一、什么是网络爬虫
在当今信息爆炸的时代,网络上蕴藏着大量宝贵的信息,如何高效地从中获取所需信息成为了一个重要课题。网络爬虫(Web crawler)作为一种自动化工具,可以帮助我们实现这一目标,用于数据分析、搜索引擎优化、信息监测等目的。由于Python语言有易学、丰富的库和爬虫框架、多线程支持、跨平台支持和强大的数据处理能力等特点,在编写爬虫方面具有得天独厚的优势,这些优势使得Python成为爬虫开发的首选语言。本文介绍了一般网络爬虫的实现过程,并介绍如何Python语言编写一个简单的网络爬虫。
二、网络爬虫的实现步骤
网络爬虫的实现可概括为以下几个步骤:
-
发送HTTP请求: 网络爬虫首先向目标网站发送HTTP请求,请求特定的页面内容。这通常是使用Python中的
requests库或类似工具来完成的。 -
获取页面内容: 网络爬虫接收到服务器的响应后,获取页面的HTML内容。这个内容可能包含文本、图片、视频、链接等信息。
-
解析页面内容: 爬虫将获取到的HTML内容进行解析,通常使用HTML解析器(如
BeautifulSoup)来提取出需要的信息,比如链接、文本、图片等。 -
链接提取: 在解析页面内容的过程中,爬虫会提取出页面中的链接。这些链接可以是其他页面的URL,也可以是资源文件(如图片、视频)的URL。
-
