定的查询,该方法都会从web中检索相关的文档,提取前20个url,并对它们进行处理以获得明文。这些文档被分割成段落,并根据它们与查询的相似性,使用TF-IDF选择最相关的文档。然后,lm将使用包含检索到的段落的few-shots提示进行调节。这种k-shot提示技术被一个证据段落所增强,创建了一个包含证据、查询和响应的提示结构。该方法还包括从模型中生成多个答案,并使用不同的概率分解对它们进行重新排序。实验结果表明,根据检索到的证据,7B Gopher LM的性能超过了280B Gopher LM,在NQ 数据集上的相对改进高达30%。
5.2.2交互式检索Interactive Retrieval。
虽然检索系统的设计目的是获取相关信息,但它们偶尔可能无法检索到准确或全面的数据。此外,llm可能难以识别,甚至被检索到的内容所误导,详见第4.2.2节。实现交互式检索机制可以解决这些挑战,帮助获取更合适的信息,并指导LLM改进内容生成。在本小节中,论文将探讨使用思想链和代理机制来实现有效的交互式检索的方法。
基于CoT的检索 CoT-based Retrieval。在最近的研究中,人们对将思想链的步骤集成到查询检索中越来越感兴趣。He等人介绍了一种方法,该方法为每个查询生成多个推理路径及其相应的预测。这个过程涉及到从外部来源检索相关知识,如wikidata、WordNet和ConceptNet。每个推理路径的忠诚度是基于隐含分数、矛盾分数和MPNet与检索知识的相似性来决定的。选择忠诚度得分最高的预测作为最终结果。该方法在常识推理、时间推理和表格推理等任务中表现出了优越的性能,优于基线CoT推理和自一致性方法。与此相关,Trivedi等人提出了IRCoT,一种交织CoT过程的创新检索技术。在这种方法中,在CoT期间生成的每个句子都与问题相结合,形成一个检索查询。随后的推理步骤然后由语言模型使用检索结果和先验推理产生。这种交错方法可以提高open-domian QA中检索和CoT的性能。实验证明,这有利于不同大小的模型,包括GPT-3(175B)和Flan-T5 家族。
FLARE是一个动态的解决方案,可以解决以前的RAG工作的局限性,它不是在生成开始时只检索一次,而是基于固定的间隔检索。由于在此过程中不断变化的信息需求,单次检索对于长形式的生成是不够的,并且对于以前的token查询的固定间隔可能是不合适的,爆发动态地决定了“何时以及要检索什么”。“何时”的决定是基于当前句子是否包含一个生成概率低于设定阈值的token。如果不接受,则该句子将被接受并转移到下一代步骤;否则,将发生检索增强生成。对于“什么”,当前的句子被用作一个查询。为了解决低概率token影响检索精度的挑战,提出了两种解决方案:屏蔽低概率token和使用LLM生成这些token作为查询。使用GPT3.5对Multihop QA 、常识推理、long-form QA和开放域摘要等任务进行测试,结果显示FLARE的性能优于基线,两种查询生成方法都显示出类似的性能。
基于代理的检索oAgent-based Retrieval。
使用基于llm的代理框架,该框架利用外部知识api作为工具,或请求此类api作为操作。
Yao等人提出了一个名为ReAct的新框架,它将思想链推理与行动结合起来。通过上下文学习,LLM的CoT输出转化为推理过程和行为的描述。随后,这些操作描述被标准化并执行这些操作,结果被合并到下一个提示中。就结果而言,对于事实检查和QA等任务,CoT有14%的正确答案包含不正确的推理步骤或事实,而ReAct只有6%。在错误的答案中,56%的CoT错误是由于推理步骤或事实中的错误,而ReAct没有事实错误。然而,ReAct有23%的错误是由搜索错误造成的。
