目录
一、啤酒和尿布的故事
二、理论
三、实例
1. 自定义数据集
2. 数据需转换成one-hot编码
3.电影题材关联分析
一、啤酒和尿布的故事
在美国,一些年轻的父亲下班后经常要到超市去购买婴儿尿布,超市因此发现一个规律,在购买婴儿尿布的年轻父亲们中,有30%~40%的人同时要买一些啤酒。超市随后调整了货架的摆放,把尿布和啤酒放在一起,明显增加了销售额。
若两个或多个变量的取值之间存在某种规律性,就称为关联
关联规则是寻找在同一个事件中出现的不同项的相关性,比如在一次购买活动中所买的不同商品的相关性。
"在购买计算机的顾客中,有30%的人也同时购买了打印机”
二、理论
| 编号 | 牛奶 | 果冻 | 啤酒 | 面包 | 花生酱 |
| T1 | 1 | 1 | 0 | 0 | 1 |
| T2 | 0 | 1 | 0 | 1 | 1 |
一个样本称为一个“事务”
每个事务由多个属性来确定,这里的属性称为“项”
多个项组成的集合称为“项集”
由K个项构成的集合
{牛奶},{啤酒}....称为1项集
{牛奶,啤酒}....称为2项集
......3项集,4项集,5项集
x-->y的含义:x和y是项集,x称为规则前项,y称为规则后项。
有必要说明一下:事务包含其涉及到的项目,而不包含项目的具体信息。在超市的关联规则挖掘问题中事务是顾客一次购物所购买的商品,但事务并不包括这些商品的具体信息,如商品的数量,价格,用途等等。
支持度(support):一个项集或者规则在所有事务中出现的频率,:表示项集X的支持度计数
项集X的支持度:
规则x-->y表示物品集x对物品集y的支持度,也就是x和y同时出现的概率。某天共有100个顾客到商场购买物品,其中有30个顾客同时购买了啤酒和尿布,那么上述的关联规则的支持度就是30%。
置信度:确定y在包含x的事务中出现的频繁程度。,
。
置信度反应了关联规则的可信度-购买了项目集x的商品的顾客同时也购买了y中商品的可能性有多大。
购买薯片的顾客中有50%的人购买了可乐,则置信度为50%。
例:
| 交易ID | 购买的商品 |
| 1 | ABC |
| 2 | AC |
| 3 | AD |
| 4 | BEF |
(x,y)--->z:支持度:交易中包含{x,y,z}的可能性
置信度:包含{x,y}的交易中也包含z的条件概率
设最小支持度50%,最小可信度为50%,则可以得到:
A-->C(50%,66.6%) C-->A(50%,100%)
若关联规则x-->y的支持度和置信度分别大于或等于用户指定的最小支持率minsupport,和最小置信度minconfidence,则称x-->y为强关联规则,否则为弱关联规则。
提升度(lift):物品集A的出现对物品集B的出现概率发生了多大的变化。
现在有1000个消费者,有500人购买了茶叶,其中有450人同时购买了咖啡,另外50人没有。由于confidence(茶叶-->咖啡)=450/500=90%,由此可能会认为喜欢喝茶的人往往喜欢喝咖啡。但是如果另外没有购买茶叶的500人,其中同样也有450人购买了咖啡同样很高的置信度90%,由此得到不爱喝茶的人也爱喝咖啡。这样看来,其实是否购买咖啡,与有没有购买茶叶没有关联,两者是相互独立的,其提升度。
由此可见,lift正是弥补了confidence的这一缺陷,if lift = 1,x与y独立,x对于y的出现的可能性没有提升作用,其值越大(lift>1),则表明x对y的提升程度就越大,也表明关联性越强。
三、实例
首先
使用mlxtend工具包得出频繁项集与规则
pip install mlxtend
1. 自定义数据集
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
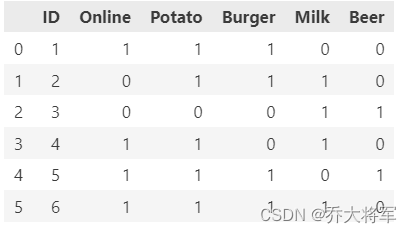
### 自定义一份购物数据集
data = {'ID':[1,2,3,4,5,6],
'Online':[1,0,0,1,1,1],
'Potato':[1,1,0,1,1,1],
'Burger':[1,1,0,0,1,1],
'Milk':[0,1,1,1,0,1],
