1 韦尔纳算法(Wellner Throsholding)
摘要
针对计算大量缺陷时速度较慢且图像阈值不平滑的Wellner算法,本文提出了两种改进方案,第一种是一维平滑算法(ODSA),第二种是基于第一种算法的,其名称为积分图像算法(IIA)。前者主要考虑像素之间的空间关系,以保证分割后像素的连续性;后者根据不同的环境动态设置局部阈值,避免局部全黑或全白,使物体与背景准确分离。通过对比实验,其结果表明,Wellner算法在图像处理的边缘不理想,时间复杂度过高。一维平滑算法在处理轮廓时清晰准确,但时间复杂度相对较大。当我们使用积分图像算法处理图像时,前景和背景分割清晰,错误率很低,时间复杂度最小,并且具有良好的场景适应能力,因此积分图像算法是最好的。
Abstract
According to the Wellner algorithm whose speed is slow and the image threshold is not smooth for computing a large amount of defects, this paper presents two kinds of improved scheme, the first scheme is onedimensional smoothing algorithm (ODSA), the second is based on the first one and its name is integral image algorithm( IIA). The former one mainly considering the spatial relationship between pixels, to ensure the continuity of pixels after segmentation; the latter dynamically set local threshold according to different environmental, to avoid local all black or all white, to separated object from the background exactly. Through the contrast experiment, its results show that, Wellner algorithm is not ideal at the edge of image processing, and the time complexity is too high. The one-dimensional smoothing algorithm is clear and accurate when processing contour, but the time complexity is relatively large. When we use the integral image algorithm to processing image, the foreground and background segmentation is clear, and the error rate is very low, and the time complexity is minimum, and it has good ability to adapt to the scene, so the integral image algorithm is the best.
Wellner自适应阈值二值化算法
1.问题的根源
现实:当使用相机拍摄一对黑白纸时,相机获得的图像不是真实的黑白图像。无论从哪个角度拍摄,图像实际上都是灰度或彩色的。除非仔细设置了照明,否则桌子上的相机拍摄的纸张图像不代表原始效果。与扫描仪或打印机不同,控制桌子表面的光源非常困难。这个开放空间可能会受到台灯、吊灯、窗户、移动阴影等的影响。人类视觉系统可以自动补偿这些,但机器没有考虑这些因素,因此结果会很差。
这个问题在处理高对比度线条艺术或文本时尤为突出,因为这些东西实际上是黑色或白色的。相机将生成不同级别的灰度图像。许多应用程序必须清楚地知道图像的哪个部分是纯黑色还是纯白色,以便将文本传递给OCR软件进行识别。这些系统不能使用灰度图像(通常每像素8位),因此必须将其转换为黑白图像。实现这一点有很多方法。在某些情况下,如果这些图像最终显示给人们,这些图像将使用一些抖动技术,使其看起来更像灰度图像。但是对于机器处理过程,例如文本识别、选择性复制操作或多重图像合成,系统不能使用抖动图像。该系统只需要简单的线条、文本或相对较大的黑白块。从灰度图像获得这种黑白图像的过程通常被称为阈值处理。
有很多方法可以对图像设置阈值,但基本的过程是检查每个灰度像素,然后决定它是白色还是黑色。本文描述了为图像设置阈值而开发的不同算法,然后提出了一种更合适的算法。这种算法(这里我们称之为快速自适应阈值方法)可能不是最合适的。但他很好地处理了我们描述的问题。
2.全局阈值方法
在某种程度上,阈值方法是对比度增强的一种极端形式,或者它使亮像素更亮,暗像素更暗。最简单(也是最常用的)方法是将图像中低于某个阈值的像素设置为黑色,其他像素设置为白色。那么问题是如何设置这个阈值。一种可能性是选择所有可能值的中间值,因此对于8位深度图像(范围从0到255),将选择128。当图像的黑色像素确实低于128而白色像素高于128时,该方法工作良好。但如果图像曝光过度或曝光不足,则图像可能是完全白色或完全黑色。因此,最好找到图像的实际值范围,而不是可能的值范围。首先找到最大值和最小值然后将中点作为阈值。选择阈值的更好方法是不仅查看图像的实际范围,还查看其分布。例如,如果您希望图像类似于白纸上的黑线绘制或文本效果,那么您希望大部分像素为背景色,小部分为黑色。像素的直方图如图1所示。
在上面的图像中,您可以找到背景色的大峰值和黑色墨水的小峰值。根据周围的光线,整个曲线可以向左或向右移动,但在任何情况下,理想的阈值都在两个峰值之间的谷处。这在理论上很好,但他在实践中表现如何?