Shinn等人提出了一个名为Reflextion的即时工程框架,使llm能够反思和纠正以前的错误。他们使用语言反馈来加强主体的行为,而不是调整模型的权重。具体来说,Reflextion代理,一个LLM,首先在few-shots场景中通过ReAct或CoT生成“动作”与环境交互,从而产生“观察”。这种“观察”,无论是奖励、错误信息,还是自然语言反馈,都提供了对代理当前的“动作”的见解。当代理接收到一个故障信号时,它会触发一个自我反射机制,利用LLM,将故障的原因总结到其内存模块中,创建一个“长期内存”。在后续生成中,代理可以回顾所有过去的反射性记忆,以防止错误。实验结果表明,在AlfWorld 、HotPotQA 和HumanEval等数据集上,Reflextion比ReACT和CoT的性能提高了10-20%
Varshney等人介绍了一个全面的框架,旨在减少事实的不准确性。它们使用模型来识别实体并生成问题,论文将这些模型识别为基于llm的代理的工具。在生成过程中,使用实体提取、关键字精馏或LLM指令,在上下文句子中确定包含名称、地理位置和时间引用的关键概念。与这些可识别的概念相对应的logit输出值可以作为置信度估计的替代品。如果这些值低于预定的阈值,该机制就会获取相关文档以证实生成的信息。用于这种检索的查询方法取决于向LLM提出一个二元(是/否)查询。在验证不成功的情况下,框架指导模型根据参考文档中的知识,通过省略或替换来纠正错误的输出。经验评估,特别是在文章生成的领域,强调了所描述的方法的有效性。值得注意的是,在采用该方法时,GPT-3的事实错误率大幅下降,从47.5%下降到仅14.5%。他们方法的诊断方面显示了80%的召回率,而纠正机制熟练地纠正了57.6%的事实不正确的输出。
Self-RAG建立在检索-增强生成(RAG)框架之上,并结合了一种自我反思的方法。这包括按需检索,促使LLM考虑检索到的文档是否相关并支持该论证,从而增强了LLM输出的事实性。Self-RAG通过让模型在输出过程中产生特殊的token(即反射token)来实现这一点。作者采用了一种端到端训练方法,使模型能够生成这些特殊的标记。在推理级别上,Self-RAG为每个输入和先前生成的内容的每个段解码一个检索标记。如果token为“否”,则模型继续进行正常输出;如果为“是”,则会执行检索。然后,输入、以前的输出和每个检索到的文档都被输入到模型的另一个会话中,该会话将评估每个文档的相关性。如果文档是相关的,模型进一步评估它是否支持,是否应该在生成中使用。基于此文档,模型生成一个段,并使用生成的反射标记应用软约束和硬约束来选择最合适的文档。然后,Self-RAG将最合适的文档整合到内容的持续生成中,并根据需要提供引用。重复此过程,直到生成整个内容。Self-RAG需要训练数据,并由GPT-4进行注释。基于Llama-2模型的短型QA(PopQA,TQA)、闭集QA(Pub,ARC)和引文长型NLG(Bio Generation,ALCE-ASQA)的实验证明了其有效性。
5.2.3检索适应Retrieval Adaptation。
最近的研究强调,仅仅在llm中使用检索到的信息并不总是能提高他们回答事实问题的能力。这强调了使llm能够更好地适应检索到的数据以产生更准确的内容的重要性。在本节中,论文将深入探讨促进这种适应的各种策略。具体来说,论文探索了三种方法:基于提示的方法、基于SFT的方法和基于RLHF的方法。
基于提示Prompt-based.。利用提示来导航检索过程,确保提取相关和事实的数据。
Peng等人介绍了LLM-增强器系统,这是一个使用固定LLM和即插即用检索模块的系统,以帮助LLM在对事实错误特别敏感的任务中表现得更好。该系统通过使LLM能够使用一系列模块(例如,允许LLM与外部知识交互)来帮助LLM生成基于证据的结果,从而提高了其性能。他们使用由实用函数生成的自动反馈(例如,LLM生成的响应的事实性分数)来修改LLM的候选响应选项。本文对系统在信息寻求对话和Wiki QA上的性能进行了评估,实验表明,该系统可以在不牺牲生成内容的流畅性和信息量的情况下,显著减少ChatGPT的错误。
