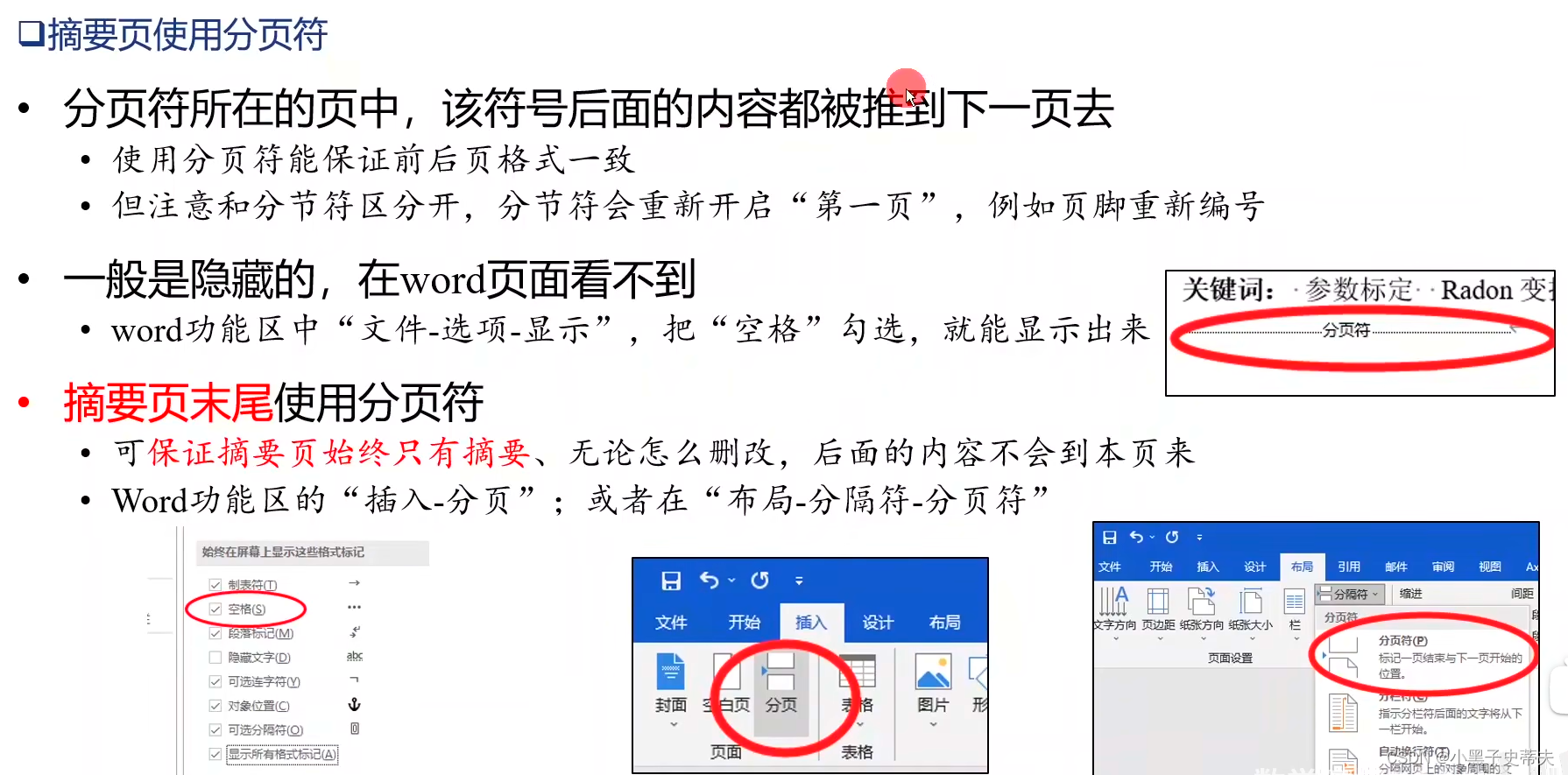
文章目录
- 前言
- 参考目录
- 学习笔记
- 1:介绍
- 2:游程编码 run-length encoding
- 2.1:介绍
- 2.2:Java 实现
- 3:霍夫曼压缩 Huffman compression
- 3.1:变长前缀码 variable-length codes
- 3.1.1:介绍
- 3.1.2:前缀码单词查找树
- 3.2:霍夫曼编码
- 3.2.1:概述
- 3.2.2:Java 实现:单词查找树节点
- 3.2.3:Java 实现:扩展
- 3.2.4:Java 实现:单词查找树、编译表
- 3.2.5:Java 实现:压缩
- 3.3:demo 演示
- 3.4:小结
- 4:LZW 压缩算法
- 4.1:统计方法
- 4.2:LZW 压缩
- 4.3:LZW 扩展
- 4.4:特殊情况
- 4.5:Java 实现
- 4.6:小结
前言
本篇主要内容包括:游程编码、霍夫曼压缩算法、LZW 压缩算法。
建议在学习本篇之前先行学习或回顾 《5.2 单词查找树》的内容。
参考目录
- B站 普林斯顿大学《Algorithms》视频课
(请自行搜索。主要以该视频课顺序来进行笔记整理,课程讲述的教授本人是该书原版作者之一 Robert Sedgewick。) - 微信读书《算法(第4版)》
(本文主要内容来自《5.5 数据压缩》) - 官方网站
(有书本配套的内容以及代码)
学习笔记
注1:下面引用内容如无注明出处,均是书中摘录。
注2:所有 demo 演示均为视频 PPT demo 截图。
注3:如果 PPT 截图中没有翻译,会在下面进行汉化翻译,因为内容比较多,本文不再一一说明。
1:介绍
这个世界充满了数据,而能够有效表达数据的算法在现代计算机基础架构中有着重要的地位。压缩数据的原因主要有两点:节省保存信息所需的空间和节省传输信息所需的时间。
对于通用数据压缩:

2:游程编码 run-length encoding
2.1:介绍
![![L21-55DataCompression_15]](https://img-blog.csdnimg.cn/direct/60c80ef5b58a470383dcbbfbad14e18b.png)
将 40 位长的比特字符串拆解可得:15个0,7个1,7个0,11个1(交替出现的 0 和 1)
用 4 位表示长度并以 0 开头,可以得到:15=1111,7=0111,7=0111,11=1011
即:1111011101111011
问题一:用多少比特表示游程长度?
答:用 8 位(但本例中使用 4 位)
问题二:当某个游程的长度超过了能够记录的最大长度时怎么办?
答:当运行长度超过最大值时,插入长度为0的运行进行间隔。
2.2:Java 实现
edu.princeton.cs.algs4.RunLength
