视频链接:【62】【Cherno C++】【中字】C++的线程_哔哩哔哩_bilibili
参考文章:TheChernoCppTutorial_the cherno-CSDN博客
Cherno的C++教学视频笔记(已完结) - 知乎 (zhihu.com)
C++ 的线程
#include<iostream>
#include<thread>
static bool is_Finished = false;
void DoWork()
{
using namespace std::literals::chrono_literals; // 为 1s 提供作用域
std::cout << "Started thread ID: "<<std::this_thread::get_id()<<std::endl;
while (!is_Finished)
{
std::cout<<"Working..."<<std::endl;
std::this_thread::sleep_for(1s);//等待1s
}
}
int main()
{
std::thread worker(DoWork);
std::cin.get(); // 其作用是阻塞主线程
is_Finished = true;// 让worker线程终止的条件
worker.join();// 让主线程等待worker线程
std::cout << "Finished thread ID: " << std::this_thread::get_id() << std::endl;
std::cin.get();
}C++ 计时器
1、有两种选择,一种是用平台特定的API,另一种是用std::chrono,此处推荐后者
2、一个比较好的方法是建立一个Timer类,在其构造函数里面记下开始时刻,在其析构函数里面记下结束时刻,并打印从构造到析构所用的时间。如此就可以用这样一个类来对一个作用域进行计时:
#include<iostream>
#include<chrono>
struct Timer
{
std::chrono::time_point<std::chrono::steady_clock> start,end;
std::chrono::duration<float> duration;
Timer()
{
start = std::chrono::high_resolution_clock::now();
}
~Timer()
{
end = std::chrono::high_resolution_clock::now();
duration = end - start;
float ms = duration.count() * 1000.0f;
std::cout << "Timer took "<< ms << "ms" <<std::endl;
}
};
void Function()
{
Timer timer;
for (int i = 0;i<100;i++)
std::cout<<"Hello"<<std::endl;
}
int main()
{
Function();
std::cin.get();
}多维数组
int** a2d = new int* [50];
for (int i = 0; i < 50; i++)
{
a2d[i] = new int[50];
}
for (int i = 0; i < 50; i++)
{
delete[] a2d[i];
}
delete[] a2d;存储二维数组一个很好的优化方法就是:存储在一维数组里面:
int** a2d = new int* [5];
for (int i = 0; i < 5; i++)
{
a2d[i] = new int[5];
for (int j = 0; j < 5; j++)
{
a2d[i][j] = 2;
}
}
int* a1d = new int[5 * 5];
for (int i = 0; i < 5; i++)
{
for (int j = 0; j < 5; j++)
{
a1d[i + j * 5] = 2;
}
}Sorting
此处主要介绍std::sort,并结合lambda表达式可进行很灵活的排序:
#include<iostream>
#include<vector>
#include<algorithm>
int main()
{
std::vector<int> values = {2,3,4,1,5};
std::sort(values.begin(), values.end(), [](int a, int b)
{
// 此处两个判断可以将等于2的值放到末尾
if(a == 2)
return false;
if(b == 2)
return true;
return a < b;
});
// 此处输出为 1,3,4,5,2
for(const int &v:values)
std::cout<<v<<std::endl;
std::cin.get();
}类型双关 type punning
(取地址,换成对应类型的指针,再解引用)
#include <iostream>
int main()
{
int a = 50;
double value = *(double*)&a;
std::cout << value << std::endl;
std::cin.get();
}1、可以将同一块内存的东西通过不同type的指针给取出来
2、指针的类型只是决定了其+1或者-1时地址的偏移量
3、以下这个示例说明了:弄清楚内存分布的重要性
struct Entity
{
int x,y;
};
int main()
{
Entity e = {2,3};
int* pos = (int*)&e;
std::cout<<pos[0]<<","<<pos[1]<<std::endl;
int y = *(int*)((char*)&e+4);
std::cout << y << std::endl;
std::cin.get();
}
C++ Union
如果想要以不同形式去取出同一块内存的东西,可以用type punning,也可以使用union
