read函数
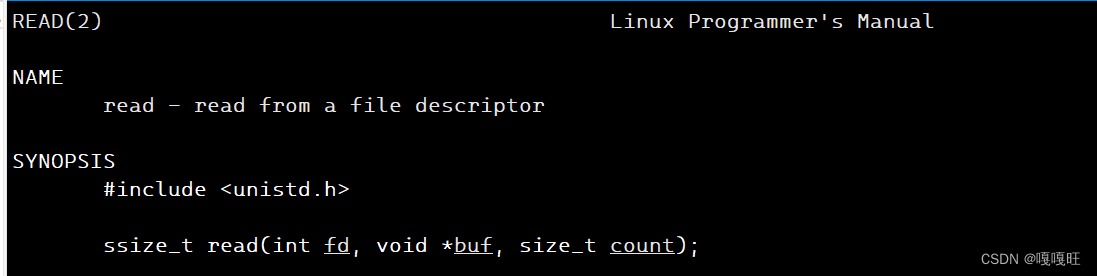
将文件标识符为fd的文件内容读到buf中去,读count个,read的返回值是实际读到的个数,有可能文件中没有count个,但是read返回的还是实际读到的个数
stat函数
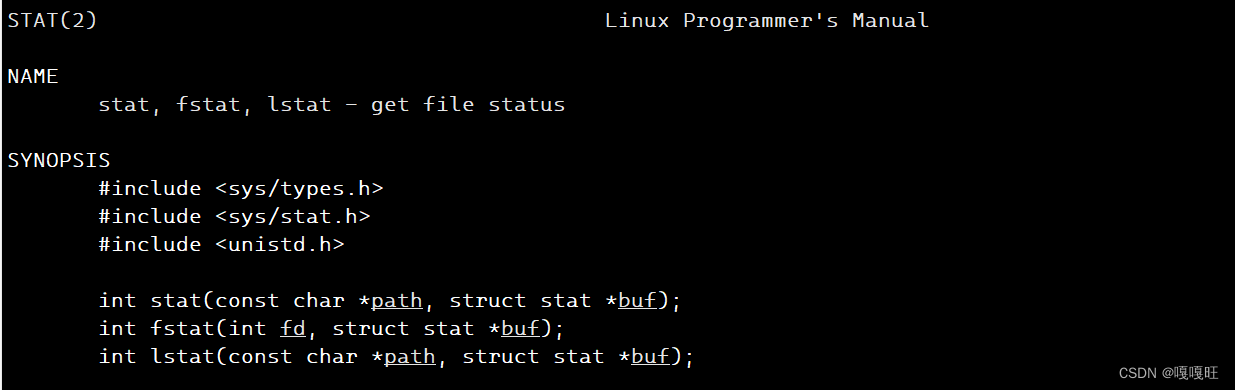
调用这个函数可以查到对应文件的属性,比方说文件大小
pathname:用于指定一个需要查看属性的文件路径。
buf:struct stat 类型指针,用于指向一个 struct stat 结构体变量。调用 stat 函数的时候需要传入一个 struct stat 变量的指针,获取到的文件属性信息就记录在 struct stat 结构体中。
返回值:成功返回 0;失败返回-1,并设置 error。
1 #include<stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <fcntl.h>
6 #include<stdlib.h>
7 const char* filename="log.txt";
8 int main()
9 {
10 struct stat st;
11 int n=stat(filename,&st);
12 if(n<0) return 1;
13 printf("file size:%lu\n",st.st_size);
14 int fd=open(filename,O_RDONLY);
15 if(fd<0)
16 {
17 perror("open");
18 return 2;
19 }
20 printf("fd:%d\n",fd);
21 char* file_buffer=(char*)malloc(st.st_size);
22 n=read(fd,file_buffer,st.st_size);
23 if(n>0)
24 {
25
26 file_buffer[n]='\0';
27 }
27 printf("%s",file_buffer);
28 free(file_buffer);
29 close(fd);
30 return 0;
31 }
32
代码解释:stat函数获取filename(log.txt)的文件属性,然后就可以直接获取文件大小在结构体变量中st.st_size,打印文件的文件标识符fd,malloc一个和文件大小一样的file_buffer模拟缓冲区,通过read函数将文件内容读到file_buffer中。read读取实际读到的大小,返回为实际大小n,并在模拟的缓冲区的最后加’\0’,释放file_buffer空间,关闭文件.