![![image-20240405171955560]](https://img-blog.csdnimg.cn/direct/74bd563b747843c9ac708464f71c6d40.png)
edu.princeton.cs.algs4.RunLength#compress
![![image-20240405172110231]](https://img-blog.csdnimg.cn/direct/4bbe36da57b54c3c8ee10893cd1463fa.png)
3:霍夫曼压缩 Huffman compression
3.1:变长前缀码 variable-length codes
3.1.1:介绍
根据不同字符采用不同位数进行编码。
![![L21-55DataCompression_19]](https://img-blog.csdnimg.cn/direct/8781c9caa552426a81e97122831fb235.png)
Q. 如何避免歧义?
**A. ** 确保任何编码都不作为其他编码的前缀存在。
示例 1. 固定长度编码。
示例 2. 在每个编码字后附加特殊终止字符。
示例 3. 实现通用的前缀码。
3.1.2:前缀码单词查找树
注:建议回顾《5.2 单词查找树》 。
![![L21-55DataCompression_20]](https://img-blog.csdnimg.cn/direct/09a30bc2fc964eb696d92e78416c0076.png)
Q. 如何表示前缀码?
A. 单词查找树!
- 字符存储在叶子节点上。
- 每个编码对应从树的根节点到某个叶子节点的一条路径。
![![L21-55DataCompression_21]](https://img-blog.csdnimg.cn/direct/bd2366c80b5e4ea29e8ff8ba87967f96.png)
压缩:
- 方法1:从叶子节点开始,沿路径向上追溯至根节点,反向输出各节点对应的二进制位。
- 方法2:创建键-值对的符号表。
扩展:
- 从根节点开始。
- 若当前位为 0,则向左子树移动;若为 1,则向右子树移动。
- 若到达叶子节点,则输出该节点所代表的字符,并返回到根节点继续处理下一个位。
![![image-20240405174020211]](https://img-blog.csdnimg.cn/direct/e616ab2382b949299959c2152f14851b.png)
3.2:霍夫曼编码
3.2.1:概述
![![L21-55DataCompression_22]](https://img-blog.csdnimg.cn/direct/237868ded4f04fbba475e571da74b153.png)
动态模型: 针对每条消息使用自定义的前缀码进行压缩。
压缩过程:
- 读取待压缩的消息。
- 根据消息内容构建最优的前缀码。如何构建?
