前言
- kafka生产者负责将数据发布到kafka集群的主题;
- kafka生产者消息发送方式有两种:
- 同步发送
- 异步+回调发送
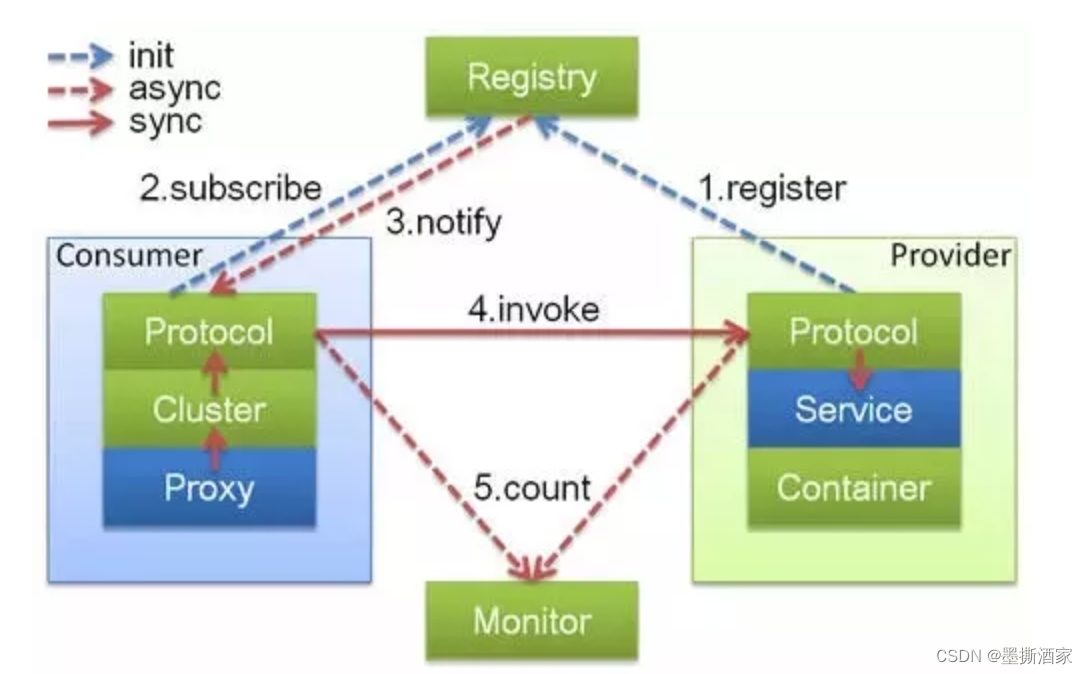
流程
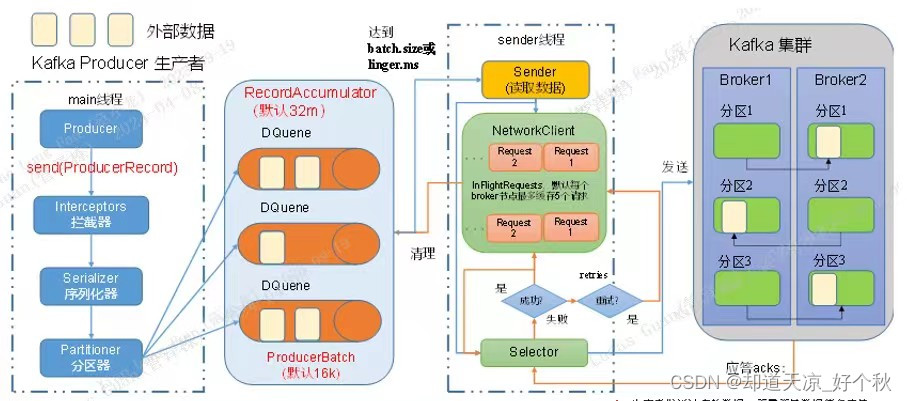
流程说明:
- Kafka Producer整体可看作是一个异步处理操作;
- 消息发送过程中涉及两个线程:main线程和sender线程;
- main线程负责将消息发送至一个双端队列,sender线程负责从双端队列取消息并发送至kafka broker;
消息可靠性
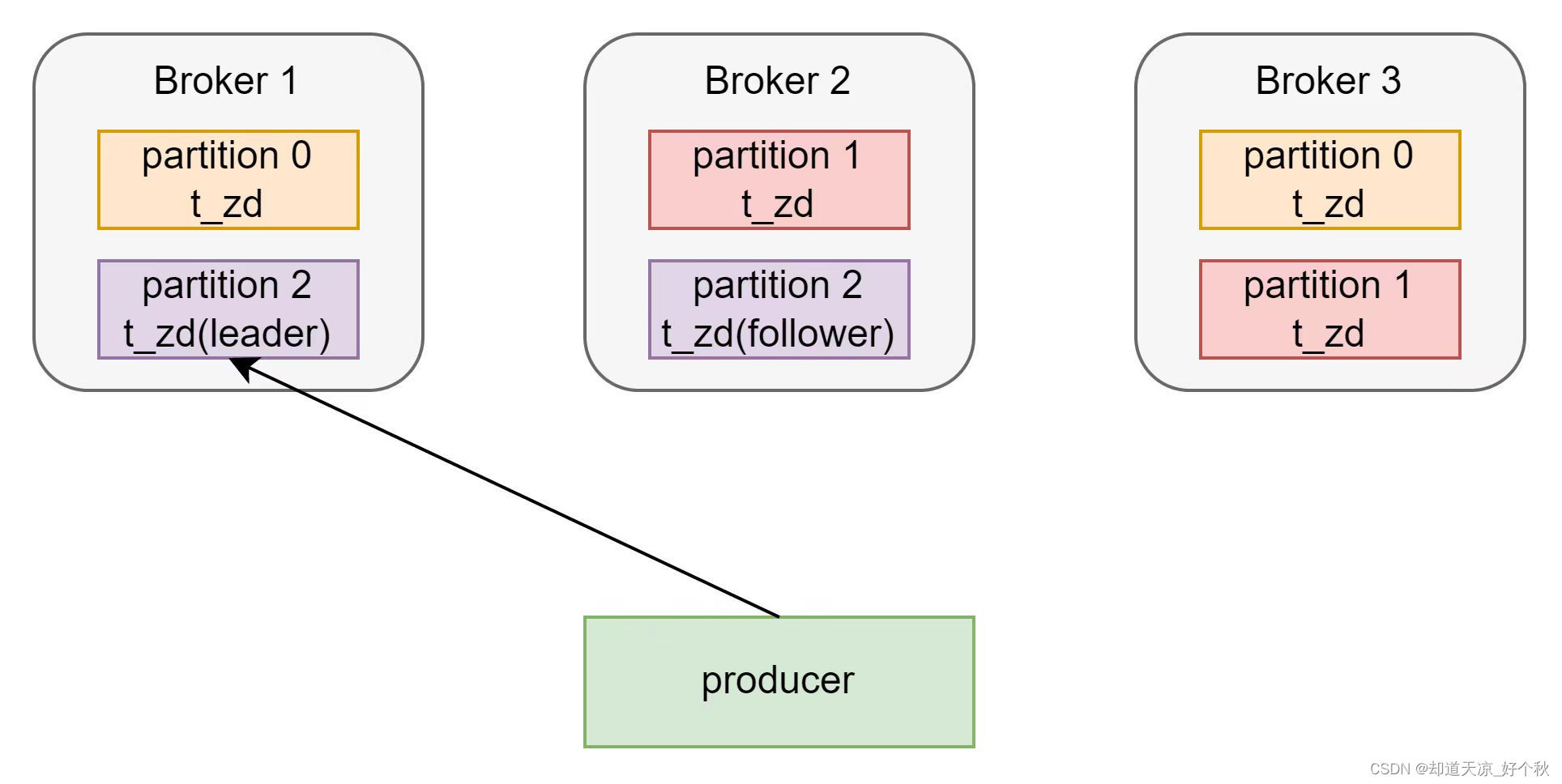
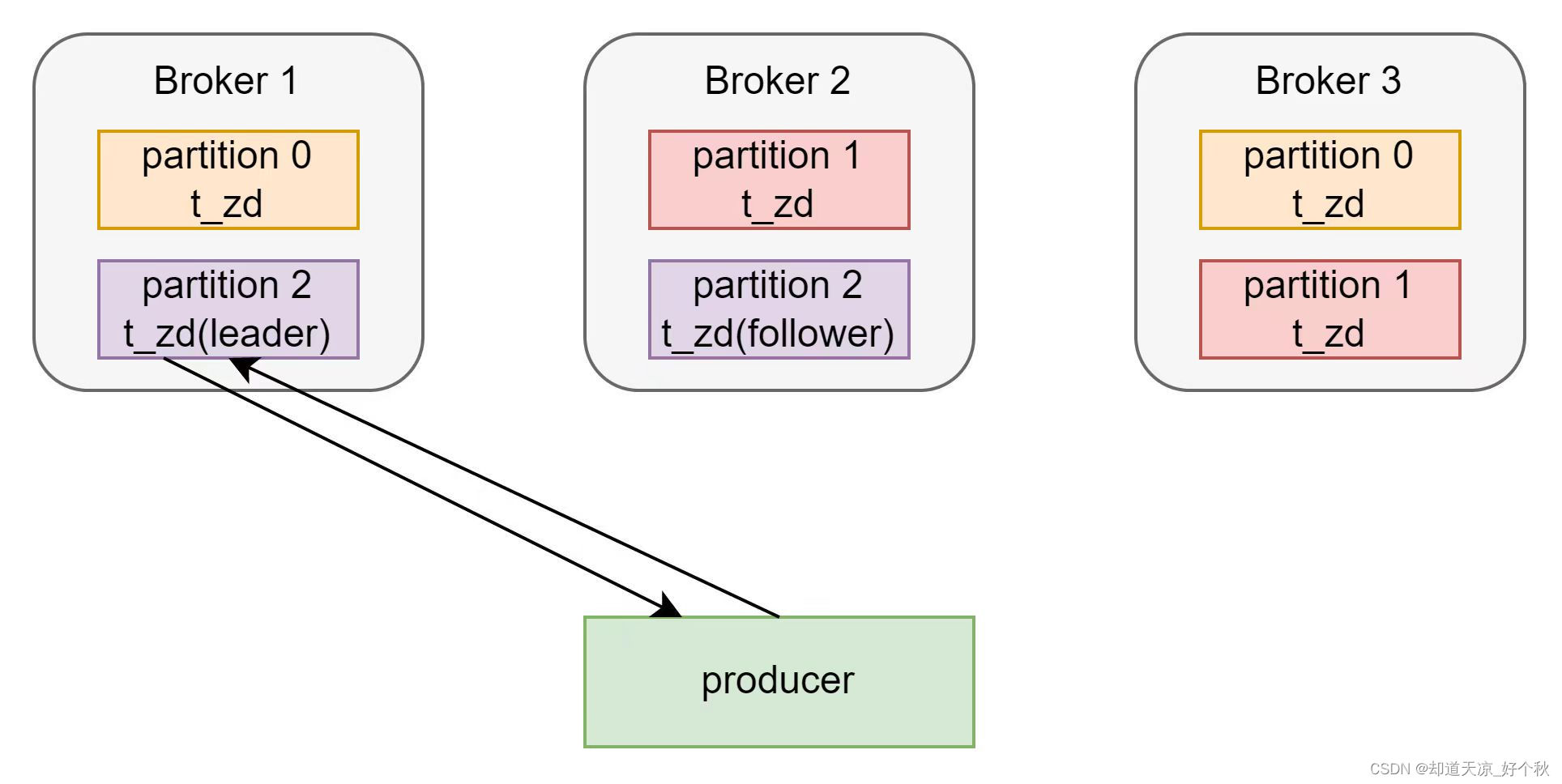
producer的acks参数表示生产者生产消息时,写入到副本的严格程度。决定了生产者的性能与可靠性。
- 0:生产者发送过来的数据,不等待broker确认,直接发送下一条数据,性能最高,但可能存在丢数据;
-
1:生产者发送过来的数据,等待Leader副本确认后发送下一条数据,性能中等;
-
-1(all):生产者发送过来的数据,等待所有副本将数据同步后发送下一条数据,性能最慢,安全性最高;

消息有序性
消息保序策略:按key分区,可以实现局部有序,但这又可能会导致数据倾斜,可根据实际情况选择。
示例:
// 指定消息key,即倒数第二个参数,当有相同的两条消息先后存储同一个key,消费者可按顺序消费到
RdKafka::ErrorCode errorCode = m_producer->produce(
m_topic, // 指定发送到的主题
RdKafka::Topic::PARTITION_UA, // 指定分区,如果为PARTITION_UA则通过
// partitioner_cb的回调选择合适的分区
RdKafka::Producer::RK_MSG_COPY, // 消息拷贝
payload, // 消息本身
len, // 消息长度
&key, // 消息key
NULL
);
Main线程与Sender线程
Main线程
流程
- 创建消息
// librdkafka源码 rdkafka_msg.c
/* Create message */
rkm = rd_kafka_msg_new0(rkt, force_partition, msgflags, payload, len,
