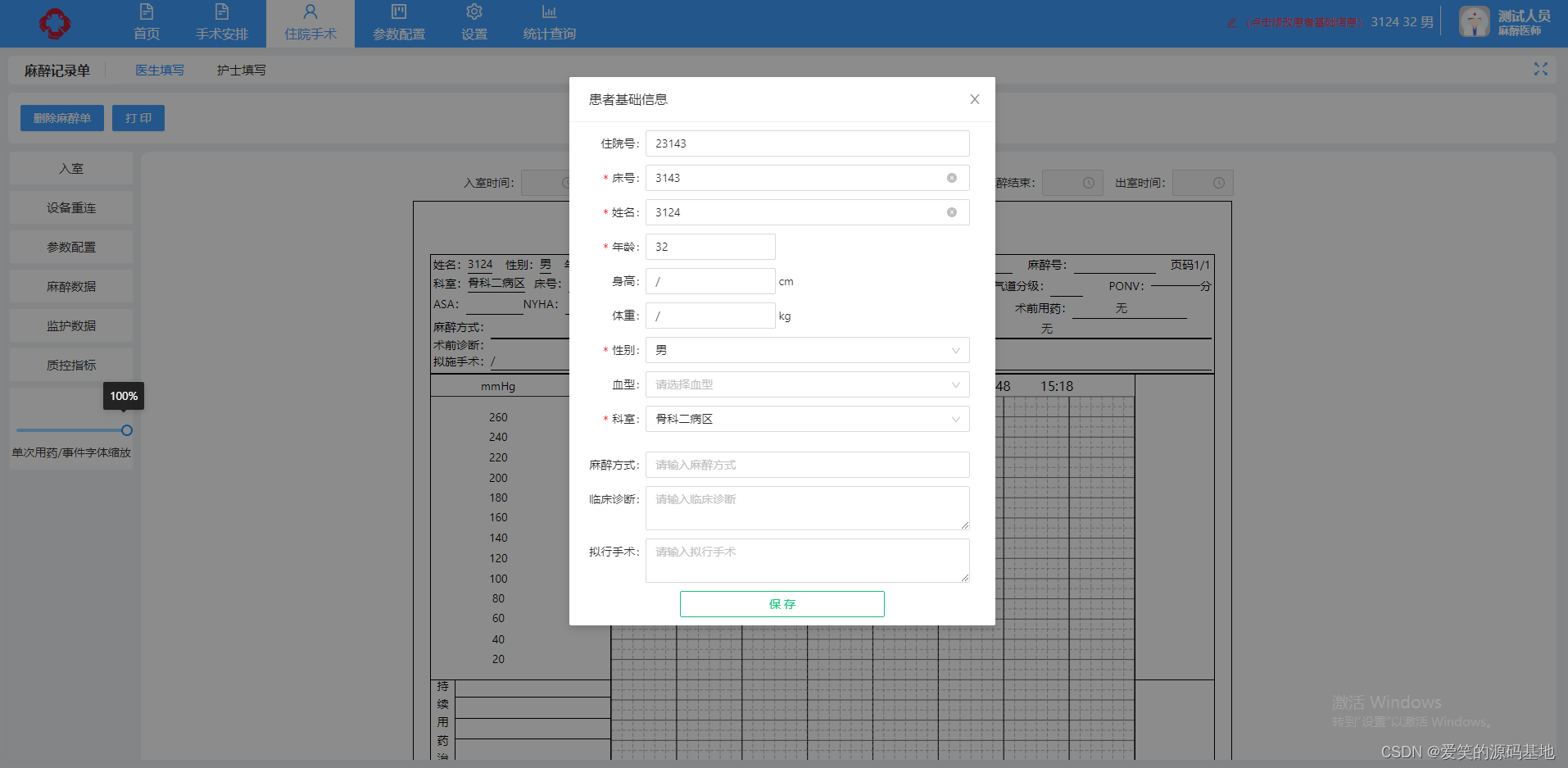
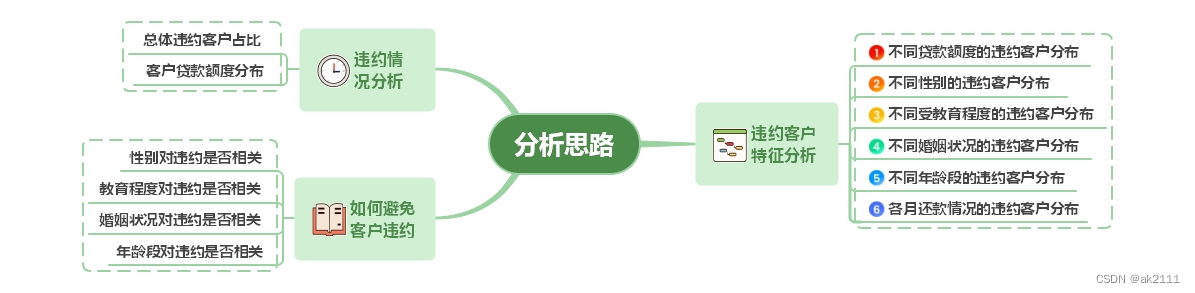
分析思路
信用卡服务提供了一种方便的贷款方式,允许用户事先消费,之后再支付费用。对银行而言,这种服务既有较高的利润潜力,同时也伴随着用户可能不履行还款义务的风险。本⽂是基于2005年台湾信⽤卡客户数据,探究信⽤卡客户有哪些信贷特征?违约客户有哪些特征?