共用内存。你可以像使用结构体或者类一样使用它们,你也可以给它添加静态函数或者普通函数、方法等待。然而你不能使用虚方法,还有其他一些限制。但通常人们用联合体来做的事情,是和类型双关紧密相关的。
通常union是匿名使用的,但是匿名union不能含有成员函数。
#include<iostream>
#include<vector>
#include<algorithm>
struct vec2
{
float x,y;
};
struct vec4
{
union
{
struct
{
float x,y,z,w;
};
struct
{
vec2 a,b;
};
};
};
void PrintVec2(const vec2& vec)
{
std::cout<<vec.x<<","<<vec.y<<std::endl;
}
int main()
{
vec4 vector = {1.0f,2.0f,3.0f,4.0f};
PrintVec2(vector.a); // 输出 1,2
PrintVec2(vector.b); // 输出 3,4
vector.z = 10.0f;
PrintVec2(vector.a); // 输出 1,2
PrintVec2(vector.b); // 输出 10,4
std::cin.get();
}虚析构函数
只要你允许一个类拥有子类,就一定要把析构函数写成虚函数,否则没人能安全地扩展这个类。
C++ 类型转换
类型转换 casting, type casting
C++是强类型语言,意味着存在一个类型系统并且类型是强制的。
示例:
double value = 5.25;
// C风格的转换
double a = (int)value + 5.3;
// C++风格的转换
double s = static_cast<int>(value) + 5.3;2、C++的cast:
static_cast:基础的类型转换,结合隐式转换和用户自定义的转换来进行类型转换
dynamic_cast:安全地在继承体系里面向上、向下或横向转换指针和引用的类型,多态转换
reinterpret_cast:通过解释底层位模式来进行类型转换
const_cast:添加或者移除const性质
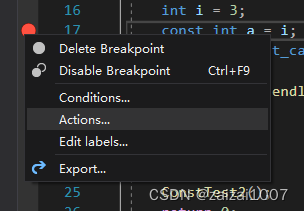
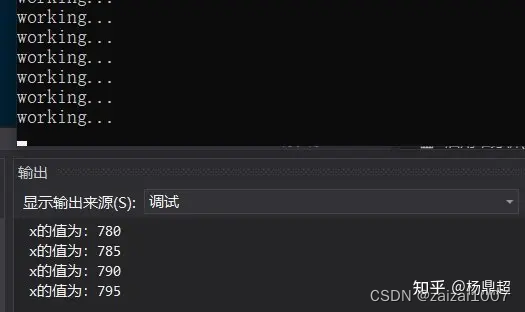
条件断点和断点操作
1、条件断点,当达到什么条件触发断点;断点操作:当触发断点后执行什么操作(在窗口输出什么)
2、一个示例,在一个死循环里面,x每次加一,当x被5整除时触发断点,触发断点后打出x的值,并且可以在调试过程中,随时更改断点的条件和动作,并且可以设置是否让程序继续运行

现代C++中的安全以及如何教授
C++里说的安全是什么意思?
安全编程,或者说是在编程中,我们希望降低崩溃、内存泄漏、非法访问等问题。
这一节重点讲讲指针和内存。
用于生产环境使用智能指针,用于学习和了解工作积累,使用原始指针,当然,如果你需要定制的话,也可以使用自己写的智能指针
Precompiled Headers (预编译头文件)
1、由于每次编译时,都需要对头文件以及头文件里面包含的头文件进行编译,所以编译时间会很长。而预编译头文件则是将头文件预先编译为二进制文件,如果此后不修改的话,在编译工程的时候就直接用编译好的二进制文件,会大大缩短编译时间。
2、只把那些不太(经常)会被修改的头文件进行预编译,如std,如windows API或者一些其他的库,如GLFW。
3、如果进行预编译头文件,一个例子:
新建一个工程和解决方案,添加Main.cpp,pch.cpp,pch.h三个文件,内容分别如下:
// Main.cpp
#include"pch.h"
int main()
{
std::cout<<"Hello!"<<std::endl;
std::cin.get();
}
// pch.cpp
#include"pch.h"
// pch.h
#pragma once
#include<iostream>
#include<vector>
#include<memory>
#include<string>
#include<thread>
#include<chrono>
#include<unordered_map>
#include<Windows.h>在pch.cpp右键,属性-配置属性-C/C++-预编译头-预编译头,里面选择创建, 并在下一行预编译头文件里面添加 pch.h
在项目名称上右键,属性-配置属性-C/C++-预编译头-预编译头,里面选择使用,并在下一行预编译头文件里面添加 pch.h
打开计时工具:工具-选项-项目和解决方案-VC++项目设置-生成计时,就可以看到每次编译的时间
进行对比:
进行预编译头文件前后的首次编译耗时分别为:2634ms和1745ms
进行预编译头文件前后的二次编译(即修改Main.cpp内容后)的耗时分别为:1235ms和312ms
可以看到进行预编译头文件后,时间大大降低
Dynamic Casting
dynamic_cast可以在继承体系里面向上、向下或者平级进行类型转换,自动判断类型,如果转换失败会返回NULL,使用时需要保证是多态,即基类里面含有虚函数。由于dynamic_cast使用了RTTI(运行时类型识别),所以会对性能增加负担
#include<iostream>
class Base
{
public:
virtual void print(){}
};
class Player : public Base
{
};
class Enemy : public Base
{
};
int main()
{
Player* player = new Player();
Base* base = new Base();
Base* actualEnemy = new Enemy();
Base* actualPlayer = new Player();
// 旧式转换
Base* pb1 = player; // 从下往上,是隐式转换,安全
Player* bp1 = (Player*)base; // 从上往下,可以用显式转换,危险
Enemy* pe1 = (Enemy*)player; // 平级转换,可以用显式转换,危险
