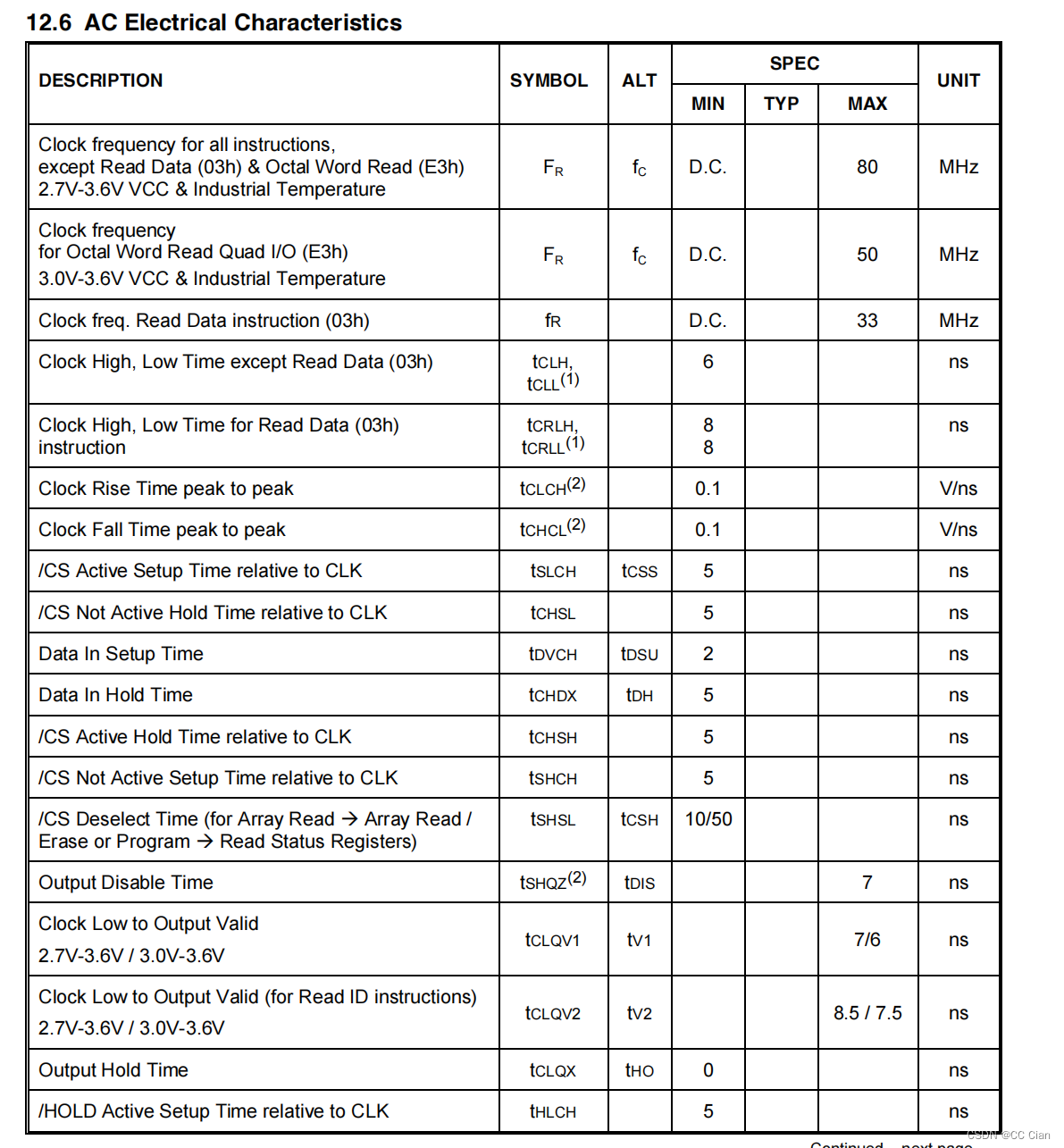
题目描述:
给定 a,b,求 1≤x<a^b 中有多少个 x 与 a^b 互质。
由于答案可能很大,你只需要输出答案对 998244353 取模的结果。
输入格式:
输入一行包含两个整数分别表示 a,b,用一个空格分隔。
输出格式:
输出一行包含一个整数表示答案。
数据范围:
对于 30% 的评测用例,ab≤1e6;
对于 70% 的评测用例,a≤1e6,b≤1e9;
对于所有评测用例,1≤a≤1e9,1≤b≤1e18。
输入样例1:
2 5
输出样例1:
16
输入样例2:
12 7
输出样例2:
11943936分析步骤:
第一:我们看到这个题目,要求有多少个数互质。首先,就应该想到我们肯定是要用欧拉函数的解题目的;其次,我们看到有a的b次方这种指数运算的话,就应该想到要运用快速幂的算法,特别是像这种题目数据量这么大的情况,一定一定是要用快速幂的。所以此题目分析到这里我们已经把题目的两大特点分析出来了:1.快速幂;2.欧拉函数。
第二:回顾欧拉函数:
-
我们先简单回顾一下什么是欧拉函数。
-
欧拉函数的定义:1~n中与n互质的数的个数成为欧拉函数
-
欧拉函数的性质:
-
如果p是质数的话,则与p互质的个数有:p-1个
-
如果p是质数的话,则与p^k互质的个数有:(p-1)*p^(k-1)
-
积性函数:若gcd(m,n) = 1也就是最大公约数为1时,则与(m*n)互质的个数有:与m的互质的个数乘上与n的互质的个数,就是(m*n)的答案。
-
欧拉函数的计算公式:

第三:书写主函数,构建整体框架:
-
我们这道题目数据量巨大,所以我们最好定义a,b为long long类型
-
如果底数 a == 1 的话那么无论b是多少答案都必定是0,这是一种剪枝的操作。
-
进入我们欧拉函数的while循环
-
我们运用试除法求因数,判断如果 x % i == 0 的话就代表 i 是 x 的因数,那么我们就把这个值给除干净;那么我们在让res乘上他的贡献。
-
while退出之后,在判断一下x是不是1,如果不是1的话就代表这个数也是一个因数,再让res乘上这个数的贡献。
-
最后我们只需要把res的乘上快速幂的值那么我们的答案就出来了。
int main()
{
LL a, b;
cin >> a >> b;
if (a == 1)
{
cout << 0 << endl;
return 0;
}
LL res = a, x = a;
for (int i = 2; i * i <= x; i ++ )
if (x % i == 0)
{
while (x % i == 0) x /= i;
res = res / i * (i - 1);
}
if (x > 1) res = res / x * (x - 1);
cout << res * qmi(a, b - 1) % MOD << endl;
return 0;
}第四:书写快速幂函数:

LL qmi(LL a, LL b)
{
LL res = 1;
while (b)
{
if (b & 1) res = res * a % MOD;
a = a * a % MOD;
b >>= 1;
}
return res;
}
----------
第五:线性筛欧拉函数:
-
我们线性筛欧拉函数,可以在O(logn)的时间复杂度之内完成筛法,大大降低了时间复杂度,比试除法更快更好
-
线性筛欧拉函数也是借用线性筛模板,大同小异。
-
首先我们定义st数组来判断我们这个数是不是质数,定义primes数组储存质数,定义mem数组储存我们之前算出的每一个数的答案。相当于记忆化搜索。
-
将mem[1]初始化为1,因为1的质数只有1个。
-
进入for循环,如果这个数状态没有被改过那么就证明这个数是质数,我们就把这个数放入质数数组,并且因为这个数是质数,那么这个数从1~i的与其互质的数为i-1。
-

-
再进入一个for循环,我们要保证每一个合数一定是被他最小的质因子给筛去(这是线性筛的精髓)所以我们将i乘primes[j]赋给m,更改m的状态。因为m一定是两个数的乘积之和,那么他一定是合数所以要改变状态。
-
再判断这个质因子是不是i的因子。如果是的话则代表了,i包含了m的所有质因子.例如:(12) = (2 * 6),因为2是质数,那么他就可以直接乘,6我们在之前的记忆化计算之中已经算出来了。所以可以写成 mem[m] = primes[j] * mem[i];
-
如果不是的话,则代表i不能被primes[j]整除,则i与primes[j]互质,因为primes[j]一定是质数,所以他的互质数就等于primes[j] - 1,这是欧拉函数的性质,i的互质数就在我们之前记忆化搜索之中也计算出来了。将两个数相乘就可以得出答案。mem[m] = (primes[j]-1) * mem[i];
bool st[N];
int primes[N];
int mem[N];
void get_prime(int n ){
mem[1] = 1;
for(int i = 2 ; i <= n ; i ++){
if(!st[i]) {
primes[cnt++] = i;
mem[i] = i-1;
}
for(int j = 0 ; i * primes[j] <= n ; j++){
int m = i * primes[j];
st[m] = true;
if(i % primes[j] == 0) {
mem[m] = primes[j] * mem[i];
break;
}else{
mem[m] = (primes[j]-1) * mem[i];
}
}
}
}----------
大家可以好好看看如何用线性筛求解欧拉函数!!!这很重要,线性筛可以节约很多时间。
代码:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
const int MOD = 998244353;
LL qmi(LL a, LL b)
{
LL res = 1;
while (b)
{
if (b & 1) res = res * a % MOD;
a = a * a % MOD;
b >>= 1;
}
return res;
}
int main()
{
LL a, b;
cin >> a >> b;
if (a == 1)
{
cout << 0 << endl;
return 0;
}
LL res = a, x = a;
for (int i = 2; i * i <= x; i ++ )
if (x % i == 0)
{
while (x % i == 0) x /= i;
res = res / i * (i - 1);
}
if (x > 1) res = res / x * (x - 1);
cout << res * qmi(a, b - 1) % MOD << endl;
return 0;
}