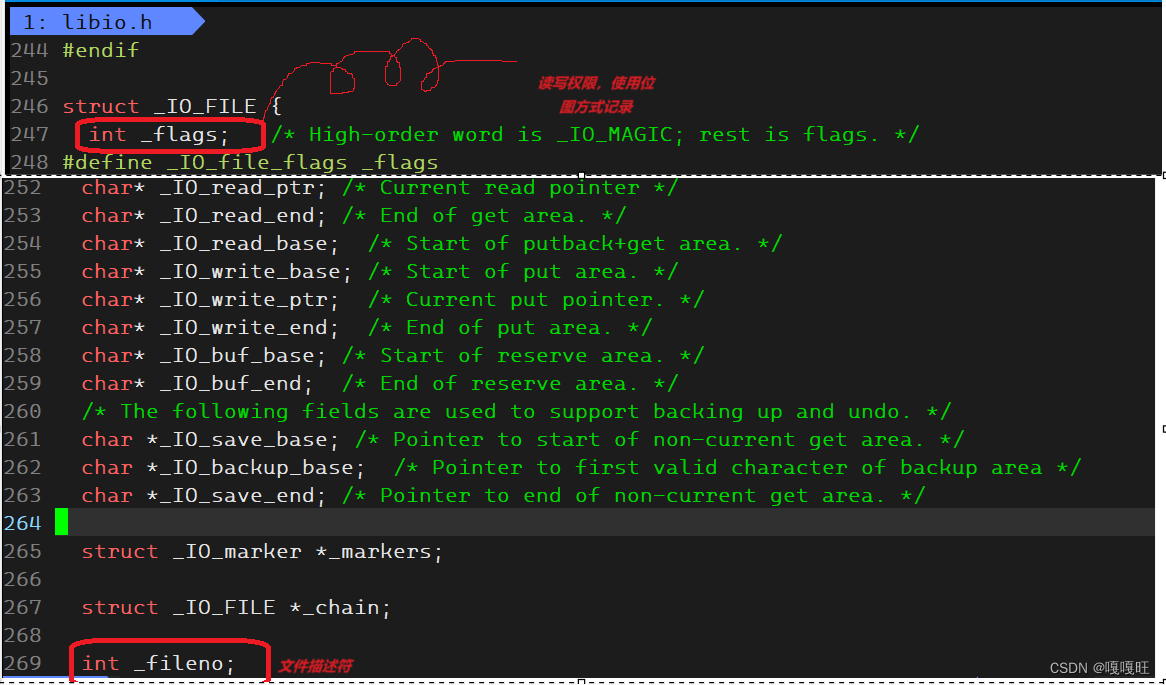
如果要查看文件对应的属性结构体在/usr/include/libio.h
重定向
1 #include<stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6 int main()
7 {
8 close(1);
9
10 int fd=open("log.txt",O_CREAT|O_TRUNC|O_WRONLY,0666);
11 if(fd<0)
12 {
13 perror("open fail");
14 }
15 const char* buf="hello world";
16 write(1,buf,sizeof(buf));
17 printf("log.txt:fd:%d",fd);