图2及其直方图表明,整个技术运行良好。平滑直方图显示两个潜在峰值。通过拟合直方图曲线或简单地取两个峰值之间的平均值来计算近似理想阈值并不困难。这不是典型的图像,因为它有很多黑白像素。该算法还必须对如图3所示的图像设置阈值。在该图像的直方图中,较小的黑色峰值被掩埋在噪声中,因此不可能可靠地确定峰值之间的最小值。
在任何情况下,大的(背景)峰值总是存在的,并且很容易找到。因此,一种有用的阈值策略可以描述如下:
1) 计算直方图。
2) 根据一定的半径对直方图数据进行平滑,并计算平滑后的数据的最大值。平滑的目的是减少噪声对最大值的影响,如图2和图3所示。
3) 根据基于上述峰值和最小值之间的距离(不包括直方图中的零项)的特定比率来选择阈值。
实验表明,这个距离的一半可以在从非常亮到几乎完全黑的图像的广泛范围内产生非常好的结果。例如,在图3中,峰值为215,最小值为75,因此可以使用的阈值为145。图4显示了在不同照明条件下拍摄的四幅图像以及基于上述直方图技术的阈值处理后的效果。尽管私有服务器图像具有如此宽的照明范围(从直方图中可以看出),但算法选择了更合适的阈值,并且阈值处理后的图像基本相同。
这种基于直方图的全局阈值技术对于图像的光照条件均匀或光照变化很小的部分非常有效,如上所述。然而,在正常的办公室照明条件下,他无法获得令人满意的结果。因为对整个图像使用相同的阈值,所以图像的某些区域变得太白,而其他区域变得太暗。因此,大部分文本变得不可读,如图5所示。
需要一种自适应阈值算法来从不均匀照明的纸张图像中产生更好的二值图像。该技术根据每个像素的背景亮度来改变阈值。下面的讨论附有图5,首先展示了新算法的效果。这是一个具有挑战性的测试,因为图像边缘有一个光源,它在白色背景上有黑色文本(整个单词PaperWorks,在黑色背景上有白色文本(“XEROX”),在白色背景下有灰色文本(“最佳方式…”)。“PaperWorks”下也有不同的阴影和一条小的水平黑线。
3.自适应阈值
理想的自适应阈值算法应该能够产生具有不均匀照明的图像,类似于上述用于均匀照明图像的全局阈值算法。为了补偿或多或少的照明,在确定像素是黑色还是白色之前,需要对每个像素的亮度进行归一化。问题是如何确定每个点的背景亮度。一个简单的方法是在拍摄二进制图片之前先拍摄一张空白页。此空白页可用作参考图像。对于要处理的每个像素,将从中减去处理前的对应参考图像像素。
只要在拍摄参考图像和要处理的实际图像期间照明条件没有变化,这种方法可以产生非常好的结果,但是照明条件将受到人、台灯或其他移动物体的阴影的影响。如果房间有窗户,照明条件会随时间变化。一种解决方案是在同一位置和同一时间将空白页作为参考,但这不如使用扫描仪方便
另一种方法是通过对图像实际外观的一些假设来估计每个像素的背景亮度。例如,我们可以假设图像的大部分是背景(即白色),而黑色只是图像的一小部分。另一个假设是背景光变化相对缓慢。基于上述假设,许多算法是可行的。由于没有关于自适应阈值的数学理论,因此没有标准的或最佳的方法来实现它。相反,有一些特殊的方法比其他方法更常用。因为这些方法很特殊,所以衡量它们的性能很有用。为此,哈拉利克和夏皮罗提出了以下建议:该地区应与灰色色调统一;该区域的内部应该是简单的,没有太多的小孔;相邻区域应具有显著不同的值;每个部分的边缘也应简单,不应不均匀,并且在空间上准确。
根据普拉特的理论,对于图像二值化,没有提出定量的性能指标。似乎评估算法性能的主要方法是简单地查看结果,然后判断它是否良好。对于文本图像,有一种可行的量化方法:通过不同的二值化算法处理不同照明条件下的图片并将结果发送到OCR系统,然后将OCR识别结果与原始文本进行比较。
Wellner adaptive threshold binarization algorithm
1. The origin of the problem
A reality: When using a camera to shoot a pair of black and white paper, the image obtained by the camera is not a real black and white image. No matter what angle it is taken from, the image is actually grayscale or color. Unless the lighting is carefully set, the paper image taken by the camera on the table does not represent the original effect. Unlike inside a scanner or printer, it is very difficult to control the light source on the surface of the table. This open space may be affected by desk lamps, chandeliers, windows, moving shadows, etc. The human visual system can automatically compensate for these, but the machine does not take these factors into account, so the results will be poor.
