BERT(Bidirectional Encoder Representations from Transformers)模型是由Google在2018年提出的预训练Transformer模型,用于自然语言处理任务。
一. BERT模型的架构
1.1 输入表示 / Encoder模块
BERT中的Encoder模块是由三种Embedding(词嵌入)共同组成,如下图所示:
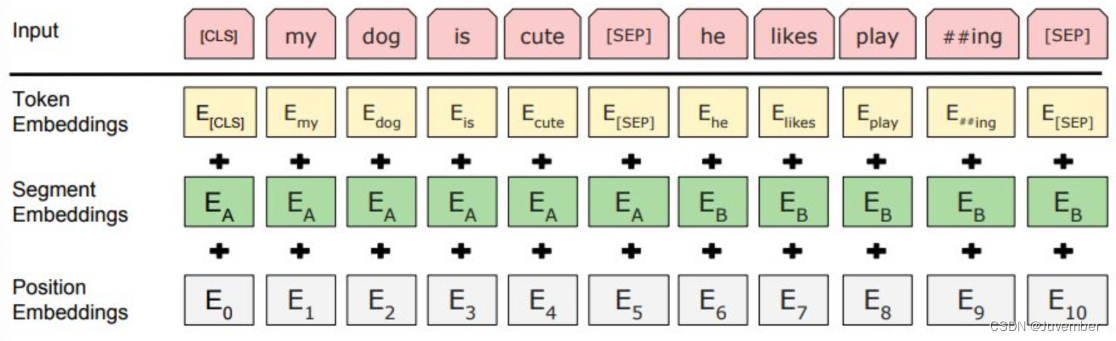
- Token Embeddings:词嵌入张量
- BERT首先将输入文本通过WordPiece或Subword Tokenization进行分词,每个分词(token)被映射到一个固定维度的词嵌入向量中,这样文本就被转化成了连续向量表示;
- 词嵌入张量的第一个单词是CLS标志, 可以用于之后的分类任务。
- Segment Embeddings:句子分段嵌入张量
- 对于序列对输入(如两个句子),BERT还包括段落嵌入(segment embeddings),用来区分两个不同的文本片段(如句子A和句子B);
- 用于服务后续的两个句子为输入的预训练任务(NSP)。
- Positional Embeddings:位置编码张量
- 由于Transformer结构本身不包含循环机制,无法直接感知顺序信息,因此BERT引入了位置嵌入(Positional Encodings),它们是与token嵌入相加的向量,用来编码每个token在序列中的位置信息;
- 和传统的Transformer不同,BERT模型的位置编码不是三角函数计算的固定位置编码,而是通过学习得出来的。
在BERT模型的训练过程中,位置嵌入会与其他的嵌入(如单词嵌入和段嵌入)一起被模型使用。当模型在处理一个单词时,它会参考该单词的位置嵌入,以理解这个单词在句子中的位置。然后,模型会根据这个位置信息以及其他嵌入信息,来预测被掩盖的单词或者判断两个句子是否连续(这就是BERT模型的两大与训练任务)。
在训练过程中,模型会根据其预测结果与实际标签的差异,计算出一个损失函数。然后,通过反向传播算法,模型会更新包括位置嵌入在内的所有参数,以最小化这个损失函数。这样,随着训练的进行,位置嵌入会逐渐学习到如何更好地表示单词在句子中的位置信息,从而提高模型在特定任务上的表现。
需要注意的是,由于BERT是一个预训练模型,其位置嵌入是在大量的无监督文本数据上学习得到的。因此,这些位置嵌入已经捕获了丰富的语言结构和位置信息,可以被直接用于各种下游任务,或者作为微调的基础。
1.2 双向Transformer模块