数据说明
- BILL_AMT账单金额:表示使用信用卡的消费金额。
- PAY_AMT支付金额:给信用卡的还款金额。
- 如果账单金额 > 支付金额则表示该用户延迟还款了,产生了逾期。
数据加载
#导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#忽略警告
import warnings
warnings.filterwarnings('ignore')
#中文乱码的处理
#plt.rcParams['font.sans-serif']=['PingFang HK'] #mac系统使用
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']# windows使用设置微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常的显示负号
#加载数据UCI_Credit_Card.csv
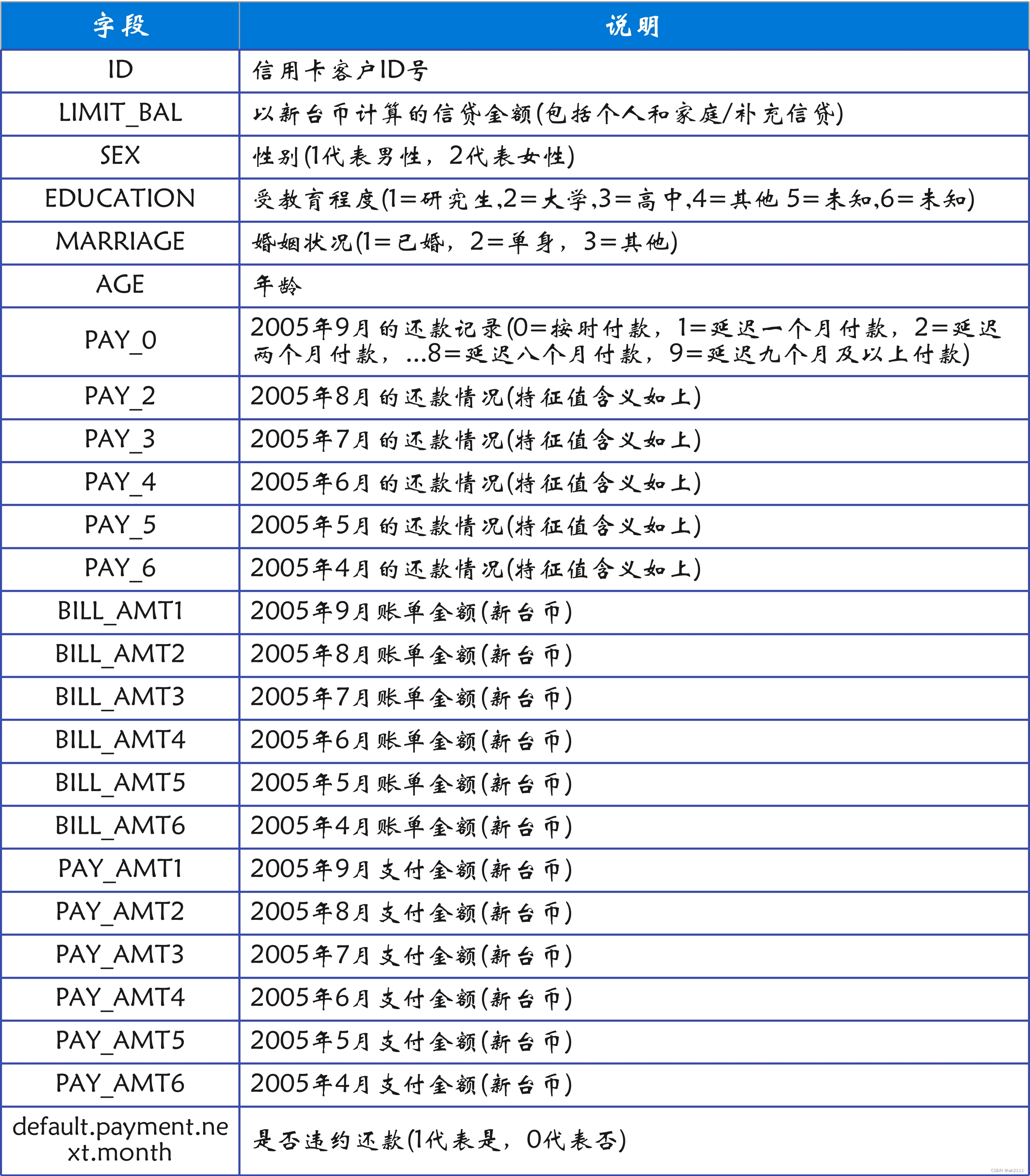
data = pd.read_csv('UCI_Credit_Card.csv')
data.head()
data.shape
(30000, 25)
数据预处理
- 选择子集
- BILL_AMT1 ~ BILL_AMT6为各⽉账单⾦额(即每⽉消费记录)、PAY_AMT1 ~ PAY_AMT6为各⽉⽀付⾦额⽀付,⽀付⾦额>上个⽉消费记录,则视为该⽉及时还款,反之则视为延迟还款
- 直接根据pay_0 ~ pay_6去计算/表示客户在4⽉-9⽉正常还款或者违约情况,所以【BILL_AMT1 ~ BILL_AMT6】和【PAY_AMT1 ~ PAY_AMT6】这些字段可视为⽆⽤信息,删除即可。
#批量生成要删除列的名字
list_pay = []
list_bill = []
for i in range(1,7):
s = 'PAY_AMT'+str(i)
list_pay.append(s)
for i in range(1,7):
s = 'BILL_AMT'+str(i)
list_bill.append(s)
list_pay.extend(list_bill)
data.drop(columns=['PAY_AMT1','PAY_AMT2','PAY_AMT3','PAY_AMT4','PAY_AMT5','PAY_AMT6',
'BILL_AMT1','BILL_AMT2','BILL_AMT3','BILL_AMT4','BILL_AMT5','BILL_AMT6'],
inplace=True)
#将default.payment.next.month的名字修改为is_pay
data.rename(columns={'default.payment.next.month':'is_pay'},inplace=True)
- 查看是否存在重复的行数据
data.duplicated().sum()
0
- 查看是否存在缺失值
data.isnull().any(axis=0)
- 异常值检测
#将EDUCATION的0,4,5都替换成6,6就表示其他这种学历
data['EDUCATION'].replace(to_replace={0:6,4:6,5:6},inplace=True)