递归爬取: 爬虫将提取到的链接作为新的目标,继续发送HTTP请求并获取页面内容。这样就形成了一个递归的过程,爬虫不断地发现新的页面,并从中提取出更多的链接。
-
数据处理与存储: 爬虫在提取到数据后,可能需要进行进一步的处理和清洗,然后将数据存储到本地文件或者数据库中供后续使用。
-
异常处理与反爬虫策略: 在爬取过程中,可能会遇到各种异常情况,如网络连接错误、页面解析错误等。爬虫需要考虑这些异常情况并进行适当的处理,同时也需要应对目标网站可能采取的反爬虫策略,如设置User-Agent、使用代理IP、降低爬取速度等。
总的来说,网络爬虫的原理就是模拟人类用户的行为,通过发送HTTP请求获取页面内容,然后解析页面内容提取出需要的信息。通过不断地递归爬取和处理,爬虫可以从互联网上收集到大量的数据。
三、如何用python编写一个简单的爬虫?
在Python中,我们可以使用第三方库如requests和BeautifulSoup来编写一个最简单的网络爬虫。以下是一个简单的示例,用于爬取西安电子科技大学研究生院的通知公告栏目第一页中的标题及相应链接:
第一步:安装所需库
首先,我们需要安装requests和BeautifulSoup库。如果这两个库没有安装,可以进入命令行,
使用以下命令来安装:
pip install requests
pip beautifulsoup4 第二步:分析要爬取的页面
1、查看robots.txt
