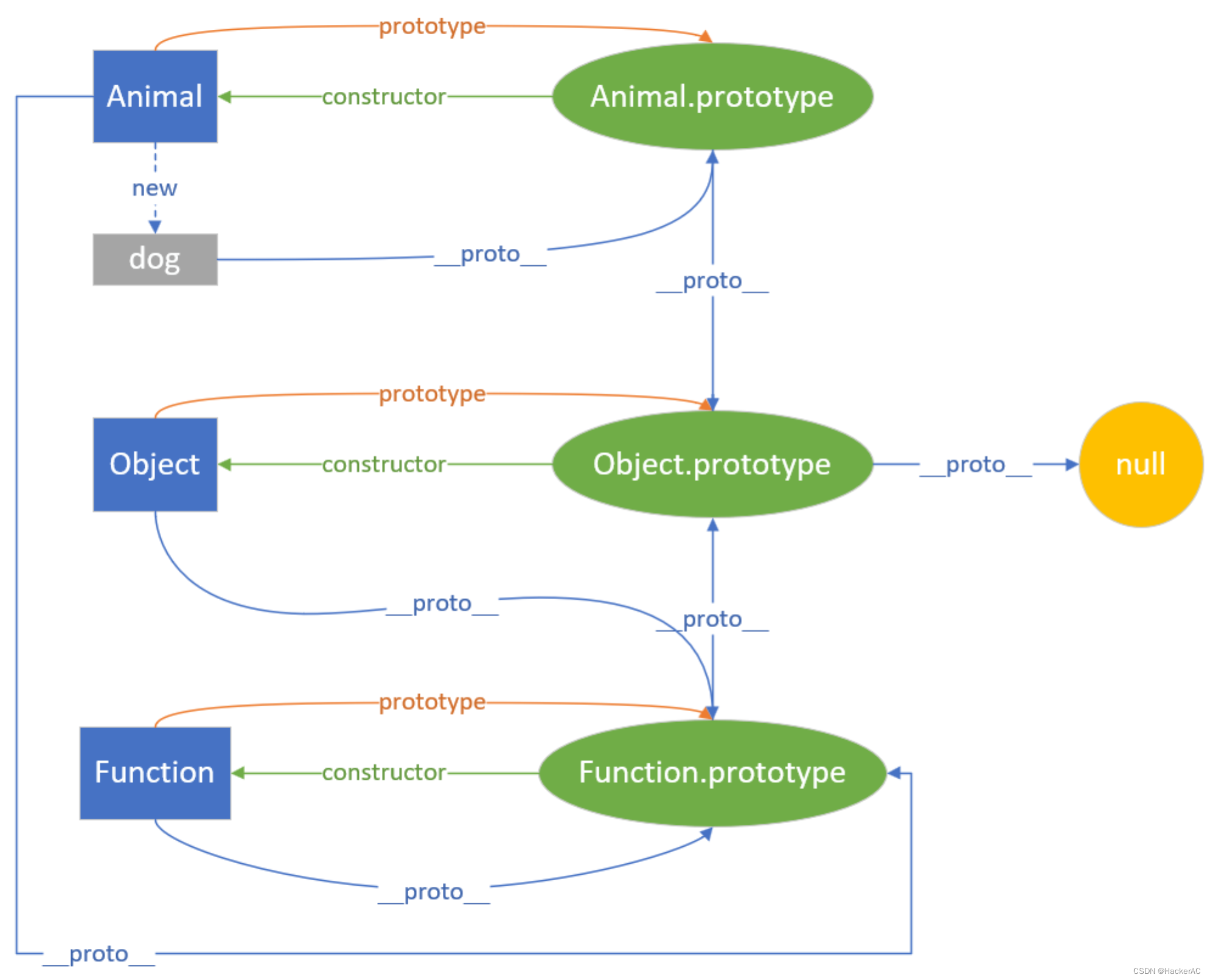
作者:Matt Riley
搜索驱动的人工智能和开发人员工具专为速度和规模而打造。

在大型语言模型(LLM)和生成式 AI 的每日突破中,开发者站在了这场运动的最前沿,影响着它的方向和可能性。在这篇博客中,我将分享 Elastic 的搜索客户是如何利用 Elastic 的向量数据库和开放平台,为搜索驱动的 AI 和开发者工具加速和扩展生成式 AI 体验,为他们提供了新的增长途径。
Dimensional Research 进行的最近一次开发者调查并得到 Elastic 支持的结果显示,87% 的开发者已经有了生成式 AI 的用例 —— 无论是数据分析、客户支持、工作场所搜索还是聊天机器人。但只有 11% 已经成功地将这些用例部署到生产环境中。
有几个因素阻碍了他们:
- 模型部署和管理:选择正确的模型需要实验和快速迭代。为生成式 AI 应用部署 LLM 是耗时且复杂的,对许多组织来说学习曲线陡峭。
- 法律和合规问题:当处理敏感数据时,这些问题尤其重要,可以成为模型采用的障碍。
- 扩展性:领域特定数据对于 LLM 理解上下文和生成准确输出至关重要。随着数据的扩展,检索这些数据需要同样可扩展的支持,以应对生成向量嵌入的工作负载,迅速增加对内存和计算资源的需求。在庞大的数据集中,上下文窗口大且代价高昂地传递给 LLM,并且更多的上下文并不一定意味着更高的相关性。只有一个强大的工具平台能够塑造上下文,并平衡相关性与扩展性之间的权衡,以实现一个可行的、面向未来的创新架构。
