R语言是一种用于统计计算与绘图的编程语言,它免费、开源,被广泛应用于统计分析、数据挖掘等领域。是应用于统计计算和统计制图的优秀工具。
完整代码放在最后
一、数据收集
所使用数据下载自GEO(https://www.ncbi.nlm.nih.gov/geoprofiles/)网站,以保证真实性。
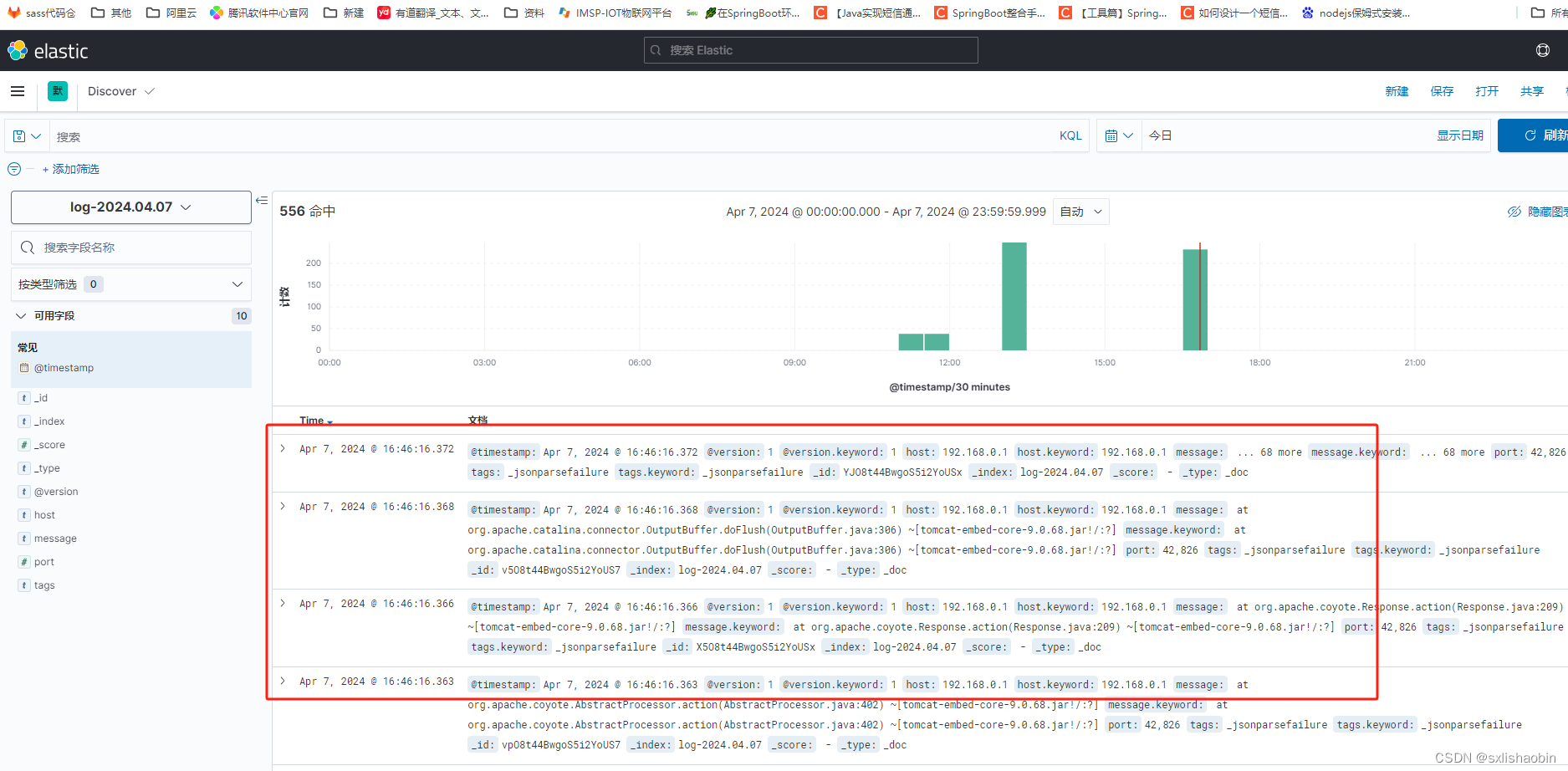
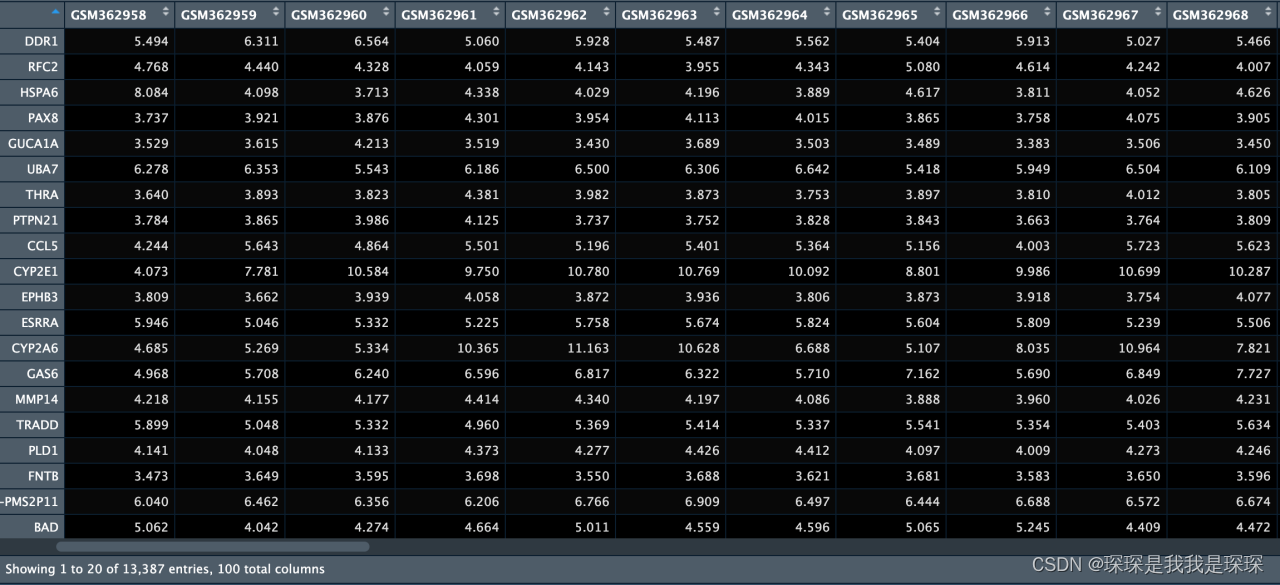
GSM基因表达矩阵预览。其中,第一列为探针名,第一行为样本名,其余为不同样本中各个基因的表达量统计。

二、数据处理及数据清洗
通过第一部分中下载好的平台数据对表达矩阵进行预处理和数据清洗。将探针ID替换为基因名,处理掉重复的基因表达量,为后续的limma数据分析流程做准备。

*第一列已经替换为基因ID
三、数据分析
通常处理高通量数据输出差异表达分析会使用DESeq2、edgeR、limma等数据处理包,适用于处理不同特点的数据。它们都可输出logFC和P-value值。

*这里使用的是limma包,这是一个标准化的过程
标准limma流程会生成两个矩阵,分别为基因表达差异矩阵和分组矩阵,我们会在后续基因差异分析中使用到。

*差异矩阵
分组矩阵将样本分为肿瘤组和非终究组作为对照,并赋予一个唯一的整数编码。
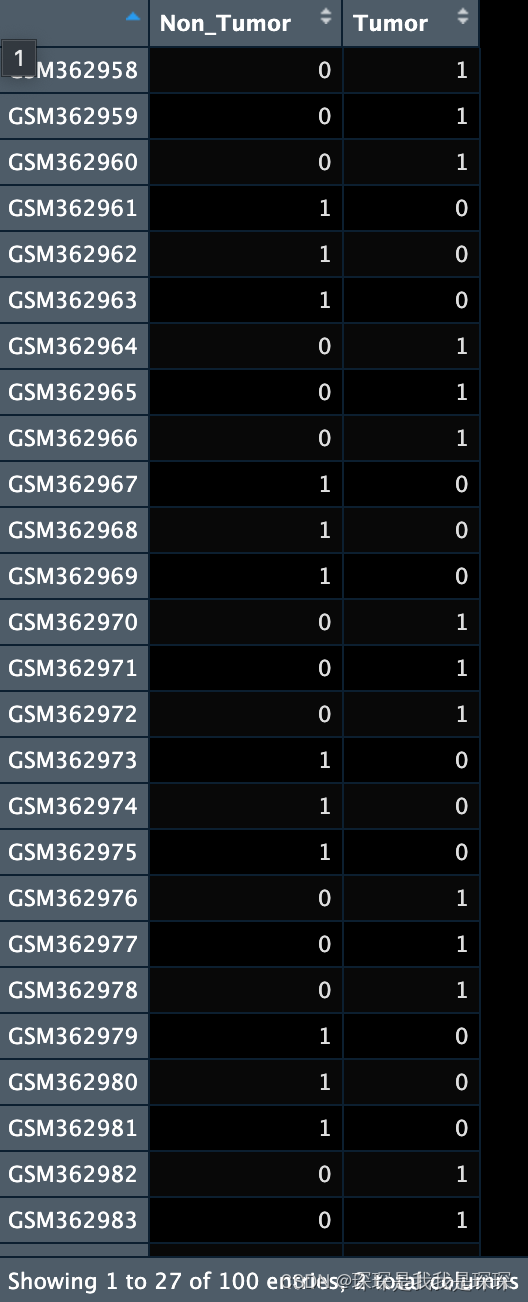
*分组矩阵
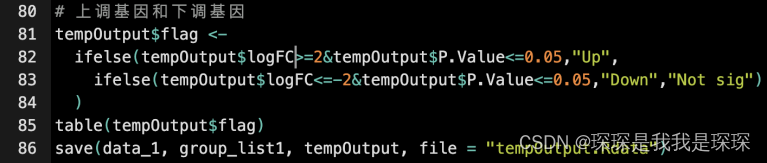
根据limma分析得到的logFC值和p值对上调基因和下调基因进行筛选并保存到tempOutput表达差异矩阵中。
四、作图
-
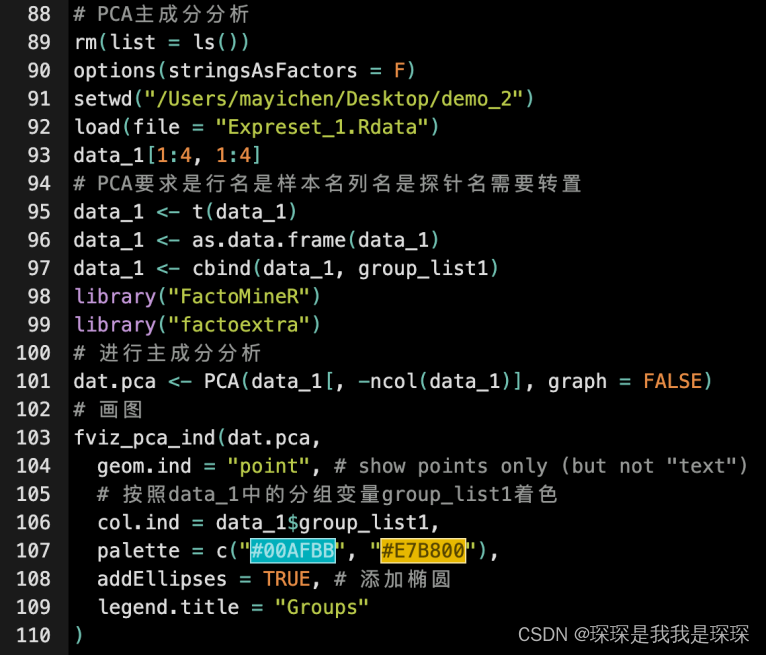
PCA主成分分析
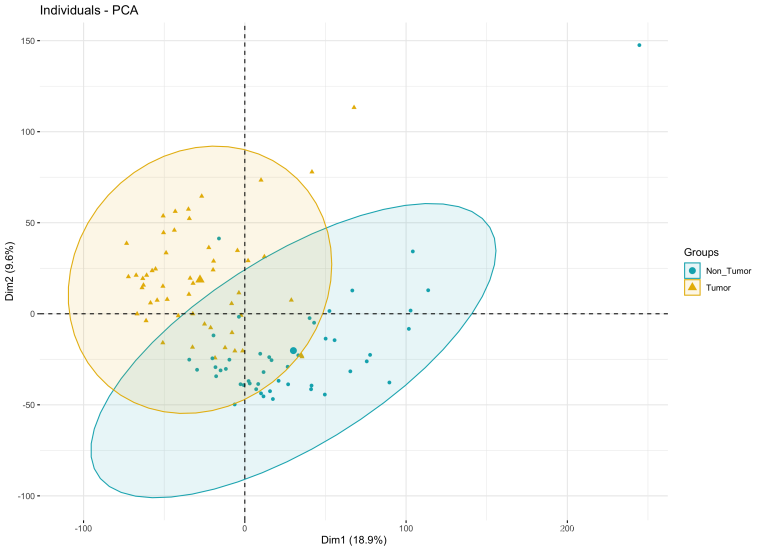
*可明显看出Tumro组和Non_Tumor组基因表达量分为两个维度并存在较大差异。
2、火山图


*根据logFC和-log10(p-value)值生成,位于图表上方且远离中心的点表示的是那些具有显著统计差 异且变化幅度大的基因。
3、箱线图

*由火山图可以看出KPNA2基因的表达明显上调,我们可以利用箱线图来进一步研究
4、热图


*常用于展示大量数据的二维矩阵,其中矩阵的每一个元素用颜色的深浅来表示数值的大小,可快速识别数据中的模式和趋势。
# 2023_03_31
# by myc_0718
rm(list = ls())
options(stringsAsFactors = F)
