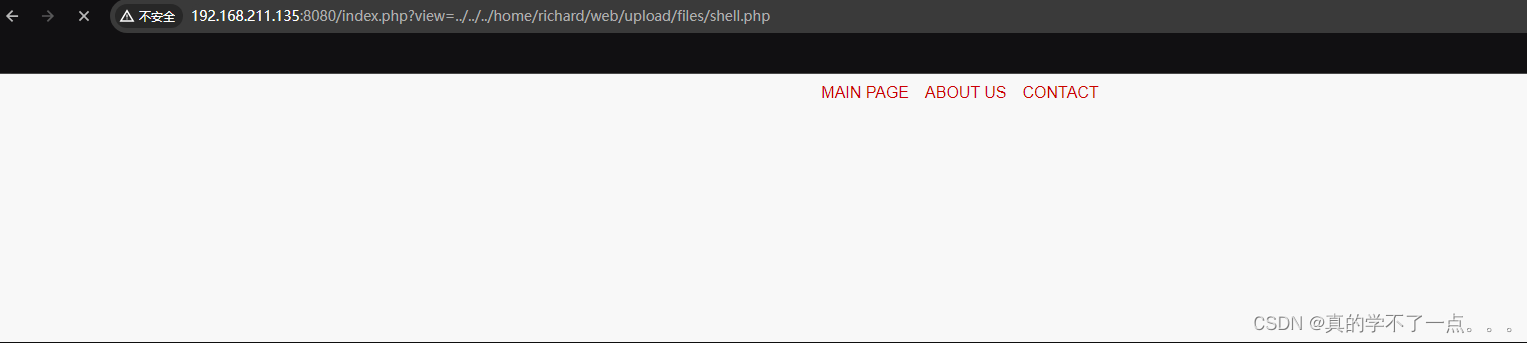
Hadoop分布式文件系统支持NameNode的高可用性,本文主要描述NameNode多节点高可用性的安装部署。
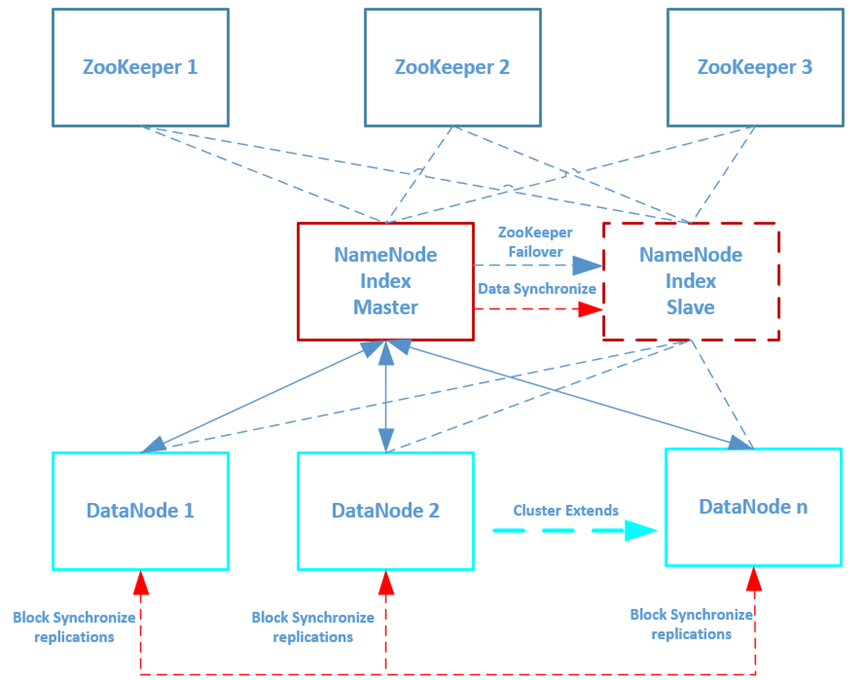
如上所示,Hadoop分布式文件系统部署了NameNode的Master主节点以及NameNode的Slave副节点,当Master主节点发生故障变得不可用时,ZooKeeper集群自动将失败转移到Slave副节点,Slave副节点继续提供服务
| NameNode1 Master ZooKeeper1 | 192.168.0.136 |
| DataNode1 NameNode2 Slave ZooKeeper2 | 192.168.0.137 |
| DataNode2 ZooKeeper3 | 192.168.0.138 |