爬取页面前,首先要确定该网站是否允许通过爬虫获取数据。网站是否允许爬虫爬取数据,以及允许爬取哪些资源,一般都是通过robots.txt来确定。
比如知乎,只允许一些知名搜索引擎去爬取特定目录,其他的爬虫,则不允许爬取其网站数据。
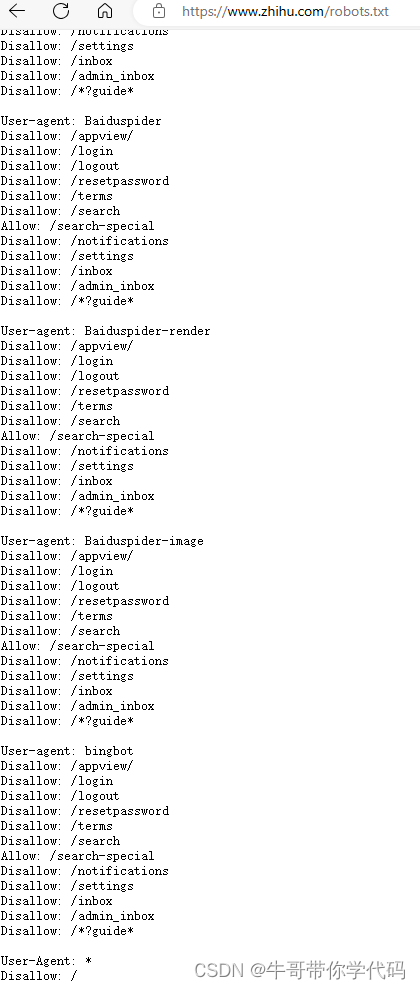
西安电子科技大学研究生院的网址是https://gr.xidian.edu.cn/,加上robots.txt,就是链接就是https://gr.xidian.edu.cn/robots.txt,未设置robots.txt文件进行说明,未做限制,那就拿它来试一下吧。经测试,西电网站确实比较友好,即使不修改,将爬虫伪装成浏览器,获取信息也没有什么困难。
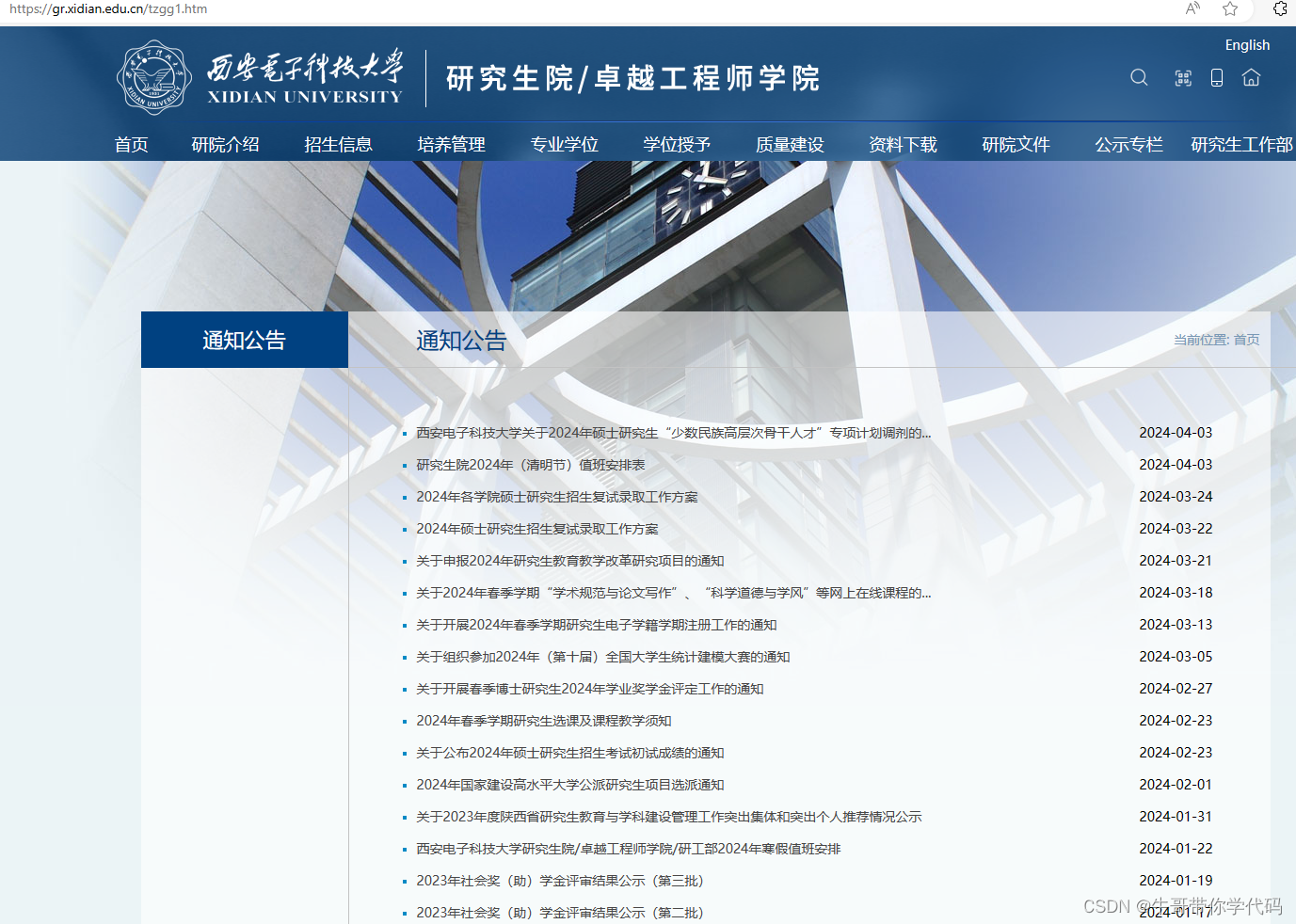
2、使用开发者工具对目标页面进行分析
打开网站通知公告栏目,可以看到网址是https://gr.xidian.edu.cn/tzgg1.htm
在浏览器中按F12,进入开发者工具。
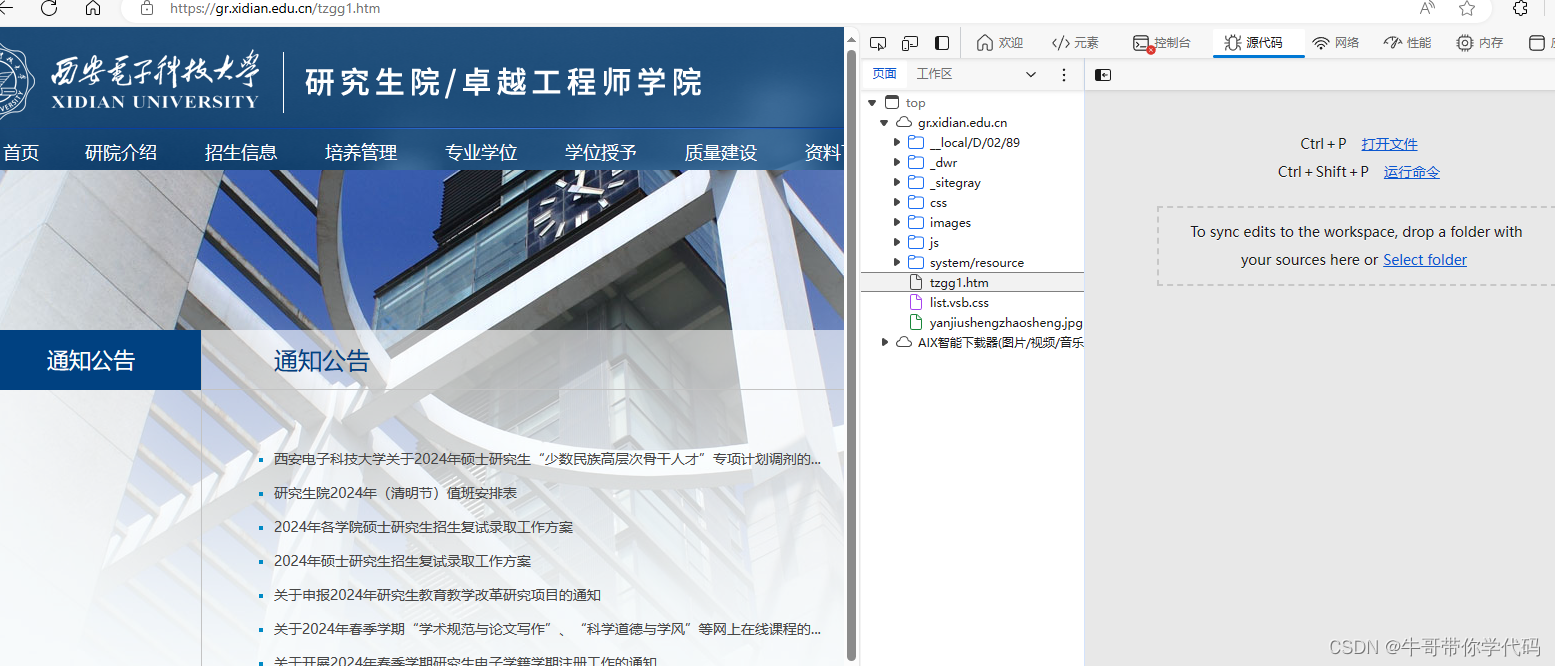
在开发者工具中选择“网络”-“全部”,然后再点击浏览器中左上角的刷新按钮。你会发现,刷新这一页面后,下载了好多东西,既有htm文件,又有css文件,还有js文件以及jpg图像文件等。一般来说,HTML文件(或htm文件)负责网页的架构;CSS文件负责网页的样式和美化;JavaScript(JS)则是负责网页的行为。正是因为这些文件相互配合,才使得页面能够正常显示。