// dynamic_cast
Base* pb2 = dynamic_cast<Base*>(player); // 从下往上,成功转换
Player* bp2 = dynamic_cast<Player*>(base); // 从上往下,返回NULL
if(bp2) { } // 可以判断是否转换成功
Enemy* pe2 = dynamic_cast<Enemy*>(player); // 平级转换,返回NULL
Player* aep = dynamic_cast<Player*>(actualEnemy); // 平级转换,返回NULL
Player* app = dynamic_cast<Player*>(actualPlayer); // 虽然是从上往下,
//但是实际对象是player,所以成功转换
}C++中的Structured Binding
C++17引入的新特性,可以在将函数返回为tuple、pair、struct等结构时且赋值给另外变量的时候,直接得到成员,而不是结构。(确保在项目属性-C/C++-语言-C++语言标准,里面打开C++17)
#include<iostream>
#include<tuple>
#include<string>
// 此处tuple换成pair或者struct结构也是一样的
std::tuple<std::string, int> CreatePerson()
{
return {"ydc",24};
}
int main()
{
auto[name,age] = CreatePerson();
std::cout<<name<<","<<age<<std::endl;
std::cin.get();
}std::optional
比如在读取文件内容的时候,往往需要判断读取是否成功,常用的方法是传入一个引用变量或者判断返回的std::string是否为空,例如:

C++17引入了一个更好的方法,std::optional,就如名字一样,是检测变量是否是present的:
#include<iostream>
#include<fstream>
#include<optional>
std::optional<std::string> ReadFileAsString(const std::string& filepath)
{
std::ifstream stream(filepath);
if (stream)
{
std::string result;
//read file
stream.close();
return result;
}
return {};
}
int main()
{
std::optional<std::string> data = ReadFileAsString("data.txt");
// 可以用has_value()来判断是否读取成功
if (data.has_value())
{
std::cout<<"File read successfully!\n";
}
else
{
std::cout<<"File not found!\n";
}
// 也可以用value_or()来判断是否读取成功
std::string result = data.value_or("Not resprent");
//如果数据不存在,就会返回我们传入的值 Not resprent
std::cout<<result<<std::endl;
std::cin.get();
}C++ 一个变量多种类型 std::variant
C++17引入一种可以容纳多种类型变量的结构,std::variant
#include<iostream>
#include<variant>
int main()
{
std::variant<std::string,int> data; // <>里面的类型不能重复
data = "ydc";
// 索引的第一种方式:std::get,但是要与上一次赋值类型相同,不然会报错
std::cout<<std::get<std::string>(data)<<std::endl;
// 索引的第二种方式,std::get_if,传入地址,返回为指针
if (auto value = std::get_if<std::string>(&data))
{
std::string& v = *value;
}
data = 2;
std::cout<<std::get<int>(data)<<std::endl;
std::cin.get();
}std::variant的大小是<>里面的大小之和,与union不一样,union的大小是类型的大小最大值
std::any
也是C++17引入的可以存储多种类型变量的结构,其本质是一个union,但是不像std::variant那样需要列出类型
#include<iostream>
#include<any>
// 此处写一个new的函数,是为了断点,看主函数里面哪里调用了new,来看其堆栈
void* operator new(size_t size)
{
return malloc(size);
}
int main()
{
std::any data;
data = 2;
data = std::string("ydc");
std::string& s = std::any_cast<std::string&>(data);
std::cout<<s<<std::endl;
std::cin.get();
}如何让 string 运行更快
一种调试在heap上分配内存的方法,自己写一个new的方法,然后设置断点或者打出log,就可以知道每次分配了多少内存,以及分配了几次:
#include<iostream>
#include<string>
static uint32_t s_AllocCount = 0;
void* operator new(size_t size)
{
s_AllocCount++;
std::cout<<"Allocing: "<<size<<" bytes\n";
return malloc(size);
}
void PrintName(const std::string& name)
{
std::cout<<name<<std::endl;
