MOMENT: A Family of Open Time-series Foundation Models
PDF: https://arxiv.org/pdf/2402.03885.pdf
Code: https://anonymous.4open.science/r/BETT-773F/README.md
1 概述
MOMENT是一个用于通用时间序列分析的开源基础模型系列。由于缺少大型公共时间序列存储库、时间序列特征多样以及缺乏实验基准等挑战,预训练这些模型变得困难。因此,科研人员创建了庞大的公共时间序列集合,并解决了特定挑战以实现大规模多数据集预训练。他们还设计了一个基准来评估这些模型在有限监督设置下的性能。实验表明,预训练模型在少量数据和特定任务微调下表现有效。
2 Methodology
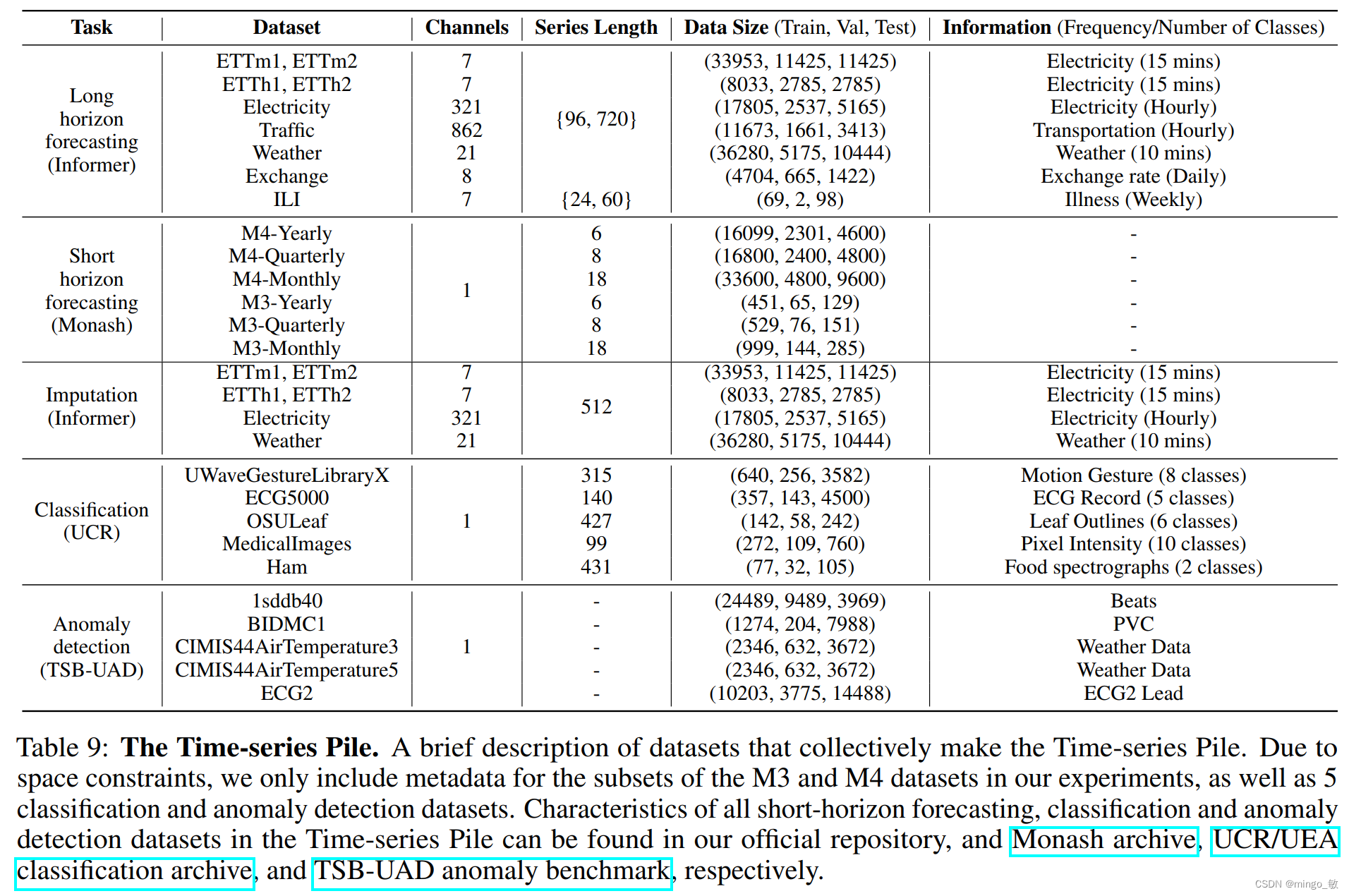
2-1 时间序列堆(The Time-series Pile)
