👦个人主页:@Weraphael
✍🏻作者简介:目前学习计网、mysql和算法
✈️专栏:MySQL学习
🐋 希望大家多多支持,咱一起进步!😁
如果文章对你有帮助的话
欢迎 评论💬 点赞👍🏻 收藏 📂 加关注✨
目录
- 一、聚合函数
- 1.1 count函数
- 1.2 sum函数
- 1.3 avg函数
- 1.4 max函数
- 1.5 min函数
- 二、分组聚合(group by + having)
- 2.1 group by
- 2.2 having
- 2.3 having vs where
一、聚合函数
在
MySQL中,聚合函数用于对数据进行汇总和统计,并返回单个值作为结果
1.1 count函数
- 用于计算指定列中非
null值的行数。它通常用于统计符合特定条件的行数。
【语法】
select count(distinct 列名) [as] 重命名 from 表名;
# as也可以不加
# 可以去重distinct统计
注意:
- 如果使用
count(*),它会统计表中所有行的数量,包括null值。

- 如果使用
count(列名),它会统计指定列中非null值的行数。
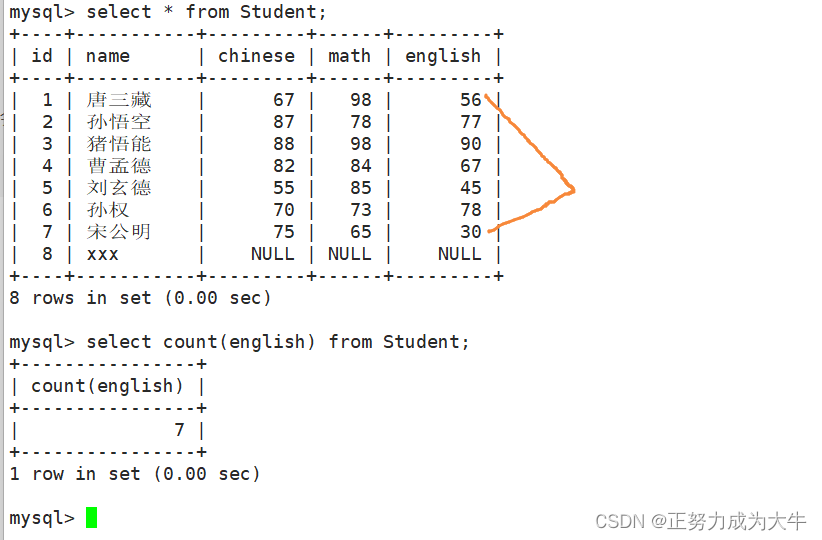
【使用案例】
假设有一个名为employees的表,包含员工的信息,如下所示:

- 统计表中的总行数
select count(*) from employees;

- 计算特定条件下的行数,比如部门为
HR的员工人数:
select count(*) as HR的员工人数 from employees where department='HR';

1.2 sum函数
- 用于计算指定列的数值总和。它通常用于计算某个列中的数值总和,比如计算某一列的总销售额、总成绩等。
【语法】
select sum(distinct 列名) [as 重命名] from 表名;
- 注意:如果指定的列包含
null值,则sum函数会忽略null值。

任何数对null进行+-*/都是null,由此看出sum 函数确实忽略了null值。
【使用案例】
假设有一个名为sales的表,包含产品销售信息,表中数据如下:
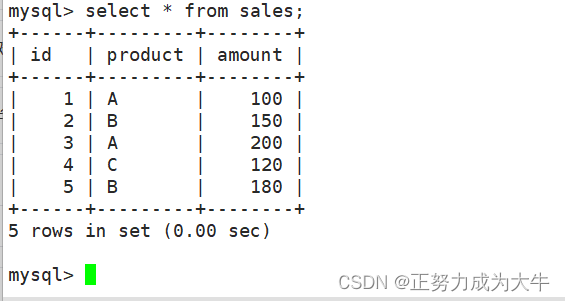
- 计算总销售额
select sum(amount) from sales;

- 计算特定条件下的销售总额,比如产品为
A的销售总额
select sum(amount) A的总销售额 from sales where product='A';

- 计算出总销售额后再除以
5
select sum(amount)/5 from sales;

