目录
导言
调整模型结构
定义搜索空间
开始搜索
查询结果
重新训练模型
调整模型训练
调整数据预处理
重新训练模型
指定调整目标
以内置指标为目标
以自定义指标为目标
调整端到端工作流程
将 Keras 代码分开
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
使用 KerasTuner 调整模型超参数的基础知识。
导言
KerasTuner 是一个通用超参数调整库。它与 Keras 工作流集成度很高,但并不局限于 Keras 工作流:你可以用它来调整 scikit-learn 模型或其他任何东西。
在本文中,您将看到如何使用 KerasTuner 调整模型架构、训练过程和数据预处理步骤。
让我们从一个简单的例子开始。
调整模型结构
我们需要做的第一件事是编写一个函数,返回编译后的 Keras 模型。它需要一个参数 hp,用于在构建模型时定义超参数。
定义搜索空间
在下面的代码示例中,我们定义了一个具有两个密集层的 Keras 模型。我们想调整第一个 Dense 层的单元数。我们只需用 hp.Int('units', min_value=32, max_value=512, step=32)定义一个整数超参数,其范围为 32 至 512(含 512)。从中取样时,走过区间的最小步长为 32。
import keras
from keras import layers
def build_model(hp):
model = keras.Sequential()
model.add(layers.Flatten())
model.add(
layers.Dense(
# Define the hyperparameter.
units=hp.Int("units", min_value=32, max_value=512, step=32),
activation="relu",
)
)
model.add(layers.Dense(10, activation="softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model您可以快速测试模型是否构建成功。
import keras_tuner
build_model(keras_tuner.HyperParameters())<Sequential name=sequential, built=False>还有许多其他类型的超参数。我们可以在函数中定义多个超参数。在下面的代码中,我们用 hp.Boolean() 来调整是否使用 Dropout 层,用 hp.Choice() 来调整使用哪个激活函数,用 hp.Float() 来调整优化器的学习率。
def build_model(hp):
model = keras.Sequential()
model.add(layers.Flatten())
model.add(
layers.Dense(
# Tune number of units.
units=hp.Int("units", min_value=32, max_value=512, step=32),
# Tune the activation function to use.
activation=hp.Choice("activation", ["relu", "tanh"]),
)
)
# Tune whether to use dropout.
if hp.Boolean("dropout"):
model.add(layers.Dropout(rate=0.25))
model.add(layers.Dense(10, activation="softmax"))
# Define the optimizer learning rate as a hyperparameter.
learning_rate = hp.Float("lr", min_value=1e-4, max_value=1e-2, sampling="log")
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=learning_rate),
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
build_model(keras_tuner.HyperParameters())<Sequential name=sequential_1, built=False>如下图所示,超参数是实际值。事实上,它们只是返回实际值的函数。例如,hp.Int() 返回一个 int 值。因此,你可以将它们放入变量、for 循环或 if 条件中。
hp = keras_tuner.HyperParameters()
print(hp.Int("units", min_value=32, max_value=512, step=32))结果如下:
32您还可以提前定义超参数,并将 Keras 代码保存在单独的函数中。
def call_existing_code(units, activation, dropout, lr):
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(units=units, activation=activation))
if dropout:
model.add(layers.Dropout(rate=0.25))
model.add(layers.Dense(10, activation="softmax"))
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=lr),
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
def build_model(hp):
units = hp.Int("units", min_value=32, max_value=512, step=32)
activation = hp.Choice("activation", ["relu", "tanh"])
dropout = hp.Boolean("dropout")
lr = hp.Float("lr", min_value=1e-4, max_value=1e-2, sampling="log")
# call existing model-building code with the hyperparameter values.
model = call_existing_code(
units=units, activation=activation, dropout=dropout, lr=lr
)
return model
build_model(keras_tuner.HyperParameters())<Sequential name=sequential_2, built=False>每个超参数的名称(第一个参数)都是唯一标识。为了分别调整不同密集层的单元数作为不同的超参数,我们给它们起了不同的名字,如 f "units_{i}"。
值得注意的是,这也是创建条件超参数的一个例子。有许多超参数指定了密集层中的单元数。此类超参数的数量由层数决定,而层数也是一个超参数。因此,每次试验使用的超参数总数可能不同。有些超参数只有在满足特定条件时才会使用。例如,units_3 仅在 num_layers 大于 3 时使用。使用 KerasTuner,您可以在创建模型时轻松地动态定义此类超参数。
def build_model(hp):
model = keras.Sequential()
model.add(layers.Flatten())