Informer长视野预测数据集(Informer long-horizon forecasting datasets)包含9个评估长视野预测性能的数据集。
Monash时间序列预测归档(Monash time-series forecasting archive)则涵盖58个短视野预测数据集,涉及多个领域和时间分辨率。
UCR/UEA分类归档(UCR/UEA classification archive)包括159个常用于分类算法基准测试的时间序列数据集。
TSB-UAD异常基准(TSB-UAD anomaly benchmark)是一个包含1980个带异常标签的单变量时间序列的集合,涉及多个来源的数据。
2-2 模型结构 Model Architecture
MOMENT接收一元时间序列T和相应的掩码M,其中0表示未观测数据,1表示已观测数据。在分割为N个长度为P的片段前,对观测数据应用可逆实例归一化。每个片段根据是否观测到所有时间步,映射到D维嵌入,使用线性投影或特定的掩码嵌入[MASK]。这些嵌入作为变换器模型的输入,模型保持其形状(1×D)并通过操作。
变换后的片段嵌入用于重建原始时间序列片段,通过一个轻量级的预测头完成。该预测头的目标是将嵌入映射到期望的输出维度,实现时间序列的重建。模型的设计简化了编码器,采用了轻量级的预测头,以便在保持编码器学到的高级特征的同时,对有限的可训练参数进行特定任务的微调。

2-3 预训练概述 Pre-training using Masked Time-series Modeling
MOMENT通过遮蔽时间序列建模任务进行预训练。在训练中,随机遮蔽一些片段并用[MASK]替换,然后通过变换器编码器学习表示,用重建头重建原始序列。目标是最小化遮蔽部分的均方误差。
预训练配置了三种规模的MOMENT模型,对应T5的不同大小。模型参数随机初始化,输入序列长度固定为512,分为64个片段,每段8个时间步,随机遮蔽30%的片段。使用Adam优化器和余弦学习率调度,训练2个周期。
2-4 微调应用于下游任务 Fine-tuning on Downstream Tasks
