一,阻塞队列
1.阻塞队列的概念和作用
阻塞队列同数据结构中的队列一样都遵守“先进先出”的原则(不了解队列相关知识的朋友请查看之前队列的博文:(6条消息) 栈和队列(内附模拟实现代码)_徐憨憨!的博客-CSDN博客),阻塞队列就是在原本队列的基础上加入了阻塞功能(是一种线程安全的数据结构):
当队列满的时候, 继续入队列就会阻塞, 直到有其他线程从队列中取走元素.
当队列空的时候, 继续出队列也会阻塞, 直到有其他线程往队列中插入元素.
2.阻塞队列中的相关方法
1.BlockingQueue接口
在Java标准库中内置了阻塞队列(是一个接口BlockingQueue),可直接使用,实现该接口的类有很多(其中最常用的是LinkedBlockingQueue类)
ArrayBlockingQueue | 一个由数组结构组成的有界阻塞队列 |
LinkedBlockingQueue | 一个由链表结构组成的有界阻塞队列 |
PriorityBlockingQueue | 一个支持优先级排序的无界阻塞队列 |
DelayQueue | 一个使用优先级队列实现的无界阻塞队列 |
SynchronousQueue | 一个不存储元素的阻塞队列 |
LinkedTransferQueue | 一个由链表结构组成的无界阻塞队列 |
LinkedBlockingDeque | 一个由链表结构组成的双向阻塞队列 |
2.put和take方法
阻塞队列也是队列包含队列的相关方法(如offer,poll,peek等方法,但是这些方法不带有阻塞特性),所以在多线程下为了保证线程安全发挥其阻塞功能,一般会使用阻塞队列的put和take方法。
put:用于阻塞式的入队列,当队列满了的时候就会发生阻塞等待,直到队列出元素
take:用于阻塞式的出队列,当队列为空的时候就会发生阻塞等待,直到队列入元素
3.生产者消费者模型
阻塞队列的主要用于生产者消费者模型,用来解决生产者和消费者之间的强耦合问题
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取(所以这里的阻塞队列主要存放的就是生产者创建的一个个任务)。
使用内置标准库来实现一个生产者消费者的示例,代码如下:
/**
*创建两个线程:生产者线程和消费者线程
* 生产者线程负责生产count并使得count++
* 消费者线程负责消费count
* 分别在生产者线程和消费者线程中打印count查看生产和消费的信息
*/import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ThreadDemo1 {
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();
//消费者线程读取阻塞队列中的元素
Thread customer = new Thread(() -> {
while (true) {
try {
int ret = blockingQueue.take();
System.out.println("消费:" + ret);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
//生产者线程输入元素到阻塞队列中
Thread producer = new Thread(() -> {
int count = 0;
while (true) {
try {
System.out.println("生产:" + count);
blockingQueue.put(count);
Thread.sleep(500);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
}
}
通过结果可以看出,这里的生产和消费都是成对出现,一般是生产者线程一个任务消费者线程就会消费一个线程(主要原因是因为我们在生产者线程中使用了sleep方法控制了生产者的生产速率,从而达到消费者线程消费完一个任务之后生产者才会继续生产),如果我们取消sleep操作会发生什么?
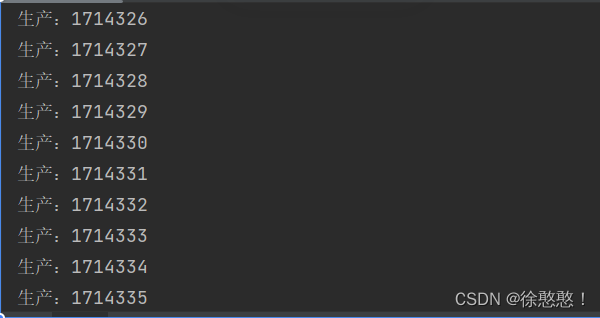
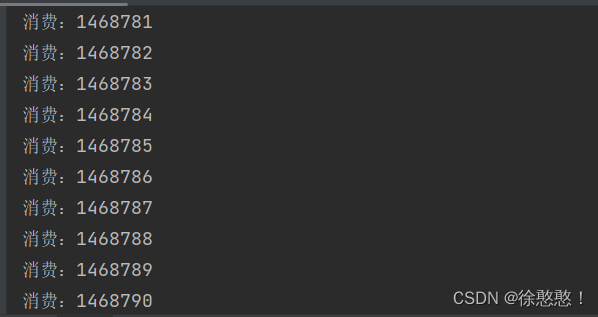
通过看出结果是不受控制的,因为两个线程是并发执行的,生产者线程一瞬间会生产很多任务,消费者线程一瞬间也会消费很多任务,所以对生产者和消费者合理加入sleep操作可以更好的控制消费和生产之间的效率。
生产者消费者模型的好处
实现了消费者和生产者之间的“解耦”(即降低可耦合过程)
假设有两个服务器A,B:A向B发送请求,B执行完A的请求之后再响应给A;

假如某一时刻A发送的请求激增,B来不及响应势必会造成B的崩溃(此时AB之间的耦合性非常高),于是提出了阻塞队列的想法,在AB之间加一个阻塞队列,A将请求全部放在阻塞队列中,不需要直接将请求发送给B,B直接从阻塞队列中接受请求,不需要直接响应A(此时AB之间的耦合性不高)

可以做到“削峰填谷”,保证系统的稳定性
接着上面AB服务器的例子,如果某一阶段A发送的请求增多,B来不及响应,此时B服务器就会崩溃,但是加入阻塞队列之后,不论发送的请求有多少都会放在阻塞队列中,队列满了就会阻塞等待,等待B从阻塞队列中执行响应,从而保证了系统的稳定性。
二,模拟实现阻塞队列
使用循环队列模拟实现阻塞队列
/**
* 自己模拟实现阻塞队列,不考虑泛型
* 使用循环队列模拟实现阻塞队列
* 定义一个size说明此时队列中的元素个数
*/class MyBlockingQueue {
private int[] elem = new int[1000];
//显示初始化
private int head = 0;
private int tail = 0;
private int size = 0;
//入队
public void put(int val) throws InterruptedException {
synchronized (this) {
while (size == elem.length) {
//队列满了,不能继续插入
//此时要产生阻塞
//return;
this.wait();
}
elem[tail] = val;
tail++;
//记得对tail的处理(因为这里是环形队列)这种方式可读性更高,而且效率也更高 因为去摸操作开销更大
//计算机算加减操作快,算乘除操作慢
if (tail == elem.length) {
tail = 0;
}
//tail = tail % elem.length;//写成这种方式是一样的
size++;
//唤醒take中的wait
this.notify();
}
}
//出队列
public Integer take() throws InterruptedException {
Integer ret;
synchronized (this) {
while (size == 0) {
//队列为空,出队失败
//return null;
this.wait();
}
ret = elem[head];
head++;
if (head == elem.length) {
head = 0;
}
size--;
//唤醒put中的wait
this.notify();
}
return ret;
}
}分别在put和take方法中加入wait和notify方法,put方法中的wait的作用是当队列满了需要阻塞等待,等待take方法中取出元素;take方法中的wait的作用是当队列为空时需要阻塞等待,等待put方法中入元素;
两个方法中的wait方法并不会同时出发,因为队列不可能同时为满和为空;
方法中涉及到写的操作,会造成线程不安全的问题,所以需要分别加上synchronized关键字进行加锁。