BERT中只使用了经典Transformer架构中的Encoder部分,并由多层Transformer Encoder堆叠而成,完全舍弃了Decoder部分。
每一层Transformer Encoder都包含以下部分:
- 多头注意力(Multi-Head Attention)机制,用于捕获词语间的双向依赖关系;
- 随后是一个前馈神经网络(Feed-Forward Network,FFN),通常包含两层线性变换和ReLU激活函数,负责对注意力机制输出的特征进行进一步的处理和转换;
- 规范化层(Layer Normalization)和残差连接层(Residual Connections)也是每一层的重要组成部分,用于稳定训练和提升性能;其中规范化层有助于加速模型的训练过程,并提高模型的稳定性,而残差连接则有助于缓解深度神经网络中的梯度消失问题,使模型能够更深入地学习文本的表示。
1.3 输出模块
经过中间层双向Transformer模块的处理后,BERT的最后一层可以根据任务的不同需求而做不同的调整。
而BERT预训练模型的输出一般主要包含以下两个部分:
- last_hidden_state:
这是模型的主要输出之一,形状为(batch_size, sequence_length, hidden_size),其中batch_size表示批处理样本的数量,sequence_length是输入序列的长度(包括特殊标记如[CLS]和[SEP]),而hidden_size是BERT模型的隐藏层维度(通常是768或更大,取决于具体的BERT变体)。这个输出代表了模型对输入序列中每个位置(token)的深度编码表示,它包含了从双向Transformer编码器中获取的上下文相关的语义信息。 - pooler_output:
形状为(batch_size, hidden_size),它是对整个输入序列的高层次抽象表示。具体而言,它是序列的第一个标记(通常是[CLS]标记,用于表示整个序列的语义)在最后一层Transformer编码器后的隐藏状态,并经过一个附加的线性层(有时带有softmax激活函数)进一步处理。这个输出常用于后续的分类任务,如情感分析或文本分类,作为整个序列的“聚合”表示。
二. BERT模型的两大预训练任务
正如在上文中提到的,BERT模型的两大预训练任务分别是:
- 遮蔽语言模型(Masked Language Model, MLM):BERT通过对输入序列中的某些token随机遮蔽,并要求模型预测这些遮蔽掉的部分,从而在无监督环境中学习语言模型的上下文表征能力。