MOMENT适用于多种时间序列分析任务,如预测、分类、异常检测和插值。预测任务用预测头替换重建头,其他任务保持不变。微调可以端到端进行,或仅对重建/预测头进行线性探测。对于某些任务,MOMENT还可以在零样本设置下使用。
3 Experiment
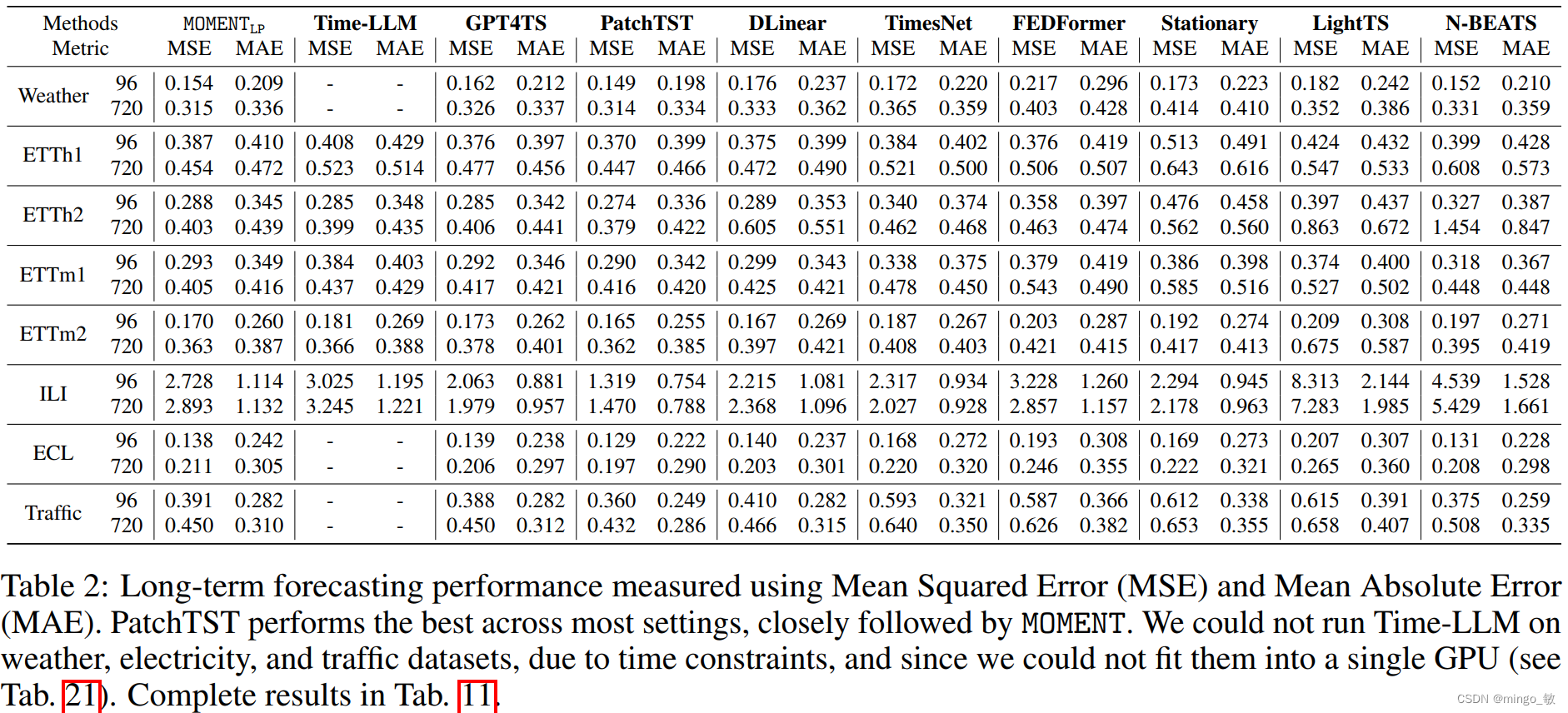
Long-horizon forecasting
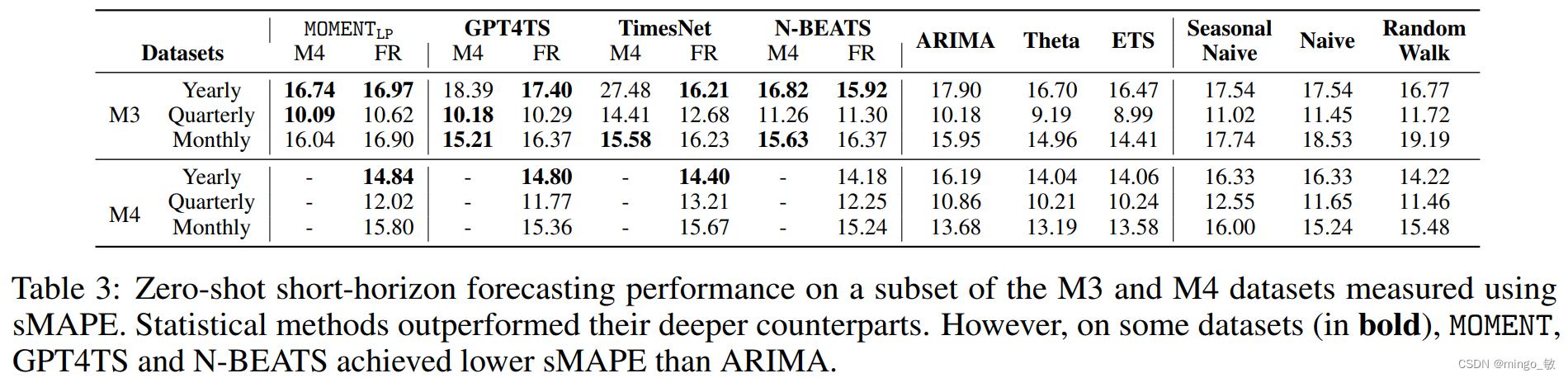
Zero-shot short-horizon forecasting
Classification

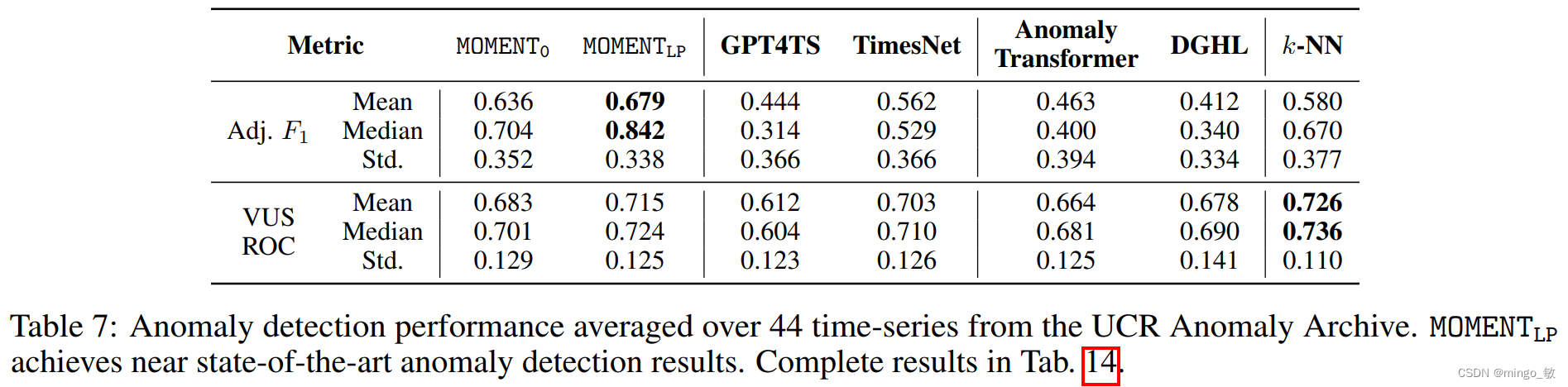
Anomaly detection
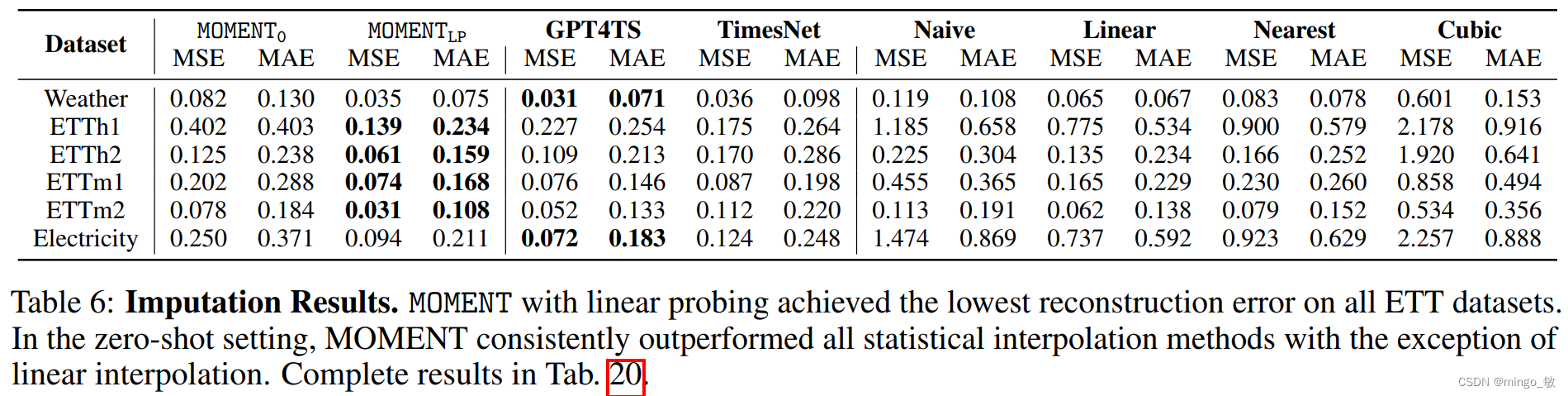
Imputation




![[大模型]ChatGLM3-6B Code Interpreter](https://img-blog.csdnimg.cn/direct/4536a1ed3c4b456d9f9d86adcbdeda9a.png#pic_center)