'Beer':[0,0,1,0,1,0]}
df = pd.DataFrame(data)
df = df[['ID','Online','Potato','Burger','Milk','Beer']]
print(df)
设置支持度(support)来选择频繁集
选择最小支持度为50%
apriori(df,min_support=0.5,use_clonames=true)
frequent_itemsets = apriori(df[['Online','Potato','Burger','Milk','Beer']],min_support=0.50,use_colnames=True)
print(frequent_itemsets)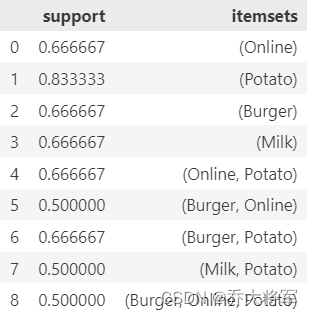
计算规则
association_rules(df,metric='lift,min_threshold=1)
可以指定不同的衡量标准与最小阈值
rules = association_rules(frequent_itemsets,metric='lift',min_threshold=1)
print(rules)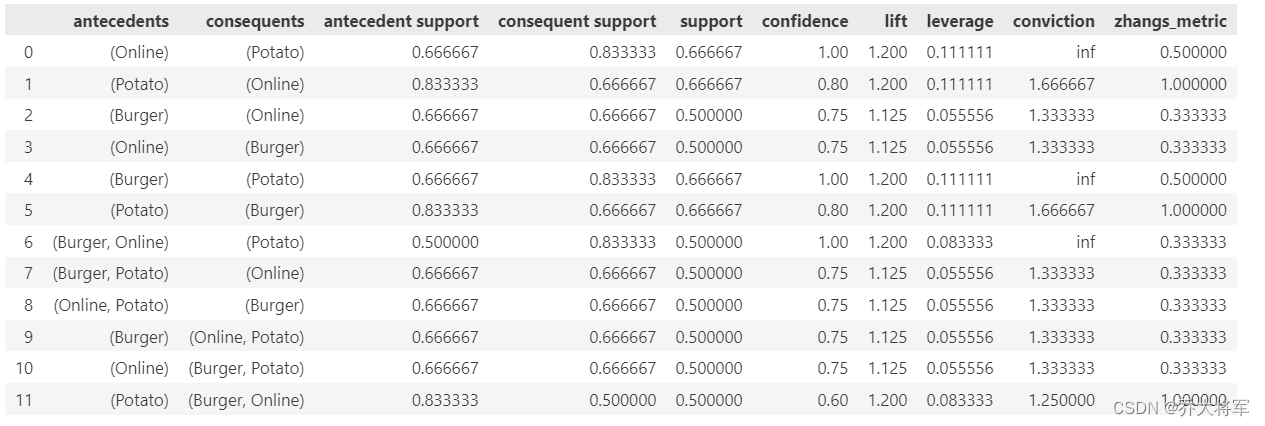
针对选择
rules [(rules['lift'] > 1.125) & (rules['confidence'] > 0.8)]
这几条结果就比较有价值了
洋葱和马铃薯 汉堡和马铃薯 可以搭配着来卖
如果洋葱和汉堡在购物篮中,顾客买马铃薯的可能性也比较高,如果篮子里面没有,可以推荐一下
2. 数据需转换成one-hot编码
在实际的数据中,数据并不是Apriori工具包直接能使用的数据格式,需要先转换成数值的形式。
retail_shopping_basket = {'ID':[1,2,3,4,5,6],
'Basket':[
['Beer','Diaper','Pretzels','Chips','Aspirin'],
['Diaper','Beer','Chips','Lotion','Juice','BabyFood','Milk'],
['Soda','Chips','Milk'],
['Soup','Beer','Diaper','Milk','IceCream'],
['Soda','Coffee','Milk','Breed'],
['Beer','Chips']
]
}
retail = pd.DataFrame(retail_shopping_basket)
retail = retail[['ID','Basket']]
pd.options.display.max_colwidth=100
print(retail)数据集中都是字符串组成的,需要转换成数值编码
#先把ID拿出来
retail_id = retail.drop('Basket',axis=1)
print(retail_id)
retail_Basket = retail.Basket.str.join(',')
print(retail_Basket)
retail_Basket = retail_Basket.str.get_dummies(',')
print(retail_Basket)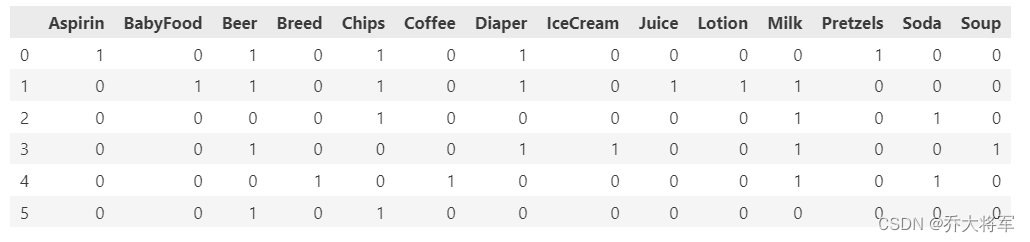
#将ID加入进去
retail = retail_id.join(retail_Basket)
print(retail)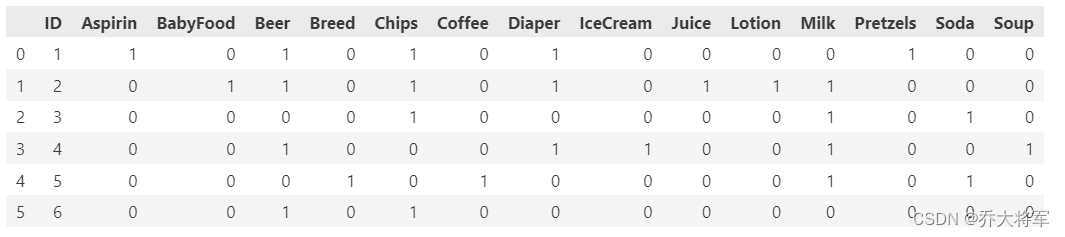
frequent_itemsets_2 = apriori(retail.drop('ID',axis=1),use_colnames=True)
print(frequent_itemsets_2)
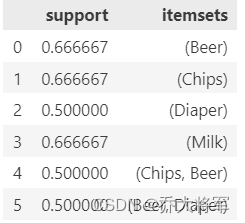
如果光考虑支持度support(X-->Y),[Beer,Chips]和[Beer,Diaper]都是很频繁的,哪一种组合更相关呢?
