前言:
💞💞大家好,我是书生♡,今天的内容主要是Hadoop的后两个组件:MapReduce和yarn的相关内容。同时还有Hadoop的完整流程。希望对大家有所帮助。感谢大家关注点赞。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. MapReduce的概述
- 1.1 MapReduce的定义
- 1.2 MapReduce的两个阶段
- 1.3 MapReduce原理-案例
- 2. YARN概述
- 2. 1 Yarn的概念
- 3. YARN架构
- 3.1 Yarn架构
- 3.2 YARN容器
- 4. MapReduce & YARN 的部署
- 4.1 Yarn集群规划
- 4. 2 Yarn部署
- 4.3 查看YARN的WEB UI页面
- 5. MapReduce & YARN 初体验
- 5. 1 Yarn集群的启停
- 5.2 执行mapreduce任务
- 6. 历史服务器
1. MapReduce的概述
1.1 MapReduce的定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。

1.2 MapReduce的两个阶段
MapReduce是hadoop三大组件之一,是分布式计算组件,分为两个阶段:
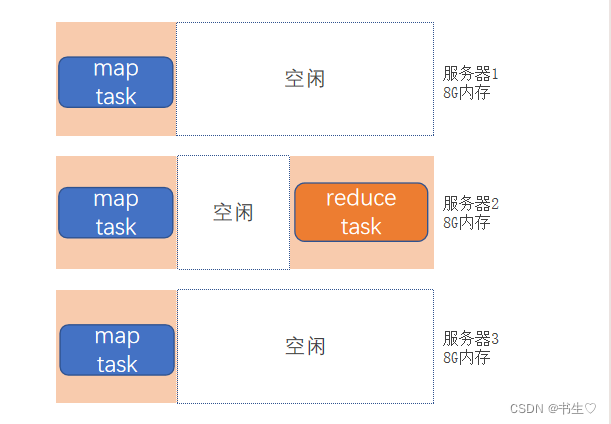
- Map阶段 : 将数据拆分到不同的服务器后执行Maptask任务,得到一个中间结果。
