大家好,检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种先进的人工智能技术,通过整合大型语言模型(LLM)的内部知识和外部权威数据源,来提升生成式AI模型的表现。
本文将介绍如何有效编写检索查询,进一步提升LLM的输出质量,使用Python和Langchain框架(专为与LLM互动而量身打造的平台)来详细阐述这一过程。通过这种方式,开发者能够更精确地从大量数据中提取所需信息,从而在各种应用场景中实现更高质量的AI生成内容。
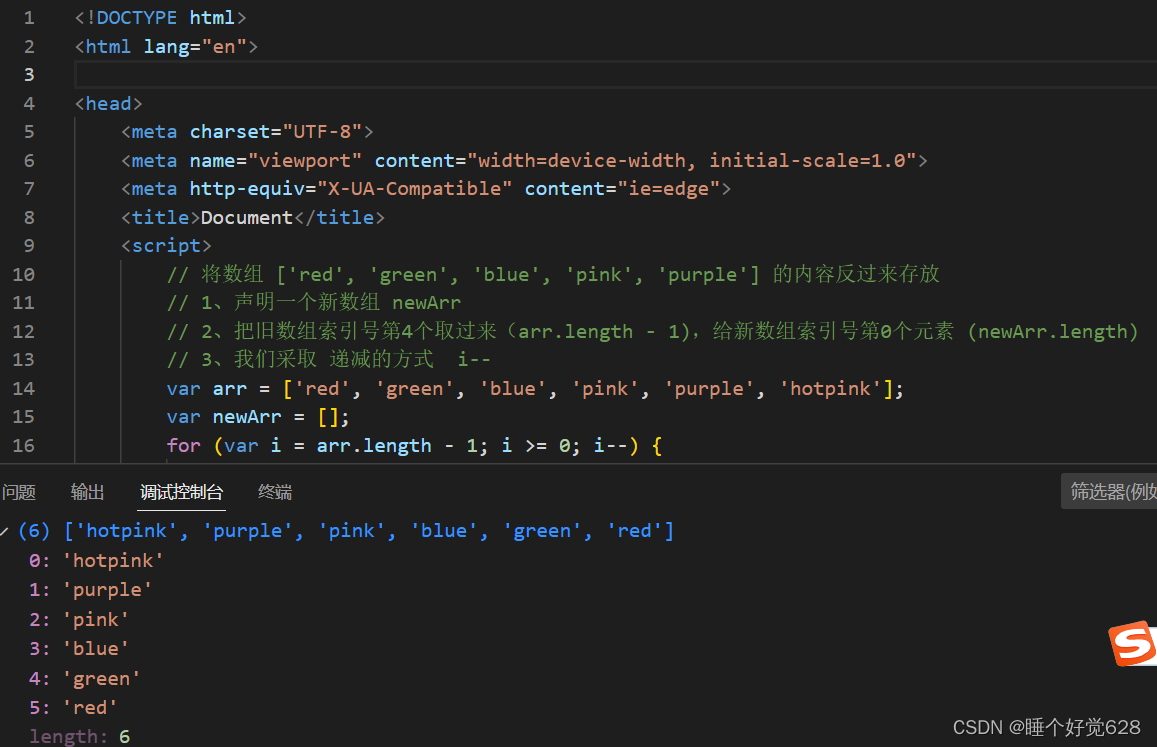
1. 数据集
首先了解一下这里的数据集,使用来自EDGAR(电子数据收集、分析和检索系统)数据库的SEC(证券交易委员会)文件(https://corporatefinanceinstitute.com/resources/valuation/sec-filings/)。这些文件极为宝贵,详细记录了上市公司的财务状况、经营活动和关键信息,如财务报表和重要披露事项。

来自EDGAR数据库的SEC文件的图形数据模型
具体来说,这些数据集包含了各公司提交给SEC的财务表格,如10K和13表格等。这些公司由不同的管理层持股,分布在多个不同的行业中。
为了便于处理,这里将这些财务表格中的文本内容细分为较小的块,并为每个文本块创建向量嵌入,这些嵌入存储在CHUNK节点中。在执行向量搜索查询时,会对比查询向量与CHUNK节点的向量,以此来定位和提取最为相似的文本块。这种方法能够有效地从大量复杂的财务信息中提取有价值的数据。
2. 构建检索查询
在构建检索查询的过程中,首先利用相似性搜索查询得到的结果,即每个相关节点(node)及其对应的相似度得分(score)。将这些结果作为输入,进一步执行检索查询。这一步骤目的是深入挖掘与这些节点相连的数据,从而获取更完整的信息。
为了实现这一目标,检索查询不仅要返回原始的节点和得分,还需要包含文本内容(text)和附加的元数据(metadata),这些元数据可以提供关于数据项的更多背景信息。通过这种方式,能够确保检索查询的结果既准确又有深度,为用户提供全面的数据视角。
retrieval_query = """
WITH node AS doc, score as similarity
# 这里还有一些查询
RETURN <something> as text, similarity as score,
{<something>: <something>} AS metadata
"""
框架已经建立,现在需要明确想要从中提取的信息。在相似性搜索过程中,数据模型会识别出CHUNK节点,这些节点在查询中以node AS doc的形式出现。由于单个文本块(CHUNK)本身并不包含丰富的上下文信息,我们的目标是获取与这些CHUNK节点相连接的Form、Person、Company、Manager和Industry等实体节点。为了更全面地理解文本内容,还希望包括与每个CHUNK节点相邻的文本块,即前一个和后一个文本块(通过NEXT关系连接)。
此外,计划提取每个块及其相应的相似性得分,但为了提高效率和针对性,决定只聚焦于相似度最高的前5个块。这样的策略可以帮助更精确地筛选出最相关的信息,同时减少不必要的数据处理。通过这种方法,能够构建一个既精确又高效的检索系统,为用户提供最有价值的数据。
retrieval_query = """
WITH node AS doc, score as similarity
ORDER BY similarity DESC LIMIT 5
CALL { WITH doc
OPTIONAL MATCH (prevDoc:Chunk)-[:NEXT]-->(doc)
OPTIONAL MATCH (doc)-[:NEXT]-->(nextDoc:Chunk)
RETURN prevDoc, doc AS result, nextDoc
}