key, keylen, msg_opaque, &err, &errnox, NULL, 0,
rd_clock());
if (unlikely(!rkm)) {
/* errno is already set by msg_new() */
rd_kafka_set_last_error(err, errnox);
return -1;
}
- 选择分区
/* Partition the message */
err = rd_kafka_msg_partitioner(rkt, rkm, 1);
if (likely(!err)) {
rd_kafka_set_last_error(0, 0);
return 0;
}
- 调用拦截器
/* Interceptor: unroll failing messages by triggering on_ack.. */
rkm->rkm_err = err;
rd_kafka_interceptors_on_acknowledgement(rkt->rkt_rk,
&rkm->rkm_rkmessage);
Sender线程
参数说明
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
|---|---|
| linger.ms | 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。生产环境建议该值大小为5-100ms之间。 |
| acks | 见“消息可靠性”章节 |
| max.in.flight.requests.per.connection | 允许最多没有返回ack的次数,默认为5,开启幂等性要保证该值是 1-5的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是int最大值,2147483647。 如果设置了重试,还想保证消息的有序性,需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是100ms。 |
| enable.idempotence | 是否开启幂等性,默认true,开启幂等性。 |
流程
- 达到batch.size大小或满足linger.ms时间发送消息;
- 消息发送至的kafka服务器后,如果kafka没有应答,默认每个broker节点队列最多缓存 5 个请求,与“max.in.flight.requests.per.connection”参数有关;