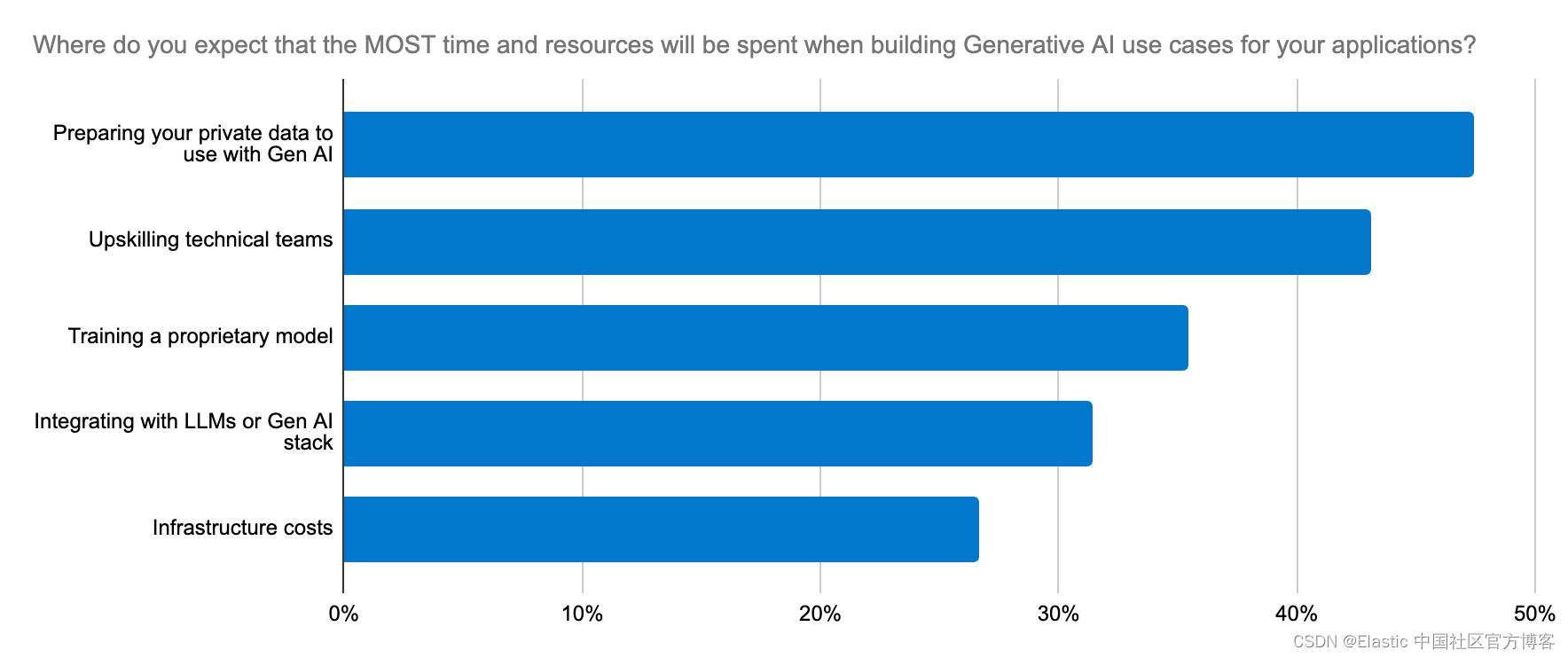
开发者寻求一种可靠、可扩展且成本效益高的方式来构建生成式 AI 应用程序,以及一个简化实施和 LLM 选择过程的平台。
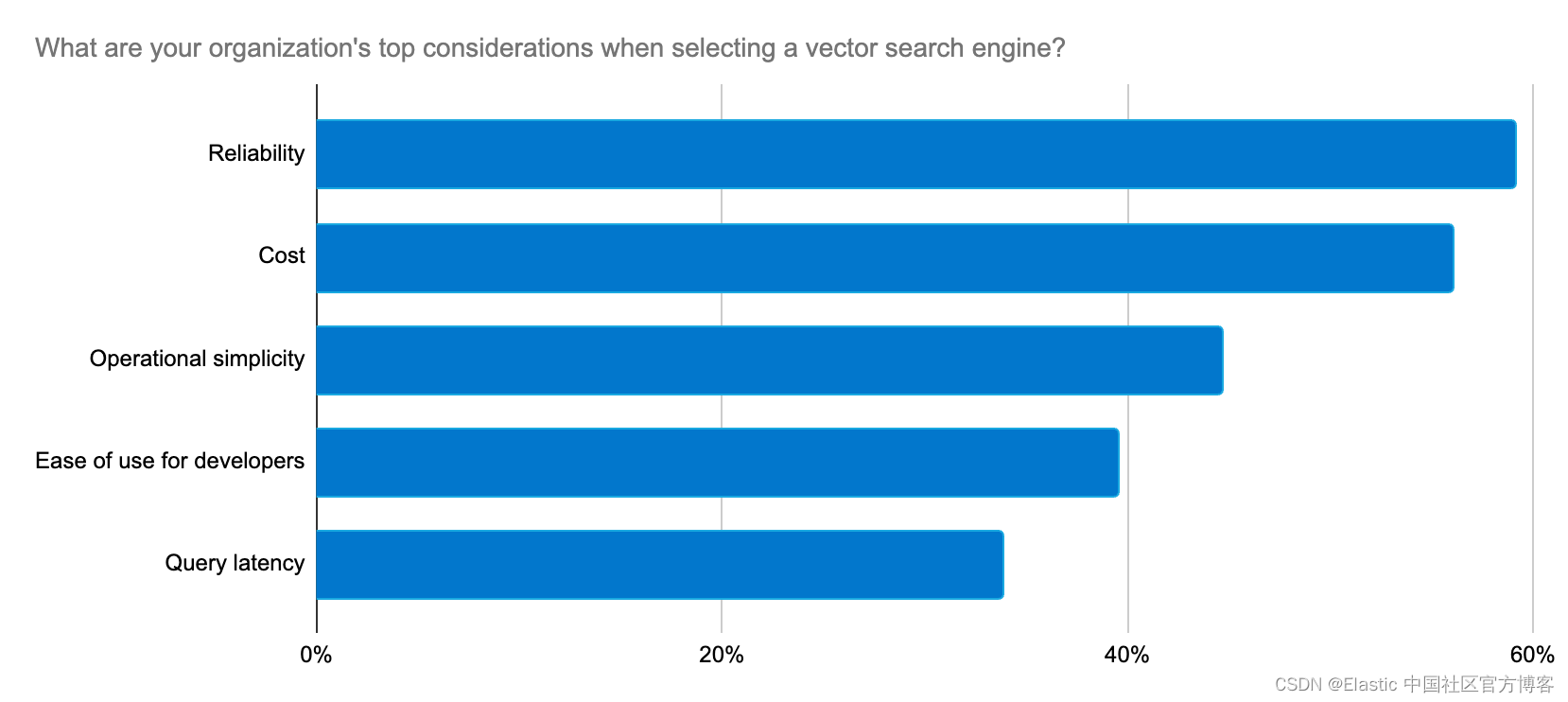
Elastic 通过快速创新的步伐,持续为这些开发者关注的问题提供解决方案,以支持生成式 AI 的用例。
快速、大规模地推出生成式人工智能体验
Elasticsearch 是市场上下载次数最多的向量数据库,Elastic 与 Lucene 社区的深厚合作使我们能够更快地为客户设计和交付搜索创新。 Elasticsearch 现在由 Lucene 9.10 提供支持,帮助客户通过生成式 AI 实现速度和规模。 在 9.10 中,除其他速度提升外,用户还发现多段索引的查询延迟显着改善。 这仅仅是开始,还会有更快的速度。
我们选择 Elastic 作为向量数据库,因为它具有固有的灵活性、可扩展性和可靠性。Elastic 不断通过快速提供支持机器学习和生成式 AI 的新功能来提升水平。
—— Peter O'Connor,Stack Overflow 平台工程部经理
为了快速实施和扩展 RAG 工作负载,Elastic 学习稀疏编码器(ELSER)—— 现已正式发布 —— 是一款易于部署、优化的、用于语义搜索的晚期交互机器学习(ML)模型。ELSER 提供上下文相关的搜索结果,无需精细调整,并为开发者提供了一个内置的可信解决方案,节省了你在模型选择、部署和管理方面的时间和复杂性。