- 下一句预测(Next Sentence Prediction, NSP):在预训练阶段,BERT还会接收两个句子输入,并判断它们是否是连续的上下文关系。这有助于模型捕捉句子间的关系。
这两个任务共同促使BERT去学习语言的内在规律和结构,从而在各种NLP任务上取得优异的性能。
三. BERT模型训练流程中的两个阶段
在BERT的训练过程中,包括以下两个步骤:
- 预训练 (Pre-training)
在这个阶段,BERT模型在大规模未标注文本数据上进行训练,通过两个自定义的预训练任务(如上所述的MLM和NSP)来学习通用的语言表示。这一阶段的目标是让模型掌握语言的基础知识和理解上下文的能力。 - 微调 (Fine-tuning)
在预训练完成后,BERT模型会被应用到具体的下游自然语言处理任务上,例如情感分析、问答系统等。此时,会在预训练好的BERT模型顶部添加特定于任务的输出层(比如分类层或序列标注层),然后使用有标签的特定任务数据对该模型进行微调。微调阶段会调整所有参数(包括预训练阶段学到的参数),使模型适应特定任务的需求。
所以,在实际应用中,BERT模型经历了从大量无标注数据学习通用语言表示(预训练)到针对性任务优化(微调)的过程。
四. BERT模型的优缺点
4.1 BERT的优点
- BERT的根基源于Transformer,相比传统RNN更加高效,可以并行化处理同时能捕捉长距离的语义和结构依赖;
- BERT采用了Transformer架构中的Encoder模块,不仅仅获得了真正意义上的bidirectional context(双向上下文信息),而且为后续微调任务留出了足够的调整空间。
4.2 BERT的缺点
- BERT模型过于庞大,参数太多,不利于资源紧张的应用场景,也不利于上线的实时处理;
- BERT目前给出的中文模型中,是以字为基本token单位的,很多需要词向量的应用无法直接使用。同时该模型无法识别很多生僻词,只能以UNK代替;
- BERT中第一个预训练任务MLM中,
[MASK]标记只在训练阶段出现,而在预测阶段不会出现,这就造成了一定的信息偏差,因此训练时不能过多的使用[MASK],否则会影响模型的表现; - 按照BERT的MLM任务中的约定,每个batch数据中只有15%的token参与了训练,被模型学习和预测,所以BERT收敛的速度比left-to-right模型要慢很多(left-to-right模型中每一个token都会参与训练)。
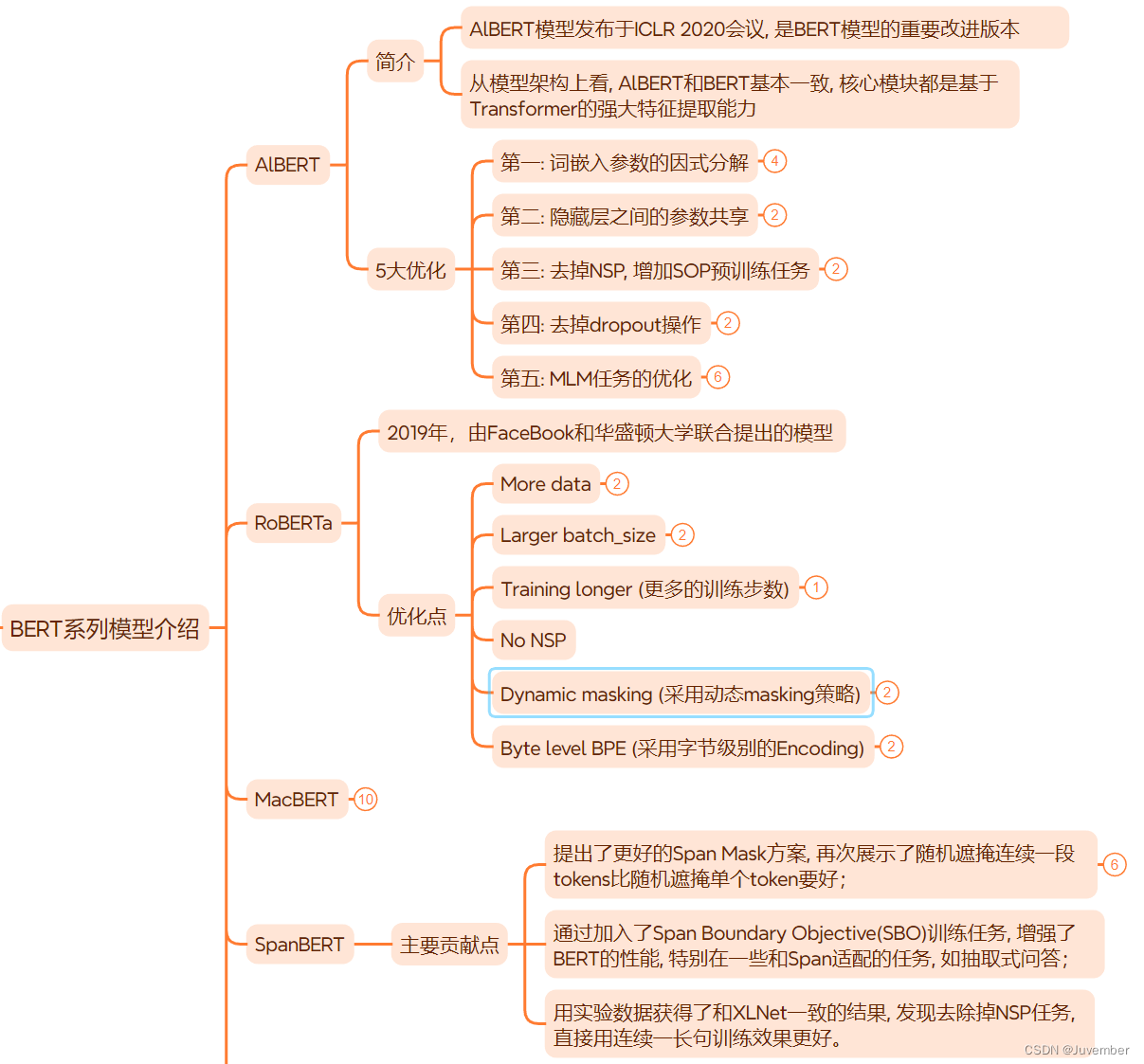
五. BERT系列模型简介(对BERT模型的优化)