18 }
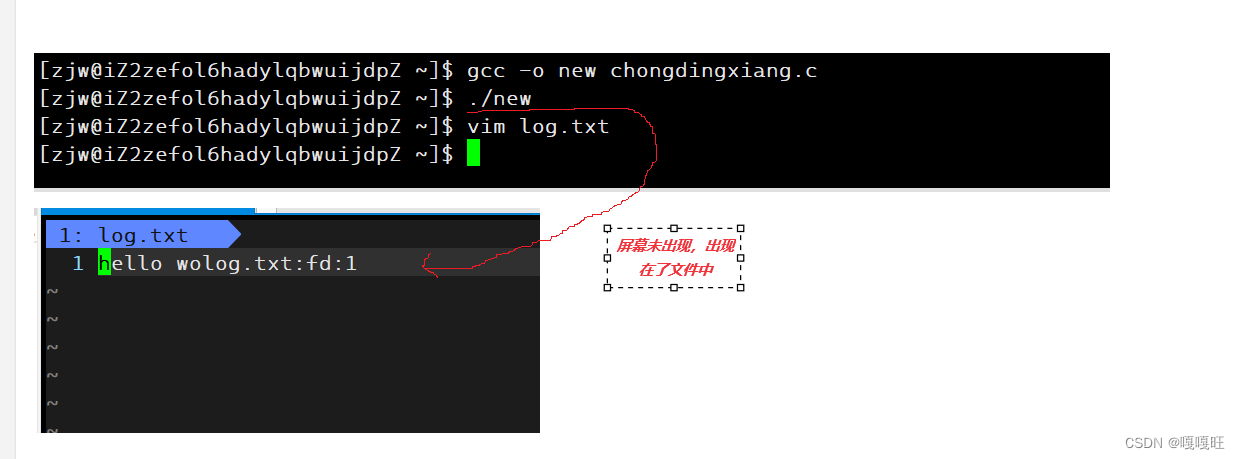
代码解释:我们关闭文件标识符为1的屏幕,根据文件描述符的分配规则:查自己的文件描述表,分配最小的没有被使用过的fd,于是新创建的文件的文件描述符被分配1,以至于本来要显示在屏幕上的东西,显示在了文件log.txt中,这就叫做重定向
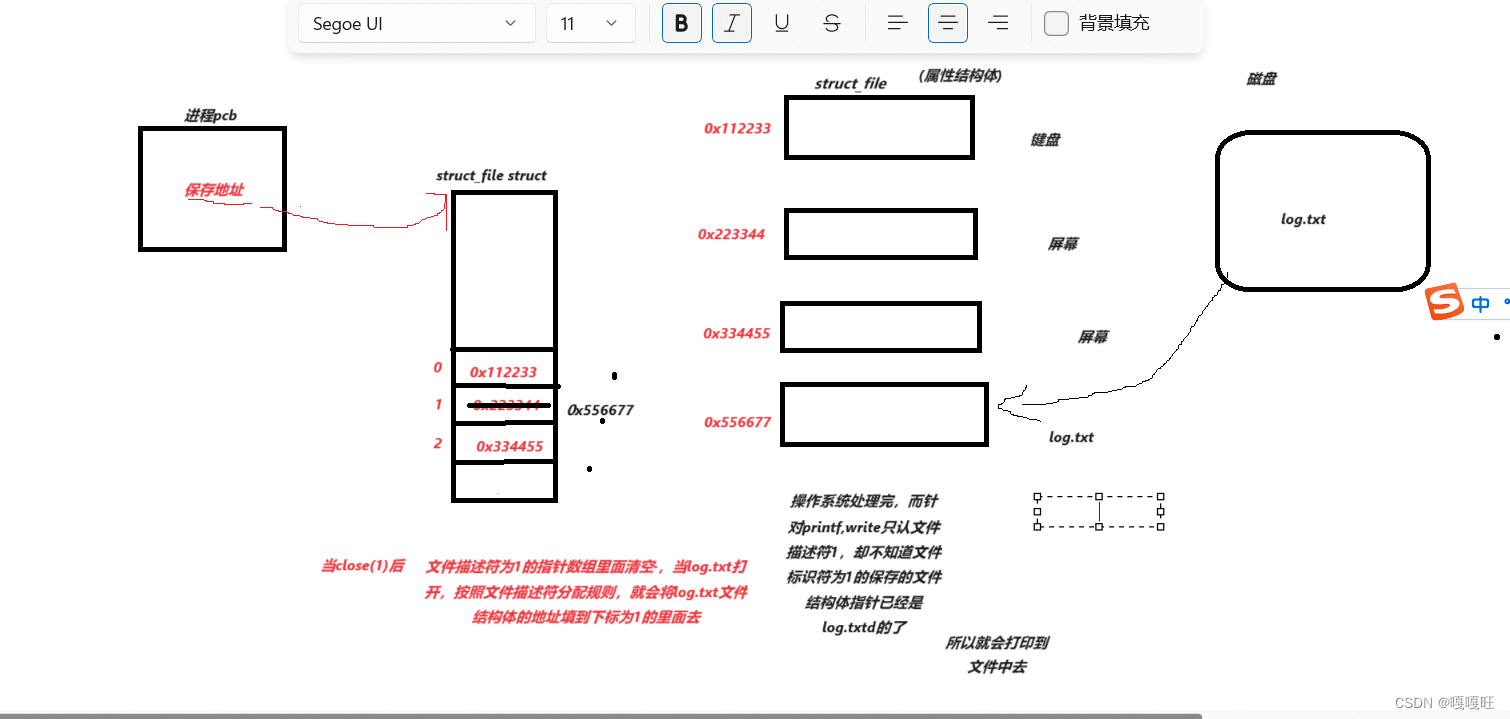
使用重定向并非要关闭一个文件描述符对应的文件,让另一个来替代这个被关闭的文件,我们可以使用dup2函数也能实现重定向
dup2函数原理说明:
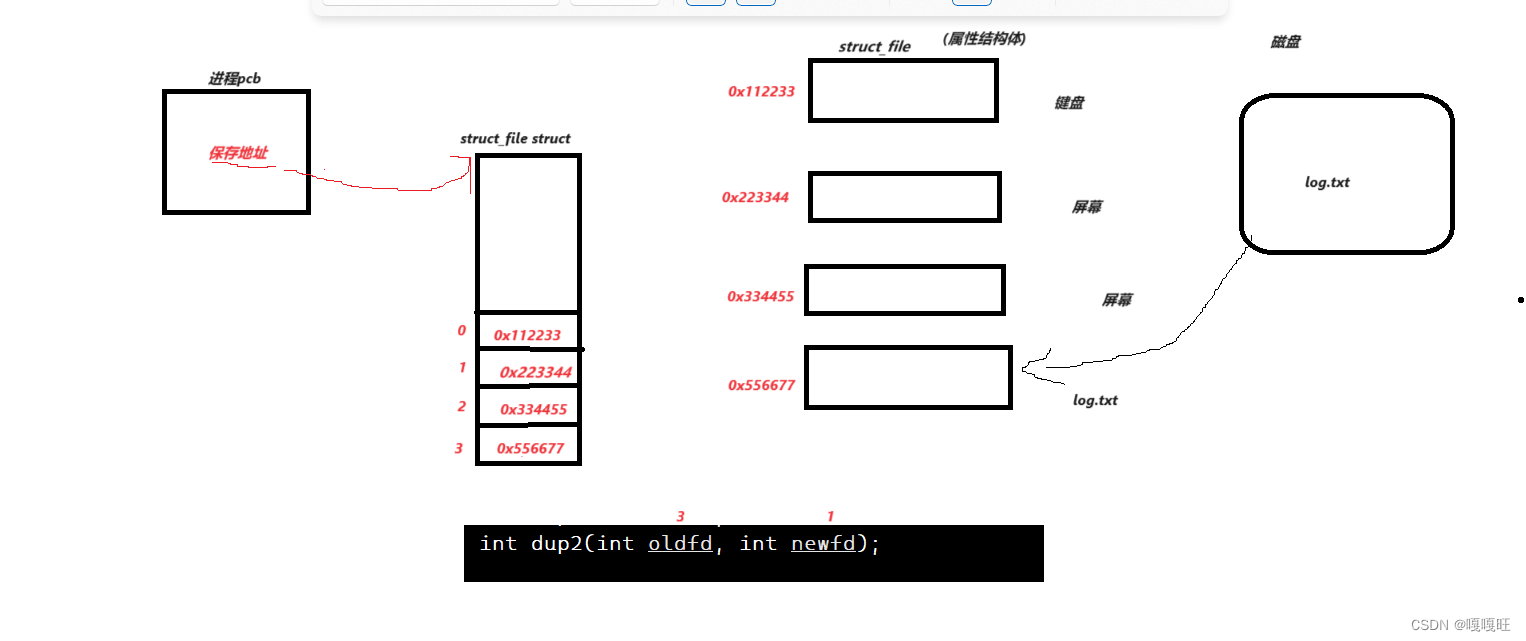
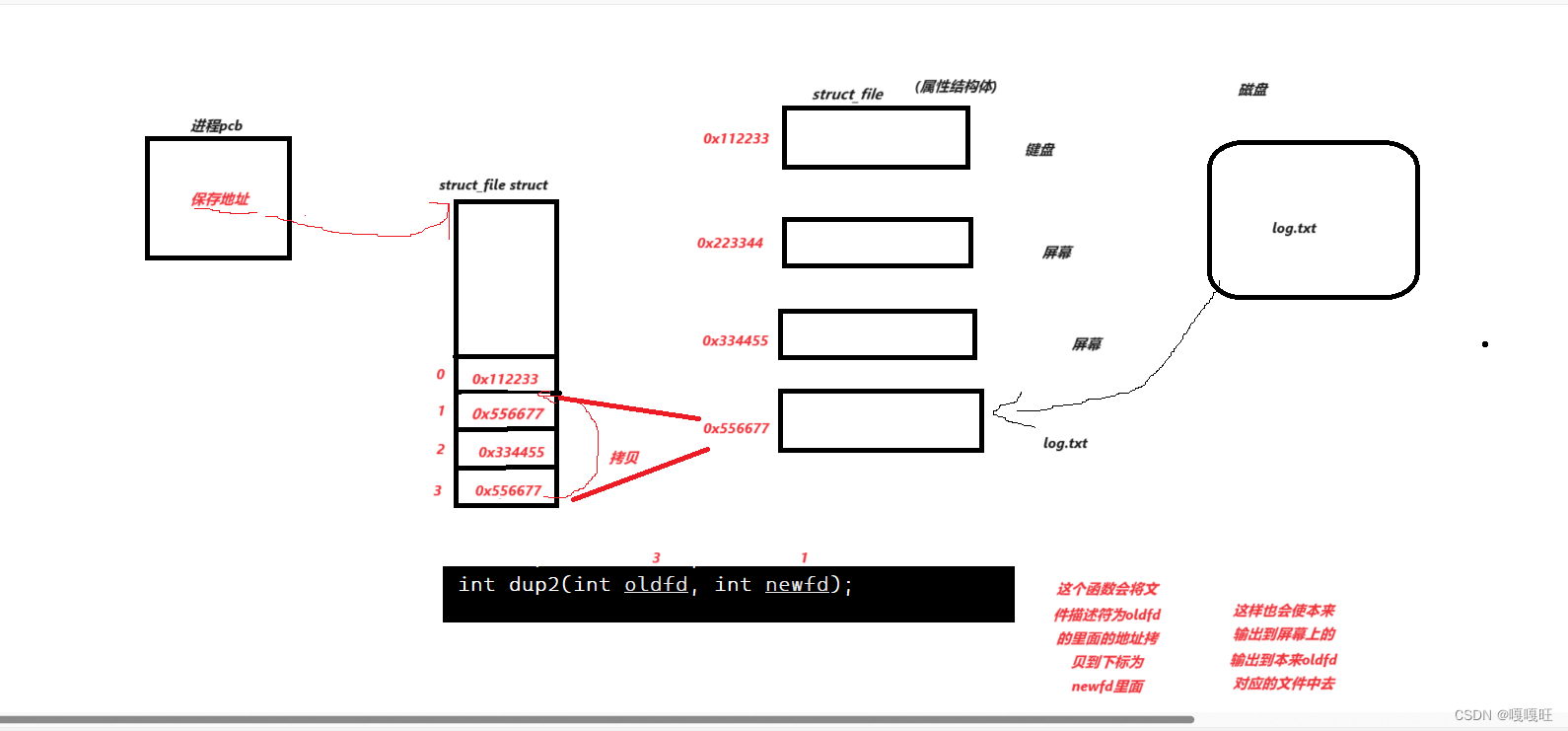