library(GEOquery)
library(limma)
library(affy)
gse_nam <- "GSE14520_eSet.Rdata"
if (!file.exists(gse_nam)) {
gset <- getGEO("GSE14520",
destdir = ".", # 目的地目录
AnnotGPL = T, # 注释文件
getGPL = T # 平台文件
)
setwd("/Users/mayichen/Desktop/demo_2")
save(gset, file = gse_nam)
}
load("GSE14520_eSet.Rdata")
gset[[1]]
class(gset[[1]])
# ExpressionSet中包含了基因表达矩阵和相关的样本信息
data_1 <- exprs(gset[[1]]) # 使用函数exprs获取样本表达矩阵
pd_1 <- pData(gset[[1]]) # 使用函数pData获取样本临床信息(如性别、年龄、肿瘤分期等等)
# ifelse会对向量中每个元素执行一次
# group list1 是分组信息后面有用
# data_1 <- data_1[-c(1001:22268),]
data_1 <- data_1[, -c(101:445)]
group_list1 <-
ifelse(
pd_1$characteristics_ch1 == "Tissue: Liver Tumor Tissue" |
pd_1$characteristics_ch1 == "tissue: Liver Tumor Tissue",
"Tumor",
"Non_Tumor"
)
group_list1 <- group_list1[1:100]
save(data_1, group_list1, file = "Expreset_1.Rdata")
# 探针ID转换为基因ID
rm(list = ls())
options(stringsAsFactors = F)
load("GSE14520_eSet.Rdata")
load(file = "Expreset_1.Rdata")
dat_gpl <- fData(gset[[1]])
dat_gpl_new <- dat_gpl[c(1, 3)]
colnames(dat_gpl_new) <- c("probe_id", "Gene symbol")
data_1 <- as.data.frame(data_1)
# 把探针id添加到最后一列 行名赋值给新列
data_1$probe_id <- rownames(data_1)