# Tune the number of layers.
for i in range(hp.Int("num_layers", 1, 3)):
model.add(
layers.Dense(
# Tune number of units separately.
units=hp.Int(f"units_{i}", min_value=32, max_value=512, step=32),
activation=hp.Choice("activation", ["relu", "tanh"]),
)
)
if hp.Boolean("dropout"):
model.add(layers.Dropout(rate=0.25))
model.add(layers.Dense(10, activation="softmax"))
learning_rate = hp.Float("lr", min_value=1e-4, max_value=1e-2, sampling="log")
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=learning_rate),
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
build_model(keras_tuner.HyperParameters())<Sequential name=sequential_3, built=False>开始搜索
定义搜索空间后,我们需要选择一个调谐器类来运行搜索。您可以选择随机搜索(RandomSearch)、贝叶斯优化(BayesianOptimization)和超宽带(Hyperband),它们对应不同的调整算法。这里我们以随机搜索为例。
要初始化调谐器,我们需要在初始化器中指定几个参数。
超模型。模型构建函数,在我们的例子中就是 build_model。
目标。要优化的目标名称(内置指标会自动推断是最小化还是最大化)。本教程稍后将介绍如何使用自定义指标。
max_trials(最大试验次数)。搜索过程中要运行的试验总数。
executions_per_trial(每次试验执行次数)。每次试验应建立和拟合的模型数。不同的试验有不同的超参数值。同一试验中的执行次数具有相同的超参数值。每个试验执行多次的目的是减少结果差异,从而更准确地评估模型的性能。如果想更快得到结果,可以设置 executions_per_trial=1(每个模型配置只进行一轮训练)。
覆盖。控制是覆盖同一目录下的上一次结果,还是恢复上一次搜索。这里我们设置 overwrite=True 开始新的搜索并忽略之前的结果。
目录。存储搜索结果的目录路径。
project_name。目录中子目录的名称。
tuner = keras_tuner.RandomSearch(
hypermodel=build_model,
objective="val_accuracy",
max_trials=3,
executions_per_trial=2,
overwrite=True,
directory="my_dir",
project_name="helloworld",
)您可以打印搜索空间的摘要:
tuner.search_space_summary()Search space summary Default search space size: 5 num_layers (Int) {'default': None, 'conditions': [], 'min_value': 1, 'max_value': 3, 'step': 1, 'sampling': 'linear'} units_0 (Int) {'default': None, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': 'linear'} activation (Choice) {'default': 'relu', 'conditions': [], 'values': ['relu', 'tanh'], 'ordered': False} dropout (Boolean) {'default': False, 'conditions': []} lr (Float) {'default': 0.0001, 'conditions': [], 'min_value': 0.0001, 'max_value': 0.01, 'step': None, 'sampling': 'log'}
在开始搜索之前,让我们先准备好 MNIST 数据集。
import keras
import numpy as np
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x[:-10000]
x_val = x[-10000:]
y_train = y[:-10000]
y_val = y[-10000:]
x_train = np.expand_dims(x_train, -1).astype("float32") / 255.0
x_val = np.expand_dims(x_val, -1).astype("float32") / 255.0
x_test = np.expand_dims(x_test, -1).astype("float32") / 255.0
num_classes = 10
y_train = keras.utils.to_categorical(y_train, num_classes)
y_val = keras.utils.to_categorical(y_val, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)然后,开始搜索最佳超参数配置。每次执行时,传给 search 的所有参数都会传给 model.fit()。记住要传递 validation_data 来评估模型。
tuner.search(x_train, y_train, epochs=2, validation_data=(x_val, y_val))Trial 3 Complete [00h 00m 19s]
val_accuracy: 0.9665500223636627Best val_accuracy So Far: 0.9665500223636627
Total elapsed time: 00h 00m 40s在搜索过程中,模型构建函数会在不同的试验中以不同的超参数值被调用。在每次试验中,调谐器都会生成一组新的超参数值来构建模型。然后对模型进行拟合和评估。指标会被记录下来。调谐器会逐步探索空间,最终找到一组好的超参数值。