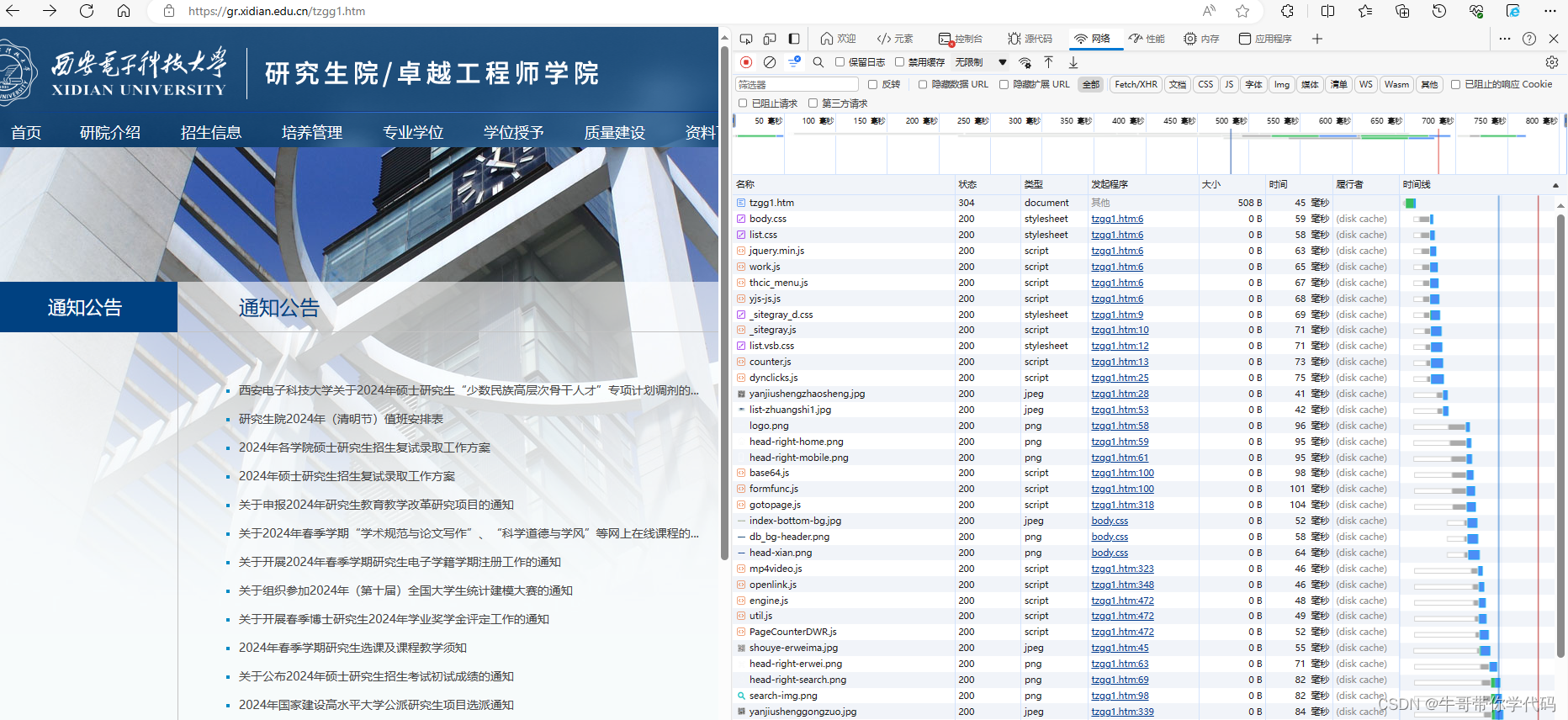
从浏览器的网址来看,通知公告的首页网址对应的文件应该是tzgg1.htm,从文件大小来比较,它的信息量也是最大的,点击它后,点击标头进行查看。
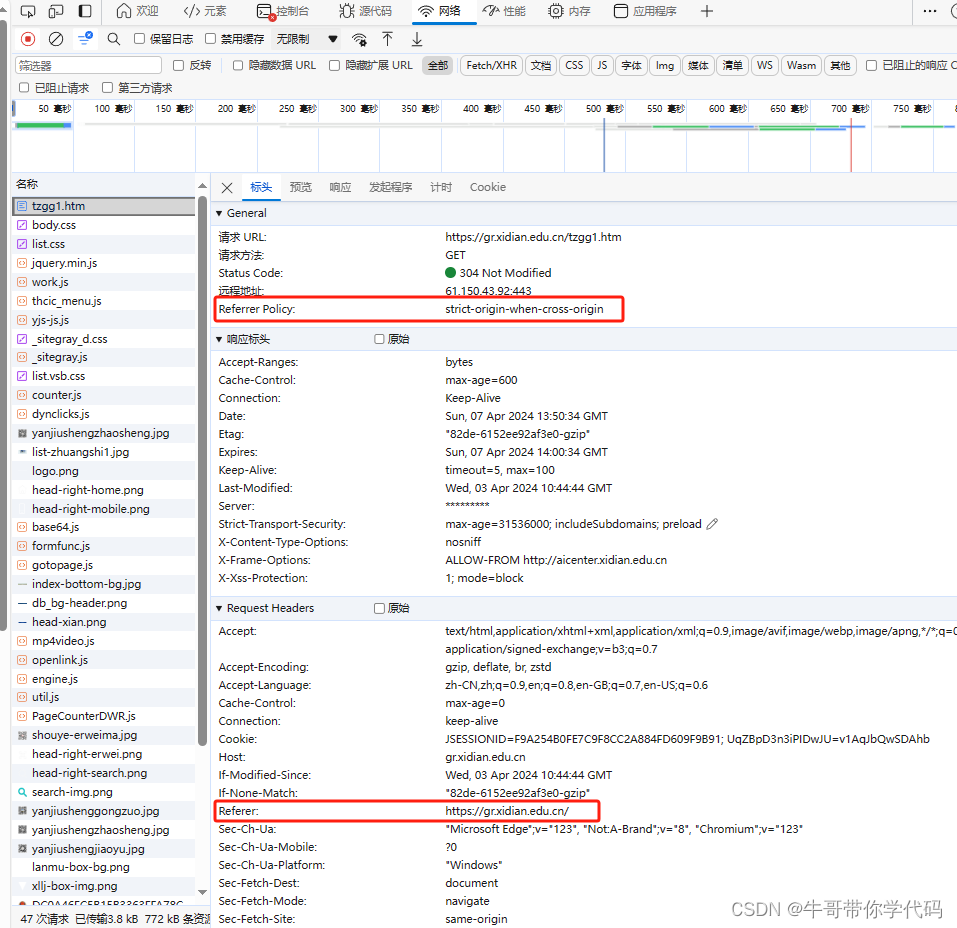
可以看到,标头中包含许多重要信息,是编写爬虫是必须要注意的部分。从标头中可以看到请示链接方法是用的GET方法,状态码是200为正常结束,GET方法相对于POST方法而言相对简单。发现这里使用了strict-origin-when-cross-origin的Referrer Policy,原以为这个策略会给我们的爬虫增加一些麻烦,结果并没有。
3、"strict-origin-when-cross-origin" 策略
"strict-origin-when-cross-origin" 是一种比较严格的 Referrer Policy 策略。它的行为如下:
- 当请求从一个页面 A 跳转到同一源的页面 B 时,Referrer 首部会包含完整的 URL 信息,包括路径和查询参数。这是为了确保目标页面 B 能够获取足够的信息来处理请求。
