使用语言 MySQL
使用工具 Navicat Premium 16
代码能力快速提升小方法,看完代码自己敲一遍,十分有用
- 拖动表名到查询文件中就可以直接把名字拉进来
- 以下是使用脚本方法,也可以直接进行修改
- 中括号,就代表可写可不写
目录
1.数据查询
1.1 DQL语句
1.1.1 DQL语句语法
1.1.2 DQL语句示例
1.1.3 使用select需注意
1.2 常用函数
1.2.1 字符串函数
1.2.2 时间日期函数
1.2.3 使用时间日期函数中时间戳的好处
1.2.4 聚合函数
1.2.5 数学函数
1.3 分页查询
1.3.1 分页查询的语法
1.3.2 分页查询使用场景
1.3.3 分页查询示例
2.子查询基础
2.1 简单子查询
2.2 子查询语法
2.3 子查询作为from子句
2.3.1 示例
2.3.2 as关键字
1.数据查询
数据查询时数据库操作系统中使用的核心技能,是SQL语言的核心技能。因为Navicat工具中的数据查询结果显示效果更加清晰,所以这里将使用Navicat工具来查看执行结果。
1.1 DQL语句
1.1.1 DQL语句语法
数据查询语句(select语句)的语法格式如下:
- select *或<字段名列表> from <表名或视图> [where <查询条件>] [group by<分组的字段名>] [having<条件>] [order by <排序的字段名>[asc 或 desc]];
*或<字段名列表>表示要查询的字段。若查询表中的所有字段,则使用"*";查询指定字段使用字段名列表,其中字段列表至少包含一个字段名称,若查询多个字段,则字段间使用逗号分隔,最后一个字段后不加逗号。
from后的表名为要查询的数据的来源,可以单个或多个。
where子句为可选项,如果选择该选项,将限定查询的条件, 查询结果必须满足此查询条件(条件也可以添加并且(AND)还有或者(OR))。
- group by子句表明查询出来的数据按指定字段进行分组。
- having子句用于筛选组。
- order by子句指定按什么顺序显示查询出来的数据,需要指定排序字段。在默认条件下,MySQL按照升序(从上到下从小到大)排列,也可以通过代码指定升序(asc)或降序(desc)(从上到下从大到小)。
1.1.2 DQL语句示例

执行结果

1.1.3 使用select需注意
在select语句中使用select * from语句的执行效率会降低于把'*'号改为字段的效率,因为前者获得的表中所有字段值所占用的资源将大于后者获得的指定字段值所占用的资源。另外,后者的可维护性高于前者。因此,在编写查询语句时,建议采用以下语法格式:
- select 字段列表 from 表名 where 条件表达式;
使用as放在对应的字段或者表名后面时,可以为这个前面的字段添加别名;(注:ID列的别名不能出现'ID'两个字);
1.2 常用函数
在程序开发过程中,除了简单的数据查询,还有基于已有数据的统计分析计算等需求。因此,在SQL中将一些常用的数据处理操作封装起来,作为函数提供给程序员使用。这大大提高了程序员的开发效率。
1.2.1 字符串函数
在数据库开发过程中,经常需要对字符串进行各种处理,MySQL提供了丰富的字符串处理函数供程序员使用。MySQL的常用字符串处理函数如下所示:
| 函数名 | 函数说明 | 示例 |
|---|---|---|
| concat(str1,str2,...,strn) | 将字符串str1、str2、...strn连接为一个完整字符串 | select concat('MySQL',‘is powerful.’); 返回:MySQL is powerful. |
| lower(str) | 将字符串str中的所有字符变为小写 | select lower('MySQL'); 返回:mysql |
| upper(str) | 将字符串str中所有字符变为大写 | select upper('mysql'); 返回:MYSQL |
| substring(str,num,len) | 返回字符串str的第num个位置开始长度为len的子字符串 | select substring('MySQL is powerful.',10,8); 返回:pwerful |