1.3 avg函数
- 用于计算指定列的平均值。它通常用于计算某一列的平均数,比如计算某产品的平均销售额、平均成绩等。
【语法】
select avg(distinct 列名) from 表名;
注意:如果指定的列包含null值,则avg函数会忽略null值。
【使用案例】
假设有一个名为grades的表,包含学生的考试成绩信息,表中数据如下:
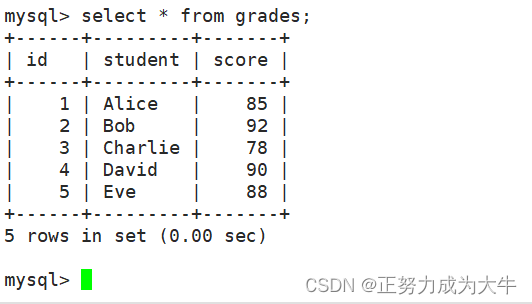
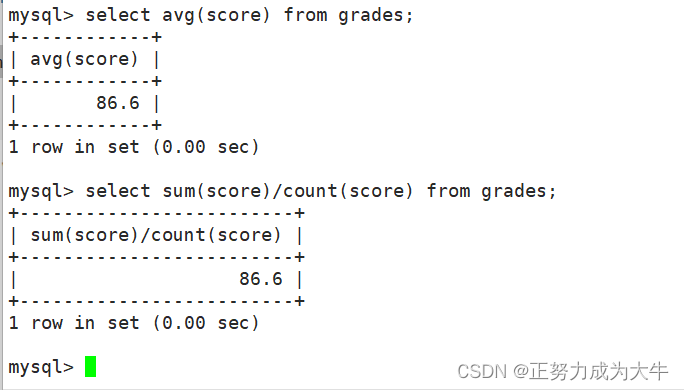
- 计算班级学生的平均值
# 写法一:
select avg(score) from grades;
# 写法二:
select sum(score)/count(score) from grades;
1.4 max函数
- 用于获取指定列中的最大值。它通常用于找到某一列中的最大值,比如找到某产品的最高价格、最高温度等。
【语法】
select max(列名) from 表名;
注意:如果指定的列包含null值,则max函数会忽略null值。
【使用案例】
假设有一个名为products的表,包含产品的价格信息,表中数据如下:
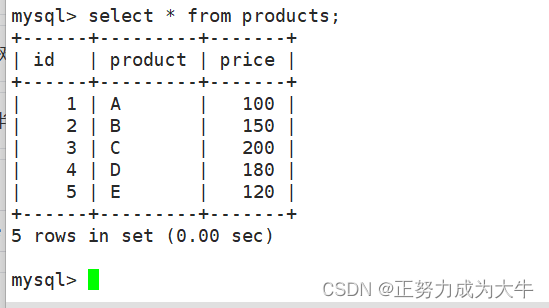
- 找到价格的最高值
select max(price) from products;

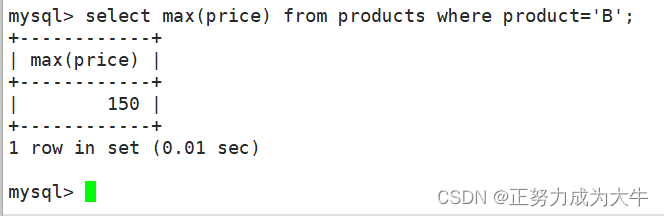
- 找到特定条件下的最大值,比如产品名称为
B的价格
select max(price) from products where product='B';
1.5 min函数
- 用于获取指定列中的最小值。它通常用于找到某一列中的最小值,比如找到某产品的最低价格、最低温度等。
基本语法如下:
【语法】
select min(列名) from 表名;
注意:如果指定的列包含null值,则min函数会忽略null值。
【使用案例】
假设有一个名为Student的表,包含学生的语数英成绩,表中数据如下:
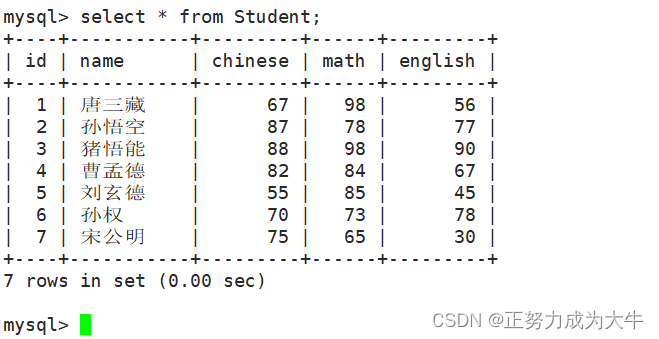
- 返回数学成绩最低分
select min(math) from Student;