- 当请求从页面 A 跳转到不同源的页面 C 时,Referrer 首部只包含请求源的 origin 信息,而不包含路径或查询参数等详细信息。这是为了减少敏感信息的泄露。
可以看到通知公告首页面的Referer是主页面https://gr.xidian.edu.cn,我们正是从主页面进行通知公告栏目的,再点击下一页,可以看到Referer变成https://gr.xidian.edu.cn/tzgg1.htm,在站内不同页面之间的链接,是完全遵守"strict-origin-when-cross-origin" 策略的
原以为"strict-origin-when-cross-origin" 策略的引用可能是为防爬策略,不在Request Head中设置正确的Referer无法爬取正确的数据,结果似乎没什么影响,也许是因为动作太小吧。
编写网络爬虫相较于一般程序而言,性价比是比较低的,一是因为其一般没有什么通用性,一个网站的代码一种风格,规则也不一样;二是对于防爬做的好的网站,想将其分析透彻或是进行破解,可能要花费大量的时间。
4、源代码分析,查找链接对应的源代码
下面,我们要做的是,在页面源代码中找到有关通知标题对应的代码。
(1)源代码查找法
点击“响应”,可以看到网站服务器返回的响应信息,也就是文件tzgg1.htm的源代码,看到原页面中第一条通知包含“少数民族高层次骨干人才",点击代码,然后按Ctrl+F,输入“少数民族高层次骨干人才”回车,立即找到了相关的网页代码。