- Reduce阶段 : 将Maptask执行的结果进行汇总,按照Reducetask的计算 规则获得一个唯一的结果
MapReduce的核心思想是: 先分(Map)再和(Reduce)
分散->汇总模式:
- 将数据分片,多台服务器各自负责一部分数据处理
- 然后将各自的结果,进行汇总处理
- 最终得到想要的计算结果
1.3 MapReduce原理-案例
我们以一个案例来演示一下他的流程:
假设有如下文件,内部记录了许多的单词。且已经开发好了一个MapReduce程序,功能是统计每个单词出现的次数。
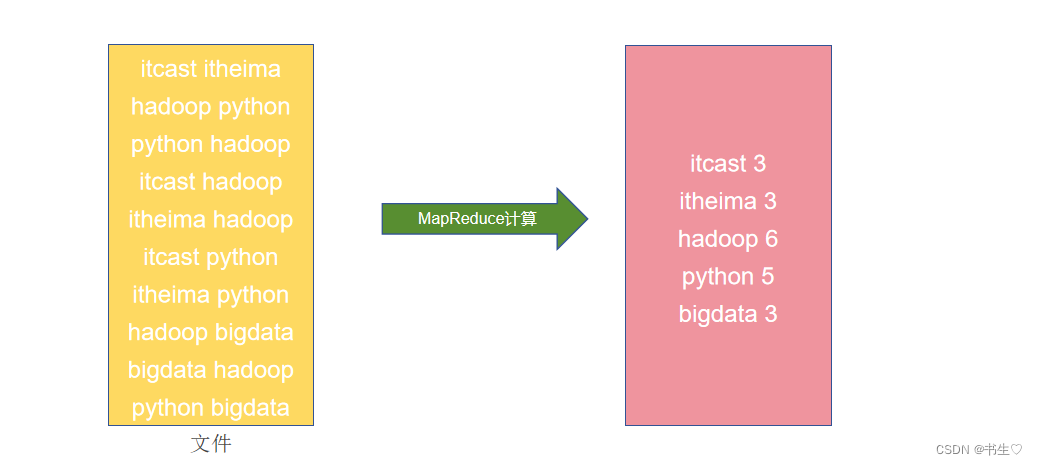
假定有4台服务器用以执行MapReduce任务,可以3台服务器执行Map,1台服务器执行Reduce
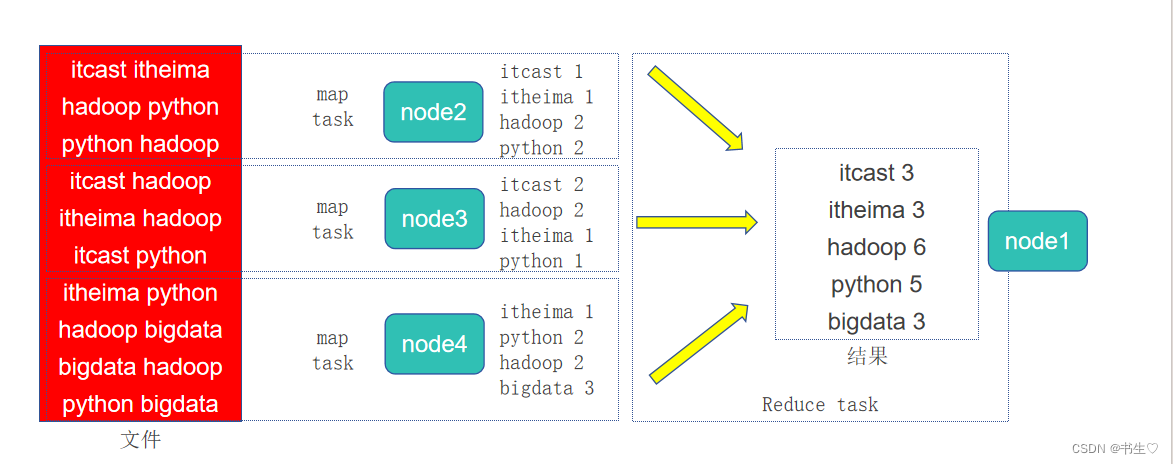
注意:
MapReduce可供Java、Python等语言开发计算程序
2. YARN概述
MapReduce是基于YARN运行的,即没有YARN”无法”运行MapReduce程序
2. 1 Yarn的概念
Yarn是Hadoop的分布式资源调度平台,负责为集群的运算提供运算资源。如果把分布式计算机和单个计算机相对应的话,HDFS就相当于计算机的文件系统,Yarn就是计算机的操作系统,MapReduce就是计算机上的应用程序。

yarn是一个分布式资源调度平台,主要是给MapReduce调度资源。
- 调度的有:cpu资源和内存资源
yarn中资源调度的目的是什么?