data['MARRIAGE'].replace(to_replace={0:3},inplace=True)
数据分析
总体违约情况分析
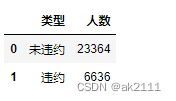
- 求违约客户的占比
df1 = data['is_pay'].value_counts().reset_index().rename(columns={'index':'类型','is_pay':'人数'})
df1

df1['类型'] = df1['类型'].map({0:'未违约',1:'违约'})
df1
#求解整体的违约率
def func(x):
return format(x/df1['人数'].sum(),'.2%')
df1['占比'] = df1['人数'].map(func)
df1
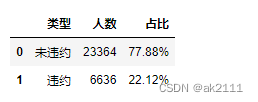
整体持卡用户的违约率高达22.12%
违约客户的特征分析
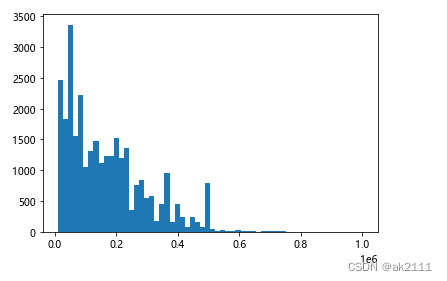
- 不同贷款额度分布
x = plt.hist(data['LIMIT_BAL'],bins=60)
data['LIMIT_BAL'].describe([.1,.2,.3,.4,.5,.6,.7,.8,.9])
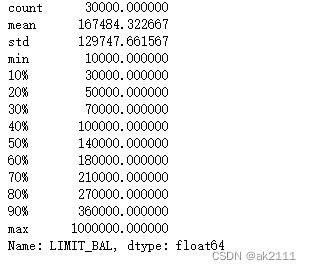
有70%的客户贷款额度大约在20万以内,有80%的客户贷款额度在30万以内,客户贷款额度还是以中低额度为主。
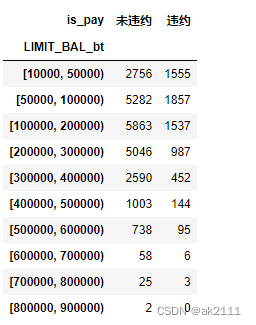
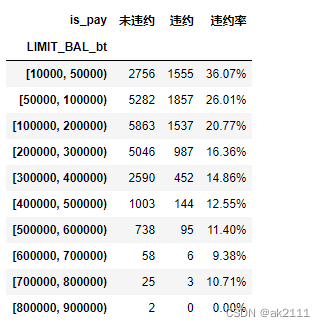
- 不同贷款额度的违约客户分布
bal_s = pd.cut(data['LIMIT_BAL'],bins=[10000,50000,100000,200000,300000,400000,
500000,600000,700000,800000,900000,1000000],right=False)
data['LIMIT_BAL_bt'] = bal_s
#不同借款区间对应的违约和未违约用户的数量
is_pay_df = pd.crosstab(data['is_pay'],data['LIMIT_BAL_bt']).T.rename(columns={0:'未违约',1:'违约'})
is_pay_df
#计算不同借款区间对应的违约率
def func(x):
return format(x['违约'] / x.sum(),'.2%')
is_pay_df['违约率'] = is_pay_df.apply(func,axis=1)
is_pay_df
plt.figure(figsize=(12,6))
plt.plot(is_pay_df.index.astype('str'),is_pay_df['未违约'],label='未违约')
plt.plot(is_pay_df.index.astype('str'),is_pay_df['违约'],label='违约')
plt.xlabel('借款区间')
plt.ylabel('人数')
plt.legend()