| DataNode3 | 192.168.0.139 |
如上所示,NameNode主节点、NameNode副节点、DataNode集群节点、ZooKeeper集群节点的IP地址信息
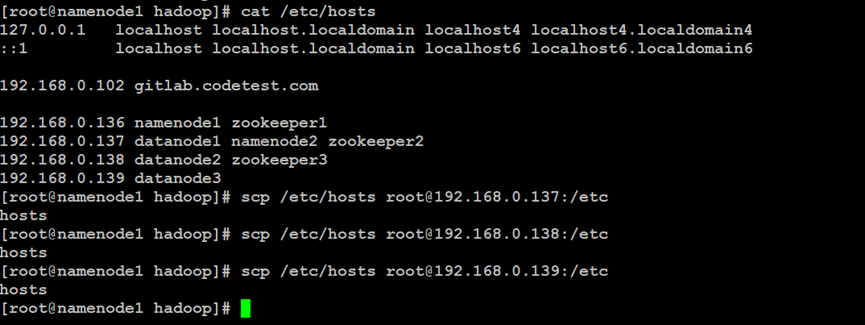
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,更新主机信息配置文件,同步到Hadoop集群的其他节点
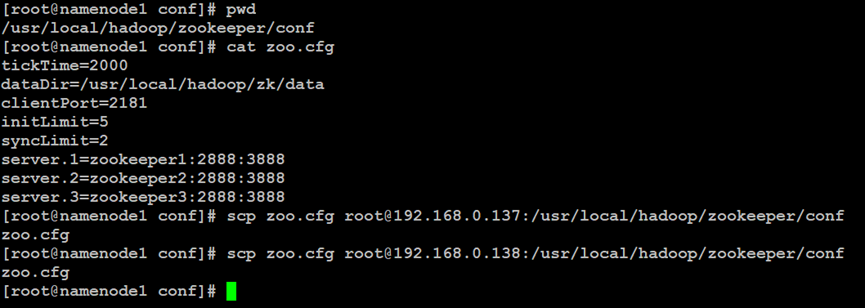
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,更新ZooKeeper集群的节点属性配置文件,同步到ZooKeeper集群的其他节点



如上所示,在ZooKeeper集群节点的数据文件夹中设置myid
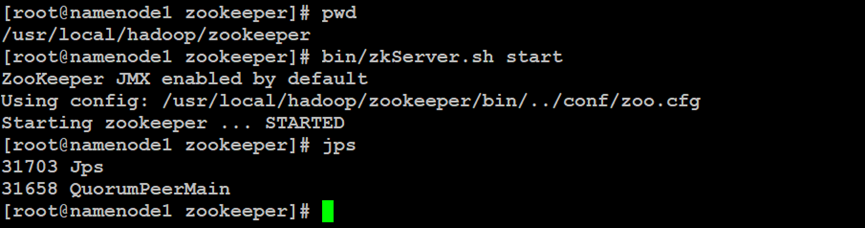