提高集群资源的利用率,防止部分程序恶意占用资源, 采用申请制,申请多少资源就使用多少资源
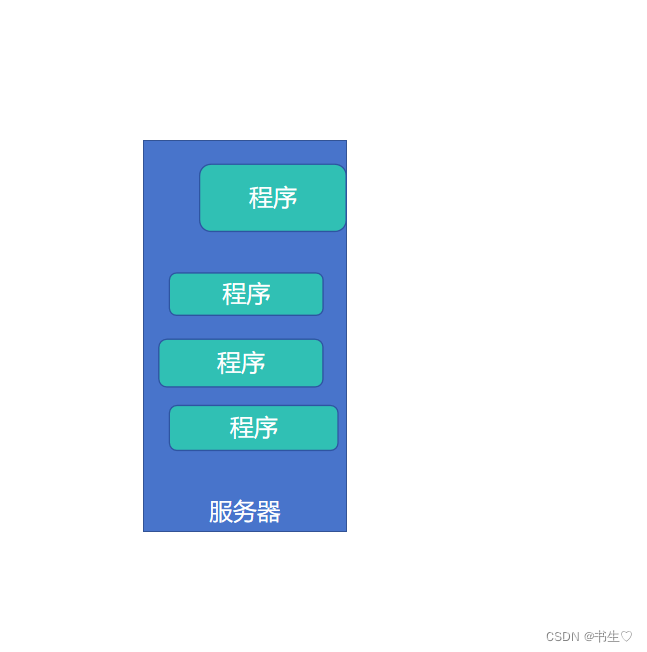
向YARN申请使用资源,YARN分配好资源后运行,空闲资源可供其它程序使用
程序向YARN申请所需资源
YARN为程序分配所需资源供程序使用
3. YARN架构
3.1 Yarn架构
Yarn既然是分布式那一定是一个标准的主从架构
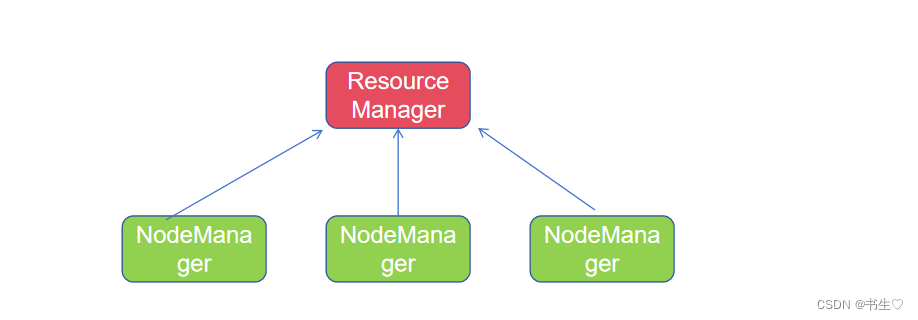
- 主角色ResourceManager: 统一管理和分配集群资源,监控每一个NodeManager的健康状况.
- 从角色NodeManager: 统计汇报集群资源给RM,当前服务器集群资源的使用和容器拆分.监督资源回收
YARN,主从架构,有2个角色
- 主(Master)角色:ResourceManager
- 从(Slave) 角色:NodeManager
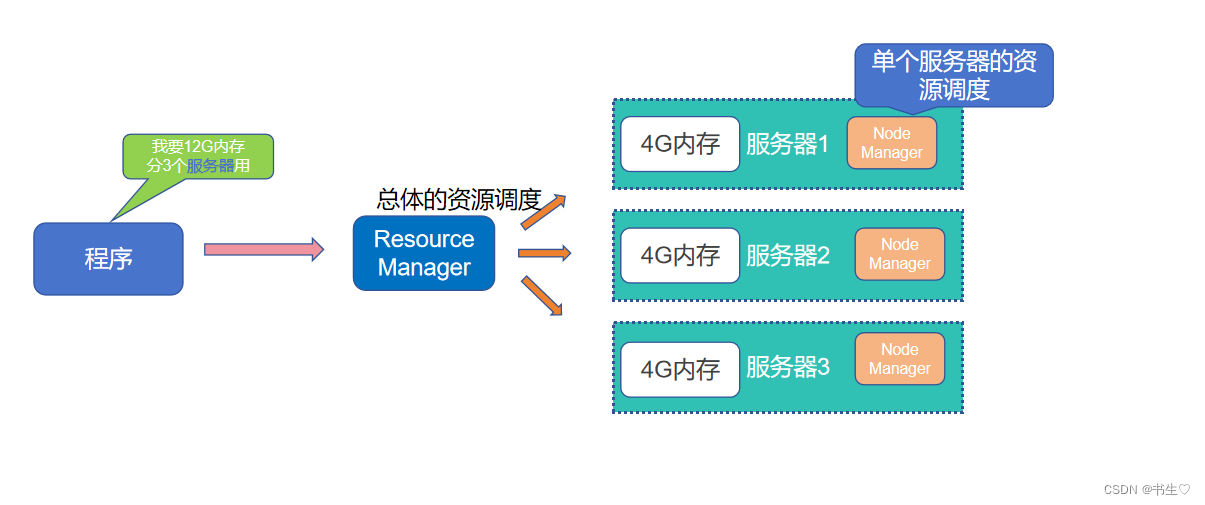
ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
3.2 YARN容器
我们要在服务器上分配资源,怎么才能准确的分配资源呢?