This problem is particularly prominent when dealing with high-contrast line art or text, because these things are really black or white. The camera will produce a grayscale image with different levels. Many applications must clearly know which part of the image is pure black or pure white in order to pass the text to the OCR software for recognition. These systems cannot use grayscale images (typically 8 bits per pixel), so they must be converted to black and white images. There are many ways to achieve this. In some cases, if these images are ultimately shown to people, these images will use some dithering techniques to make them look more like grayscale images. But for machine processing processes, such as text recognition, selective copy operation, or multiple image synthesis, the system cannot use dithered images. The system only needs simple lines, text or relatively large blocks of black and white. The process of obtaining such a black and white image from a grayscale image is commonly referred to as thresholding.
There are many ways to threshold an image, but the basic process is to check every gray pixel and then decide whether it is white or black. This article describes the different algorithms that have been developed to threshold an image, and then proposes a more appropriate algorithm. This algorithm (here we call it fast adaptive threshold method) may not be the most suitable. But he handled the problem we described quite well.
2. the global threshold method
To some extent, the threshold method is an extreme form of contrast enhancement, or it makes bright pixels brighter and dark pixels darker. The simplest (and most commonly used) method is to set the pixels in the image below a certain threshold to black, and the others to white. Then the question is how to set this threshold. One possibility is to choose the middle value of all possible values, so for 8-bit deep images (ranging from 0 to 255), 128 will be selected. This method works well when the black pixels of the image are indeed below 128 and the white pixels are above 128. But if the image is over or underexposed, the image may be completely white or completely black. So it is better to find the actual value range of the image instead of the possible value range. First find the maximum and minimum values of all pixels in the image, and then take the midpoint as the threshold. A better way to select the threshold is to look at not only the actual range of the image, but also its distribution. For example, if you want an image to resemble a black line drawing or a text effect on white paper, then you expect most of the pixels to be the background color, and a small part to be black. The histogram of a pixel may be as shown in Figure 1.
In the image above, you can find a large peak of background color and a small peak of black ink. Depending on the surrounding light, the entire curve can be shifted to the left or right, but in any case, the ideal threshold is at the valley between the two peaks. This is good in theory, but how does he perform in practice?
Figure 2 and its histogram show that the whole technique works well. The smoothed histogram shows two potential peaks. It is not difficult to calculate an approximate ideal threshold by fitting the histogram curve or simply taking the average between the two peaks. This is not a typical image because it has a lot of black and white pixels. The algorithm must also threshold an image like Figure 3. In the histogram of this image, the smaller black peaks have been buried in the noise, so it is impossible to reliably determine a minimum value between the peaks.
In any case, a large (background) peak always exists and is easy to find. Therefore, a useful threshold strategy can be described as follows:
1) Calculate the histogram.
2) Smooth the histogram data according to a certain radius, and calculate the maximum value of the smoothed data. The purpose of smoothing is to reduce the influence of noise on the maximum value, as shown in Figure 2 and Figure 3.
3) The threshold is selected according to a certain ratio based on the distance between the above peak value and the minimum value (not including the zero item in the histogram).
Experiments show that half of this distance can produce quite good results for a wide range of images, from very bright to almost completely black images. For example, in Figure 3, the peak is at 215 and the minimum is 75, so the threshold that can be used is 145. Figure 4 shows four images captured under different lighting conditions and the effect after threshold processing based on the above-mentioned histogram technology. Although the private server image has this wide illumination range (as can be seen from the histogram), the algorithm has selected a more appropriate threshold, and the image after threshold processing is basically the same.
This histogram-based global thresholding technique works well for the part of the image where the light conditions are uniform or the light changes little as mentioned above. However, he could not obtain satisfactory results under normal office lighting conditions. Because the same threshold is used for the entire image, some areas of the image become too white and other areas are too dark. Therefore, most of the text becomes unreadable, as shown in Figure 5.