- 将生成的前缀码(单词查找树)写入文件。
- 利用构建好的前缀码对消息进行压缩。
扩展过程:
- 从文件中读取前缀码(单词查找树)。
- 读取已压缩的消息,并利用单词查找树对其进行扩展还原。
3.2.2:Java 实现:单词查找树节点
![![image-20240405174719041]](https://img-blog.csdnimg.cn/direct/790ca0f22f4f441f89d3c2f42df3a089.png)
edu.princeton.cs.algs4.Huffman.Node
![![image-20240405175437498]](https://img-blog.csdnimg.cn/direct/083df9b4a4a64926a8974d8183a9778f.png)
3.2.3:Java 实现:扩展
edu.princeton.cs.algs4.Huffman#expand
![![image-20240405174941646]](https://img-blog.csdnimg.cn/direct/552c8b2d626b4d63a85fddb2a3f4585b.png)
3.2.4:Java 实现:单词查找树、编译表
edu.princeton.cs.algs4.Huffman#buildTrie
![![image-20240405175922898]](https://img-blog.csdnimg.cn/direct/742b8c461fbc423a897a911878f5017d.png)
edu.princeton.cs.algs4.Huffman#buildCode
![![image-20240405175938985]](https://img-blog.csdnimg.cn/direct/d9bda2bbd77344388a39bd3e3d769dca.png)
3.2.5:Java 实现:压缩
edu.princeton.cs.algs4.Huffman#compress
/**
* Reads a sequence of 8-bit bytes from standard input; compresses them
* using Huffman codes with an 8-bit alphabet; and writes the results
* to standard output.
* 从标准输入中读取8位字节序列; 使用具有8位字母的霍夫曼代码对其进行压缩; 并将结果写入标准输出。
*/
public static void compress() {
// read the input
String s = BinaryStdIn.readString();
char[] input = s.toCharArray();
// tabulate frequency counts
int[] freq = new int[R];
for (int i = 0; i < input.length; i++)
freq[input[i]]++;
// build Huffman trie
Node root = buildTrie(freq);
// build code table
String[] st = new String[R];
buildCode(st, root, "");
// print trie for decoder
writeTrie(root);
// print number of bytes in original uncompressed message
BinaryStdOut.write(input.length);
// use Huffman code to encode input
for (int i = 0; i < input.length; i++) {
String code = st[input[i]];
for (int j = 0; j < code.length(); j++) {
if (code.charAt(j) == '0') {
BinaryStdOut.write(false);
}
else if (code.charAt(j) == '1') {
BinaryStdOut.write(true);
}
else throw new IllegalStateException("Illegal state");
}
}
// close output stream
BinaryStdOut.close();
}
3.3:demo 演示
- 计算输入字符的频率。
![![image-20240405180301604]](https://img-blog.csdnimg.cn/direct/5b01e01cfe364ff9b1dc14764d82dbf8.png)
- 从每个字符开始,对应创建一个节点,并赋予其权重等于该字符的出现频率。(按照权重排序)
![![image-20240405180339783]](https://img-blog.csdnimg.cn/direct/f370c4ac743f42829cddcdcd85ddecab.png)
- 找到最小权重的两个。
- 合并成一个累计权重的单词查找树。
![![image-20240405180714577]](https://img-blog.csdnimg.cn/direct/58382e73a5354e16ae42fcf38f7a0ff1.png)
将新的树放回原本的队列中,按照权重排序。
![![image-20240405181057070]](https://img-blog.csdnimg.cn/direct/ca8d8e7558a0416c906afce05a356ef9.png)
重复以上的构建步骤,具体过程如下:
![![image-20240405181146423]](https://img-blog.csdnimg.cn/direct/b957dd715b214489af128f270decda67.png)
![![image-20240405181226901]](https://img-blog.csdnimg.cn/direct/aa7fc691edc84f2bbf24b0f3bdacb618.png)
![![image-20240405181332540]](https://img-blog.csdnimg.cn/direct/4f7da6f7edfe42d99308d150f2d7e5ff.png)
![![image-20240405181352694]](https://img-blog.csdnimg.cn/direct/51ea59ed2f284cc69844fe9ff840c15e.png)
![![image-20240405181407305]](https://img-blog.csdnimg.cn/direct/035efef74a524b11a74f97ab90e09c0f.png)
![![image-20240405181435345]](https://img-blog.csdnimg.cn/direct/30d0e85b37a34e18b3865c6da1ffdddc.png)
![![image-20240405181451244]](https://img-blog.csdnimg.cn/direct/be59f8faec3a48ae8278c351dceb04df.png)
最终构建结果:
![![L21-55DataCompression_29]](https://img-blog.csdnimg.cn/direct/2ea0e3d2b44f4aad9c14883b9f7a25cb.png)
3.4:小结
![![L21-55DataCompression_30]](https://img-blog.csdnimg.cn/direct/57d432642c09490e93af2b2f1e5ebc0a.png)