查询结果
搜索结束后,可以检索最佳模型。模型将保存在根据验证数据评估的最佳性能历元上。
# Get the top 2 models.
models = tuner.get_best_models(num_models=2)
best_model = models[0]
best_model.summary()/usr/local/python/3.10.13/lib/python3.10/site-packages/keras/src/saving/saving_lib.py:388: UserWarning: Skipping variable loading for optimizer 'adam', because it has 2 variables whereas the saved optimizer has 18 variables.
trackable.load_own_variables(weights_store.get(inner_path))
/usr/local/python/3.10.13/lib/python3.10/site-packages/keras/src/saving/saving_lib.py:388: UserWarning: Skipping variable loading for optimizer 'adam', because it has 2 variables whereas the saved optimizer has 10 variables.
trackable.load_own_variables(weights_store.get(inner_path))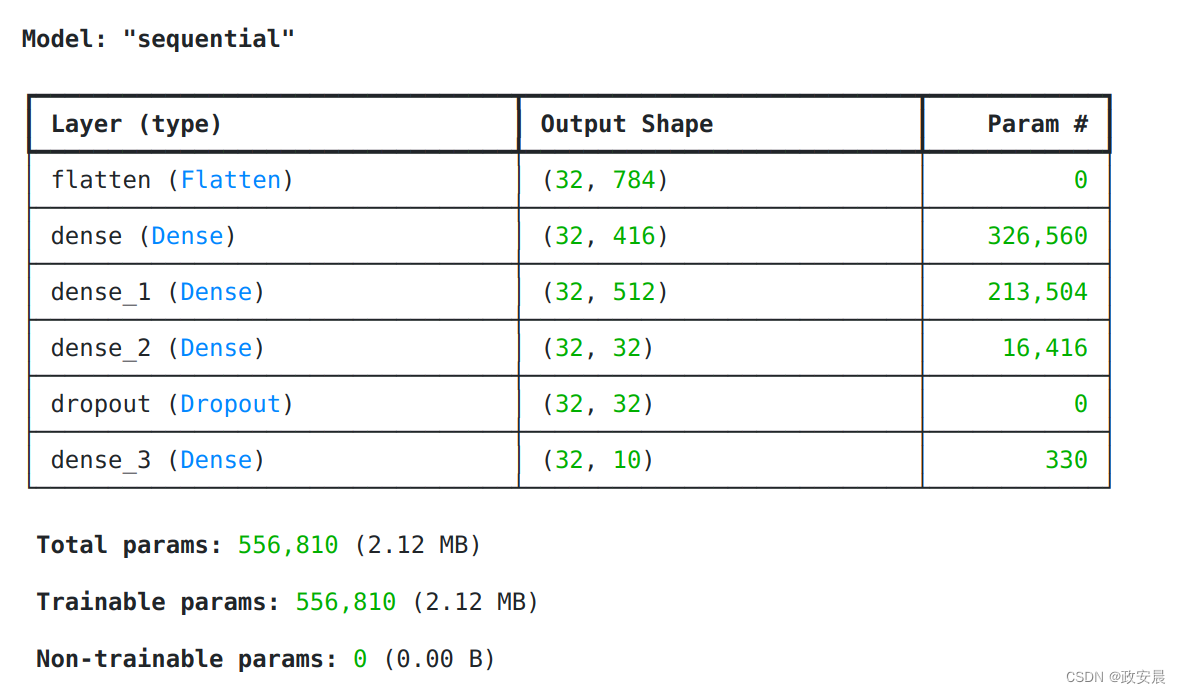
您还可以打印搜索结果摘要。
tuner.results_summary()Results summary
Results in my_dir/helloworld
Showing 10 best trials
Objective(name="val_accuracy", direction="max")Trial 2 summary
Hyperparameters:
num_layers: 3
units_0: 416
activation: relu
dropout: True
lr: 0.0001324166048504802
units_1: 512
units_2: 32
Score: 0.9665500223636627Trial 0 summary
Hyperparameters:
num_layers: 1
units_0: 128
activation: tanh
dropout: False
lr: 0.001425162921397599
Score: 0.9623999893665314Trial 1 summary
Hyperparameters:
num_layers: 2
units_0: 512
activation: tanh
dropout: True
lr: 0.0010584293918512798
units_1: 32
Score: 0.9606499969959259您可以在 my_dir/helloworld 文件夹(即目录/项目名称)中找到详细日志、检查点等信息。
您还可以使用 TensorBoard 和 HParams 插件直观地查看调整结果。
重新训练模型
如果您想用整个数据集来训练模型,可以检索最佳超参数,然后自己重新训练模型。
# Get the top 2 hyperparameters.
best_hps = tuner.get_best_hyperparameters(5)
# Build the model with the best hp.
model = build_model(best_hps[0])
# Fit with the entire dataset.
x_all = np.concatenate((x_train, x_val))
y_all = np.concatenate((y_train, y_val))
model.fit(x=x_all, y=y_all, epochs=1)1/1875 [37m━━━━━━━━━━━━━━━━━━━━ 17:57 575ms/step - accuracy: 0.1250 - loss: 2.3113调整模型训练
为了调整模型构建过程,我们需要对 HyperModel 类进行子类化,这样也可以方便地共享和重用超模型。
我们需要重载 HyperModel.build() 和 HyperModel.fit(),以分别调整模型构建和训练过程。HyperModel.build() 方法与模型构建函数相同,使用超参数创建 Keras 模型并返回。
在 HyperModel.fit() 中,你可以访问 HyperModel.build() 返回的模型、hp 和传给 search() 的所有参数。您需要训练模型并返回训练历史记录。
在下面的代码中,我们将调整 model.fit() 中的 shuffle 参数。
一般情况下不需要调整epochs 的数量,因为会向 model.fit() 传递一个内置回调,以保存模型在验证_数据所评估的最佳epochs。
class MyHyperModel(keras_tuner.HyperModel):
def build(self, hp):
model = keras.Sequential()
model.add(layers.Flatten())
model.add(
layers.Dense(
units=hp.Int("units", min_value=32, max_value=512, step=32),
activation="relu",
)
)
model.add(layers.Dense(10, activation="softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
def fit(self, hp, model, *args, **kwargs):
return model.fit(
*args,
# Tune whether to shuffle the data in each epoch.
shuffle=hp.Boolean("shuffle"),
**kwargs,
)调整数据预处理
要调整数据预处理,我们只需在 HyperModel.fit() 中添加一个额外步骤,从参数中访问数据集。在下面的代码中,我们将调整是否在训练模型前对数据进行归一化处理。这次我们在函数签名中明确写入了 x 和 y,因为我们需要使用它们。
class MyHyperModel(keras_tuner.HyperModel):
def build(self, hp):
model = keras.Sequential()
model.add(layers.Flatten())
model.add(
layers.Dense(
units=hp.Int("units", min_value=32, max_value=512, step=32),
activation="relu",
)
)
model.add(layers.Dense(10, activation="softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
def fit(self, hp, model, x, y, **kwargs):
if hp.Boolean("normalize"):
x = layers.Normalization()(x)