基于SFT SFT-based。通过训练来优化LLM或检索系统,以增强生成任务和检索内容之间的对齐性。
Izacard等人介绍了一个名为图集的综合架构,该架构由双编码器架构的通信器检索器和具有融合解码器的T5语言模型组成。检索器的训练目标包括四个组成部分:注意蒸馏,训练每篇文章的语言模型的平均注意力分数;多文档阅读器和检索器(EMDR2)的端到端训练,包括使用查询和当前检索器检索到的文章作为输入和损失计算来训练检索器;困惑蒸馏(PDist),其中训练检索器来预测每个文档的标准答案的困惑程度会提高多少;留一法困惑蒸馏(LOOP),它训练检索器预测当从top-K结果中删除一个文档时,语言模型的预测效果有多差。LM的训练目标包括三个部分:前缀语言建模、掩码语言建模和章节标题生成。此外,他们还使用诸如全索引更新、重新排序和查询端微调等技术来优化和加速检索器的训练。Atlas仅使用64个例子就在NaturalQuestions上取得了显著的准确性,优于具有50倍参数的540B模型。
Shi等人引入了REPLUG,这是一个检索增强框架,它将LLM视为一个黑盒,冻结其参数,并使用语言建模分数用监督信号调整检索模型。在该框架中,通过双编码器架构对输入上下文和文档进行编码,然后计算余弦相似度来检索相关文档。计算每个检索到的文档的可能性和语言模型分数。然后通过最小化检索到的文档似然与语言模型得分分布之间的KL差异来更新检索模型参数。消融实验表明,该方法显著提高了原始语言模型的性能,且其改进并非来自于随机文档的集成。
Luo等人专注于利用指令调优来去噪检索结果。它们收集来自各种搜索api和域的检索结果,从而创建一个新的基于搜索的数据集。这个数据集包括指令、接地信息和响应。值得注意的是,它包括了相关的结果和那些不相关或有争议的结果。该模型需要学习基于有用的搜索结果。在对该数据集上的LLaMa-7B模型进行微调后,得到的模型名为SAIL-7B,在open-ended QA和事实检查等透明敏感任务中表现出了优越的性能。
基于RLHF RLHF-based。Menick等人使用来自人类偏好的强化学习(RLHP)训练一个名为GopherCite的2800亿参数模型,该模型产生答案和高质量的支持证据。他们首先从现有的模型中收集数据,并由人类对其进行评级。这些数据用于微调和奖励模型训练。一个有监督的微调模型被训练以产生具有适当的语法的准确引号。创建一个奖励模型,基于总体质量对模型输出进行排名。最后,对强化学习策略进行优化,使模型行为与人类偏好相一致,提高引用性能。当奖励模型得分过低时,该模型可能会拒绝回答这个问题。根据人类的评估,该模型在NaturalQuestions数据集的子集上比之前的SOTA(FiD-DPR)获得了更好的支持和可信的评级。
5.2.4在外部存储上的检索。
目前,大多数llm通过从外部存储中以文本片段的形式检索知识并将其合并到上下文中来增强其事实性。一些研究人员正在探索非文本形式的知识存储,并通过专门的方法将这些知识整合到模型中。
Li等人的将知识以键值对的形式存储在内存中。Key是通过使用文档检索嵌入器来编码知识来获得的,而value通过使用transformer编码器来编码的。与传统的基于检索的llm类似,该模型使用查询检索嵌入器对输入进行编码,并从内存中检索知识。然后通过交叉注意,将检索到的值整合到模型的多头注意层中,以增强事实性。