如上所示,在ZooKeeper集群节点中启动ZooKeeper服务
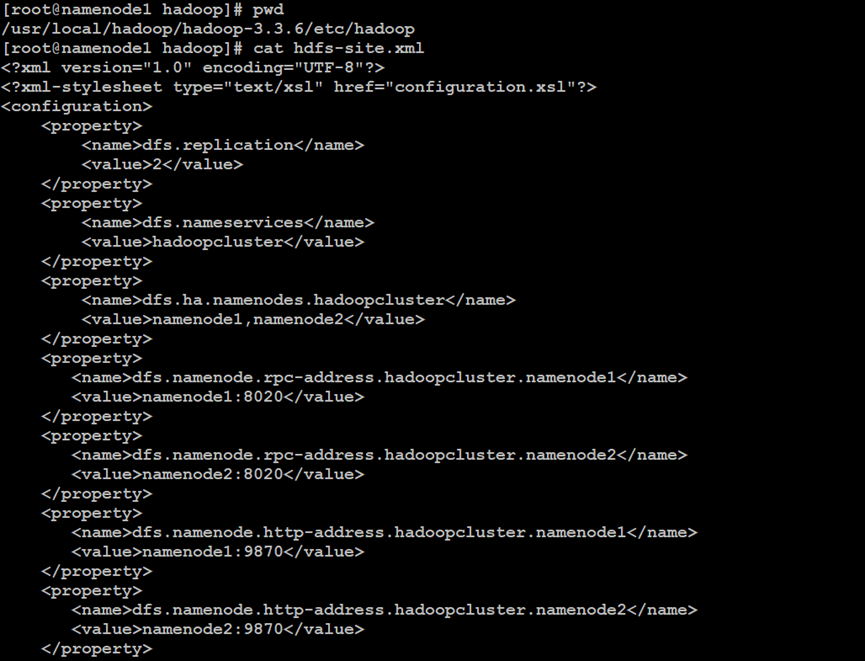
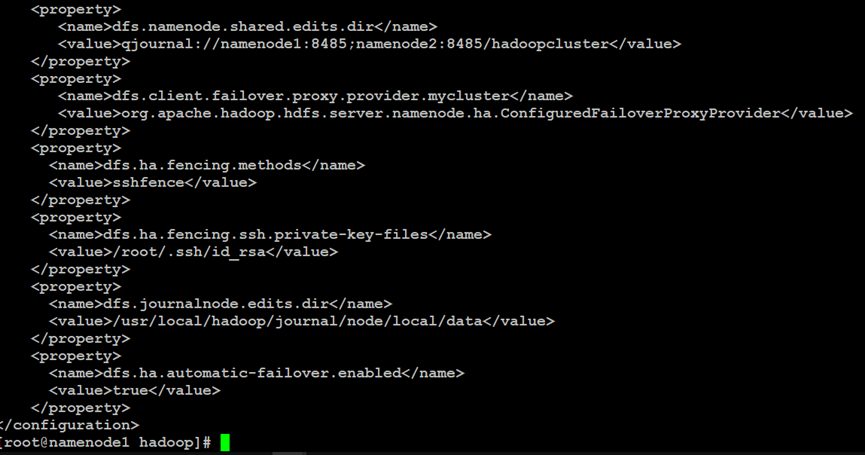
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,设置NameNode高可用性的配置文件属性
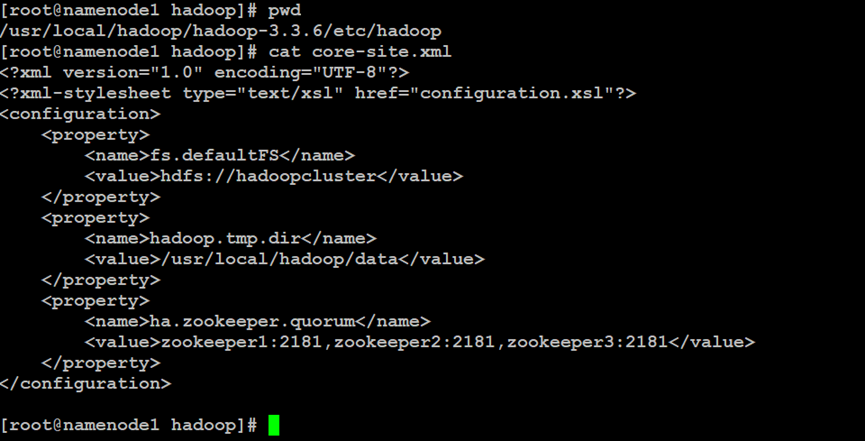
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,设置NameNode高可用性的配置文件属性

如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,设置DataNode集群节点的主机信息
