文章目录
- 博客详细讲解视频
- 点击查看高清脑图
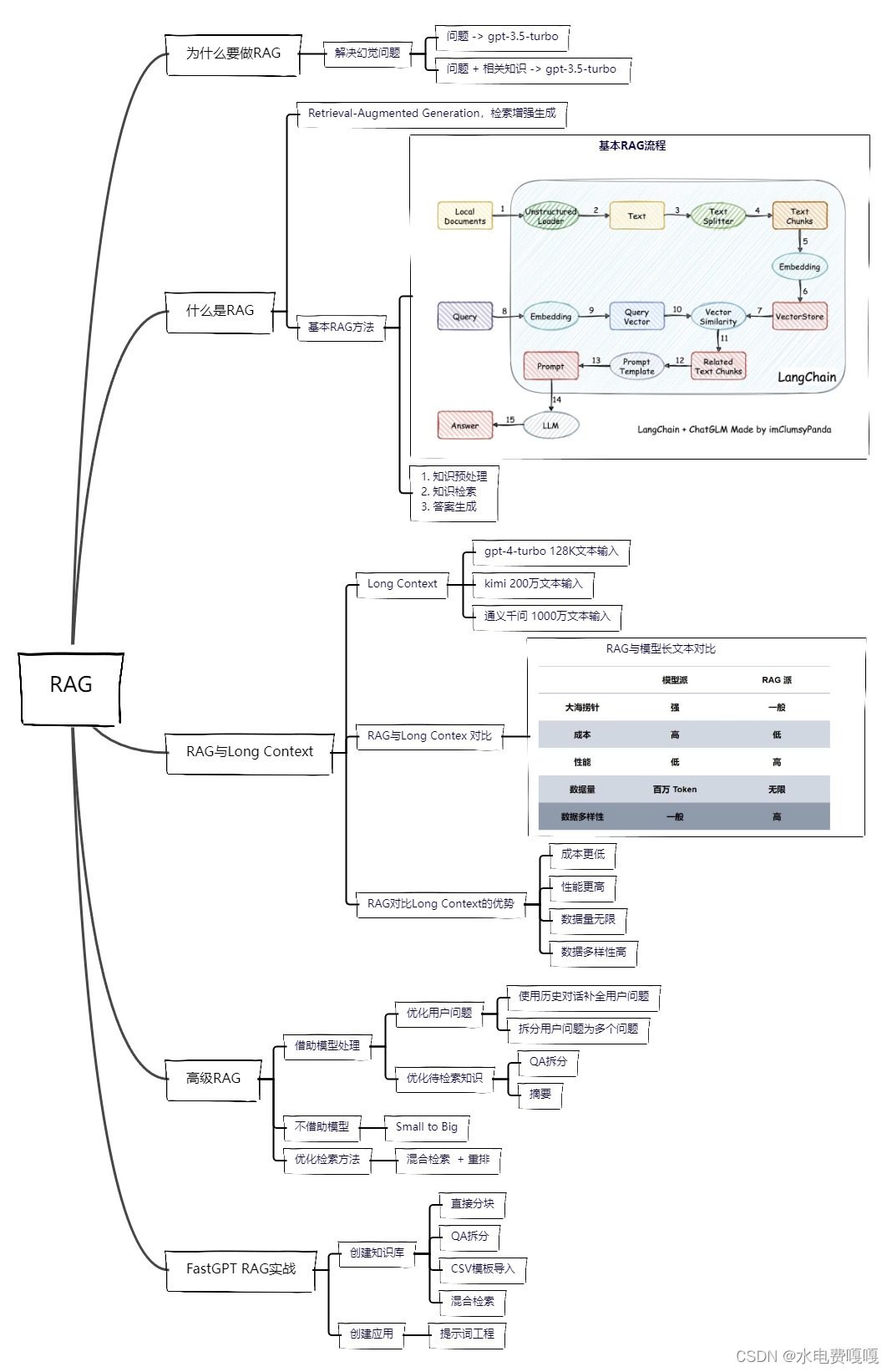
- 1.为什么要做RAG
- 1.1. 解决幻觉问题
- 1.1.1 直接输入问题
- 1.1.2. 问题 + 相关知识
- 2. 什么是RAG
- 2.1. 基本概念
- 2.2. 基本RAG方法
- 2.2.1. 知识预处理
- 2.2.2. 知识检索
- 2.2.3. 答案生成
- 3. RAG 与 Long Context
- 3.1. Long Context
- 3.2. RAG 与Long Context
- 3.3 RAG对比Long Context的优势
- 4. 高级RAG
- 4.1. 借助模型处理
- 4.1.1. 优化用户问题
- 4.1.2. 优化待检索知识
- 4.2. 不借助模型
- 4.2.1 Small to Big
- 4.3. 优化检索方法
- 4.3.1 混合检索
- 向量检索的优势
- 向量检索的劣势
- 关键词搜索的优势
- 4.3.2. 重排
- RRF (Reciprocal Rank Fusion, 倒数排序融合)
- ReRank 模型
- 5. FastGPT RAG实战
- 5.1. 创建知识库
- 5.1.1. 直接分块
- 5.1.2. QA拆分
- 5.1.3. CSV 模板文件导入
- 5.1.4. 混合检索
- 5.2. 创建应用
- 5.2.1. 提示词工程
博客详细讲解视频
点击查看高清脑图
1.为什么要做RAG
1.1. 解决幻觉问题
1.1.1 直接输入问题
小米汽车的型号
1.1.2. 问题 + 相关知识
请把引号内的内容作为你的知识
"3月28日晚7点,在小米汽车发布上,小米集团董事长雷军宣布,小米SU7正式发布,标准版售价21.59万元,雷军表示,这个价格小米是亏钱的; 小米SU7 Pro 版(后驱超长续航高阶智驾版)售价24.59万元; 小米SU7 Max版 (高性能四驱超长续航高阶智驾版)售价29.99万元。"
我的问题是:小米汽车的型号
2. 什么是RAG
2.1. 基本概念
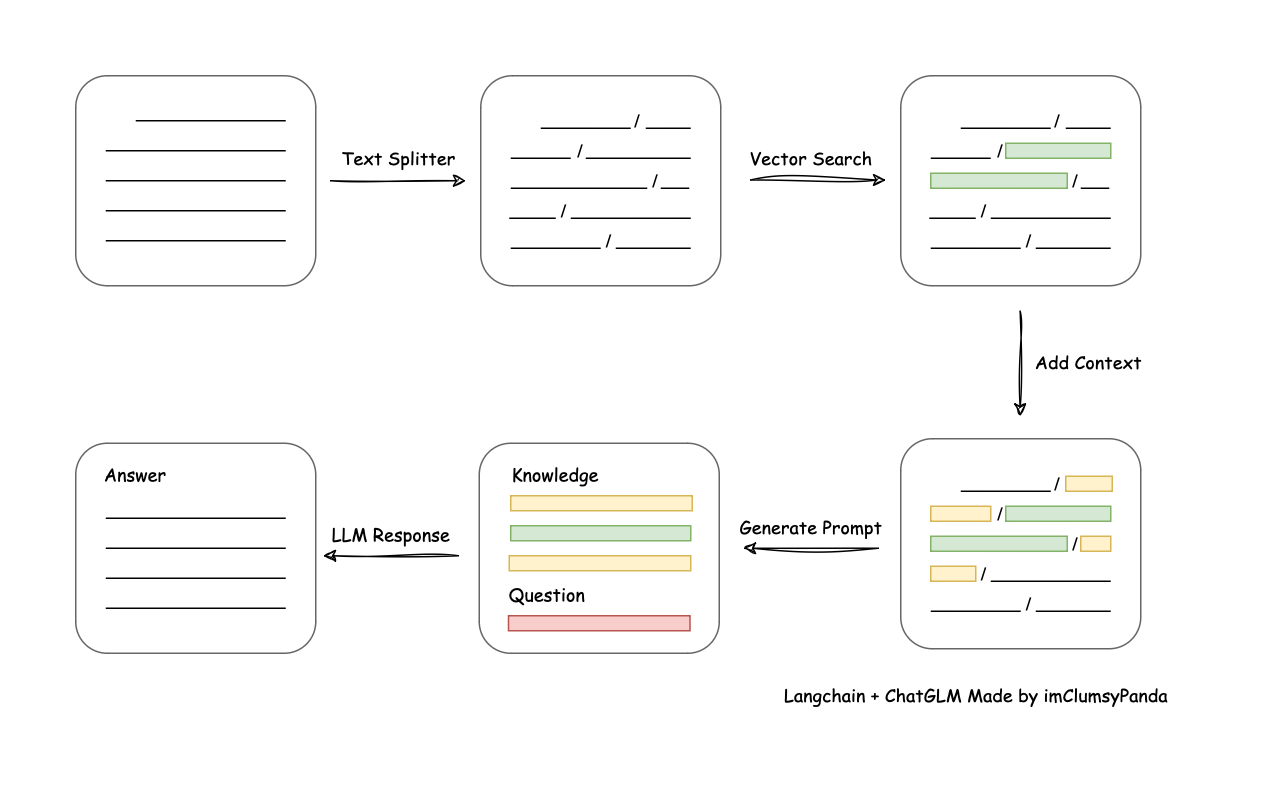
- Retrieval-Augmented Generation,检索增强生成
- 把"问题 + 相关知识"一起输入到模型,模型根据相关知识生成答案,避免幻觉
2.2. 基本RAG方法

2.2.1. 知识预处理
- 解析知识库文件为文本,例如pdf、word、xlsx、txt
- 长文本分割为文本块
- 文本块转为语义向量 egg:[0.1234, 0.221, …, 0.1552] 768, 1024, 1536
- 保存语义向量到向量数据库
测试语义相关度
几岁了 & 今年多大了
2.2.2. 知识检索
- 用户问题转为语义向量
- 向量搜索: 计算余弦相似度,即向量内积 [0.1234, 0.221, …, 0.1552] · [0.2, 0.3, …, 0.2] = 0.1234 * 0.2 + 0.221 * 0.3 + … + 0.1552 * 0.2 = x . x∈[0, 1]