G-MAP 不显式地存储知识,而是使用通用域PLM作为外部内存。为了减轻自适应预训练过程中的灾难性遗忘,G-MAP在对领域特定的PLM(PLM-D)的微调过程中引入了一个冻结参数的一般域PLM(PLM-G)。在微调期间,输入将同时提供给PLM-G和PLM-D。PLM-G的每一层的隐藏状态存储在一个缓存中,并使用内存增强策略从某些层中提取隐藏状态,然后将其连接并集成到PLM-D的内存增强层中。该研究还比较了四种记忆增强策略,其中基于块的门控记忆转移表现最好。
微调方法和一些模型编辑方法通过不断的预训练,将新的知识存储在新的模型参数中。不同之处在于,微调方法在一个矩阵参数中存储了许多知识片段,而模型编辑则为每个知识片段建立了一个新的神经元。
Houlsby等人提出添加适配器模块,通过在现有层之间插入小的、可训练的模块,对原始模型的微调。在微调过程中,预训练模型的主体被冻结,适配器模块学习特定于下游任务的知识。适配器方法减少了模型微调的计算需求,同时增强了模型对特定领域的事实性。然而,适配器模块的增加也增加了模型的总体参数计数,在一定程度上降低了模型的推理性能。
为了增强模型对实体的理解,从而提高事实性,KALA、EaE和Mention Memory将编码的实体存储在外部存储中。在生成过程中,检索到的实体嵌入被集成到模型层中。
Kang等人引入了KALA来减少自适应训练中的开销和灾难性遗忘。KALA不仅为实体及其编码建立了一个内存,而且还使用了一个KG来存储这些实体之间的关系。对于输入中给定的提及,首先确定相应的实体。基于KG,从内存中检索到该实体及其邻近实体的编码。通过GNN加权聚合,得到了本文对应实体的编码。最后,在模型层中引入了知识条件特征调制(KFM),将编码结果集成到其中所涉及的所有标记的表示中。
Fevry等人在模型训练过程中引入了提及检测、实体链接和MLM。该模型从最接近当前提到的实体存储中查询前100个实体嵌入,并使用注意力对它们进行集成。
de Jong等人的TOME模型是对EaE模型的改进。TOME不是在内存中存储实体嵌入,而是存储实体提及的嵌入。对于输入中标记的实体提及,TOME从内存中检索所有相关的实体提及嵌入,并通过记忆注意层将它们集成到模型中。
与上面提到的三种方法类似,知识插件也引入了全部相关的知识。然而,它们没有将知识直接集成到模型层中,而是利用预训练到的映射网络。该网络将实体嵌入映射到预训练的语言模型(PLM)的token嵌入空间。最终,映射的实体嵌入注入输入嵌入级别,促进知识插入过程。
Xue等人通过引入扩展前馈网络(FFNs)和利用强化学习来提高基于知识的对话系统中的事实一致性的挑战,从而产生更准确和可靠的响应,如WoW和CMU_DoG数据集所示。
为了进一步解决事实校正任务,Gao等人探索了GPT-3等llm与搜索引擎的集成,以提高其精度和内存。其目标是使用搜索引擎来搜索证据和正确的由llm生成的句子。所提出的方法RARR是,对每个输入句子,生成一组问题,并搜索网页,以验证信息与输入句子的一致性。本文基于归属和保存标准,采用手动和自动验证两种方法对修改进行了评估。主要的评估指标是F1,考虑了归因和保存方面,以评估该方法在增强llm生成的句子方面的有效性。
Chen等人对T5模型进行了微调以作为编辑器,但在微调过程中引入了负样本。模型PURR被训练为回答用户的问题,执行谷歌搜索来检索前5个网页摘要(用作正样本),并通过使用语言模型替换这些正样本中的一些内容来产生噪声。然后训练一个序列到序列的模型,将嘈杂的句子修正回正确的版本。这种方法不同于EFEC,后者使用了掩码和填充的方法。PURR是对EFEC的一种改进,它专注于直接训练一个语言模型,使用谷歌搜索将错误的句子编辑成正确的句子,以生成正样本,最终导致F1-scores的增加。
5.2.5在结构化知识源上的检索 Retrieval on Structured Knowledge Sourc。论文将讨论在结构化存储库中检索的研究,如知识图谱和数据库,以在生成过程中获取事实数据。