# merge()函数将data_1的探针id与芯片平台探针id相匹配,合并到data_1
data_1 <- merge(data_1, dat_gpl_new, by = "probe_id")
# 基因名有重复所以按基因ID取平均
data_1 <- avereps(data_1[, -c(1, 102)], ID = data_1$`Gene symbol`)
data_1 <- as.matrix(data_1)
save(data_1, group_list1, file = "Expreset_1.Rdata")
rm(list = ls())
options(stringsAsFactors = F)
load(file = "Expreset_1.Rdata")
# 标准的limma流程(生成表达矩阵和分组矩阵)
library(limma)
# factor() 创建一个分组的因子变量,每个类别会被赋予一个唯一的整数编码
design <- model.matrix(~ 0 + factor(group_list1))
colnames(design) <- levels(factor(group_list1))
rownames(design) <- colnames(data_1)
head(design)
# 创建差异比较矩阵,这个矩阵声明要对Tumor组和Non_Tumor组进行差异分析比较
contrast.matrix <-
makeContrasts(paste0(unique(group_list1), collapse = "-"), levels = design)
contrast.matrix
# 线性拟合模型的构建
fit_1 <- lmFit(data_1, design)
fit_2 <- contrasts.fit(fit_1, contrast.matrix)
fit_2 <- eBayes(fit_2)
# topTable 提取limma模型分析后有显著差异表达的基因。
options(digits = 4)
tempOutput <- topTable(fit_2, coef = 1, n = Inf)
tempOutput <- na.omit(tempOutput) # 移除NA值
head(tempOutput)
# 上调基因和下调基因
tempOutput$flag <-
ifelse(tempOutput$logFC >= 2 & tempOutput$P.Value <= 0.05, "Up",