return model.fit(
x,
y,
# Tune whether to shuffle the data in each epoch.
shuffle=hp.Boolean("shuffle"),
**kwargs,
)
hp = keras_tuner.HyperParameters()
hypermodel = MyHyperModel()
model = hypermodel.build(hp)
hypermodel.fit(hp, model, np.random.rand(100, 28, 28), np.random.rand(100, 10))如果超参数在 build() 和 fit() 中同时使用,可以在 build() 中定义它,然后在 fit() 中使用 hp.get(hp_name) 获取它。我们以图像大小为例。它既在构建(build)中用作输入形状,也在数据预处理步骤中用于在拟合(fit)中裁剪图像。
class MyHyperModel(keras_tuner.HyperModel):
def build(self, hp):
image_size = hp.Int("image_size", 10, 28)
inputs = keras.Input(shape=(image_size, image_size))
outputs = layers.Flatten()(inputs)
outputs = layers.Dense(
units=hp.Int("units", min_value=32, max_value=512, step=32),
activation="relu",
)(outputs)
outputs = layers.Dense(10, activation="softmax")(outputs)
model = keras.Model(inputs, outputs)
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
def fit(self, hp, model, x, y, validation_data=None, **kwargs):
if hp.Boolean("normalize"):
x = layers.Normalization()(x)
image_size = hp.get("image_size")
cropped_x = x[:, :image_size, :image_size, :]
if validation_data:
x_val, y_val = validation_data
cropped_x_val = x_val[:, :image_size, :image_size, :]
validation_data = (cropped_x_val, y_val)
return model.fit(
cropped_x,
y,
# Tune whether to shuffle the data in each epoch.
shuffle=hp.Boolean("shuffle"),
validation_data=validation_data,
**kwargs,
)
tuner = keras_tuner.RandomSearch(
MyHyperModel(),
objective="val_accuracy",
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="tune_hypermodel",
)
tuner.search(x_train, y_train, epochs=2, validation_data=(x_val, y_val))Trial 3 Complete [00h 00m 04s]
val_accuracy: 0.9567000269889832
Best val_accuracy So Far: 0.9685999751091003
Total elapsed time: 00h 00m 13s重新训练模型
使用 HyperModel 还可以自行重新训练最佳模型。
hypermodel = MyHyperModel()
best_hp = tuner.get_best_hyperparameters()[0]
model = hypermodel.build(best_hp)
hypermodel.fit(best_hp, model, x_all, y_all, epochs=1)指定调整目标
在之前的所有示例中,我们都使用了验证准确率("val_accuracy")作为调整目标来选择最佳模型。实际上,你可以使用任何指标作为目标。最常用的指标是 "val_loss",即验证损失。
以内置指标为目标
Keras 中还有许多其他内置指标可以用作目标。以下是内置指标列表。
要使用内置指标作为目标,需要遵循以下步骤:
使用内置指标编译模型。例如,您想使用 MeanAbsoluteError()。您需要使用 metrics=[MeanAbsoluteError()]编译模型。您也可以使用其名称字符串来代替:metrics=["mean_absolute_error"]。度量的名称字符串总是类名的蛇形字符串。
确定目标名称字符串。目标名称字符串的格式总是 f "val_{metric_name_string}"。例如,在验证数据上评估均方误差的目标名称字符串应为 "val_mean_absolute_error"。
将其封装到 keras_tuner.Objective 中。我们通常需要将目标封装到 keras_tuner.Objective 对象中,以指定优化目标的方向。例如,我们要最小化均方误差,可以使用 keras_tuner.Objective("val_mean_absolute_error", "min")。方向应为 "min "或 "max"。
将封装好的目标传递给调谐器。
请看下面的代码示例。
def build_regressor(hp):
model = keras.Sequential(
[
layers.Dense(units=hp.Int("units", 32, 128, 32), activation="relu"),
layers.Dense(units=1),
]
)
model.compile(
optimizer="adam",
loss="mean_squared_error",
# Objective is one of the metrics.
metrics=[keras.metrics.MeanAbsoluteError()],
)
return model
tuner = keras_tuner.RandomSearch(
hypermodel=build_regressor,
# The objective name and direction.
# Name is the f"val_{snake_case_metric_class_name}".
objective=keras_tuner.Objective("val_mean_absolute_error", direction="min"),
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="built_in_metrics",
)
tuner.search(
x=np.random.rand(100, 10),
y=np.random.rand(100, 1),
validation_data=(np.random.rand(20, 10), np.random.rand(20, 1)),
)
tuner.results_summary()以自定义指标为目标
您可以实现自己的度量标准,并将其作为超参数搜索目标。这里,我们以均方误差(MSE)为例。首先,我们通过子类化 keras.metrics.Metric 来实现 MSE 指标。记住使用 super().__init__() 的 name 参数为度量器命名,稍后会用到。注意:MSE 实际上是一个内置度量,可以通过 keras.metrics.MeanSquaredError 导入。这只是一个示例,说明如何使用自定义度量作为超参数搜索目标。
from keras import ops
class CustomMetric(keras.metrics.Metric):
def __init__(self, **kwargs):