Zhang等人利用知识图谱(KG)进行检索来处理事实错误。他们观察到,在用户的请求和KG中的内容之间可能存在不一致。例如,当用户提到一个全名时,KG可能只有其缩写,从而导致不完美的检索结果。为了纠正这一点,他们提出了一种方法来重新表述用户的请求。他们的方法涉及到基于用户输入的SQL查询和使用LLM的数据库元数据生成SQL查询。然后,他们查询数据库,并要求LLM识别出句子中的哪个实体对应于数据库中的一个实体,从而创建一个映射。使用数据库中的实体名称,系统将提示LLM重新制定这个问题。如果数据库查询导致选定列和项的多行,则使用贪婪方法生成一个新问题,提示用户获取更具体的细节,直到得出决定性的答案。实验表明,与当代最先进的技术相比,该方法在减轻语言模型的不准确性方面具有显著的改进能力。
StructGPT是一个通用的提示框架,它支持llm对结构化数据(例如,KG、表和数据库)的推理。一般来说,这个框架的核心是它们构建专门的接口来从结构化数据中收集相关证据(即阅读),并让llm集中于基于收集到的信息(即推理)的推理任务。特别地,他们提出了一种调用-线性化生成过程,以支持llm借助接口对结构化数据进行推理。通过使用提供的接口迭代此过程,论文的方法可以逐步接近给定查询的目标答案。对KGQA、TableQA和Text-to-SQL三种结构化数据进行的实验表明,在few-shots或zero-shot设置下,StructGPT极大地提高了llm的性能。
Baek等人提出将知识图谱中的事实知识注入到(大型)语言模型(直到GPT-3.5)中,根据知识图谱与输入问题的文本相似性从知识图谱中检索相关事实,然后将其作为语言模型的提示。与没有知识图谱的基线相比,这种方法将语言模型在知识图谱问题回答任务上的性能平均提高了48%。
5.3领域事实性增强的llm
领域知识缺陷不仅是限制LLM在特定领域应用的一个重要原因,也是学术界和工业界高度关注的课题。在本小节中,论文将讨论这些特定于领域的llm如何增强它们的领域事实性。
表9列出了增强的领域-事实性llm。在这里,论文包括了几个领域,包括医疗保健/医学(H)、金融(F)、法律/法律(L)、地球科学/环境(G)、教育(E)、食品测试(FT)和家庭装修(HR)。

基于领域特定的llm的实际场景和论文之前对增强方法的分类,论文总结了几种常用的针对领域特定的llm的增强技术:
(1)持续预训练:一种使用特定领域的数据不断更新和微调预训练的语言模型的方法。此过程确保模型在特定域或字段中保持最新的和相关性。它从一个初始的预训练的模型开始,通常是一个通用的语言模型,然后使用特定于领域的文本或数据对其进行微调。随着新信息的可用,该模型可以进一步进行微调,以适应不断发展的知识环境。持续的预训练是一种强大的方法,可以在快速变化的领域中保持人工智能模型的准确性和相关性,如技术或医学。
(2)持续的SFT:另一种增强人工智能模型的事实性的策略。在这种方法中,模型使用特定于感兴趣的领域的标记或注释数据进行微调。这种微调过程允许模型学习和适应该领域的细微差别和细节,提高了其提供准确和上下文相关信息的能力。它在可以长期访问特定于领域的标签数据的应用程序中特别有用,例如在法律数据库、医疗记录或财务报告中。
(3)从零开始训练:它包括在最少的先验知识或预训练下开始学习过程。这种方法可以比作用一张白纸教授机器学习模型。虽然它可能没有利用现有知识的优势,但在处理全新的相关数据有限的领域或任务时,从头开始的训练可能是有利的。它允许模型从头开始建立其理解,尽管它可能需要大量的计算资源和时间。