重定向的本质:是在内核中改变文件描述符特定下标的内容,和上层无关,文件描述符下标对应内容的拷贝
使用dup2实现的重定向和close(1)重新分配一样的效果
1 #include<stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6 int main()
7 {
8
9
10 int fd=open("log.txt",O_CREAT|O_TRUNC|O_WRONLY,0666);
11 if(fd<0)
12 {
13 perror("open fail");
14 }
15 dup2(fd,1);
16 const char* buf="hello world";
17 write(1,buf,sizeof(buf));
18 printf("log.txt:fd:%d",fd);
19 }

缓冲区
1 #include<stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 close(1);
10 int fd=open("log.txt",O_CREAT|O_WRONLY|O_TRUNC,0666);
11 if(fd<0)
12 {perror("open fail");
13 return 1;}
14 printf("printf,fd:%d\n",fd);
15 fprintf(stdout,"fprintf,fd:%d\n",fd);
16 close(fd);
17 return 0;
18 }
代码解释:我们关闭屏幕,让本来打印到屏幕上去的,打印到文件log.txt中去.


我们发现没有打印到文件中去
1 #include<stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 close(1);
10 int fd=open("log.txt",O_CREAT|O_WRONLY|O_TRUNC,0666);
11 if(fd<0)
12 {perror("open fail");
13 return 1;}
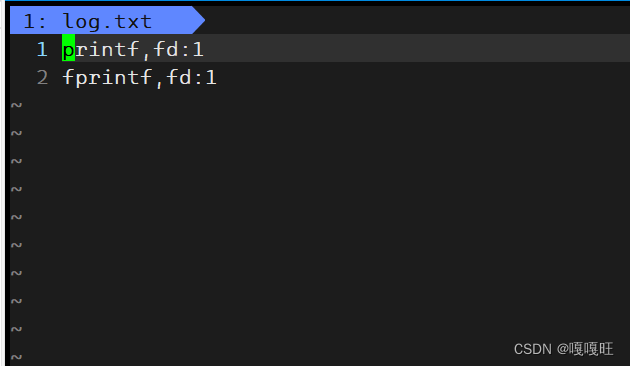
14 printf("printf,fd:%d\n",fd);
15 fprintf(stdout,"fprintf,fd:%d\n",fd);
16 fflush(stdout);
17 close(fd);
18 return 0;
19 }
当我加上一个fflush后,就出现了,到底是为什么呢???