- 筛选出topK 或 余弦相似度 大于某个阈值的文本块
2.2.3. 答案生成
- 使用提示词模板组合问题与相关知识
请把引号内的内容作为你的知识
"{{knowledge}}"
我的问题: {{question}}
- 发送给大模型得到答案
3. RAG 与 Long Context
3.1. Long Context
超长文本输入
- gpt-4-turbo 128K文本输入
- kimi 200万文本输
- 通义千问 1000万文本输入
3.2. RAG 与Long Context
3.3 RAG对比Long Context的优势
- 成本更低
- 性能更高
- 数据量无限
- 数据多样性高
4. 高级RAG
4.1. 借助模型处理
4.1.1. 优化用户问题
- 使用对话背景或历史对话补全用户问题
- 拆分用户问题为多个问题
测试补全用户问题与问题拆分
问题:价格
4.1.2. 优化待检索知识
- QA拆分: 文本分块,使用模型根据文本块生成QA问答对
- 摘要:文本分块,使用模型总结一下文本块内容
4.2. 不借助模型
4.2.1 Small to Big
把文本块中的一句话向量化,召回的时候把这句话以及这句话前后附近的句子同时召回。或者召回的时候把这个句子整个段落都召回。
4.3. 优化检索方法
4.3.1 混合检索
向量检索的优势
除了能够实现复杂语义的文本查找,向量检索还有其他的优势:
- 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
- 多语言理解(跨语言理解,如输入中文匹配英文)
- 多模态理解(支持文本、图像、音视频等的相似匹配)
- 容错性(处理拼写错误、模糊的描述)
向量检索的劣势
虽然向量检索在以上情景中具有明显优势,但有某些情况效果不佳。比如:
- 搜索一个人或物体的名字(例如,伊隆·马斯克,iPhone 15)
- 搜索缩写词或短语(例如,RAG,RLHF)
- 搜索 ID(例如,gpt-3.5-turbo,titan-xlarge-v1.01)
关键词搜索的优势
而上面这些的缺点恰恰都是传统关键词搜索的优势所在,传统关键词搜索擅长:
- 精确匹配(如产品名称、姓名、产品编号)
- 少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
- 倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“吗”在句子中承载更重要的含义)
参考资料:引入混合检索(Hybrid Search)和重排序(Rerank)改进 RAG 系统召回效果
4.3.2. 重排
RRF (Reciprocal Rank Fusion, 倒数排序融合)
RRF(Reciprocal Rank Fusion)算法和rerank算法都是用于改进搜索结果排序的方法。