x = plt.xticks(rotation=30)
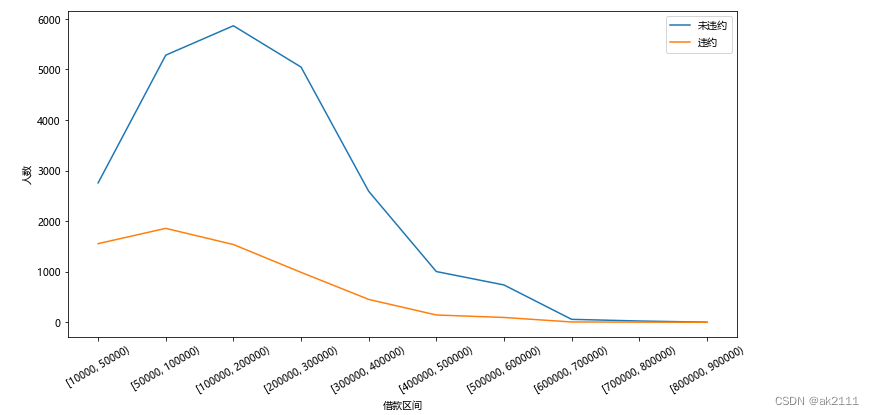
可以看出,贷款额度越⾼,违约率逐渐降低,违约率较⾼的贷款额度主要集中在20万以内,所以对低于20万的贷款,⼀定要加强审核度,防⽌违约。
- 不同性别的违约情况
is_pay_sex = pd.crosstab(data['SEX'],data['is_pay']).rename(columns={0:'未违约',1:'违约'},index={1:'男',2:'女'})
is_pay_sex['总计'] = is_pay_sex['未违约'] + is_pay_sex['违约']
def func(x):
return format(x['违约']/x['总计'],'.2%')
is_pay_sex['违约率'] = is_pay_sex.apply(func,axis=1)
is_pay_sex
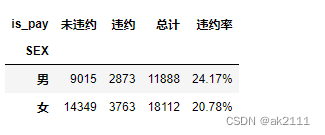
⼥性贷款的⼈数会远⾼于男性,但男性的违约率更⾼
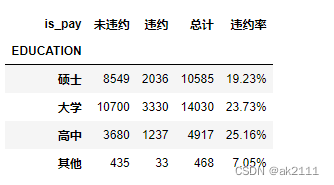
- 不同受教育程度的违约情况
is_pay_edu = pd.crosstab(data['EDUCATION'],data['is_pay']).rename(columns={0:'未违约',1:'违约'},index={1:'硕士',2:'大学',3:'高中',6:'其他'})
is_pay_edu['总计'] = is_pay_edu['未违约'] + is_pay_edu['违约']
def func(x):
return format(x['违约']/x['总计'],'.2%')
is_pay_edu['违约率'] = is_pay_edu.apply(func,axis=1)
is_pay_edu
- 不同婚姻状况的违约率
is_pay_mar = pd.crosstab(data['MARRIAGE'],data['is_pay']).rename(columns={0:'未违约',1:'违约'},index={1:'已婚',2:'单身',3:'其他'})
is_pay_mar['总计'] = is_pay_mar['未违约'] + is_pay_mar['违约']
def func(x):
return format(x['违约']/x['总计'],'.2%')
is_pay_mar['违约率'] = is_pay_mar.apply(func,axis=1)
is_pay_mar
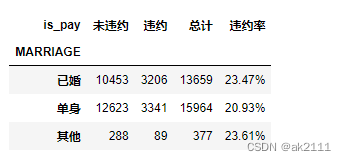
已婚的违约率略⾼于未婚的违约率,但是差异性并不是很⼤,相对来说都偏⾼
- 不同年龄段的违约率
age_s = pd.cut(data['AGE'],bins=[21,30,40,50,60,70,80],right=False)
age_s

is_pay_age = pd.crosstab(age_s,data['is_pay']).rename(columns={0:'未违约',1:'违约'})
is_pay_age