这个时候我们就要引入容器这个概念。
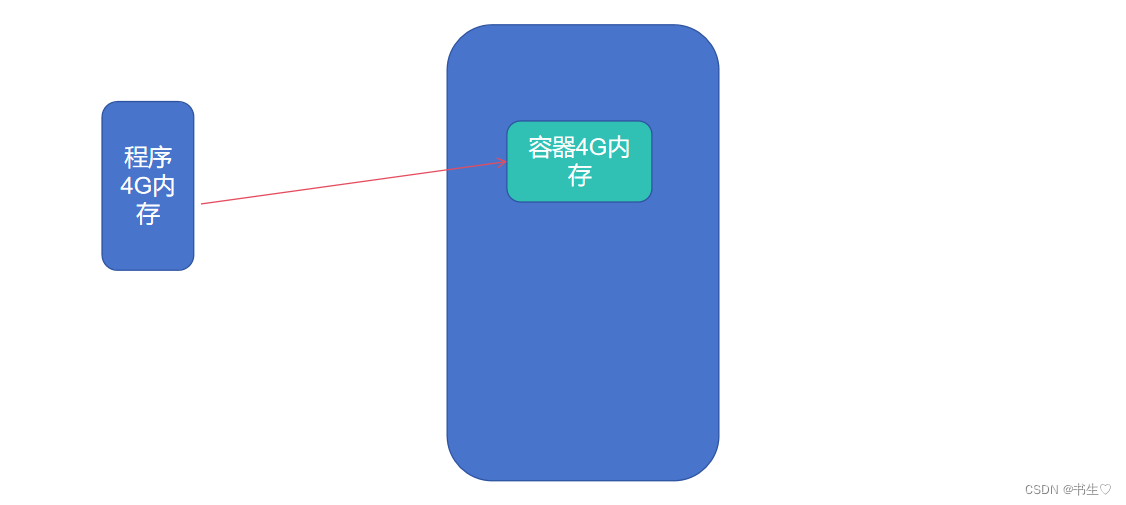
容器机制:容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
NodeManager,在程序没有执行时就预先抢占一部分资源划分为容器,等待服务进行使用
程序运行时先申请资源,RM分配资源后,由NodeManager划分出相应的资源支持程序运行
程序运行期间无法突破资源限制最多只能使用容器范围内的资源
容器资源分为: 内存资源和cpu资源
注意:
分配集群资源时,容器可以合并,但是不能拆分.
4. MapReduce & YARN 的部署
4.1 Yarn集群规划
YARN的集群规划
思考1: 哪一个角色占用资源最多??? ResourceManager
所以我们将RM放置在node1中,因为node1的服务器性能最好
思考2: hadoop中yarn集群可以和hdfs集群在同一台服务器中么?
可以,一般Hadoop服务部署时,hdfs和yarn逻辑上分离,物理上在一起.
yarn分配的是内存和cpu资源, 从而运行MapReduce计算任务,而该计算任务需要获取计算数据,计算数据存放在hdfs上,所以他们物理上在一起后数据传输速度快.