}
int main()
{
std::string fullName = "yang dingchao";
std::string firstName = fullName.substr(0,4);
std::string lastName = fullName.substr(5,8);
PrintName(firstName);
PrintName(lastName);
std::cout<<s_AllocCount<<" allocations\n";
std::cin.get();
}以下为运行结果:
Allocing: 8 bytes
Allocing: 8 bytes
Allocing: 8 bytes
yang
dingchao
3 allocations这个程序仅仅是从一个string取子字符串,就多分配了两次内存,下面来改进它
2、用C++17引入的std::string_view来对同一块内存的string进行截取
#include<iostream>
#include<string>
static uint32_t s_AllocCount = 0;
void* operator new(size_t size)
{
s_AllocCount++;
std::cout<<"Allocing: "<<size<<" bytes\n";
return malloc(size);
}
void PrintName(std::string_view name)
{
std::cout<<name<<std::endl;
}
int main()
{
std::string fullName = "yang dingchao";
std::string_view firstName(fullName.c_str(),4);
std::string_view lastName(fullName.c_str()+5,8);
PrintName(firstName);
PrintName(lastName);
std::cout<<s_AllocCount<<" allocations\n";
std::cin.get();
}输出如下:
Allocing: 8 bytes
yang
dingchao
1 allocations3、上面的程序还是有一次分配,如果把std::string改成const char*,就变成了0次分配:
#include<iostream>
#include<string>
static uint32_t s_AllocCount = 0;
void* operator new(size_t size)
{
s_AllocCount++;
std::cout<<"Allocing: "<<size<<" bytes\n";
return malloc(size);
}
void PrintName(std::string_view name)
{
std::cout<<name<<std::endl;
}
int main()
{
const char* fullName = "yang dingchao";
std::string_view firstName(fullName,4);
std::string_view lastName(fullName+5,8);
PrintName(firstName);
PrintName(lastName);
std::cout<<s_AllocCount<<" allocations\n";
std::cin.get();
}输出如下:
yang
dingchao
0 allocationsSingleton单例
Singleton只允许被实例化一次,用于组织一系列全局的函数或者变量,与namespace很像。例子:随机数产生的类、渲染器类。
#include<iostream>
class Singleton
{
public:
Singleton(const Singleton&) = delete; // 删除拷贝复制函数
static Singleton& Get() // 通过Get函数来获取唯一的一个实例,
//其定义为static也是为了能直接用类名调用
{
return s_Instance;
}
void Function(){} // 执行功能的函数
private:
Singleton(){} // 不能让别人实例化,所以要把构造函数放进private
static Singleton s_Instance; // 定义为static,让其唯一
};
Singleton Singleton::s_Instance; // 唯一的实例化的地方
int main()
{
Singleton::Get().Function();
}具体的一个简单的随机数类的例子:
#include<iostream>
class Random
{
public:
Random(const Random&) = delete; // 删除拷贝复制函数
static Random& Get() // 通过Get函数来获取唯一的一个实例
{
static Random instance; // 在此处实例化一次
return instance;
}
static float Float(){ return Get().IFloat();} // 调用内部函数,可用类名调用
private:
float IFloat() { return m_RandomGenerator; } // 将函数的实现放进private
Random(){} // 不能让别人实例化,所以要把构造函数放进private
float m_RandomGenerator = 0.5f;
};
// 与namespace很像
namespace RandomClass {
static float s_RandomGenerator = 0.5f;
static float Float(){return s_RandomGenerator;}
}
int main()
{
float randomNum = Random::Float();
std::cout<<randomNum<<std::endl;
std::cin.get();
}