RRF是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法。这种方法的优势在于不需要调优,不同的相关性指标也不必相互关联即可获得高质量的结果。RRF算法的工作原理是,对于每个查询,如果文档在结果集中,那么它的分数就会增加1.0 / ( k + rank( result(q), d ) ),其中k是一个排名常数,rank( result(q), d )是文档在结果集中的排名。这样,即使你不了解不同方法中排名分数的确切分布,RRF也能提供出色的排序方法[1]。
例如,假设我们有两个查询,每个查询返回的结果集如下:
● 查询1的结果集:{文档A: 1, 文档B: 2, 文档C: 3}
● 查询2的结果集:{文档B: 1, 文档A: 2, 文档C: 3}
使用RRF算法,我们可以计算每个文档的分数:
● 文档A的分数:1.0 / (60 + 1) + 1.0 / (60 + 2) = 0.016 + 0.016 = 0.032
● 文档B的分数:1.0 / (60 + 2) + 1.0 / (60 + 1) = 0.016 + 0.016 = 0.032
● 文档C的分数:1.0 / (60 + 3) + 1.0 / (60 + 3) = 0.015 + 0.015 = 0.03
因此,最终的排名结果是:文档A,文档B,文档C。
Rerank算法则是在初步排序结果的基础上,对前N个结果进行重新排序。这通常是因为初步排序可能使用了一些快速但不够精确的方法(如ANN等),而rerank阶段则可以使用更精确的算法进行排序。例如,我们可以先使用某种快速的方法获取前30个结果,然后使用一种更精确的方法(如一一计算打分的方式)对这30个结果进行重新排序[2][4]。
例如,假设我们有一个初步排序的结果集:{商品A: 0.9, 商品B: 0.8, 商品C: 0.7}。然后我们使用一个更精确的模型进行rerank,得到的新的打分可能是:{商品A: 0.85, 商品B: 0.9, 商品C: 0.8}。因此,rerank后的结果集是:{商品B, 商品C, 商品A}。
总的来说,RRF和rerank都是用于改进搜索结果排序的方法,但它们的工作方式和使用场景有所不同。RRF是通过合并多个结果集来改进排序,而rerank则是在初步排序的基础上进行二次排序以提高精度。
(ChatGPT回答)
ReRank 模型
- Say Goodbye to Irrelevant Search Results: Cohere Rerank Is Here
- Reranker API
- bge-reranker
rerank模型的作用并不仅仅是重复向量化语义检索的功能,它还有几个关键的作用,使得在检索流程的最后阶段使用它是有价值的:
更深层次的分析:尽管rerank模型也是基于向量化的方法,但它通常能进行更深层次、更复杂的分析。例如,它可能会考虑查询和文档之间的微妙关系、上下文的细节、以及特定领域的知识,这超出了初步向量化语义检索的能力范围。