4. 2 Yarn部署
前提:Yarn的部署实在hdfs已经部署成功下完成的。
所以大家需要先去部署hdfs大家可以参考我的上一篇博客。
Hdfs的基础概念与部署🤞🤞🤞
- 先关闭HDFS集群
stop-dfs.sh
- 修改配置文件
先进入目录下进行修改
cd /export/server/hadoop/etc/hadoop
3.修改mapred-site.xml文件
大家主需要把我下面的代码直接复制过去就可以。
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 配置 yarn-site.xml文件
额外配置项的功能后续会慢慢接触到
目前先复制粘贴配置上使用即可
同理:直接复制
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 为MapReduce开启shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- NodeManager本地数据存储路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
</property>
<!-- NodeManager日志数据存储路径 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
- 修改完node1上的配置文件后,需要远程发送到node2和node3中
scp -r /export/server/hadoop root@node2:/export/server
scp -r /export/server/hadoop root@node3:/export/server
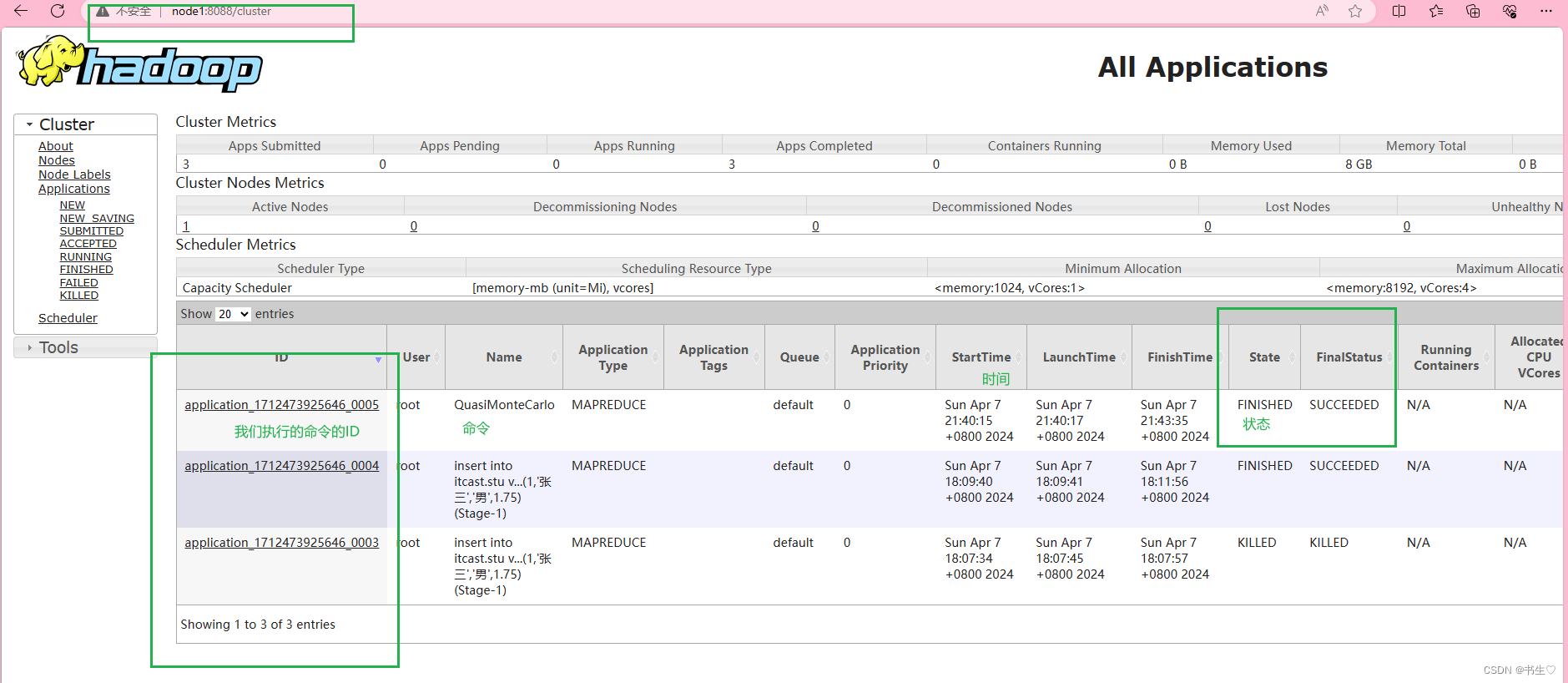
4.3 查看YARN的WEB UI页面
我们在配置完Yarn文件之后,通用端口号访问Yarn的页面
能进入到这个页面,说明我们的Yarn配置成功
node1:8088
5. MapReduce & YARN 初体验
我们这里就只是简单的了解一下怎么使用,具体的使用我们在后面会详细的说明。
5. 1 Yarn集群的启停
我们在之前学过hdfs的启停
- yarn和hdfs是一样的:通过start和stop
# 启动yarn集群
start-yarn.sh
# 停止yarn集群
stop-yarn.sh
- 当然我们也可以通过单启单停
yarn --daemon start|stop|status resourcemanager或者nodemanager
- 我们还可以直接全部启动所有的服务:一键自动hdfs和yarn集群
# 启动
start-all.sh
# 终止
stop-all.sh
5.2 执行mapreduce任务
保证服务启动且可以正常使用(yarn 和hdfs)
- 求Π
先进入到这个目录下
cd /export/server/hadoop/share/hadoop/mapreduce
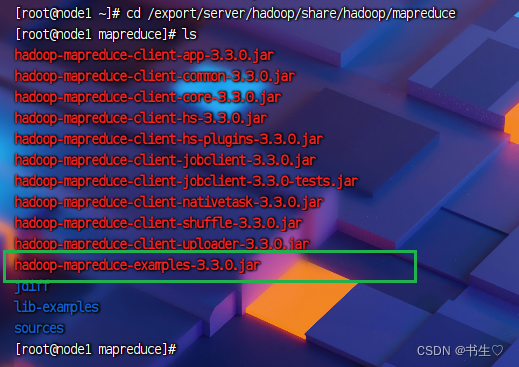
使用已经有的命令
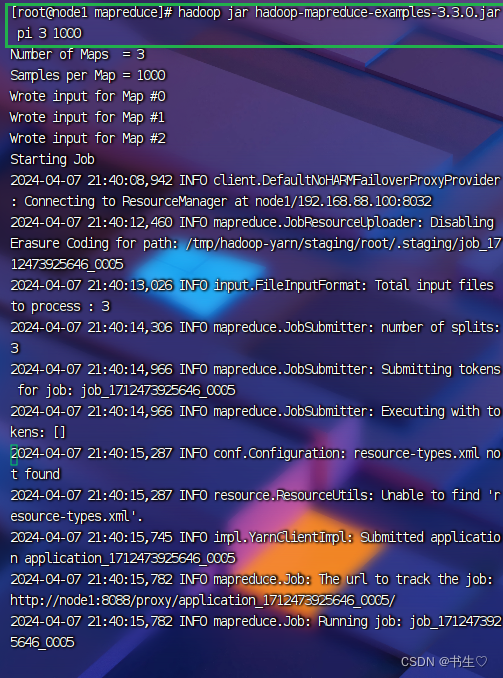
注意:这个命令是我们已经封装好的
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
2. 词频统计