- 如配置了“retries”、“ retry.backoff.ms”参数,消息发送失败由kafka内部自动重试,无需手动在回调函数中重试;
同步和异步流程
同步流程
流程说明
- 通过produce方法将消息推送至双端队列;
- 通过flush方法等待发送结果,如outq_len()大于0,说明存在未发送成功的消息;
代码示例
int KafkaProducer::PushMessage(const std::string &str, const std::string &key)
{
int32_t len = (int32_t)str.length();
void *payload = const_cast<void *>(static_cast<const void *>(str.data()));
// produce 方法,生产和发送单条消息到 Broker
// 如果不加时间戳,内部会自动加上当前的时间戳
RdKafka::ErrorCode errorCode = m_producer->produce(
m_topic, // 指定发送到的主题
RdKafka::Topic::PARTITION_UA, // 指定分区,如果为PARTITION_UA则通过
// partitioner_cb的回调选择合适的分区
RdKafka::Producer::RK_MSG_COPY, // 消息拷贝
payload, // 消息本身
len, // 消息长度
&key, // 消息key
NULL
);
if (RdKafka::ERR_NO_ERROR != errorCode)
{
// kafka 队列满,等待 100 ms
if (RdKafka::ERR__QUEUE_FULL == errorCode)
{
m_producer->poll(100);
}
return -1;
}
// 同步等待200ms
m_producer->flush(200);
if(m_producer->outq_len() > 0) // 用于调试
{
printf("Existed not send message.size:%d\n", m_producer->outq_len());
return -1;
}
return 0;
}
异步流程
流程说明
- 设置生产者投递报告回调
- 设置生产者自定义分区策略回调
- 消息发送
代码示例