| insert(str,pos,len,newstr) | 将字符串str从pos位置开始,将len个字符长的子串替换为字符串newstr(开始的位置0就代表在那个字母前面,1就代表在后面,字母从1开始算) | select insert('MySQL is powerful.',10,0,'very '); 返回:MySQL is very powerful. |
1.2.2 时间日期函数
在实际的业务中,经常会涉及时间日期的处理。MySQL的日期函数如下所示:
| 函数名 | 函数名 | 示例(部分结果与当前日期有关) |
|---|---|---|
| curdate() | 获取当前日期 | select curdate(); 返回:2024-04-09 |
| curtime() | 获取当前时间 | select curtime(); 返回:21:54:40 |
| now() | 获取当前时间 | select now(); 返回:2024-04-09 21:54:40 |
| week(date) | 返回参数date为一年中的第几周 | select week(now()); 返回:14 |
| year(date) | 返回参数date的年份 | select year(now()); 返回:2024 |
| hour(time) | 返回参数date的年份 | select hour(now()); 返回:21 |
| minute(time) | 返回参数time的分钟值 | select minute(now()); 返回:54 |
| datediff(date1,date2) | 返回参数date1和date2之间相隔的天数 | 返回:25 |
| adddate(date,n) | 计算参数date在n天后的日期 | select adddate(now(),1); 返回:2024-04-10 21:54:40 在原有的日期上,加n天; |
| unix_timestamp(date) | 将日期转换为时间戳 | select unix_timestamp('2024-04-10'); 返回:1712678400 企业一般都是使用时间戳来转换为日期; |
1.2.3 使用时间日期函数中时间戳的好处
- 自动更新功能:在定义表结构时,可以将时间戳列指定为自动更新。这意味着每当插入新行或更新现有行时,MySQL会自动将时间戳更新为当前时间,而无需手动编写更新语句。这简化了对数据变更时间的记录。
- 精确度和一致性:时间戳提供了非常高的精确度,通常精确到秒甚至更小的单位(如毫秒)。这确保了记录的时间信息是准确的,并且在不同的操作系统和MySQL服务器上保持一致。
- 方便的操作和查询:时间戳可以方便地与日期和时间函数一起使用,用于执行各种操作和查询。例如,你可以使用DATE_FORMAT函数将时间戳格式化为特定的日期时间格式,或者使用UNIX_TIMESTAMP函数将日期时间转换为UNIX时间戳。
- 排序和过滤:由于时间戳是可以排序和比较的数字类型,因此它们非常适合用于排序和过滤数据。你可以根据时间戳列对结果进行排序,也可以使用WHERE子句基于时间戳进行条件过滤。
- 数据分析和报告:使用时间戳记录数据的创建或修改时间可以帮助进行数据分析和生成报告。你可以根据时间戳进行数据聚合、时间序列分析,或者生成基于时间的报表和图表。
总的来说,MySQL中使用时间戳可以简化数据的时间记录和管理,提供高精度的时间信息,并支持各种操作、查询和分析需求。
1.2.4 聚合函数
聚合函数用来对已有数据进行汇总,常见的有求和、平均值、最大值和最小值等。(一定要会!!!)MySQL常用的聚合函数如下:
| count() | 返回某字段的行数; 搭配分组可以实现分组统计; |
| max() max() | 返回某字段的最大值 返回某字段的最小值  |
| sum() | 返回某字段的和 |
| avg() | 返回某字段的平均值 |
1.2.5 数学函数
在一些场景下,在开发过程中还需要进行数值运算。MySQL中常用的数学函数如下所示:
| ceil(x) floor(x) | 返回大于或等于数值x的最小整数(向上转整) 返回小于或等于数值x的最大整数(向下转整) |  第一个打印26,第二个打印25 |
| rand() | 返回0~1的随机数 | select rand(); 返回(这只是其中一种结果):0.15421445512123 |