# 1. 创建一个文件words.txt内部书写如下单词组合
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce
# 2. 创建输入和输出目录,并且将words文件上传到输入目录中
hadoop fs -mkdir -p /input/wordcount
hadoop fs -mkdir /output
hadoop fs -put words.txt /input/wordcount/
# 3. 执行示例
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount
hdfs://node1:8020/input/wordcount
hdfs://node1:8020/output/wc
# 注意: 输入目录必须存在,输出目录必须不存在,否则报错
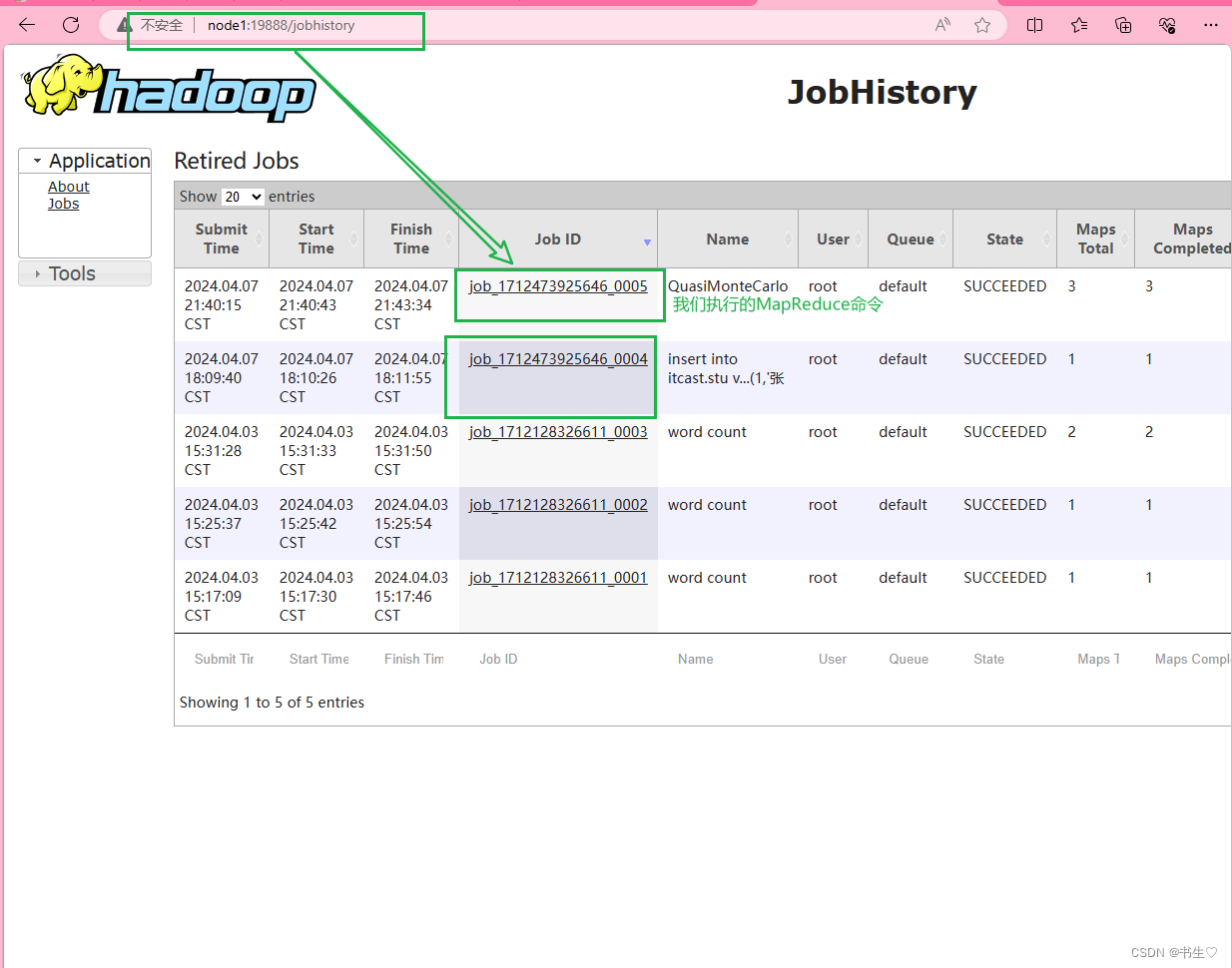
6. 历史服务器
历史服务器:主要是为了将各个NodeManager中零散的log日志聚集起来,存放到hdfs中,启动一个历史服务器,用来统一查看历史服务信息(计算任务的执行信息)
我们需要配置一下历史服务器:
cd /export/server/hadoop/etc/hadoop
yarn-site.xml文件
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
注意:修改完配置以后,一定要重启hadoop服务,否则无法生效
历史服务器启动
mapred --daemon start historyserver

我们直接通过端口号19888,通过浏览器访问
node1:19888