- 设置生产者投递回调
// 生产者投递报告回调
class ProducerDeliveryReportCb : public RdKafka::DeliveryReportCb
{
public:
void dr_cb(RdKafka::Message& message)
{
if (message.err()) // 出错回调
{
// TODO
}
else // 正常回调
{
// TODO
}
}
};
// 设置生产者投递报告回调
m_dr_cb = new ProducerDeliveryReportCb; // 创建投递报告回调
errCode = m_config->set("dr_cb", m_dr_cb, errorStr); // 异步方式发送数据
if (RdKafka::Conf::CONF_OK != errCode)
{
printf("Conf set(dr_cb) failed, errorStr:%s", errorStr.c_str());
break;
}
- 设置生产者自定义分区策略回调
// 生产者自定义分区策略回调:partitioner_cb
class HashPartitionerCb : public RdKafka::PartitionerCb
{
public:
// @brief 返回 topic 中使用 key 的分区,msg_opaque 置 NULL
// @return 返回分区,(0, partition_cnt)
int32_t partitioner_cb(const RdKafka::Topic *topic, const std::string *key,
int32_t partition_cnt, void *msg_opaque)
{
// 用于自定义分区策略:这里用 hash。例:轮询方式:p_id++ % partition_cnt
int32_t partition_id = generate_hash(key->c_str(), key->size()) % partition_cnt;
return partition_id;
}
private:
// 自定义哈希函数
static inline unsigned int generate_hash(const char *str, size_t len)
{
unsigned int hash = 5381;
for (size_t i = 0; i < len; i++)