学习网络爬虫,是必须对HTML有一定了解的,但不需要精通,如果不太了解,可通过我写的另一篇博客快速了解HTML有关知识:HTML超详细教程_html教程-CSDN博客。
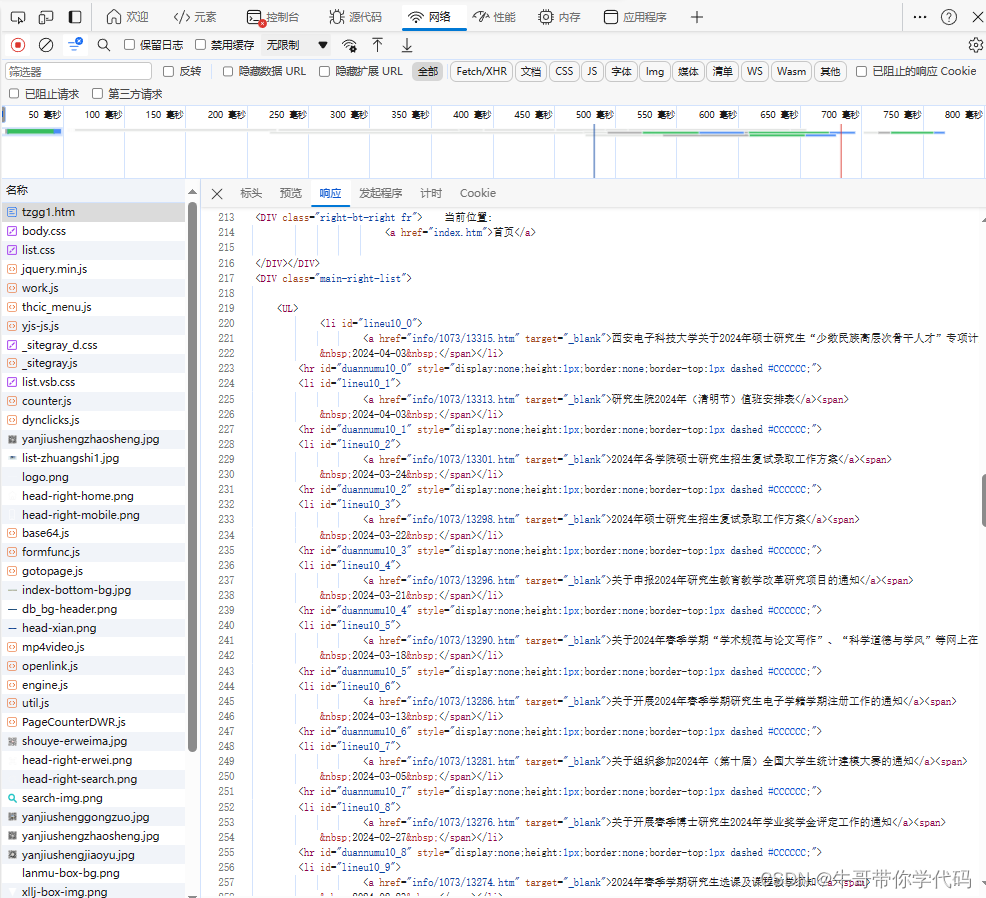
从代码中可以看到,通知都集中在<DIV class="main-right-list"> 中的 <UL>内,每条通知的标题和链接都包含在一个<li>的<a>内,
<DIV class="main-right-list">
<UL>
<li id="lineu10_0">
<a href="info/1073/13315.htm" target="_blank">西安电子科技大学关于2024年硕士研究生“少数民族高层次骨干人才”专项计划调剂的...
</a>
<span> 2024-04-03 </span>
</li>
<hr id="duannumu10_0" style="display:none;height:1px;border:none;border-top:1px dashed #CCCCCC;">
<li id="lineu10_1">
<a href="info/1073/13313.htm" target="_blank">研究生院2024年(清明节)值班安排表
</a>
<span> 2024-04-03 </span></li>