ELSER 在不牺牲速度的情况下提升了搜索的相关性 —— 当 Consensus 升级了其由 Elastic 提供动力的学术研究平台,使用 ELSER 时,它将搜索延迟减少了75%,同时提高了准确性。
当你将 ELSER 与 E5 嵌入模型配对时,你可以轻松应用多语言向量搜索。我们为 Elasticsearch 部署特别定制的 E5 优化工件。通过上传多语言模型或与 Elastic 的推理 API 集成(例如,Cohere 的多语言模型嵌入)也可以实现多语言搜索。这些进步进一步加速了检索增强生成(RAG),使 Elastic 成为扩展你构建的创新生成式 AI 体验的关键基础设施。
Elastic 也专注于高效地扩展这些体验。我们在 8.12 版本中引入的标量量化是向量存储的游戏规则改变者。大型向量扩展可能会导致搜索速度变慢。但这种压缩技术显著降低了内存需求,达到四倍,并且在更高的规模上,对召回率的影响可以忽略不计。它使得在 RAG 中使用的向量搜索速度翻倍,而不牺牲准确性。结果是什么?一个更精简、更快的系统,在规模上削减了基础设施成本。
搜索对于提升 Udemy 用户体验至关重要 —— 将用户与相关的教育内容匹配,这就是为什么 Elastic 一直是我们的长期合作伙伴。自从去年升级到 Elastic Cloud 以来,我们就一直使用 Elastic 作为我们的向量数据库,它为我们的业务开辟了新的机会。随着我们在创新教育解决方案中扩展向量搜索,我们已经看到了查询速度和资源效率的增加。
Udemy 软件工程团队
对于 RAG 来说,最相关的搜索引擎