(4)外部知识:包括用来自外部来源的信息来增强语言模型的内部知识。这种方法允许模型访问数据库、网站或其他结构化数据存储库,以在响应用户查询时验证事实或收集其他信息。通过集成外部知识,该模型可以增强其事实核查能力,并提供更准确和与上下文相关的答案,特别是在处理动态或快速变化的信息时。下面,论文将介绍这些方法。
对于每个特定于领域的LLM,论文列出了它们各自的增强方法,如表9所示。
5.4医疗保健领域增强的LLM
这些llm已经成为医疗领域的强大工具,提供了各种各样的能力。这些模型,如 CohortGPT, ChatDoctor, DeID-GPT157, BioMedLM259, DoctorGLM281, MedChatZH243, BioGPT, GeneGPT, Almanac和 MolXPT,利用llm的潜力彻底改变医疗保健。它们配备了将非结构化医学文本分类为疾病标签等特征,通过知识图谱和样本选择策略提高性能,微调大型数据集的医患对话,实现自动医学文本识别,擅长医学问答任务,掌握传统的中文医学问答,并优于各种生物医学NLP任务。一些模型与基因组学问题的web api交互,而另一些模型专门研究临床指南和治疗建议。这些llm不仅展示了医疗保健领域的最先进表现,而且强调了特定领域的训练和评估的重要性,展示了它们在改变医疗保健和临床决策方面的潜力。
Zhang等人提出了HuatuoGPT,该模型使用了ChatGPT和医生的数据,在医疗咨询中取得了最先进的表现。它基于baichuan-7B和Ziya-LLaMA-13B-Pretrain-v1,不断对提取的数据(来自ChatGPT)和真实世界的数据(来自医生)进行预训练。
同样,Yang等介绍了第一个基于LLaMA的中医语言模型Zhongjing,它利用了全面的训练渠道和多回合医学对话数据集。具体来说,它通过一个名为CMtMedQA的多回合医疗对话数据集得到了增强,该数据集包含7万个真实的医患对话,支持复杂的对话和主动的查询。所使用的骨干模型为Ziya-LLaMA-13B-v1,评估数据集为CMtMedQA和huatuo-26M。
Wang等人推出了一个名为LLM-AMT的系统,该系统通过医学教科书改进了GPT-3.5-Turbo和LLaMA-2-13B等大规模语言模型,特别是增强了开放领域的医学问答任务。同时,外部知识来源是一只混合教科书检索器,其中包括来自MedQA数据集和维基百科的51本教科书。
Bao等人提出了DISC-MedLLM解决方案,该解决方案使用LLMs在会话医疗服务中提供准确的医疗响应,利用医学知识图谱、真实对话重建和人工引导的偏好重构等策略来创建高质量的SFT数据集,应用于baichuan-13b-base。本文使用各种数据集进行微调,包括重建的AI医患对话、MedDialog、cMedQA、知识图谱QA对(CMeKG)、行为偏好数据集(手动选择)、MedMCQA、MOSS6和Alpaca-GPT。
类似地,Guan等人引入了CohortGPT,这是一种通过将复杂的医学文本分类为疾病标签,在临床研究中使用llm来招募参与者的模型。CohortGPT通过使用知识图谱作为辅助信息和CoT样本选择策略来提高ChatGPT的性能。这些任务包括IU-RR(准备一套供分发和检索的放射学检查)和MIMIC-CXR(Mimic-cxr,一个去识别的公开的胸片数据库)。Li等人介绍了ChatDoctor,一个改进的基于llama的模型。它使用一个包含10万名病人-医生对话的数据集进行微调,并配备了一个自导向的信息检索机制。
Liu等人介绍了DeID-GPT,这是一个利用GPT-4进行自动医疗文本去识别的框架。此外,本文还提到了使用HIPAA标识符作为一个额外的知识来源来增强去识别过程。
Venigalla等人提出了BioMedLM,这是一种基于PubMed数据训练的领域特定的LLM,用于医疗QA任务。Xiong等人介绍了DoctorGLM,这是一种以中文为重点的语言模型,针对医疗保健特定的任务进行了微调。Tan等人和Luo等人分别为传统中医问答和生物医学自然语言处理任务引入了对话和生成转换语言模型。