An adaptive threshold algorithm is needed to produce a better binary image from the unevenly illuminated paper image. This technique changes the threshold according to the background brightness of each pixel. The following discussion is accompanied by Figure 5 to show the effect of the new algorithm first. This is a challenging test because there is a light source at the edge of the image, and it has black text on a white background (the entire word PaperWorks, and white text on a black background ("XEROX")), and gray text on a white background ("The best way...") There are also different shadows and a small horizontal black line under the word "PaperWorks".
3.adaptive thresholds
An ideal adaptive threshold algorithm should be able to produce images with uneven illumination similar to the above-mentioned global threshold algorithm for uniform illumination images. In order to compensate for more or less illumination, the brightness of each pixel needs to be normalized before it can be determined whether a pixel is black or white. The problem is how to determine the background brightness of each point. A simple way is to take a blank page before taking a binary picture. This blank page can be used as a reference image. For each pixel to be processed, the corresponding reference image pixel before processing will be subtracted from it.
As long as there is no change in the lighting conditions during the shooting of the reference image and the actual image to be processed, this method can produce very good results, but the lighting conditions will be affected by the shadows of people, desk lamps or other moving objects. If the room has windows, the lighting conditions will change over time. One solution is to take a blank page at the same location and at the same time as a reference, but this is not as convenient as using a scanner
Another way is to estimate the background brightness of each pixel through some assumptions about what the image should actually look like. For example, we can assume that most of the image is background (that is, white), and black is only a small part of the image. Another assumption is that the background light changes relatively slowly. Based on the above assumptions, many algorithms are feasible. Since there is no mathematical theory about adaptive thresholds, there is no standard or optimal way to achieve it. Instead, there are some special methods that are more used than others. Because these methods are special, it is useful to measure their performance. For this reason, Haralick and Shapiro put forward the following suggestions: the area should be unified with the gray tone; the interior of the area should be simple without too many small holes; the adjacent areas should have significantly different values; the edges of each part should also be simple , Should not be uneven, and be accurate in space.
According to Pratt's theory, for image binarization, no quantitative performance indicators have been proposed. It seems that the main way to evaluate the performance of an algorithm is to simply look at the results and then judge whether it is good. For text images, there is a feasible quantification method: the pictures under different lighting conditions are processed by different binarization algorithms and the results are sent to the OCR system, and then the OCR recognition results are compared with the original text. Although this method may be useful, it cannot be used in the algorithm described below because it is impossible to give a standard that looks good. For some interactive applications, such as copy and paste operations, users must wait until the binary processing. So another important indicator is speed. The following sections present different adaptive threshold algorithms and their results.
4. Adaptive threshold based on Wall algorithm
The description of the algorithm for dynamically calculating the threshold based on the background brightness developed by RJ Wall can be found in "Castleman, K. Digital Image Processing. Prentice-Hall Signal Pro-cessing Series, 1979.". The following description is basically based on his thesis. 1. divide the image into smaller blocks, and then calculate the histogram of each block separately. Based on the peak value of each histogram, the threshold is then calculated for each block. Then, the threshold of each pixel is obtained by interpolation according to the threshold of adjacent blocks. Figure 6 is the result of processing Figure 5 with this algorithm.
This image is divided into 9 blocks (3*3), and the threshold of each block is selected to be 20% lower than the peak value. This result is better than the global threshold, but it has a large amount of calculation and slow speed. Another problem is that for some images, the local histogram may be deceived by a large number of black or white points, causing the threshold to not change smoothly in the entire image. The result may be very bad, as shown in Figure 7.
5. fast adaptive threshold
Most of the algorithms documented in the literature are more complex than the Wall algorithm and therefore require more running time. It is feasible to develop a simple and faster adaptive threshold algorithm, so let us introduce the related theory.
The basic thinking of the algorithm is to traverse the image and calculate a moving average. If a pixel is significantly lower than this average value, it is set to black, otherwise it is set to white. Only one traversal is enough, and it is also very simple to use hardware to implement the algorithm. It is interesting to note the similarity between the following algorithm and the algorithm implemented in hardware by IBM in 1968.
Assume that Pn is the pixel at point n in the image. At this moment, we assume that the image is a single row connected by all rows in sequence. This leads to some exceptions at the beginning of each line, but this exception is smaller than starting from zero for each line.
Suppose f s (n) is the sum of the last s pixels at point n:
The final image T(n) is 1 (black) or 0 (white) depending on whether it is darker than the average value of the first s pixels.
Using 1/8 of the image width for s and a value of 15 for t seems to produce better results for different images. Figure 8 shows the result of scanning rows from left to right using this algorithm.
