文章目录
- 环境准备
- 创建表
- 插入数据
- 查询数据
- 更新数据
- 删除数据
- 覆盖数据
- 修改表结构(Alter Table)
- 修改分区
- 存储过程(Procedures)
Catalog:可以和Spark或者Flink中做一个共享,共享之后,计算引擎才可以去读取计算Hive引擎
环境准备
将如下配置内容放入hive-site.xml配置文件中
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!--Hive开启元数据-->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
并将hudi的jar包hudi-hive-sync-bundle-0.12.0.jar 放到hive的lib中,方便hive查询
cp /opt/software/hudi/hudi-0.12.0/packaging/hudi-hive-sync-bundle/targethudi-hive-sync-bundle-0.12.0.jar /opt/module/hive/lib
启动 Hive 的 Metastore
[root@hadoop102 spark-3.2.2]# nohup hive --service metastore &
[1] 10796
查看进程,有如下情况,则成功!
[root@hadoop102 spark-3.2.2]# netstat -anp|grep 9083
tcp6 0 0 :::9083 :::* LISTEN 10796/java
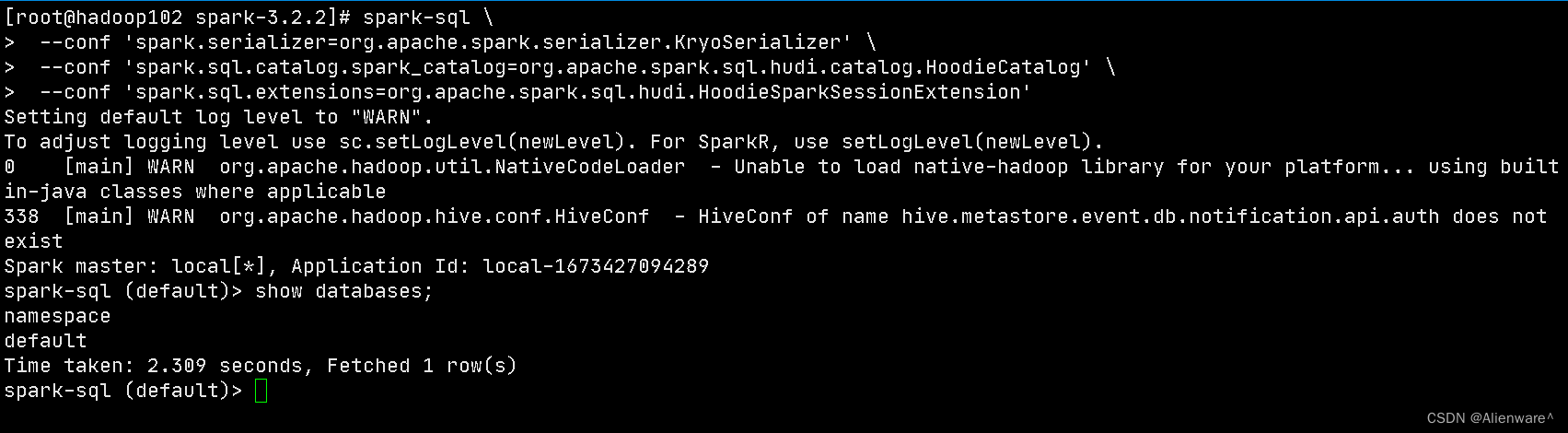
启动 spark-sql
#针对 Spark 3.2
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
如果没有配置 hive 环境变量,手动拷贝 hive-site.xml 到 spark 的 conf 下
创建表
1)建表参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
| primaryKey | uuid | 表的主键名,多个字段用逗号分隔。同 hoodie.datasource.write.recordkey.field |
| preCombineField | 表的预合并字段。同 hoodie.datasource.write.precombine.field | |
| type | cow | 创建的表类型: type = ‘cow’ type = 'mor’同 hoodie.datasource.write.table.type |
2)创建非分区表
(1)创建一个 cow 表,默认 primaryKey ‘uuid’,不提供 preCombineField
create database spark_hudi;
use spark_hudi;
create table hudi_cow_nonpcf_tbl (
uuid int,
name string,
price double
) using hudi;
(2)创建一个 mor 非分区表
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
3)创建分区表
创建一个 cow 分区外部表,指定 primaryKey 和 preCombineField
此刻数据在hdfs上
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/opt/hudi/hudi_cow_pt_tbl';
4)在已有的 hudi 表上创建新表,不需要指定模式和非分区列(如果存在)之外的任何属性,Hudi 可以自动识别模式和配置。
(1)非分区表
create table hudi_existing_tbl0 using hudi
location 'file:///opt/datas/hudi/dataframe_hudi_nonpt_table';
(2)分区表
create table hudi_existing_tbl1 using hudi
partitioned by (dt, hh)
location 'file:///opt/datas/dataframe_hudi_pt_table';
5)通过 CTAS (Create Table As Select)建表为了提高向 hudi 表加载数据的性能,CTAS 使用批量插入作为写操作。
(1)通过 CTAS 创建 cow 非分区表,不指定 preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
as
select 1 as id, 'a1' as name, 10 as price;
(2)通过 CTAS 创建 cow 分区表,指定 preCombineField
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField =
'ts')
partitioned by (dt)
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-
01' as dt;
(3)通过 CTAS 从其他表加载数据
# 创建内部表
create table parquet_mngd using parquet location
'file:///opt/datas/parquet_dataset/*.parquet';
