背景
在搜索推荐系统里,有一个重要的服务是向量检索服务,也就是求向量在空间中最相近的topk个向量,在搜索系统里,涉及大量的召回引擎可能需要用到向量检索服务,需要在线实时计算,并且可快速响应;
所以这里需要解决两个问题,一个是存储所有待计算的向量,并对输入的向量,做向量相似度计算,求得最近的向量列表排序,取得top k个;另一个因为要达到在线服务即时响应需求,因为这个是基础服务,所以要做到毫秒级别响应
解决方案&迭代演进
1、最粗暴的向量KNN计算
对输入的向量,遍历待计算的所有向量做相似度计算,再用有限容量K最大堆排序,取得最后topk向量;
优点是:算法实现简单,服务维护成本低;针对向量数量小的,在万级别的情况下,也可以达到毫秒级响应;
缺点:面向十万级别以上向量,每一次的请求计算量一样,都要做全量计算,计算代价太大,响应性能不能满足;

2、引入HNSW java开源算法库
对向量做索引,主要索引存储在内存里,提高响应速度,针对大数据量的向量可快速响应;
优点:直接用java服务开发管理向量,向量的更新管理,直接内嵌在服务里,不需要再增加多一层请求服务。管理简单,实现成本 也不高;
存在风险问题: 因为索引放在内存里,要占用比较多的内存资源 ,特别是数据量较大的情况下,内存占用太大,400W左右的数据量大概占用10G左右;
索引更新,直接在线上构建,占用cpu使用,索引更换过程时,需要双倍内存资源,更新索引时候容易发生fullgc,导致其它响应问题;

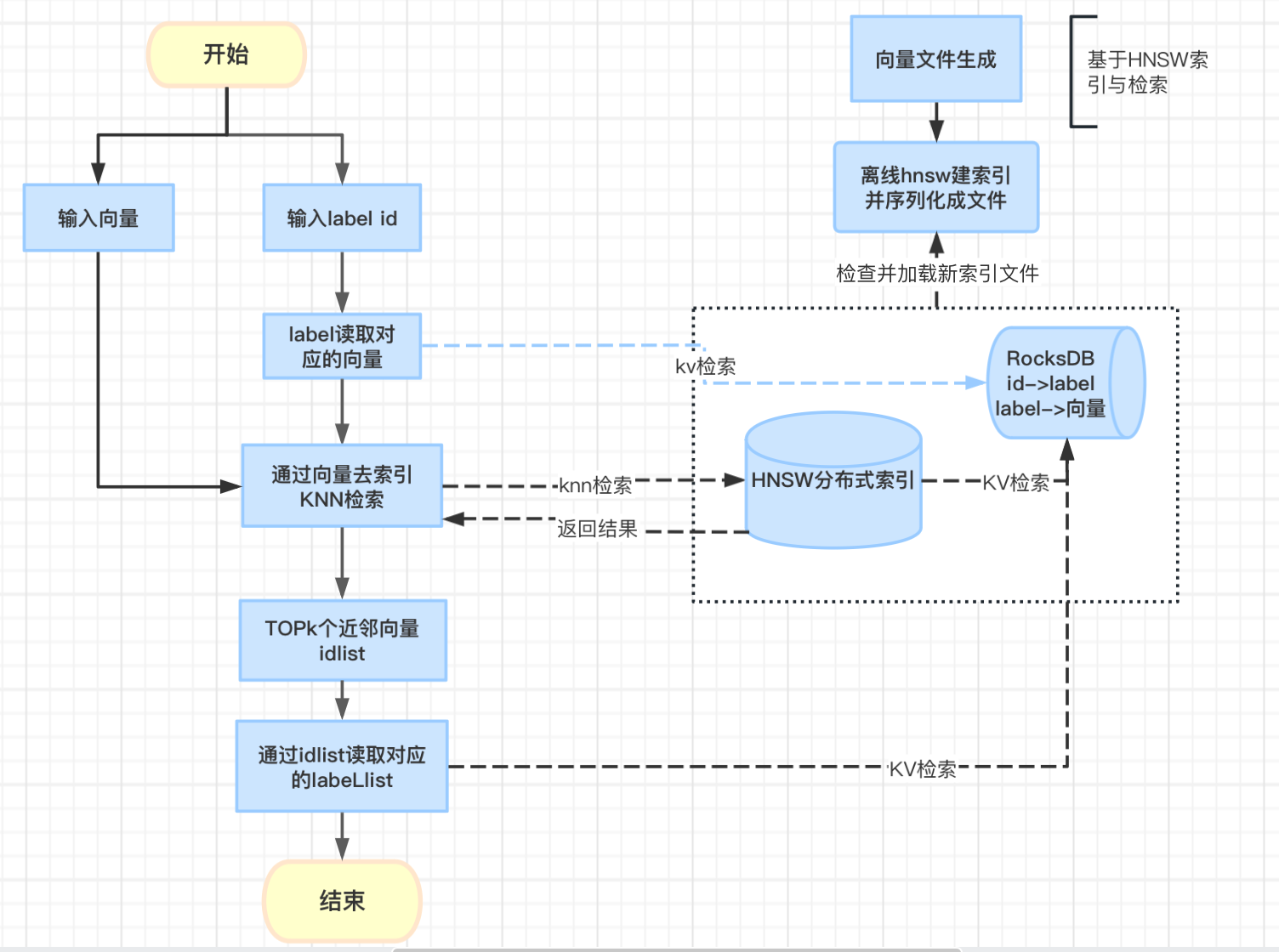
3、引用hnsw c++开源算法库,离线索引&分布式索引构建
采用c++实现库索引则使用了堆外内存,减少gc,并且利用c++对密集计算性能的优势,提高响应性能;
针对大数据量向量,拆分多分片,除了支持更大数据量,增加并行计算提高响应速度;
索引也会先在离线建完,序列化持久到文件,线上直接加载索引文件反序列化再提供服务;
更新索引虽然占用双倍内存,但使用堆外内存,避免引起FULLGC风险问题,只要机器预留一定的内存资源足以;
分布式索引,支撑索引数据量是单机n倍,并提高并行计算,提高响应性能;
存在的问题点:
分布式管理 会比原有单点管理 复杂性变大,系统的开发成本与维护成本 也会相应增加;
现有的hnsw实现里有两块占用比较大内存,label 与内部id映射,向量的存储。可考虑转移到外存,减少内存消耗;

4. 基于第3种方案,再优化了一版,修改了hnsw源码,将id->vector , label->id对应的数据结构移到外存上,减少依赖的内存资源;
优化点:比前一版,可以将部分内存资源转移到外存,减少资源成本 ;
存在问题点: 修改了源生代码 ,并且多了一个RocksDB外存管理 ,整体依赖的技术栈也增加,复杂度也会因此增加。
未来展望
hnsw索引目前遇到一个相似度计算问题,不能比较好支持点乘相似度计算,所以还是得再换用fasis,它支持比较多种类型的索引,以及相似度计算也支持比较多类,比较能满足需求;可以在现有的架构上,改用fasis接入替换hnsw;