ifelse(tempOutput$logFC <= -2 & tempOutput$P.Value <= 0.05, "Down", "Not sig")
)
table(tempOutput$flag)
save(data_1, group_list1, tempOutput, file = "tempOutput.Rdata")
# PCA主成分分析
rm(list = ls())
options(stringsAsFactors = F)
setwd("/Users/mayichen/Desktop/demo_2")
load(file = "Expreset_1.Rdata")
data_1[1:4, 1:4]
# PCA要求是行名是样本名列名是探针名需要转置
data_1 <- t(data_1)
data_1 <- as.data.frame(data_1)
data_1 <- cbind(data_1, group_list1)
library("FactoMineR")
library("factoextra")
# 进行主成分分析
dat.pca <- PCA(data_1[, -ncol(data_1)], graph = FALSE)
# 画图
fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (but not "text")
# 按照data_1中的分组变量group_list1着色
col.ind = data_1$group_list1,
palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # 添加椭圆
legend.title = "Groups"
)
# 层次聚类分析
rm(list = ls())
options(stringsAsFactors = F)
setwd("/Users/mayichen/Desktop/demo_2")
load(file = "Expreset_1.Rdata")
data_1[1:4, 1:4] # 每次都要检测数据
data_1 <- t(data_1) # 层次聚类分析要求行名是样本名
data_1[1:4, 1:4]
fit.complete <- hclust(dist(data_1), method = "complete")
plot(fit.complete, labels = FALSE, hang = -1, cex = 0.8)
# for volcano 火山图
rm(list = ls())
options(stringsAsFactors = F)
load(file = "tempOutput.Rdata")