# 通过 CTAS 加载数据
create table hudi_ctas_cow_pt_tbl2 using hudi location
'file://opt/datas/hudi/hudi_tbl/' options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (datestr) as select * from parquet_mngd;
插入数据
默认情况下,如果提供了 preCombineKey,则 insert into 的写操作类型为 upsert,否则使用 insert
1)向非分区表插入数据
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
2)向分区表动态分区插入数据
insert into hudi_cow_pt_tbl partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
3)向分区表静态分区插入数据
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11')
select 2, 'a2', 1000;
4)使用 bulk_insert 插入数据
hudi 支持使用 bulk_insert 作为写操作的类型,只需要设置两个配置:hoodie.sql.bulk.insert.enable 和 hoodie.sql.insert.mode。
-- 向指定 preCombineKey 的表插入数据,则写操作为 upsert
insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
-- 向指定 preCombineKey 的表插入数据,指定写操作为 bulk_insert
set hoodie.sql.bulk.insert.enable=true;
set hoodie.sql.insert.mode=non-strict;
insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
1 a1_2 20.0 1002
查询数据
1)查询
select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0;
2)时间旅行查询
Hudi 从 0.9.0 开始就支持时间旅行查询。Spark SQL 方式要求 Spark 版本 3.2 及以上。
-- 关闭前面开启的 bulk_insert
set hoodie.sql.bulk.insert.enable=false;
-- 数据写入到hdfs上
create table hudi_cow_pt_tbl1 (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/opt/datas/hudi/hudi_cow_pt_tbl1';
-- 插入一条 id 为 1 的数据
insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 修改 id 为 1 的数据
insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 基于第一次提交时间进行时间旅行
select * from hudi_cow_pt_tbl1 timestamp as of '20220307091628793' where id = 1;
-- 其他时间格式的时间旅行写法
select * from hudi_cow_pt_tbl1 timestamp as of '2022-03-07 09:16:28.100' where id = 1;
select * from hudi_cow_pt_tbl1 timestamp as of '2022-03-08' where id = 1;
更新数据
1)update
更新操作需要指定 preCombineField。
(1)语法
UPDATE tableIdentifier SET column = EXPRESSION(,column = EXPRESSION) [ WHERE boolExpression]
(2)执行更新
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1;
update hudi_cow_pt_tbl1 set name = 'a1_1', ts = 1001 where id = 1;
-- update using non-PK field
update hudi_cow_pt_tbl1 set ts = 1111 where name = 'a1_1';
2)MergeInto
(1)语法
MERGE INTO tableIdentifier AS target_alias
USING (sub_query | tableIdentifier) AS source_alias
ON <merge_condition>
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN NOT MATCHED [ AND <condition> ] THEN <not_matched_action> ]
<merge_condition> =A equal bool condition
<matched_action> =
DELETE |
UPDATE SET * |
UPDATE SET column1 = expression1 [, column2 = expression2 ...]