is_pay_age[‘总计’] = is_pay_age[‘未违约’] + is_pay_age[‘违约’]
def func(x):
return format(x[‘违约’]/x[‘总计’],‘.2%’)
is_pay_age[‘违约率’] = is_pay_age.apply(func,axis=1)
is_pay_age
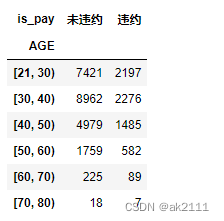
各个年龄段的违约率随着年龄的增⻓,有上升趋势,60岁以上的违约率最⾼;21-30和30-40的贷款⼈数
最多,说明贷款⼈员偏年轻。
- 各⽉还款情况的违约客户分析
pay_df = data[['PAY_0','PAY_2','PAY_3','PAY_4','PAY_5','PAY_6']]
pay_df
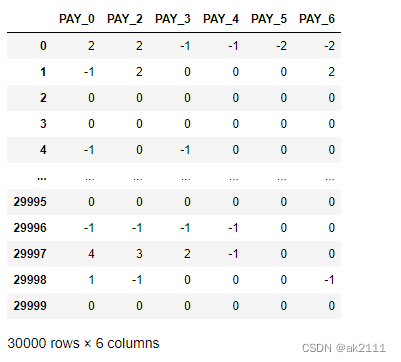
#计算不同月份逾期还款的用户数
def func(x):
return (x > 0).sum()
month_df = pay_df.apply(func,axis=0).rename(index={'PAY_0':'九月','PAY_2':'八月','PAY_3':'七月','PAY_4':'六月','PAY_5':'五月','PAY_6':'四月'}).reset_index().rename(columns={'index':'月份',0:'逾期用户数'})
month_df
#计算每个月的逾期率:逾期用户数 / 总用户数
def func(x):
return format(x,‘.2%’)
month_df[‘逾期率’] = (month_df[‘逾期用户数’]/data[‘ID’].count()).map(func)
month_df
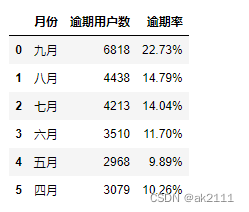
从数据来看,逾期还款的⽤户数从4⽉到9⽉,呈现递增的趋势,说明当时的违约情况越演愈烈。
如何避免客户违约
#相关性分析:探究两组数据之间是否存在相关关系
#相关关系: 正相关 负相关
#如何表示相关性:相关系数(皮尔森系数)
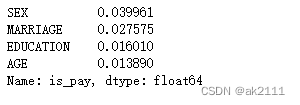
df = data[['SEX','EDUCATION','MARRIAGE','AGE','is_pay']]
df
df.corr().abs()['is_pay'][:-1].sort_values(ascending=False)
分析结论
- 1.总体违约率⾼达22.12%,当时违约情况⾮常严重,05年4⽉-9⽉还款逾期率逐渐上升,违约情况愈演愈烈。
- 2.贷款额度越⾼,违约率越低,违约率较⾼的贷款额度主要集中在20万以内,所以对于低于20万的贷款,⼀定要加强审核度,降低违约⻛险。
- 3.教育⽔平在⾼中的违约率较⾼,随着教育⽔平的提⾼,违约率呈下降趋势,⼀定程度说明教育⽔平越⾼,违约率越低,建议教育⽔平可作为信⽤卡审核的标准之⼀。
- 4.各个年龄段的违约率随着年龄的增⻓,有上升趋势,60岁以上的违约率最⾼;建议对于年龄⾼于60岁以上的⼈员办理信⽤卡增加审核强度,降低申请贷款额度。
- 5.⼥性贷款的⼈数会远⾼于男性,但男性的违约率更⾼。
- 6.已婚的违约率略⾼于未婚的违约率,但是差异性并不是很⼤,相对来说都偏⾼。