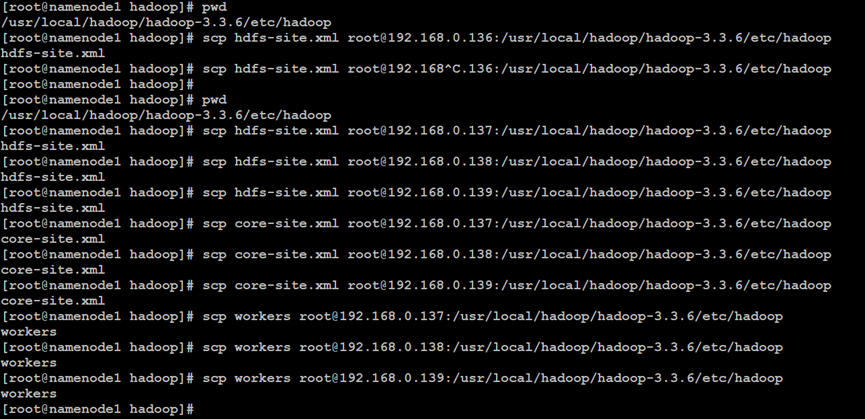
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,同步属性配置文件到Hadoop集群的其他节点
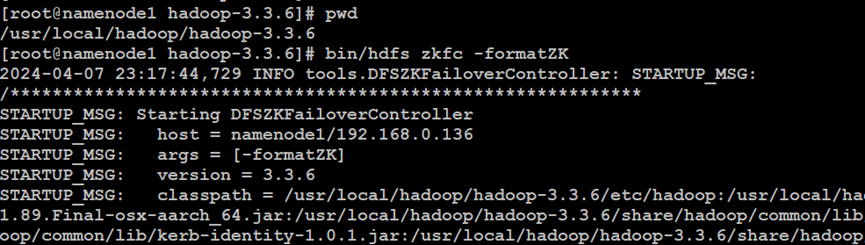
如上所示,在Hadoop分布式文件系统的NameNode主索引节点、NameNode副索引节点中,执行格式化ZooKeeper集群节点数据文件
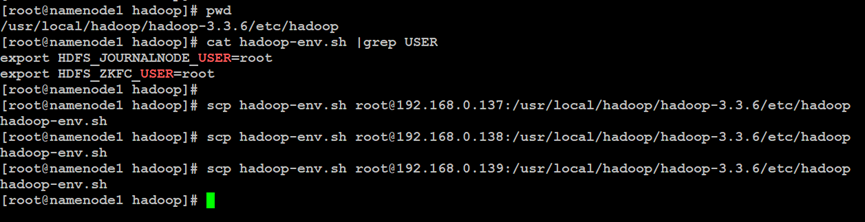
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,设置NameNode高可用性的用户环境变量,同步到Hadoop集群的其他节点
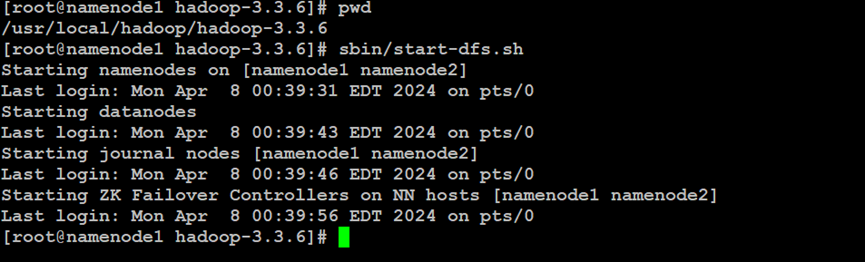