整合多种信号:Rerank模型可能会整合初步检索阶段未考虑的多种信号,如文档的新颖性、可靠性、用户行为数据等,从而提供一个更全面的评估。
优化用户体验:Rerank模型可以根据用户的具体需求和偏好进行调整,以优化用户体验。例如,它可以根据用户的历史交互对结果进行个性化调整。
处理多样性和公平性问题:在rerank阶段,可以采取措施确保结果的多样性和公平性,例如防止某一来源的文档过度占据顶部位置。
实时反馈和学习:Rerank模型可以利用用户的即时反馈(如点击率)来实时调整排序策略,更好地适应用户的当前需求。
总的来说,rerank阶段的目的不仅仅是再次评估文档的相关性,而是在初步检索的基础上提供更精细、更个性化、更符合用户需求的排序。这是对初步向量化语义检索的一个重要补充,而不是简单的重复。
(ChatGPT回答)
5. FastGPT RAG实战
5.1. 创建知识库
5.1.1. 直接分块
5.1.2. QA拆分
5.1.3. CSV 模板文件导入
| index | content |
|---|---|
| 直接分块文本:结合人工智能的演进历程,AIGC的发展大致可以分为三个阶段,即:早期萌芽阶段(20世纪50年代至90年代中期)、沉淀积累阶段(20世纪90年代中期至21世纪10年代中期),以及快速发展展阶段(21世纪10年代中期至今)。 | |
| 问题:AIGC发展分为几个阶段? | 早期萌芽阶段(20世纪50年代至90年代中期)、沉淀积累阶段(20世纪90年代中期至21世纪10年代中期)、快速发展展阶段(21世纪10年代中期至今) |
| 摘要:AIGC发展的阶段 | 早期萌芽阶段(20世纪50年代至90年代中期)、沉淀积累阶段(20世纪90年代中期至21世纪10年代中期)、快速发展展阶段(21世纪10年代中期至今) |
5.1.4. 混合检索
5.2. 创建应用
5.2.1. 提示词工程
- 系统提示词
- 知识库模板
Use the content within the tags as your knowledge:
{{quote}}
Answer requirements:
- If you are unsure of the answer, you need to clarify.
- If the user's question is not related to your knowledge, please say you don't know.
- Avoid mentioning that your knowledge comes from the data.
- Keep your answer consistent with the description in the data.
- Use Markdown syntax to optimize the formatting of your answer.
- Answer in Chinese.
Question: {{question}}