Jin等人提出了GeneGPT,一种使用NCBI Webapi教学llm回答基因组学问题的方法。Zakka等人介绍了Almanac,这是一种具有医学指南建议检索能力的LLM。最后,Liu等人介绍了MolXPT,一种擅长于分子性质预测和分子生成的统一语言模型。
5.5法律领域增强的llm
这些llm,如LawGPT 和ChatLaw,已经经过微调,以提供全面的法律援助,从回答复杂的法律查询和生成法律文件到提供专家法律建议。利用广泛的法律文本语料库,这些模型确保了上下文感知和准确的响应。此外,它们的持续发展包括注入领域知识,设计有监督的微调任务,以及整合检索模块来解决幻觉等问题,并确保高质量的法律援助。这些创新不仅为更容易获得和更可靠的法律服务铺平了道路,而且也为法律领域内的研究和探索开辟了新的途径。
Nguyen引入了LawGPT 1.0,这是一个针对法律领域的经过微调的GPT-3语言模型,可以提供会话法律援助,包括回答法律问题、生成法律文件和提供法律建议。本文提到了使用大量的法律文本语料库对模型进行微调,以使其适应法律领域。
Savelka等评估GPT-4的性能生成法律术语的解释立法,比较基线方法增强方法,使用法律信息检索模块提供背景从判例法,揭示质量的改进和解决事实准确性和幻觉的问题。
Huang等人通过在持续训练中注入领域知识,设计适当的监督微调任务,并结合检索模块来提高文本生成过程中的事实性,解决了增强LLaMA等LLMs的挑战,特别是在法律领域。他们公布了自己的数据和模型,以进一步研究中文的法律任务。
Cui等人介绍了为中文法律领域设计的开源法律LLM ChatLaw。本文介绍了一种改进数据筛选过程中模型事实性的方法,以及一种进行错误处理的自注意方法。本文使用各种数据集对ChatLaw进行微调,包括原始法律数据的收集、基于法律法规和司法解释构建的数据,以及抓取真实的法律咨询数据。本文使用的主要模型是Ziya-LLaMA-13B,它是ChatLaw的骨干,为中文法律领域量身定制,并优化处理法律问题和任务。此外,本文还采用了向量数据库检索方法、关键词检索方法和自注意方法来提高模型在法律领域的性能。
5.6金融领域增强LLM
这些llm结合了专门为商业和金融任务设计的复杂语言模型,以提供健壮的处理能力。他们专注于为金融文本分析和电子商务设置创建量身定制的解决方案,并在包含大量业务相关任务和大量金融token的数据集上进行训练。它们被设计用来执行过多的功能,从理解和生成各种电子商务任务的指令,到识别情绪,识别命名实体,以及在金融环境中回答问题。该模型对不同任务和基准上的zero-shot泛化进行了进一步的微调。
Li等人介绍了EcomGPT,这是一种为电子商务场景定制的语言模型,在新创建的EcomInstruct数据集上进行训练,该数据集包含250万条跨越各种电子商务任务和数据类型的指令数据。该数据集包括产品信息、用户评论等。它定义了原子任务和任务链任务,以便为电子商务场景提供全面的训练。所使用的主干模型是BLOOMZ,它是对EcomInstruct数据集进行微调的。评估数据集包括12个任务,包括分类、生成、提取和其他与电子商务相关的任务。
Wu等人引入了BloombergGPT,一个专门的500亿参数语言模型,在3630亿token数据集上进行训练,该数据集结合了彭博广泛的金融数据源和通用数据集。本文中使用的数据集是一个广泛的3630亿个token数据集,其中包括来自彭博社来源的很大部分财务数据(占训练数据的51.27%)。BlombergGPT基于一种被称为BLOOM的解码器因果语言模型架构。评估包括各种金融自然语言处理任务,如情感分析、命名实体识别、二元分类和问题回答。