相关性是获得最佳生成式 AI 体验的关键。使用 ELSER 进行语义搜索和使用 BM25 进行文本搜索是检索作为 LLM 上下文的相关文档的绝佳首选步骤。大型上下文窗口可以进一步通过现在是 Elastic Stack 的一部分的重新排名工具进行细化。重新排名器应用强大的 ML 模型对搜索结果进行微调,并根据用户偏好和信号将最相关的结果置于顶部。学习排序(LTR)现在也是 Elasticsearch 平台的本机功能。这对于依赖于向 LLM 提供最相关结果作为上下文的 RAG 用例非常有用。
通过 inference API 和像 Cohere 这样的第三方提供商,实施进一步简化。升级到我们的最新版本,以测试重新排名器对相关性的影响。
这些方法不仅可以提高搜索准确性(例如 Consensus 的情况下提高了 30%),而且还可以帮助你快速获得结果,为 RAG 优化相关性并有效管理 ML 工作流。
使模型选择和更换变得简单
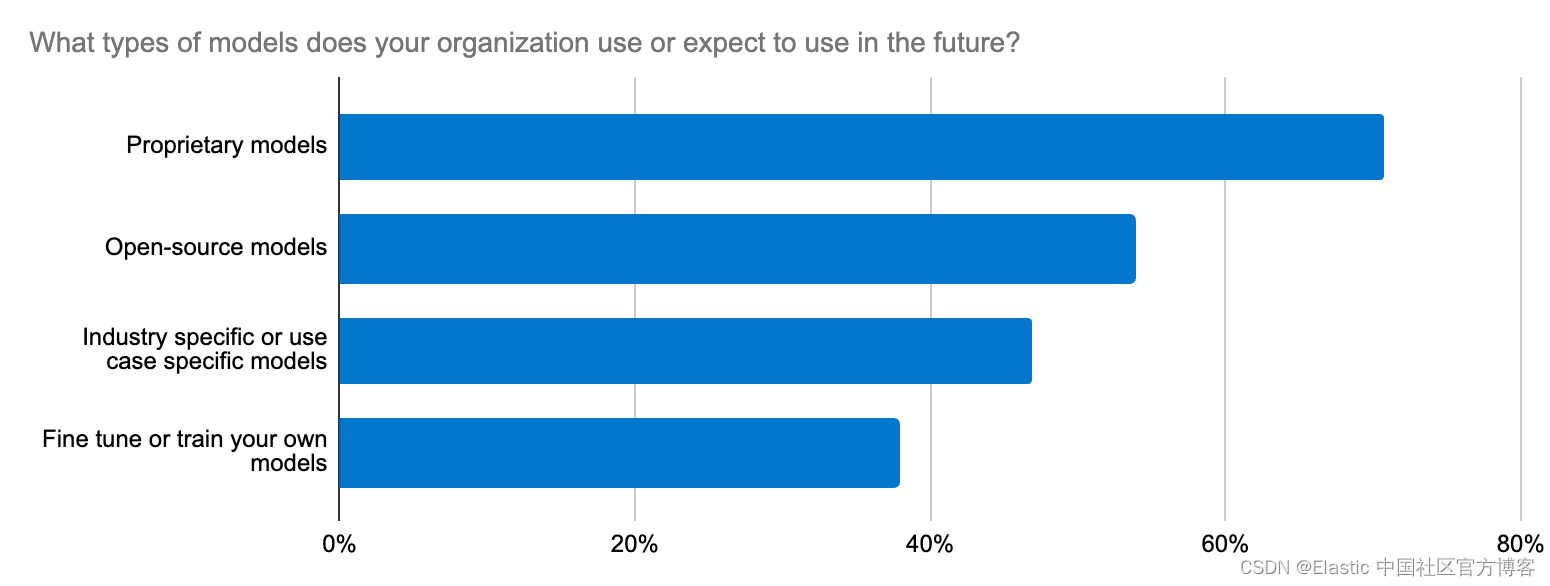
模型选择就像在干草堆里寻找针一样感觉艰难。实际上,我们的开发者调查突出显示,跨组织的前五大生成式 AI 努力之一是与 LLM 集成。这个难题不仅仅是为一个用例选择开源还是闭源 LLM —— 它还扩展到准确性、数据安全性、特定领域的特性,以及快速适应不断变化的 LLM 生态系统。开发者需要一个直接的工作流程来尝试新模型并轻松更换它们。
Elastic 通过其开放平台、向量数据库和搜索引擎支持转换器模型和基础模型。Elastic 学习稀疏编码器(ELSER)是加速 RAG 实施的可靠起点。