看提升度
print(association_rules(frequent_itemsets_2,metric='lift'))
3.电影题材关联分析
moiveLen数据集,广泛用于推荐系统。读者可以自行下载。
uname = ['Movie_id', 'title', 'genres']
movies = pd.read_table(r'ml-1m\movies.dat', sep='::', header=None, names=uname,engine='python',encoding='ISO-8859-1')
print(movies.head(10))
数据中包括电影名字与电影类型的标签,第一步还是先转换成one-hot格式
movies_ohe = movies.drop('genres',axis=1).join(movies.genres.str.get_dummies())
print(movies_ohe.head(10))
将ID和电影名字都作为索引
movies_ohe.set_index(['Movie_id','title'],inplace=True)
print(movies_ohe.head(10))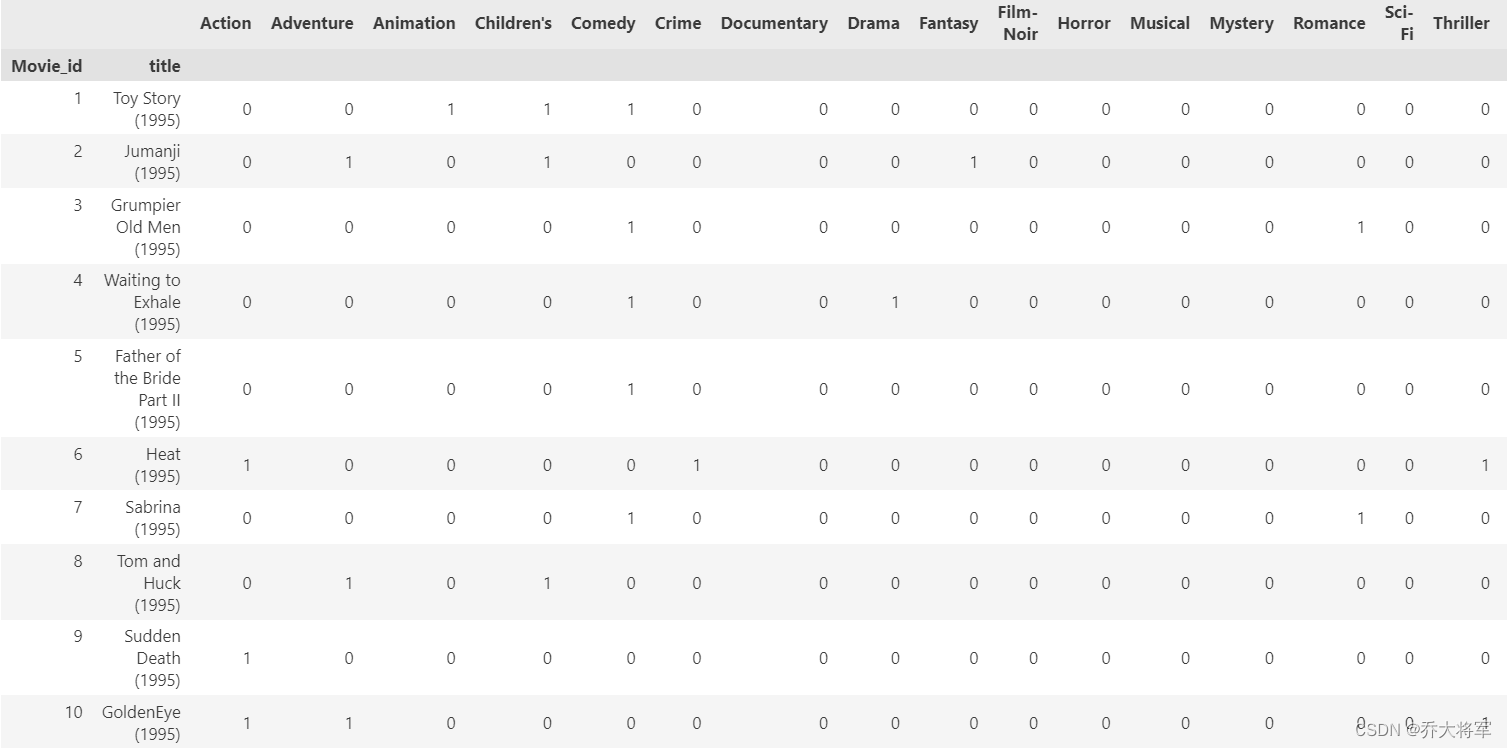
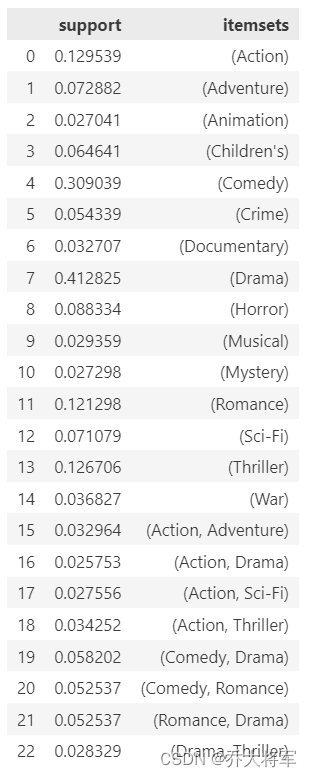