</UL>
</DIV>(2)元素查找定位法
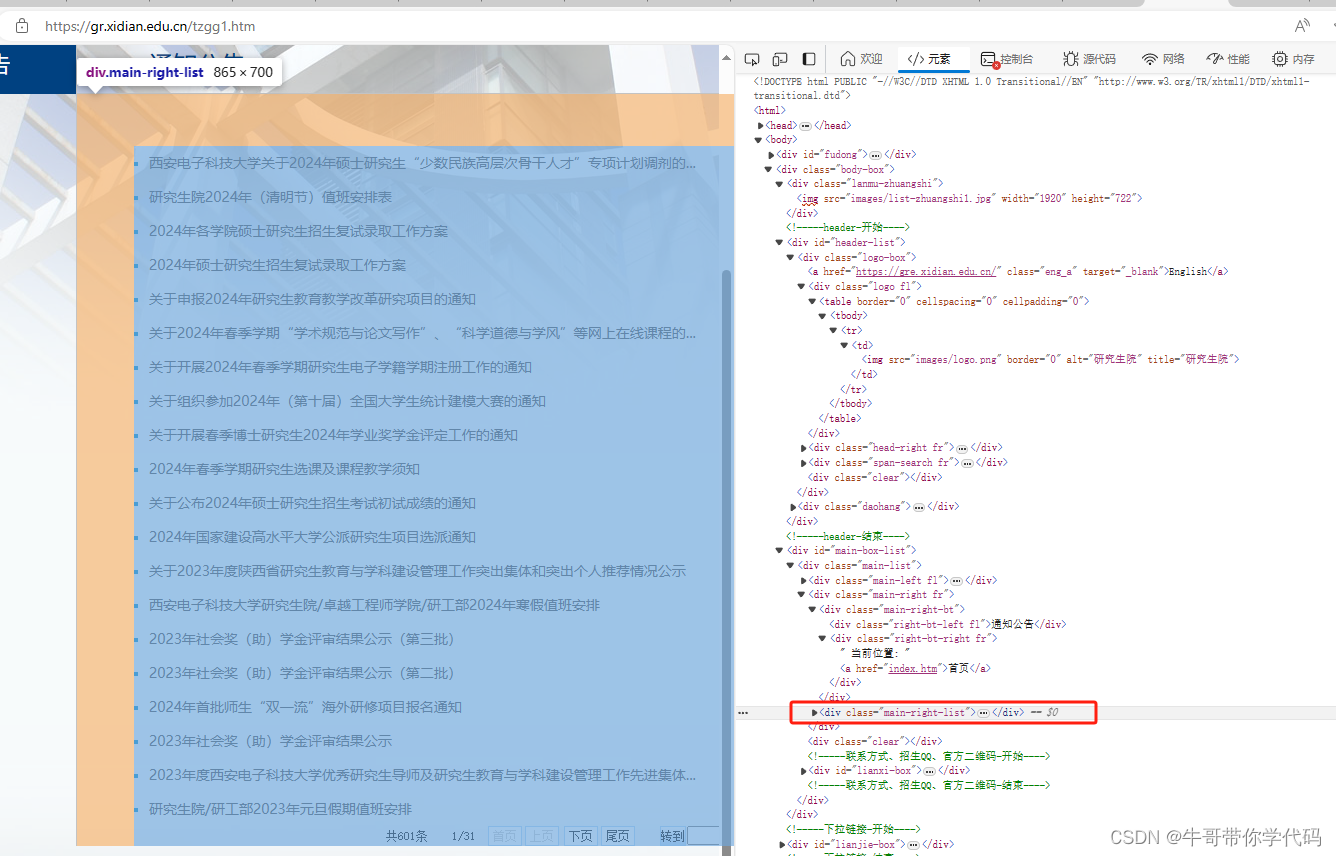
在开发工具中,点击“元素”,就可以将鼠标放在相应代码上,直接查看代码在左边页面上对应哪些模块。可也明显看到,通知的链接都在<div class="main-right-list">内,这样查找,更直观也更方便。
第二步:编写爬虫代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
def get_links(url):
# 发送HTTP请求获取页面内容
response = requests.get(url)
#使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.content, "html.parser",from_encoding='utf-8')
#定位到class名为main-right-list的div
rightlist=soup.find('div', class_='main-right-list')
# 找到div中所有链接并提取标题和URL
links = rightlist.find_all("a")
#链接只包含路径,未包含域名,将其补上
return [(link.text, "https://gr.xidian.edu.cn/"+link.get("href")) for link in links]
# 要爬取的网页URL
url = "https://gr.xidian.edu.cn/tzgg1.htm"
# 获取链接并打印标题和URL
links = get_links(url)
for title, link in links:
print(f"{title}: {link}")在这个示例中,我们首先使用requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析HTML内容。最后,我们提取所有链接的标题和URL,并将其打印出来。

在爬到的链接最后,列出了下一頁的网址,通过它就可以进行下一页的爬取,一直循环到将全部内容爬完,这里不再赘述。

四、爬虫使用注意事项
在编写爬虫时,还有一些注意事项需要注意:
- 尊重网站规则: 爬虫应该遵守网站的robots.txt文件,以确保不会对网站造成过度负荷或侵犯其隐私政策。
- 处理异常情况: 在爬取过程中,可能会遇到各种异常情况,如网络错误或页面解析错误。在编写爬虫时,应该考虑这些情况并进行适当处理。本文的爬虫比较简单,未进行异常处理。
- 频率控制: 为了避免对网站造成过度负荷,爬虫应该控制访问频率,并遵守网站的访问频率限制。
以上为个人爬虫学习的一点体会,如不当或不正确之处,欢迎指出,以便及时更正。