hash = ((hash << 5) + hash) + str[i];
return hash;
}
};
// 设置生产者自定义分区策略回调
m_partitioner_cb = new HashPartitionerCb; // 创建自定义分区投递回调
errCode = m_topicConfig->set("partitioner_cb", m_partitioner_cb, errorStr);
if (RdKafka::Conf::CONF_OK != errCode)
{
printf("Conf set(partitioner_cb) failed, errorStr:%s", errorStr.c_str());
break;
}
- 消息发送
注意:此处produce执行成功不代表消息发送成功,需根据dr_cb消息回调结果判断消息是否发送成功。
int KafkaProducer::PushMessage(const std::string &str, const std::string &key)
{
int32_t len = (int32_t)str.length();
void *payload = const_cast<void *>(static_cast<const void *>(str.data()));
// produce 方法,生产和发送单条消息到 Broker
// 如果不加时间戳,内部会自动加上当前的时间戳
RdKafka::ErrorCode errorCode = m_producer->produce(
m_topic, // 指定发送到的主题
RdKafka::Topic::PARTITION_UA, // 指定分区,如果为PARTITION_UA则通过
// partitioner_cb的回调选择合适的分区
RdKafka::Producer::RK_MSG_COPY, // 消息拷贝
payload, // 消息本身
len, // 消息长度
&key, // 消息key
NULL
);
// 轮询处理
m_producer->poll(0);
if (RdKafka::ERR_NO_ERROR != errorCode)
{
// kafka 队列满,等待 100 ms
if (RdKafka::ERR__QUEUE_FULL == errorCode)
{
m_producer->poll(100);
}
return -1;
}
return 0;
}