frequent_itemsets_movies = apriori(movies_ohe,use_colnames=True,min_support=0.025)
print(frequent_itemsets_movies)
rules_movies = association_rules(frequent_itemsets_movies,metric='lift',min_threshold=1.25)
print(rules_movies)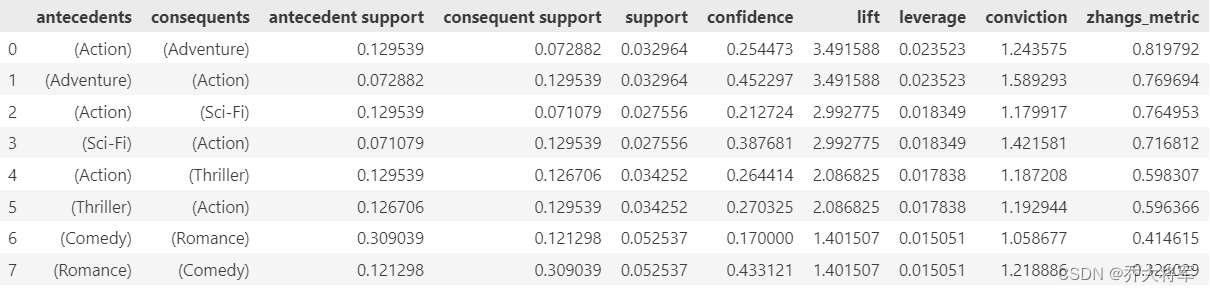
rules_movies[(rules_movies.lift>3)].sort_values(by=['lift'],ascending=False)
Advebture 和 Action 这两个题材是最相关的了,常识也可以分辨出来
#查看相关题材电影
movies[(movies.genres.str.contains('Adventure')) & (~movies.genres.str.contains('Action'))]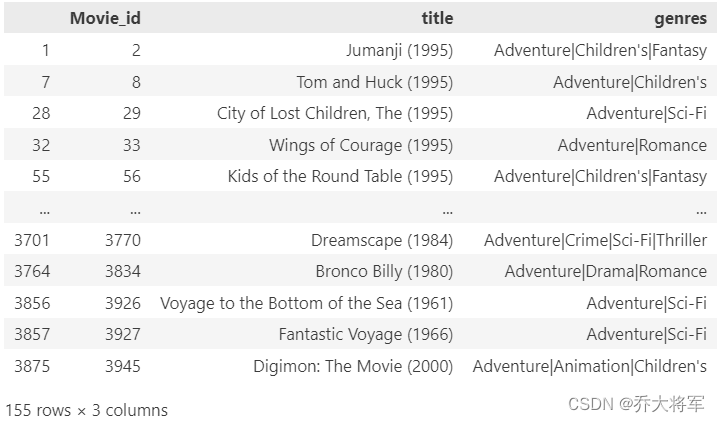
![[调度算法]](https://img-blog.csdnimg.cn/direct/7288f360996243cd802cd55284f9c532.png)