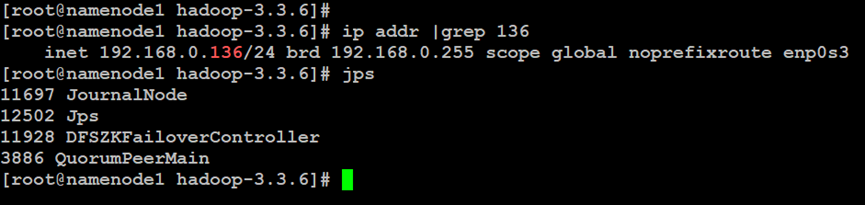
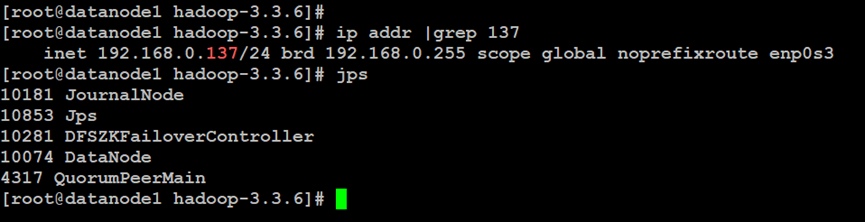
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,启动Hadoop集群服务
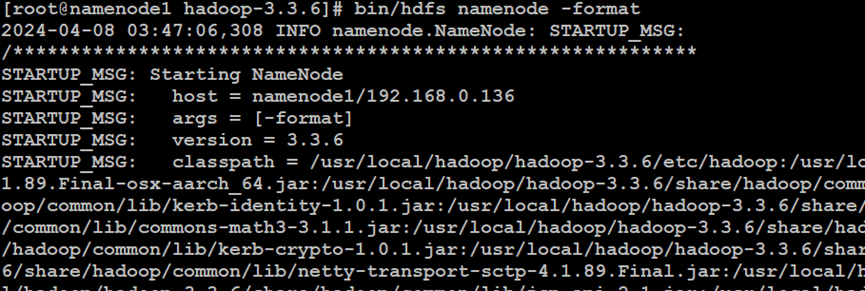
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,格式化NameNode主节点
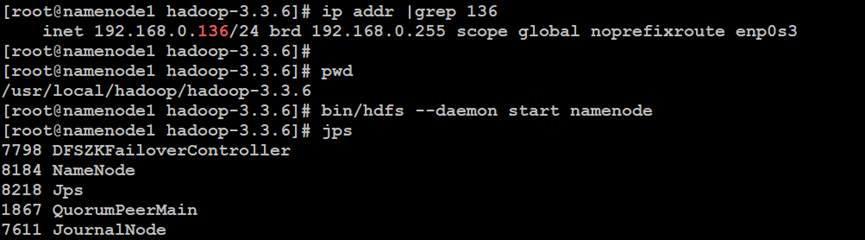
如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,启动NameNode主节点服务
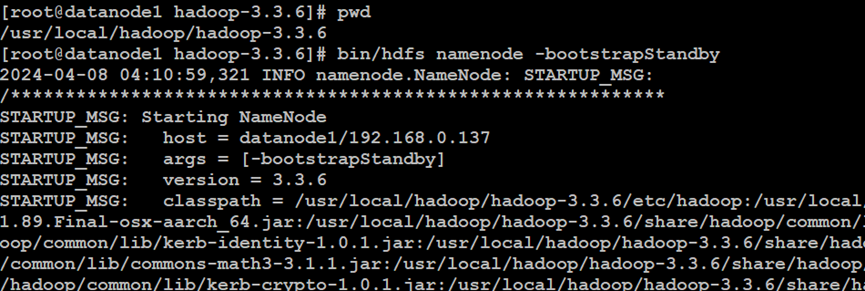
