Clickhouse作为一个列式存储分析型数据库,提供了很多集成其他组件的表引擎数据同步方案。
官网介绍

一 Kafka 表引擎
使用Clickhouse集成的Kafka表引擎消费Kafka写入Clickhouse表中。
1.1 流程图

1.2 建表
根据上面的流程图需要建立三张表,分别Clickhouse存储数据表、Kafka数据消费引擎表、物化视图。
(1)Clickhouse存储数据表
create table if not exists my_test (
`id` Int64 comment '主键ID',
`name` String comment '名称',
`create_time` DateTime comment '创建时间'
)ENGINE = MergeTree()
PARTITION BY toInt64(toYYYYMMDD(create_time))
PRIMARY KEY id
ORDER BY (id, create_time)
SETTINGS index_granularity = 8192;(2)Kafka数据消费引擎表
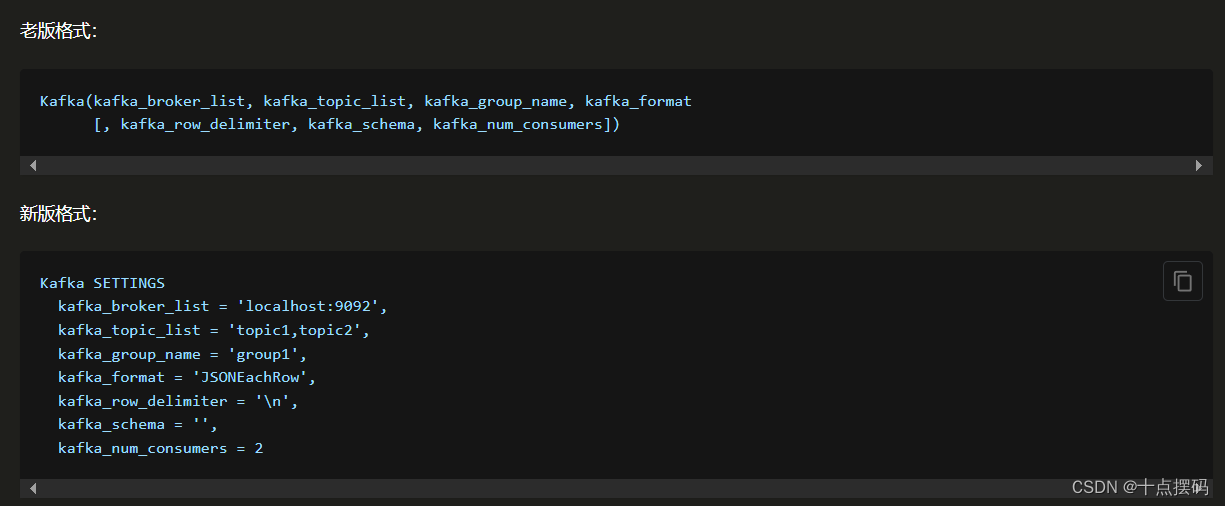
create table if not exists kafka_my_test (
`id` Int64 comment '主键ID',
`name` String comment '名称',
`create_time` DateTime comment '创建时间'
)ENGINE = Kafka()
SETTINGS
kafka_broker_list = '127.0.0.1:9092',
kafka_topic_list = 'topic_m_test',
kafka_group_name = 'group_id_test',
kafka_format = 'JSONEachRow';必要参数:
kafka_broker_list– 以逗号分隔的 brokers 列表 (localhost:9092)。kafka_topic_list– topic 列表 (my_topic)。kafka_group_name– Kafka 消费组名称 (group1)。如果不希望消息在集群中重复,请在每个分片中使用相同的组名。kafka_format– 消息体格式。使用与 SQL 部分的FORMAT函数相同表示方法,例如JSONEachRow。了解详细信息,请参考Formats部分。
可选参数:
kafka_row_delimiter- 每个消息体(记录)之间的分隔符。kafka_schema– 如果解析格式需要一个 schema 时,此参数必填。例如,普罗托船长 需要 schema 文件路径以及根对象schema.capnp:Message的名字。kafka_num_consumers– 单个表的消费者数量。默认值是:1,如果一个消费者的吞吐量不足,则指定更多的消费者。消费者的总数不应该超过 topic 中分区的数量,因为每个分区只能分配一个消费者。
(3)物化视图
CREATE MATERIALIZED VIEW IF NOT EXISTS view_m_test TO m_test AS SELECT id, name, create_time FROM kafka_m_test;1.3 数据模拟
#使用命令生产数据
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic topic_m_test
#发送一下数据
{"id": 12345666,"name":"test","age":12,"create_time":"2024-04-05 12:23:34"}
#查询
select * from m_test limit 10;