<not_matched_action> =
INSERT * |
INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
(2)执行案例
执行前开启hive的hiveservice2
[root@hadoop102 bin]# ./hiveserver2 start
-- 1、准备 source 表:非分区的 hudi 表,插入数据
create table merge_source (id int, name string, price double, ts
bigint) using hudi tblproperties (primaryKey = 'id', preCombineField = 'ts');
insert into merge_source values (1, "old_a1", 22.22, 2900), (2,
"new_a2", 33.33, 2000), (3, "new_a3", 44.44, 2000);
merge into hudi_mor_tbl as target using merge_source as source on target.id = source.id when matched then update set * when not matched then insert *;
-- 2、准备 source 表:分区的 parquet 表,插入数据
create table merge_source2 (id int, name string, flag string, dt
string, hh string) using parquet;
insert into merge_source2 values (1, "new_a1", 'update', '2021-12-
09', '10'), (2, "new_a2", 'delete', '2021-12-09', '11'), (3,
"new_a3", 'insert', '2021-12-09', '12');
merge into hudi_cow_pt_tbl1 as target
using (
select id, name, '2000' as ts, flag, dt, hh from merge_source2
) source
on target.id = source.id
when matched and flag != 'delete' then
update set id = source.id, name = source.name, ts = source.ts, dt
= source.dt, hh = source.hh
when matched and flag = 'delete' then delete
when not matched then
insert (id, name, ts, dt, hh) values(source.id, source.name,
source.ts, source.dt, source.hh);
mergeInto会发生的报错:
Could not sync using the meta sync class org.apache.hudi.hive.HiveSyncTool
java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=hive, access=EXECUTE, inode="/tmp":root:supergroup:drwxrwx---
解决方案:https://blog.csdn.net/weixin_45417821/article/details/128651942
删除数据
1)语法
DELETE FROM tableIdentifier [ WHERE BOOL_EXPRESSION]
2)案例
delete from hudi_cow_nonpcf_tbl where uuid = 1;
delete from hudi_mor_tbl where id % 2 = 0;
-- 使用非主键字段删除
delete from hudi_cow_pt_tbl1 where name = 'a1_1';
覆盖数据
- 使用 INSERT_OVERWRITE 类型的写操作覆盖分区表
- 使用 INSERT_OVERWRITE_TABLE 类型的写操作插入覆盖非分区表或分区表(动态分区)
1)insert overwrite 非分区表
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
insert overwrite hudi_cow_nonpcf_tbl select 99, 'a99', 20.0;
2)通过动态分区 insert overwrite table 到分区表
insert overwrite table hudi_cow_pt_tbl1 select 10, 'a10', 1100, '2021-12-09', '11';
3)通过静态分区 insert overwrite 分区表
insert overwrite hudi_cow_pt_tbl1 partition(dt = '2021-12-09', hh='12') select 13, 'a13', 1100;
修改表结构(Alter Table)
1)语法
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
-- Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
-- Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = 'value')
2)案例
--rename to:
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl2;
--add column:
ALTER TABLE hudi_cow_nonpcf_tbl2 add columns(remark string);
--change column:
ALTER TABLE hudi_cow_nonpcf_tbl2 change column uuid uuid int;
--set properties;
alter table hudi_cow_nonpcf_tbl2 set tblproperties (hoodie.keep.max.commits = '10');
修改分区
1)语法
-- Drop Partition
ALTER TABLE tableIdentifier DROP PARTITION ( partition_col_name = partition_col_val [ , ... ] )
-- Show Partitions
SHOW PARTITIONS tableIdentifier
2)案例
--show partition:
show partitions hudi_cow_pt_tbl1;
--drop partition:
alter table hudi_cow_pt_tbl1 drop partition (dt='2021-12-09', hh='10');
注意:show partition 结果是基于文件系统表路径的。删除整个分区数据或直接删除某个分区目录并不精确。
存储过程(Procedures)
1)语法
--Call procedure by positional arguments
CALL system.procedure_name(arg_1, arg_2, ... arg_n)
--Call procedure by named arguments
CALL system.procedure_name(arg_name_2 => arg_2, arg_name_1 =>
arg_1, ... arg_name_n => arg_n)
2)案例
可用的存储过程:https://hudi.apache.org/docs/procedures/
--show commit's info
call show_commits(table => 'hudi_cow_pt_tbl1', limit => 10);