# Specify the name of the metric as "custom_metric".
super().__init__(name="custom_metric", **kwargs)
self.sum = self.add_weight(name="sum", initializer="zeros")
self.count = self.add_weight(name="count", dtype="int32", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
values = ops.square(y_true - y_pred)
count = ops.shape(y_true)[0]
if sample_weight is not None:
sample_weight = ops.cast(sample_weight, self.dtype)
values *= sample_weight
count *= sample_weight
self.sum.assign_add(ops.sum(values))
self.count.assign_add(count)
def result(self):
return self.sum / ops.cast(self.count, "float32")
def reset_states(self):
self.sum.assign(0)
self.count.assign(0)使用自定义目标运行搜索。
def build_regressor(hp):
model = keras.Sequential(
[
layers.Dense(units=hp.Int("units", 32, 128, 32), activation="relu"),
layers.Dense(units=1),
]
)
model.compile(
optimizer="adam",
loss="mean_squared_error",
# Put custom metric into the metrics.
metrics=[CustomMetric()],
)
return model
tuner = keras_tuner.RandomSearch(
hypermodel=build_regressor,
# Specify the name and direction of the objective.
objective=keras_tuner.Objective("val_custom_metric", direction="min"),
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="custom_metrics",
)
tuner.search(
x=np.random.rand(100, 10),
y=np.random.rand(100, 1),
validation_data=(np.random.rand(20, 10), np.random.rand(20, 1)),
)
tuner.results_summary()如果您的自定义目标难以纳入自定义指标,也可以在 HyperModel.fit() 中自行评估模型并返回目标值。默认情况下,目标值会最小化。在这种情况下,您无需在初始化调整器时指定目标值。不过,在这种情况下,Keras 日志中不会跟踪度量值,而只会跟踪 KerasTuner 日志。因此,使用 Keras 指标的任何 TensorBoard 视图都不会显示这些值。
class HyperRegressor(keras_tuner.HyperModel):
def build(self, hp):
model = keras.Sequential(
[
layers.Dense(units=hp.Int("units", 32, 128, 32), activation="relu"),
layers.Dense(units=1),
]
)
model.compile(
optimizer="adam",
loss="mean_squared_error",
)
return model
def fit(self, hp, model, x, y, validation_data, **kwargs):
model.fit(x, y, **kwargs)
x_val, y_val = validation_data
y_pred = model.predict(x_val)
# Return a single float to minimize.
return np.mean(np.abs(y_pred - y_val))
tuner = keras_tuner.RandomSearch(
hypermodel=HyperRegressor(),
# No objective to specify.
# Objective is the return value of `HyperModel.fit()`.
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="custom_eval",
)
tuner.search(
x=np.random.rand(100, 10),
y=np.random.rand(100, 1),
validation_data=(np.random.rand(20, 10), np.random.rand(20, 1)),
)
tuner.results_summary()如果要在 KerasTuner 中跟踪多个度量指标,但只将其中一个作为目标,则可以返回一个字典,字典的键是度量指标名称,值是度量指标值,例如,返回 {"metric_a":1.0, "metric_b", 2.0}。使用其中一个键作为目标名称,例如,keras_tuner.Objective("metric_a", "min")。
class HyperRegressor(keras_tuner.HyperModel):
def build(self, hp):
model = keras.Sequential(
[
layers.Dense(units=hp.Int("units", 32, 128, 32), activation="relu"),
layers.Dense(units=1),
]
)
model.compile(
optimizer="adam",
loss="mean_squared_error",
)
return model
def fit(self, hp, model, x, y, validation_data, **kwargs):
model.fit(x, y, **kwargs)
x_val, y_val = validation_data
y_pred = model.predict(x_val)