Figure 9 is the result of processing from right to left using the same algorithm. Note that in this image, the smaller text on the far left is incomplete. There are also more holes in the character PaperWorks. Similarly, the black edge on the far right is much narrower. This is mainly because the background light source of the image gradually darkens from left to right.
Another problem is how to start the algorithm, or how to calculate g(0). One possibility is to use s*p0, but because of the edge effect, P 0 is not a typical value. So another possibility is 127*s (based on the median of 8-bit images). In any case, these two schemes will only affect a small part of the value of g. When calculating g s (n), the weight of g(0) is:
Therefore, if s=10, then for any n>6, the contribution of g(0) is less than 10% of g 10 (n), and for n>22, the contribution of g(0) is less than 1%. For s=100, the share of g(0) is less than 10% after 8 pixels, and less than 1% after 68 pixels.
It should be better if the average value is not calculated from one direction. Figure 12 shows the effect of using another method to calculate the average value. This method replaces the average value in a certain direction by calculating the average value of pixels on both sides of the symmetry of point n. At this time, the definition of f(n) is as follows:
Another alternative is to calculate the average from left to right and from right to left alternately, as shown below:
This effect is not much different from the center average.
A small modification may have a better effect on most images, that is to keep the average effect of the previous line (in the opposite direction to the current line), and then take the average value of the current line and the average value of the previous line Average as the new average, that is, use:
This makes the calculation of the threshold consider the information in the vertical direction, and the result is shown in the figure:
Please pay attention to the effect of his segmentation of characters. This is also one of the few algorithms that retains the horizontal line under PaperWorks.
Part of the original text is now unreasonable and has not been translated.
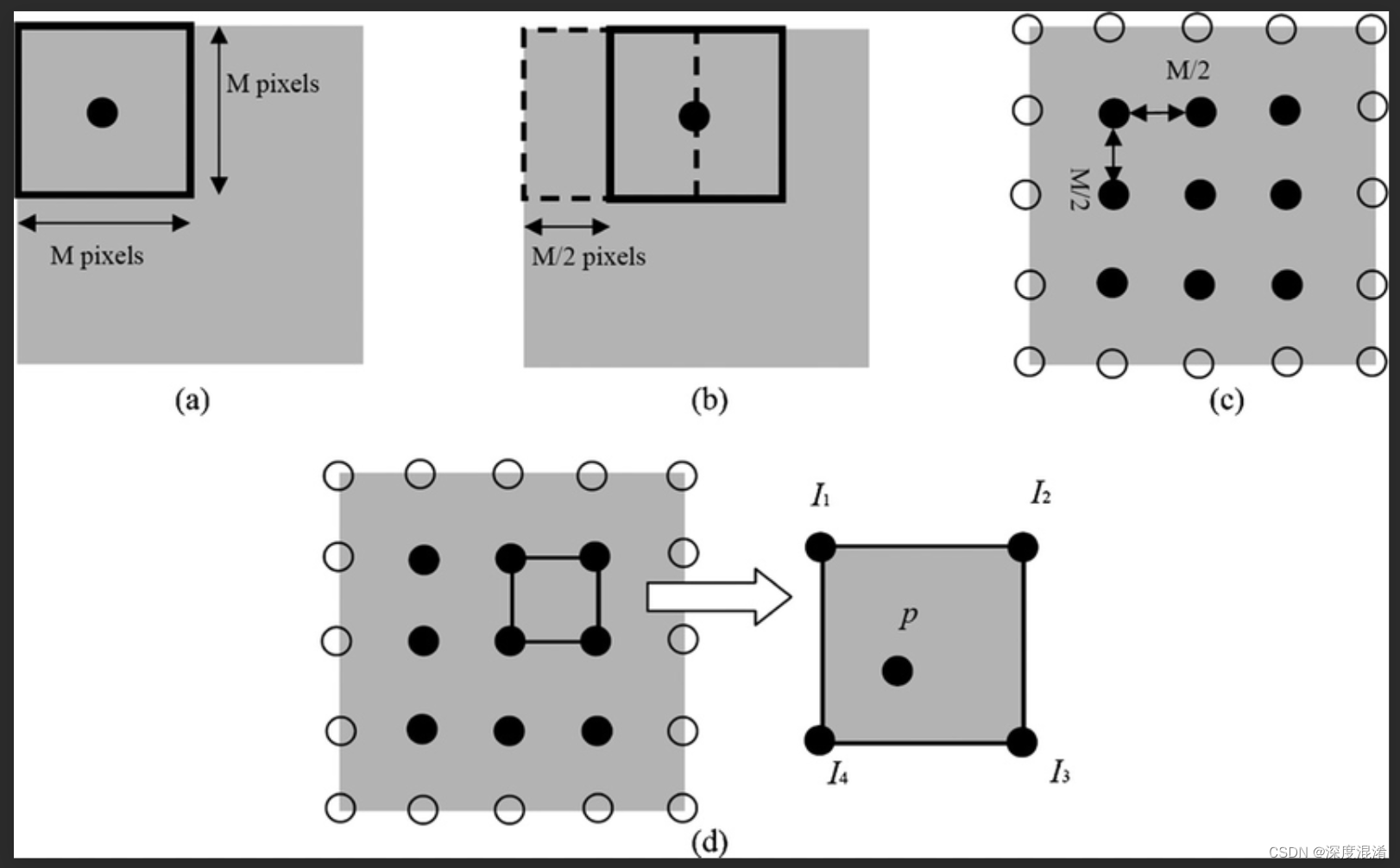
