突然想到了这个问题,网上搜集了一些资料,自己也总结一下
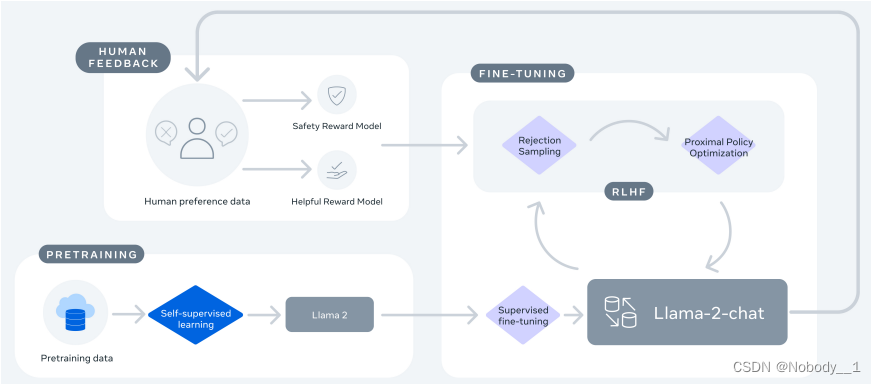
首先放一张llama2论文当中的图,可以很直观的看到区别
面试回答版
问题:
大语言模型base版和chat版的区别是什么?
回答:
base版本更适合文本补全、摘要、翻译和内容生成等任务,而chat版本适合多轮对话的任务。而base版有更强的泛化能力,chat版本是在base版本的基础上进行SFT和RLHF,有更好的对话能力和自然语言理解能力。实际业务环境中,需要根据业务和自身拥有的数据来进行选择。
追问:
我们在SFT的时候是在Base模型上训练还是在Chat模型上训练?
回答:
如果只有5k数据,可以在Chat模型上进行微调;如果有10w数据,可以在Base模型上进行微调。因为不知道Chat模型在SFT时具体的数据质量如何
这里的追问追答来自链接https://www.wehelpwin.com/article/4718
监督式微调(SFT):
这种方法使用标注过的数据集来微调模型。在对话模型的背景下,标注的数据可能是由人类评估员生成的高质量对话,目的是让模型学会产生这种高质量的响应。
基于人类反馈的强化学习(RLHF):
这种方法结合了几种技术,其中包括收集人类对模型生成内容的偏好,然后使用这些数据训练一个奖励模型,该模型可以判断模型输出的质量。然后,使用这个奖励模型指导强化学习过程,调整模型参数以更倾向于产生高质量的输出。
openai的回答
如果预测任务主要与对话系统或需要理解并生成自然语言对话相关,例如聊天机器人、虚拟助手或客户支持场景,那么选择经过特别优化用于处理对话的Chat版本可能更合适。Chat版本通常对上下文理解和维持对话连贯性进行了优化,从而能够提供更自然、流畅且符合对话习惯的回复。
相反,如果您的预测任务主要是基于文本的非对话型任务,如文本分类、实体识别、情感分析或其他类型的文本分析任务,Base版本可能是更好的选择。Base版本通常在更广泛的文本数据上训练,具备了处理多种自然语言处理任务的基础能力。
因此,总结一下关键考虑点:
任务类型:对话型任务选择Chat版本,非对话型任务选择Base版本。
数据类型:如果您的数据集主要是对话形式,选择Chat版本可能更有优势;如果是多种类型的文本,则Base版本更为适宜。
模型性能:考虑任务需求和性能指标选择最适合任务特点的版本。
目前来说,网上可以见到回答这个问题的网址如下,回答内容类似
- https://medium.com/@sujathamudadla1213/difference-between-large-language-models-llm-s-and-chat-models-3a3263194a8c
- https://blog.csdn.net/xieshaohu/article/details/136181775
- https://zhuanlan.zhihu.com/p/682970183