1.3 分页查询
1.3.1 分页查询的语法
在MySQL中,指定查询结果返回条数的语法与SQL Server。MySQL没有top关键字,而是使用limit子句实现指定返回查询结果条数的目的。语法格式如下:
- select *或<字段名列表> from <表名或视图> [where <查询条件>] [group by<分组的字段名>] [having<条件>] [order by <排序的字段名>[asc 或 desc]] [limit [位置偏移量,]行数];
位置偏移量表示从结果集的第几条数据开始选取(记录的偏移位置从0开始计数,表示从第1条记录、第2条记录的偏移位置是1,以此类推)。位置偏移量参数为可选参数,省略时,从第1条数据开始选取。
行数指以偏移位置为起点,选取记录的条数。 (这个看不懂可以等会看下面代码的注释)
1.3.2 分页查询使用场景
- Web应用程序的分页显示:在网站或Web应用程序中,通常会有大量数据需要显示给用户,如商品列表、新闻文章、用户评论等。为了提高页面加载速度和用户体验,可以使用分页查询将数据分批加载到页面中。
- 数据报表和分析:在数据报表或分析系统中,可能需要按页显示大量数据,以便用户逐步查看和分析数据。分页查询可以帮助将数据切分成可管理的小块,方便用户逐页浏览。
- 数据导出和下载:当用户需要下载大量数据时,分页查询可以确保只有一部分数据被一次性加载到内存中,从而减少内存消耗和提高性能。用户可以按需下载分页数据,而不必等待所有数据加载完成。
- 数据搜索和过滤:在数据搜索和过滤功能中,分页查询可以帮助处理大量匹配的数据,并将结果分页显示给用户。这样用户可以浏览搜索结果的不同页面,以找到他们感兴趣的数据。
- 数据备份和恢复:在进行数据备份或恢复操作时,分页查询可以确保在处理大型数据集时不会消耗过多的系统资源。通过分页将数据分批处理,可以降低系统负载并提高备份/恢复的效率。
MySQL的分页查询适用于许多需要处理大量数据并且需要将数据分批显示或处理的场景,可以提高系统性能和用户体验。
1.3.3 分页查询示例
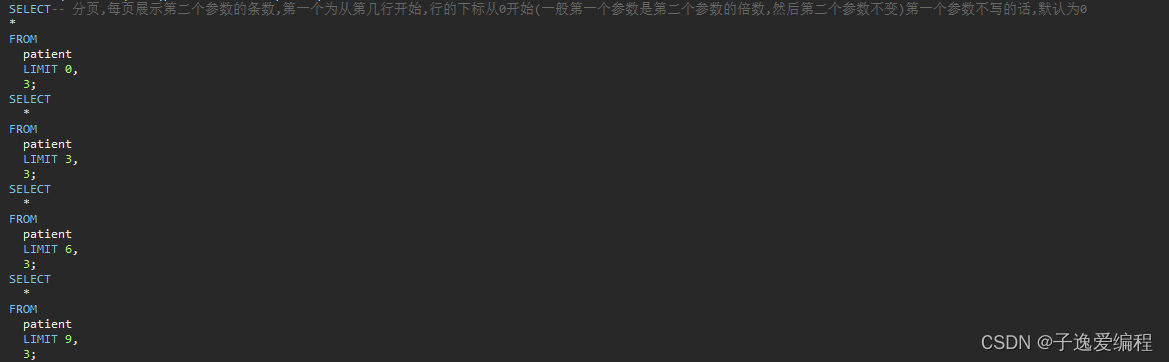 运行结果
运行结果
每个结果打印3条数据,数据没有到3条的话即只打印有的条数或者空;
2.子查询基础
2.1 简单子查询
示例;查询所有年龄比姚维新大的病人:
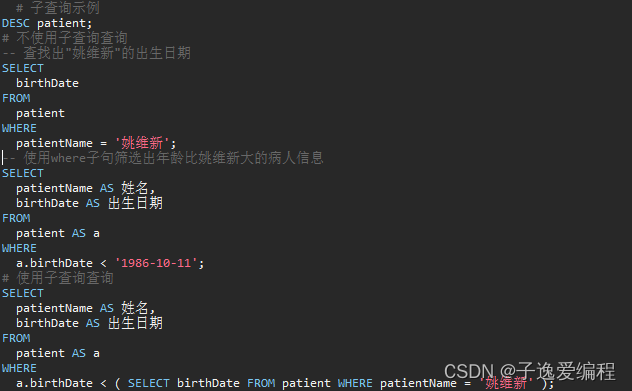
从升级后的代码可以看出两条查询语句被合并成了一条,即把查询语句嵌套至父查询语句中,成为where条件的一部分,即内层语句是外层语句的子查询。
2.2 子查询语法
子查询在where子句中的语法格式如下:
- select ....... from 表1 where 字段1 比较运算符 (子查询)
子查询语句必须放在括号中,括号外面的查询被称为父查询。
- 比较运算符包括>,>=,=,<,<=,子查询和比较运算符联合使用必须保证子查询的结果不能多于一个
- 先执行求出子查询的值,再执行父查询,返回最后的结果;
- 如果有多个结果(指查询出来多个列)就使用in(如果有包含在里面就true,没有就false),一个结果就用运算符即可
update、insert、delete中的where子句中也可以使用子查询,使用语法与select语句类似。
2.3 子查询作为from子句
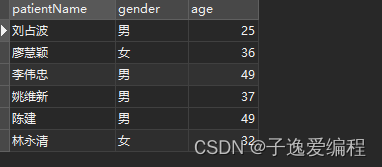
2.3.1 示例
![]() 这个图片太小了,可以在浏览器按住Ctrl键加鼠标滚轮加大页面来看;
这个图片太小了,可以在浏览器按住Ctrl键加鼠标滚轮加大页面来看;
这样就是把子查询中查出来的表作为源表,然后从其中获取数据;
运行结果
2.3.2 as关键字
子查询信息后如果想在from子句中,子查询结果需要起一个别名(Alias),否则执行时会出错。在SQL中,别名通常会使用在表名或字段上。以给表起别名为例,主要有以下两种方法:
使用as关键字,符合ANSI标准。语法格式如下:
- select 字段列表 from 表名 as 表的别名;
使用空格,这是较为简便的方法。语法格式如下:
- select 字段列表 from 表名 表的别名;
当为某张表命名了别名后,在select语句中出现该表的字段需要指定表名时,就必须统一使用该表的别名;否则将产生语法错误。