data_vol <- tempOutput
table(data_vol$flag)
data_vol$temp_v <- -log10(data_vol$P.Value) # -log10(P.Value)整理p值
temp_v_2 <- data_vol[data_vol$temp_v >= 23, ]
library(tibble)
temp_v_2 <- rownames_to_column(temp_v_2, var = "gene_name")
dim(temp_v_2)
library(ggplot2)
library(ggrepel)
ggplot(data_vol, aes(x = logFC, y = temp_v)) +
geom_point(aes(color = flag)) +
scale_color_manual(values = c("dodgerblue", "gray", "firebrick")) +
geom_label_repel
(data = temp_v_2, aes(x = logFC, y = temp_v, label = gene_name)) +
labs(y = "-log10(pvalue)", x = "log(Fold Change)") +
theme_bw()
# for heatmap 热图
rm(list = ls())
options(stringsAsFactors = F)
if (!requireNamespace("RColorBrewer", quietly = TRUE)) {
install.packages("RColorBrewer")
}
load(file = "tempOutput.Rdata")
data_1[1:4, 1:4]
table(group_list1)
x <- tempOutput$logFC # 取logFC这列并将其重新赋值给x
names(x) <- row.names(tempOutput)
x[1:4]
cg <- c(
names(head(sort(x), 10)),
names(tail(sort(x), 10))
)
head(cg)
library(pheatmap)
# 归一化
data_2 <- t(scale(t(data_1[cg, ])))
data_2[data_2 > 2] <- 2
data_2[data_2 < -2] <- -2
data_2[1:4, 1:4]
# 聚类
library(tibble)
library(forcats)