Q. 如何找到最佳的前缀码?
霍夫曼算法:
- 计算输入字符串中每个字符 i 的出现频率
freq[i]。 - 针对每个字符 i,初始化一个节点,节点的权重设置为其频率
freq[i]。 - 重复以下过程直到形成一个单一的单词查找树:
- 选择两个具有最小权重
freq[i]和freq[j]的节点。 - 将这两个节点合并成为一个新节点,新节点的权重为原两个节点权重之和
freq[i] + freq[j]。
- 选择两个具有最小权重
![![L21-55DataCompression_32]](https://img-blog.csdnimg.cn/direct/1a832d47fa3344188d39d047bfbba26f.png)
对应书本命题 U:
![![image-20240405182201039]](https://img-blog.csdnimg.cn/direct/d6e5bb57962344d6ad85bc50c4df50fd.png)
4:LZW 压缩算法
4.1:统计方法
![![L21-55DataCompression_34]](https://img-blog.csdnimg.cn/direct/d08ce317799a4ce3ad3e492ee125193a.png)
静态模型: 应用于所有文本的固定模型。
- 速度快。
- 不是最优:因为各类文本具有各自的统计特征差异。
- 示例:ASCII码、摩尔斯电码。
动态模型: 根据文本内容动态生成压缩模型。
- 需要先进行一次预处理遍历来建立模型。
- 在传输压缩数据时,必须同时发送模型信息。
- 示例:霍夫曼编码。
适应性模型: 在读取文本过程中不断学习和更新模型。
- 精确的模型构建可带来更高的压缩率。
- 解压时需从起始位置开始解码整个文件。
- 示例:LZW算法。
4.2:LZW 压缩
demo 演示:
![![image-20240405195218117]](https://img-blog.csdnimg.cn/direct/dd6715d2fcc2483a8f460350397bde50.png)
压缩:
![![L21-55DataCompression_36]](https://img-blog.csdnimg.cn/direct/e4b74228bb1647c886c18f0e80ee59e4.png)
LZW压缩:
- 创建一张关联 W 位长度编码值和字符串的符号表。
- 初始化 ST,其中包含单个字符键对应的码字。
- 在输入未扫描部分中查找 ST 中最长的字符串 s,该字符串是输入的一个前缀。
- 写出与字符串s关联的W位码字。
- 将 s 与输入中的下一个字符 c 拼接起来,形成新的字符串,并将其添加到 ST 中。
Q. 如何表示 LZW 压缩的码表?
A. 使用一个单词查找树(Trie)结构来支持最长前缀匹配。
4.3:LZW 扩展
demo 演示:
![![image-20240405200135556]](https://img-blog.csdnimg.cn/direct/ac17aa09f5a143bbae4614f3fa65daf8.png)
![![image-20240405200147524]](https://img-blog.csdnimg.cn/direct/05438660bc234290a4931aa31954a618.png)
扩展:
![![L21-55DataCompression_38]](https://img-blog.csdnimg.cn/direct/c7dbcf9601584ae9a5efc05ef69ff412.png)
LZW 扩展:
- 创建一个符号表,用于关联 W 位宽的码键与对应的字符串值。
- 初始化 ST,填充所有可能的单字符解码结果。
- 读取一个 W 位码键。
- 在 ST 中查找与该码键关联的字符串值并输出。
- 更新ST。
Q. 如何表示 LZW 解压缩的码表?
A. 使用大小为 2W 的数组来表示。
4.4:特殊情况
![![image-20240405200955157]](https://img-blog.csdnimg.cn/direct/d1d13296f2414fffa2209c55fac274e3.png)
![![image-20240405201005888]](https://img-blog.csdnimg.cn/direct/9b63d84f98c24c8abd59e983bfcc921f.png)
4.5:Java 实现
edu.princeton.cs.algs4.LZW
![![image-20240405201101502]](https://img-blog.csdnimg.cn/direct/5a12b2caf474491781e6c8f290f5b720.png)
edu.princeton.cs.algs4.LZW#compress
![![image-20240405201120034]](https://img-blog.csdnimg.cn/direct/c782a6436b0548f9b7d5340f3dffd2e0.png)
edu.princeton.cs.algs4.LZW#expand
![![image-20240405201135239]](https://img-blog.csdnimg.cn/direct/bc71e3389b554c6bbbf066437fef0528.png)
4.6:小结
![![L21-55DataCompression_45]](https://img-blog.csdnimg.cn/direct/e642338b6066484cbdc830d532b00d4e.png)
无损压缩:
- 使用变长编码表示固定长度的符号。[霍夫曼编码]
- 使用固定长度的编码表示变长的符号。[LZW 编码]
有损压缩: [本课程未涵盖]
· JPEG、MPEG、MP3等。
· FFT(快速傅里叶变换)、小波分析、分形等技术。
压缩的理论极限: 香农信息熵。
压缩实践: 尽可能利用所有可利用的信息。
(完)