# Return a dictionary of metrics for KerasTuner to track.
return {
"metric_a": -np.mean(np.abs(y_pred - y_val)),
"metric_b": np.mean(np.square(y_pred - y_val)),
}
tuner = keras_tuner.RandomSearch(
hypermodel=HyperRegressor(),
# Objective is one of the keys.
# Maximize the negative MAE, equivalent to minimize MAE.
objective=keras_tuner.Objective("metric_a", "max"),
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="custom_eval_dict",
)
tuner.search(
x=np.random.rand(100, 10),
y=np.random.rand(100, 1),
validation_data=(np.random.rand(20, 10), np.random.rand(20, 1)),
)
tuner.results_summary()调整端到端工作流程
在某些情况下,很难将代码整合到构建和匹配函数中。您还可以通过覆盖 Tuner.run_trial(),将端到端的工作流程集中在一处,从而完全控制试验。你可以把它看作是一个黑盒优化器,可以优化任何事情。
调整任何函数
例如,你可以找到一个 x 值,使 f(x)=x*x+1 最小化。在下面的代码中,我们只需将 x 定义为超参数,并返回 f(x) 作为目标值。用于初始化调整器的超模型和目标参数可以省略。
class MyTuner(keras_tuner.RandomSearch):
def run_trial(self, trial, *args, **kwargs):
# Get the hp from trial.
hp = trial.hyperparameters
# Define "x" as a hyperparameter.
x = hp.Float("x", min_value=-1.0, max_value=1.0)
# Return the objective value to minimize.
return x * x + 1
tuner = MyTuner(
# No hypermodel or objective specified.
max_trials=20,
overwrite=True,
directory="my_dir",
project_name="tune_anything",
)
# No need to pass anything to search()
# unless you use them in run_trial().
tuner.search()
print(tuner.get_best_hyperparameters()[0].get("x"))将 Keras 代码分开
您可以保持所有 Keras 代码不变,然后使用 KerasTuner 对其进行调整。如果您由于某些原因无法修改 Keras 代码,它将非常有用。
它还能为您提供更多灵活性。您不必将模型构建和训练代码分开。不过,这种工作流程无法帮助你保存模型或连接 TensorBoard 插件。
要保存模型,可以使用 trial.trial_id(一个唯一标识试验的字符串)来构建不同路径,以保存不同试验的模型。
import os
def keras_code(units, optimizer, saving_path):
# Build model
model = keras.Sequential(
[
layers.Dense(units=units, activation="relu"),
layers.Dense(units=1),
]
)
model.compile(
optimizer=optimizer,
loss="mean_squared_error",
)
# Prepare data
x_train = np.random.rand(100, 10)
y_train = np.random.rand(100, 1)
x_val = np.random.rand(20, 10)
y_val = np.random.rand(20, 1)
# Train & eval model
model.fit(x_train, y_train)
# Save model
model.save(saving_path)
# Return a single float as the objective value.
# You may also return a dictionary
# of {metric_name: metric_value}.
y_pred = model.predict(x_val)
return np.mean(np.abs(y_pred - y_val))
class MyTuner(keras_tuner.RandomSearch):
def run_trial(self, trial, **kwargs):
hp = trial.hyperparameters
return keras_code(
units=hp.Int("units", 32, 128, 32),
optimizer=hp.Choice("optimizer", ["adam", "adadelta"]),
saving_path=os.path.join("/tmp", f"{trial.trial_id}.keras"),
)
tuner = MyTuner(
max_trials=3,
overwrite=True,
directory="my_dir",
project_name="keep_code_separate",
)
tuner.search()
# Retraining the model
best_hp = tuner.get_best_hyperparameters()[0]
keras_code(**best_hp.values, saving_path="/tmp/best_model.keras")KerasTuner 包括预制的可调整应用程序:HyperResNet 和 HyperXception
这些都是随时可用的计算机视觉超模型。
from keras_tuner.applications import HyperResNet
hypermodel = HyperResNet(input_shape=(28, 28, 1), classes=10)
tuner = keras_tuner.RandomSearch(
hypermodel,
objective="val_accuracy",
max_trials=2,
overwrite=True,
directory="my_dir",
project_name="built_in_hypermodel",
)