- 返回
>70分以上的数学最低分
select min(math) from Student where math>70;

二、分组聚合(group by + having)
2.1 group by
- 聚合函数常与
group by结合使用,以便对数据进行分组聚合。(对数据进行分组统计)- 分组顾名思义就是将一组拆成了多个组,然后进行各自组内的统计。也可以看成将一张表拆成多个子表进行聚合统计。
- 执行顺序:先分组,再聚合。
【语法】
select group_name, 聚合fuc, ... from 表名 group by group_name, ...;
注意: group_name:除聚合函数括号里的列名以外,只有在group by后面出现的列名称,才能在select后面出现。
【使用案例】
-
准备工作:导入
scott_data.sql文件(来自oracle 9i的经典测试表)。该scott由三个表组成,分别是: -
emp员工表(子表) -
dept部门表(从表) -
sakgrade工资等级表(主表)

这里重点看emp员工表(子表)即可
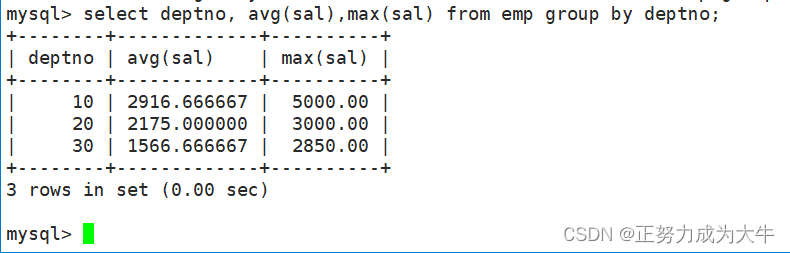
- 通过员工表,显示每个部门的平均工资和最高工资
select deptno, avg(sal),max(sal) from emp group by deptno;
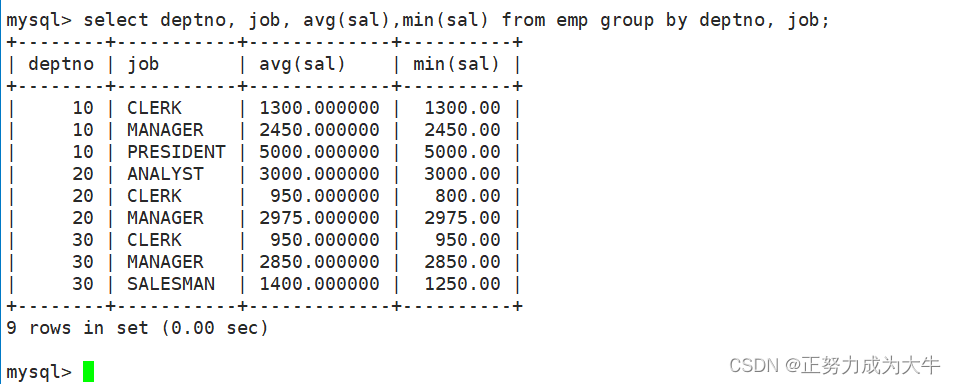
- 显示每个部门的每种岗位的平均工资和最低工资
select deptno, job, avg(sal),min(sal) from emp group by deptno, job;
2.2 having
having的功能其实和where一样,当你需要在 分组后的结果集上应用条件过滤 时,可以配合having子句使用。
- 显示平均工资低于
2000的部门和它的平均工资
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;

注意:where子句后面不能用重命名,而having可以。

SMITH员工不参与统计,显示平均工资低于2000的部门和它的平均工资
select deptno,job,avg(sal) 平均工资 from emp where ename!='SMITH' group by deptno,job having 平均工资<2000;

2.3 having vs where
在sql查询中,where和having都是用于筛选数据的关键字,但它们有着不同的作用范围和使用位置。
-
作用范围
where用于在对原始数据进行查询之前筛选行,它作用于未分组的数据having用于在对数据进行聚合后筛选结果,它作用于已分组的数据。
-
使用位置
where子句通常出现在sql查询的起始部分,用于过滤原始数据表的行。having子句通常出现在group by子句之后,用于筛选分组后的结果。