如上所示,在NameNode副节点中,同步NameNode主节点的格式化信息
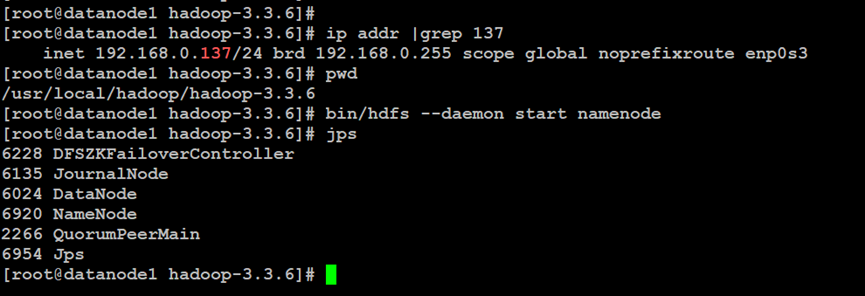
如上所示,在NameNode副节点中,启动NameNode副节点服务
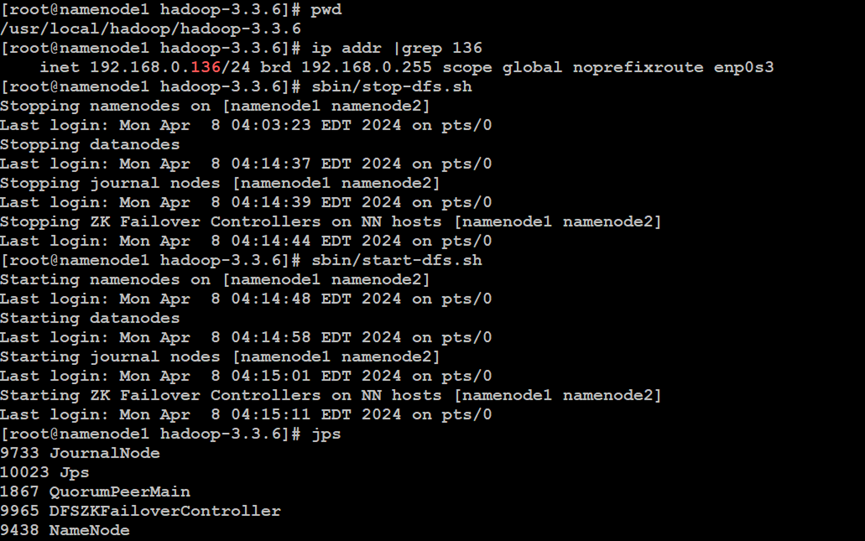

如上所示,在Hadoop分布式文件系统的NameNode主索引节点中,重新启动Hadoop集群服务
| http://192.168.0.136:9870/ http://192.168.0.137:9870/ |


如上所示,在浏览器中访问NameNode主节点或者NameNode副节点web页面,显示NameNode节点信息
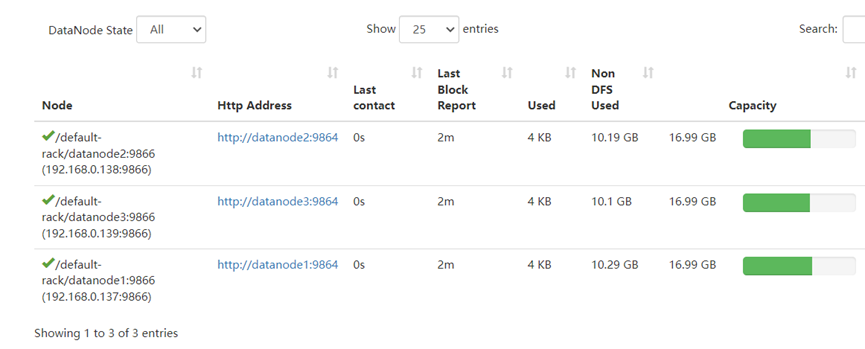
如上所示,在浏览器中访问NameNode主节点或者NameNode副节点web页面,显示DataNode集群节点信息