library(RColorBrewer)
group_list1_select <- data.frame(flag = group_list1)
rownames(group_list1_select) <- colnames(data_2)
group_list1_select <- group_list1_select %>%
dplyr::mutate(flag = fct_relevel(flag, c("Tumor", "Non_Tumor"))) %>%
dplyr::arrange(flag)
# 将group_list1_select的行名也就分组信息给到n的列名,即热图中位于上方的分组信息
# 从矩阵或数据框 data_2 中选择与 group_list1_select 数据框的行名相对应的列
data_2 <- data_2[, rownames(group_list1_select)]
anno_color <- list(group = c("Tumor" = "#66C2A5", "Non_Tumor" = "#FC8D62"))
pheatmap(data_2,
show_colnames = F, show_rownames = F, cluster_cols = F, scale = "row",
# 样本组别信息 按照列
annotation_col = group_list1_select,
annotation_colors = anno_color,
color = rev(colorRampPalette(brewer.pal(11, "RdBu"))(1000)))
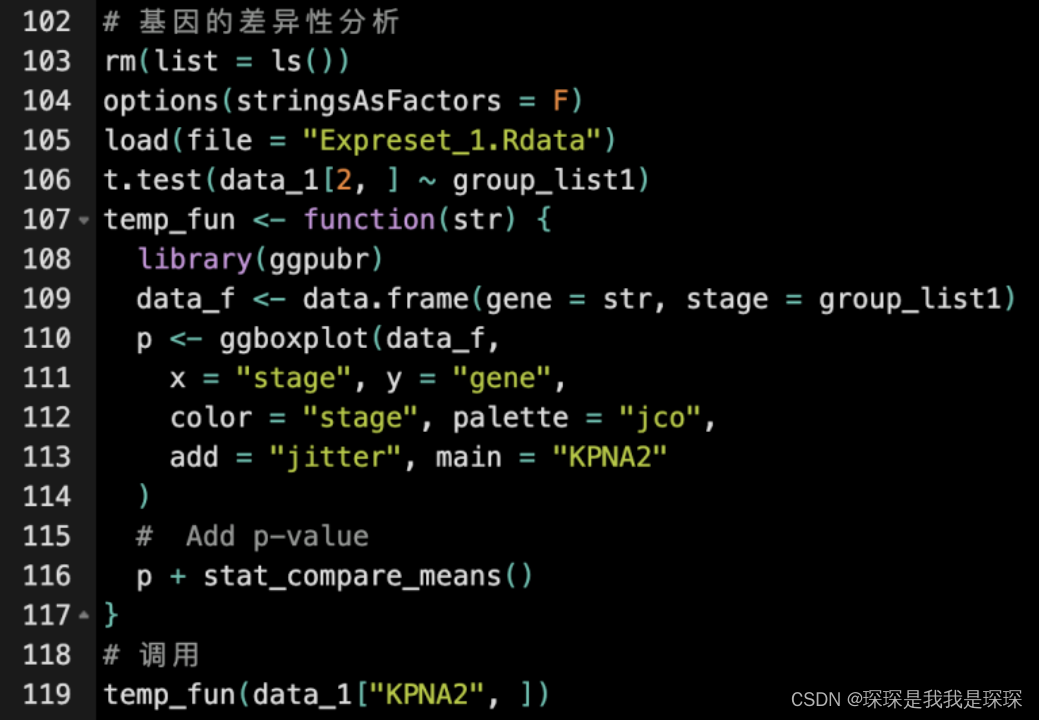
# 基因的差异性分析
rm(list = ls())
options(stringsAsFactors = F)
load(file = "Expreset_1.Rdata")
t.test(data_1[2, ] ~ group_list1)
temp_fun <- function(str) {
library(ggpubr)
data_f <- data.frame(gene = str, stage = group_list1)
p <- ggboxplot(data_f,
x = "stage", y = "gene",
color = "stage", palette = "jco",
add = "jitter"
)
# Add p-value
p + stat_compare_means()
}
# 调用
temp_fun(data_1["HAMP", ])