这里就要提出缓冲区这个概念了,实际上存在一个语言级别的缓冲区,当我们使用printf,fprintf的时候,我们是将对应内容写到了语言级别的缓冲区里面,并没有写到操作系统对应内核的操作系统里面,如果此时不加fflush的话,就关闭文件,对应文件的内核缓冲区中没有数据,而文件中写入的数据,都是文件对应的内核缓冲区中冲刷过来的.这里fflush的作用是将语言级别的缓冲区的内容冲刷到对应文件的内核缓冲区中去
画一个图理解一下
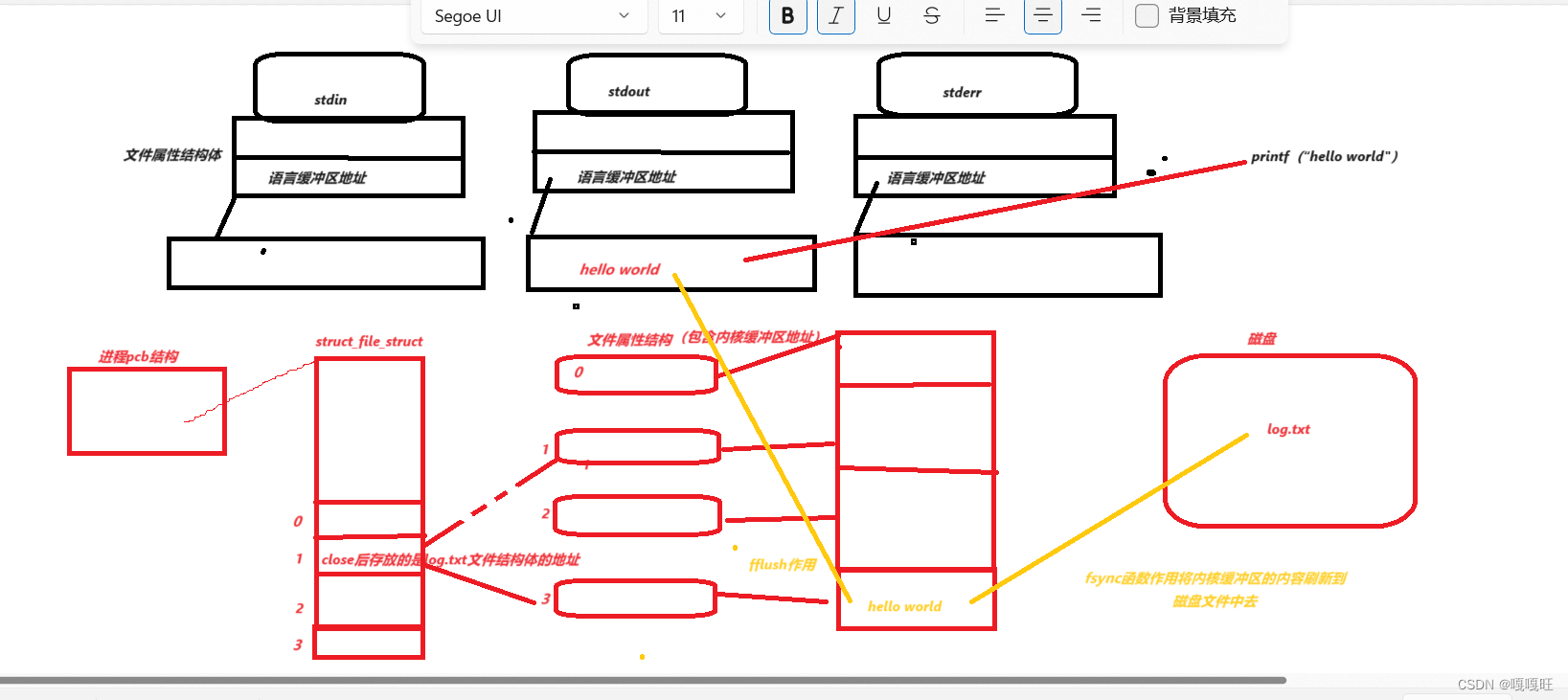
缓冲区知识总结:缓冲区包括用户级缓冲区(语言层面的)和内核级缓冲区,主要作用是解耦和提高效率,提高了使用者的效率,使用者只需将printf将内容放到用户级缓冲区中,剩下的的事情操作系统帮你干,提高了刷新IO的效率
缓冲区是什么?
一段内存空间
为什么要存在缓冲区?