5.7其他域增强的LLM
地球科学和环境领域增强的llm,是专业设计的,利用全面的资料来提供与地球科学和可再生能源有关的精确和可靠的结果。K2是地球科学LLM的先驱,在大量地球科学文本语料库上进行训练,并使用地球信号数据集进一步细化。与此同时,另一个专注于先驱的可再生能源LLM的HouYi模型利用了可再生能源学术论文数据集,包含超过100万的学术文献来源。这些llm经过了微调,以便在各自的领域提供了良好的性能,在与用户查询和可再生能源学术文献相结合方面显示出了强大的能力。
Deng等人介绍了K2,这是第一个专门为地球科学设计的LLM,它基于LLaMA-7B,在55亿个标志性的地球科学文本语料库上进行连续训练,并使用地球信号数据集进行微调。本文还介绍了一些资源,如地球科学指令调整数据集,和GeoBench,在地球科学背景下评估llm的第一个地球科学基准。
白等人介绍了Houyi模型的发展,第一个专门为可再生能源而生的LLM,利用新创建的可再生能源学术论文(REAP)数据集,其中包含超过110万可再生能源相关的学术文献,Houyi模型是基于一般LLM如ChatGLM-6B进行微调的。
Bi等人提出了OceanGPT,海洋领域的第一个LLM,它是各种海洋科学任务方面的专家。他们还提出了一个名为DoDoult的新框架来自动获得大量的海洋域数据。OceanGPT在OceanBench进行评估,显示了海洋科学任务的更高水平的专业知识。
教育领域增强的llm。用于协助教育场景。GrammarGPT就是一个例子,它为语言学习提供了一种创新的方法,特别是关注汉语语法中的错误纠正。它是一个开源的针对中文本地语法纠错的LLM,它利用chatgpt生成的和人注释数据的混合数据集,以及启发式方法来指导模型生成非语法句子。所使用的骨干模型是phoenix-inst-chat-7b。
食品领域增强的llm。是专门为满足食品测试协议的不同要求而设计的语言模型。例如,齐等人介绍FoodGPTLLM食品测试将结构化知识和扫描文档使用增量训练的方法,通过构建一个知识图谱作为外部知识库解决机器幻觉,利用Chinese-LLaMA2-13B作为骨干模型并收集食品相关数据训练。
家庭装修领域增强的llm。是为家庭装修任务量身定制的领域特定的语言模型。例如,Wen等人介绍了ChatHome,它使用了一种双管齐下的方法,包括领域自适应的预训练和广泛的数据调整,该数据集包括专业文章、标准文档和与家庭装修相关的网络内容。骨干模型为baichuan-13B,评估数据集包括C-Eval、CMMLU和新创建的“EvalHome”域数据集,微调数据源包括国家标准、域图书、域网站和 WuDaoCorpora。
六、结论
在整个调查过程中,论文系统地探索了大型语言模型(llm)中的事实性问题的复杂图景。论文首先定义了事实性的概念,然后继续讨论了其更广泛的含义。论文讲述了事实评估的多方面领域,包括基准、指标、具体评估研究和特定领域的评估。然后,论文更深入地探索了llm中支撑事实性的内在机制。论文的探索最终是关于增强技术的讨论,包括针对独立的LLM和检索增强的LLM,特别关注特定领域的LLM增强。
尽管这项调查详细说明了进展,但仍有一些挑战很大。对事实性的评估仍然是一个复杂的谜题,由于自然语言固有的可变性和细微差别而变得复杂。管理llm如何存储、更新和生成事实的核心过程尚未完全揭示。虽然某些技术,如持续的训练和检索,显示出了希望,但它们并非没有限制。展望未来,论文既在追求完全真实的llm,也带来了挑战和机遇。未来的研究可能会更深入地理解llm的神经结构,开发更稳健的评估指标,并创新增强技术。随着llm越来越多地融入论文的数字生态系统,确保其实际可靠性仍将至关重要,并将影响整个人工智能社区及其他领域。