Judging from the above, Wellner's adaptive filtering threshold is actually one-dimensional smoothing of pixels with a specified radius, and then comparing the original pixel with the smoothed value to determine whether it is black or white. A large part of the article is devoted to discussing the direction of the pixels sampled, whether it is completely on the left, completely on the right or symmetrical, or considering the effect of the previous row. However, in general, he only considered the effect of pixels in the row direction on smoothing. Later, Derek Bradley and Gerhard Roth proposed in their paper Adaptive Thresholding Using the Integral Image a two-dimensional smoothing value of a rectangular area with W*W as a template instead of one-dimensional weighting. Thus putting aside the one-dimensional smooth directionality problem.
Of course, they proposed a 0(1) time complexity algorithm for two-dimensional smoothing, which is actually very simple, that is, first calculate the accumulation table of the entire image. Then loop again to get the accumulated value centered on a certain pixel by adding and subtracting the order.

2 局部阈值的韦尔纳算法(Wellner Throsholding)的C#源代码
二值算法综述请阅读:
C#,图像二值化(01)——二值化算法综述与二十三种算法目录

https://blog.csdn.net/beijinghorn/article/details/128425225?spm=1001.2014.3001.5502
支持函数请阅读:
C#,图像二值化(02)——用于图像二值化处理的一些基本图像处理函数之C#源代码

https://blog.csdn.net/beijinghorn/article/details/128425984?spm=1001.2014.3001.5502
namespace Legalsoft.Truffer.ImageTools
{
public static partial class BinarizationHelper
{
#region 灰度图像二值化 局部算法 Wellner 算法
/// <summary>
/// Wellner 自适应阈值二值化算法
/// https://www.cnblogs.com/Imageshop/archive/2013/04/22/3036127.html
/// </summary>
/// <param name="data"></param>
/// <param name="radius"></param>
/// <param name="threshold"></param>
public static void Wellner_Adaptive_Algorithm(byte[,] data, int radius = 5, int threshold = 50)
{
int width = data.GetLength(1);
int height = data.GetLength(0);
int InvertThreshold = 100 - threshold;
double[,] Integral = new double[height, width];
byte[,] dump = (byte[,])data.Clone();
for (int y = 0; y < height; y++)
{
double sum = 0;
for (int x = 0; x < width; x++)
{
sum += dump[y, x];
Integral[y, x] = (y == 0) ? sum : Integral[(y - 1), x] + sum;
}
}
for (int y = 0; y < height; y++)
{
int Y1 = Math.Max(0, y - radius);
int Y2 = Math.Min(height - 1, y + radius);
int Y2Y1 = (Y2 - Y1) * 100;
for (int x = 0; x < width; x++)
{
int X1 = Math.Max(0, x - radius);
int X2 = Math.Min(width - 1, x + radius);
double sum = Integral[Y2, X2] - Integral[Y1, X2] - Integral[Y2, X1] + Integral[Y1, X1];
if ((dump[y, x] * (X2 - X1) * Y2Y1) < (sum * InvertThreshold))
{
data[y, x] = 0;
}
else
{
data[y, x] = 255;
}
}
}
}
#endregion
}
}
3 局部阈值的韦尔纳算法(Wellner Throsholding)计算效果

POWER BY 315SOFT.COM AND TRUFFER.CN
:-)