给上层提供高效的IO体验,间接提供整体效率
刷新策略
1.立即刷新
2.行刷新(方便用户阅读习惯)
3.全缓冲:缓冲区写满,才刷新(普通文件采用这个)
特殊情况:
进程退出,系统会自动刷新(强制)
1 #include<stdio.h>
2 #include <unistd.h>
3 int main()
4 {
5 fprintf(stdout,"hello fprintf\n");
6 printf("hello printf\n");
7 const char* buf="hello write\n";
8 write(1,buf,sizeof(buf));
9 return 0;
10
11
12 }
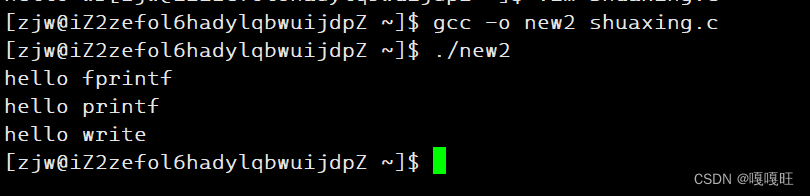
1 #include<stdio.h>
2 #include <unistd.h>
3 #include<string.h>
4 int main()
5 {
6 fprintf(stdout,"hello fprintf\n");
7 printf("hello printf\n");
8 const char* buf="hello write\n";
9 write(1,buf,strlen(buf));
10 fork();
11 return 0;
12
13
14 }
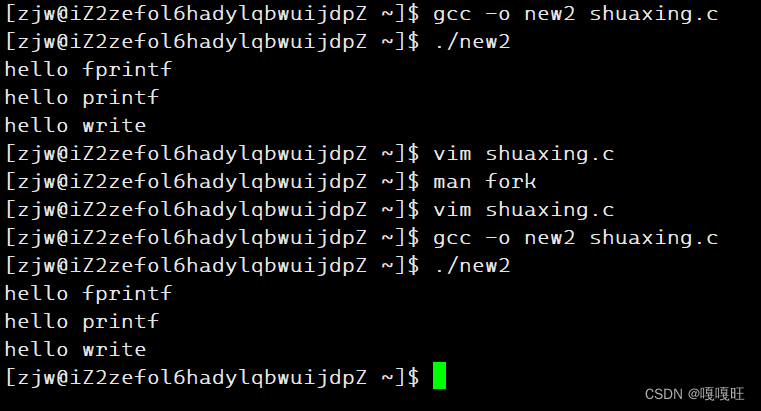
1 #include<stdio.h>
2 #include <unistd.h>
3 #include<string.h>
4 #include <sys/types.h>
5 #include <sys/stat.h>
6 #include <fcntl.h>
7 int main()
8 {
9 close(1);
10 int fd=open("log.txt",O_CREAT|O_WRONLY|O_TRUNC,0666);
11 fprintf(stdout,"hello fprintf\n");
12 printf("hello printf\n");
13 const char* buf="hello write\n";
14 write(fd,buf,strlen(buf));
15 fork();
16 return 0;
17
18
19 }
我们如果往文件中输出的话,为什么会存在下面的问题呢

解释:如果是输出到屏幕上的,属于行刷新,一行满了就立刻刷新到内核级缓冲区中去,而如果输出到文件中去,他是全缓冲,直到用户级缓冲区写满之后,才会写入到内核级缓冲区中去,而write是直接写到内核级缓冲区里面的,在fork之前,语言级缓冲区里面只有父进程缓冲区的内容也就是只有一遍hello fprintf ,hello printf,当fork后,由于子进程是复制父进程好多的内容,包括pcb结构,也就是说子进程的文件缓冲区和父进程的文件缓冲区指向的是同一个,如果发生写时拷贝的话,操作系统会给子进程单独搞一个内核级缓冲区,内容和父进程一样hello fprintf ,hello printf,深拷贝导致缓冲区地址不一样,但是都是一个文件的缓冲区,子进程写时拷贝后导致这个文件的文件缓冲区满了,然后就会刷新,将父进程的缓冲区,和子进程的缓冲区的内容都刷新到文件中去,write是系统调用,自然不会有语言级的缓冲区,也不会让子进程在拷贝一个新的缓冲区