此外,Elastic 的 inference API 为开发者简化了代码和多云推理管理。无论你是使用 ELSER 还是来自 OpenAI(在开发者中评估和使用最多的模型)、Hugging Face、Cohere 或其他来源的嵌入式模型来处理 RAG 工作负载,一个 API 调用就能确保管理混合推理部署的代码整洁。借助 inference API,可以轻松访问广泛的模型,因此你可以找到合适的选择。与特定领域的自然语言处理(NLP)和生成式 AI 模型的轻松集成简化了模型管理,释放你的时间专注于 AI 创新。
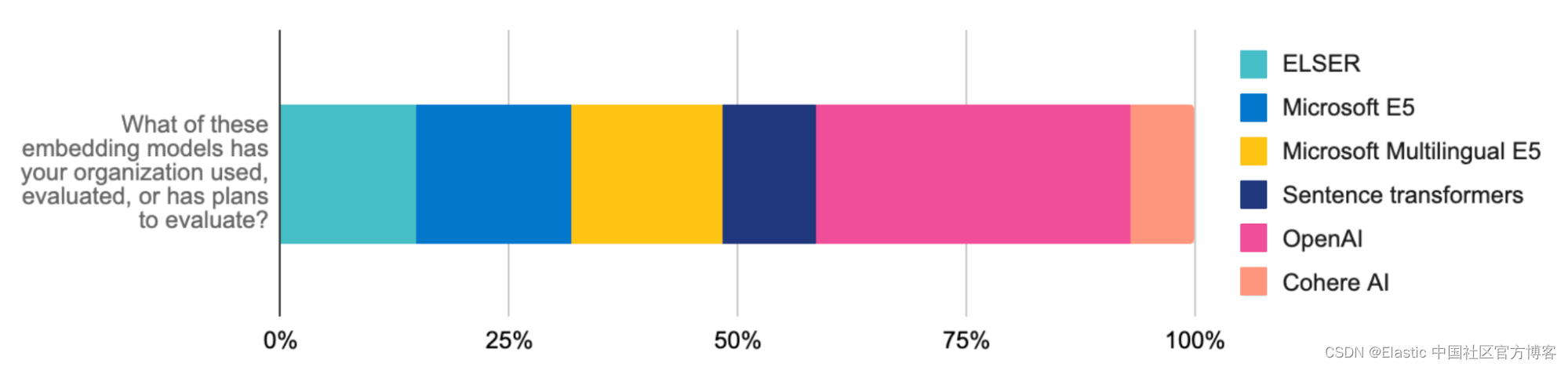
携手同行:与集成共创卓越体验
开发者还可以托管包括公共和私有 Hugging Face 模型在内的多样化转换模型。虽然 Elasticsearch 作为整个生态系统的多功能向量数据库,那些偏好使用诸如 LangChain 和 LlamaIndex 工具的开发者,可以利用我们的集成快速启动基于 LangChain 模板的生产就绪的生成式 AI 应用。Elastic 的开放平台让你能够快速适应、实验并加速生成式 AI 项目。Elastic 最近还被添加为 On Your Data 的第三方向量数据库,这是一个构建对话式 copilots 的新服务。另一个好例子是 Elastic 与 Cohere 团队背后的合作,使 Elastic 成为 Cohere 嵌入式向量的优秀向量数据库。
生成式 AI 正在重塑每一个组织,Elastic 在这里支持这一转型。对开发者而言,成功实施生成式 AI 的关键是持续学习(你已经看过 Elastic Search Labs 了吗?)和快速适应不断变化的 AI 景观。
当你将 Elastic 的准确性和速度与 Google Cloud 的强大功能结合起来时,你可以构建一个非常稳定和成本效益高的搜索平台,同时为用户提供令人愉悦的体验。
—— Sujith Joseph,思科系统的首席企业搜索和云架构师
立即尝试!
- 在 Elastic Search 发布说明中阅读有关这些功能以及更多内容。
- 现有的 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问许多这些功能。还没有使用 Elastic Cloud?开始免费试用。
- 尝试 Elasticsearch Relevance Engine,我们的一套用于构建 AI 搜索应用程序的开发者工具。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或引用了第三方生成人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 和相关标志是 Elasticsearch N.V. 的商标、徽标或注册商标。 在美国和其他国家。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:Accelerating generative AI experiences | Elastic Blog