RETURN coalesce(prevDoc.text,'') + coalesce(document.text,'') + coalesce(nextDoc.text,'') as text,
similarity as score,
{<something>: <something>} AS metadata
"""
我们的目标是筛选出与查询最为相似的五个文本块,并在子查询中提取这些块的前后文本。为了实现这一点,对RETURN语句进行了调整,以便将相邻的文本块内容合并到一个名为text的变量中。在这个过程中,利用了coalesce()函数来确保即使在缺少前一个或后一个文本块的情况下,也能够平滑地处理这些空值,仅返回一个空字符串,从而保证了查询结果的完整性和一致性。
来添加更多的上下文,以提取图中的其他相关实体。
retrieval_query = """
WITH node AS doc, score as similarity
ORDER BY similarity DESC LIMIT 5
CALL { WITH doc
OPTIONAL MATCH (prevDoc:Chunk)-[:NEXT]->(doc)
OPTIONAL MATCH (doc)-[:NEXT]->(nextDoc:Chunk)
RETURN prevDoc, doc AS result, nextDoc
}
WITH result, prevDoc, nextDoc, similarity
CALL {
WITH result
OPTIONAL MATCH (result)-[:PART_OF]->(:Form)<-[:FILED]-(company:Company), (company)<-[:OWNS_STOCK_IN]-(manager:Manager)
WITH result, company.name as companyName, apoc.text.join(collect(manager.managerName),';') as managers
WHERE companyName IS NOT NULL OR managers > ""
WITH result, companyName, managers
ORDER BY result.score DESC
RETURN result as document, result.score as popularity, companyName, managers
}
RETURN coalesce(prevDoc.text,'') + coalesce(document.text,'') + coalesce(nextDoc.text,'') as text,
similarity as score,
{documentId: coalesce(document.chunkId,''), company: coalesce(companyName,''), managers: coalesce(managers,''), source: document.source} AS metadata
"""
在执行第二个CALL {}子查询时,目标是获取与查询相关的Form、Company和Manager节点信息。使用OPTIONAL MATCH能够灵活地处理可能存在或缺失的节点。对于管理者信息,将其累积到一个列表中,并确保公司名称和管理者列表在返回结果时非空。
尽管目前没有利用得分来提供具体价值,但它可以作为一个有用的指标,记录文档被检索的频次。因此根据得分对结果集进行排序,以便对检索频率有一个直观的认识。
由于查询结果只返回text、score和metadata三个属性,需要将额外的信息,如documentId、company和managers,整合到metadata字典中。这样,最终的RETURN语句将包含所有必要的信息,确保返回的数据既全面又结构化。





![[蓝桥杯练习题]出差](https://img-blog.csdnimg.cn/direct/31eaf66539ea4ddcbf180ee66e307310.png)