2023 05 01 重复局面
- 题目
- 题解1
- 题解2
- 区别:
- 数据存储方式:
- 时间复杂度:
- 空间复杂度:
- 总结:
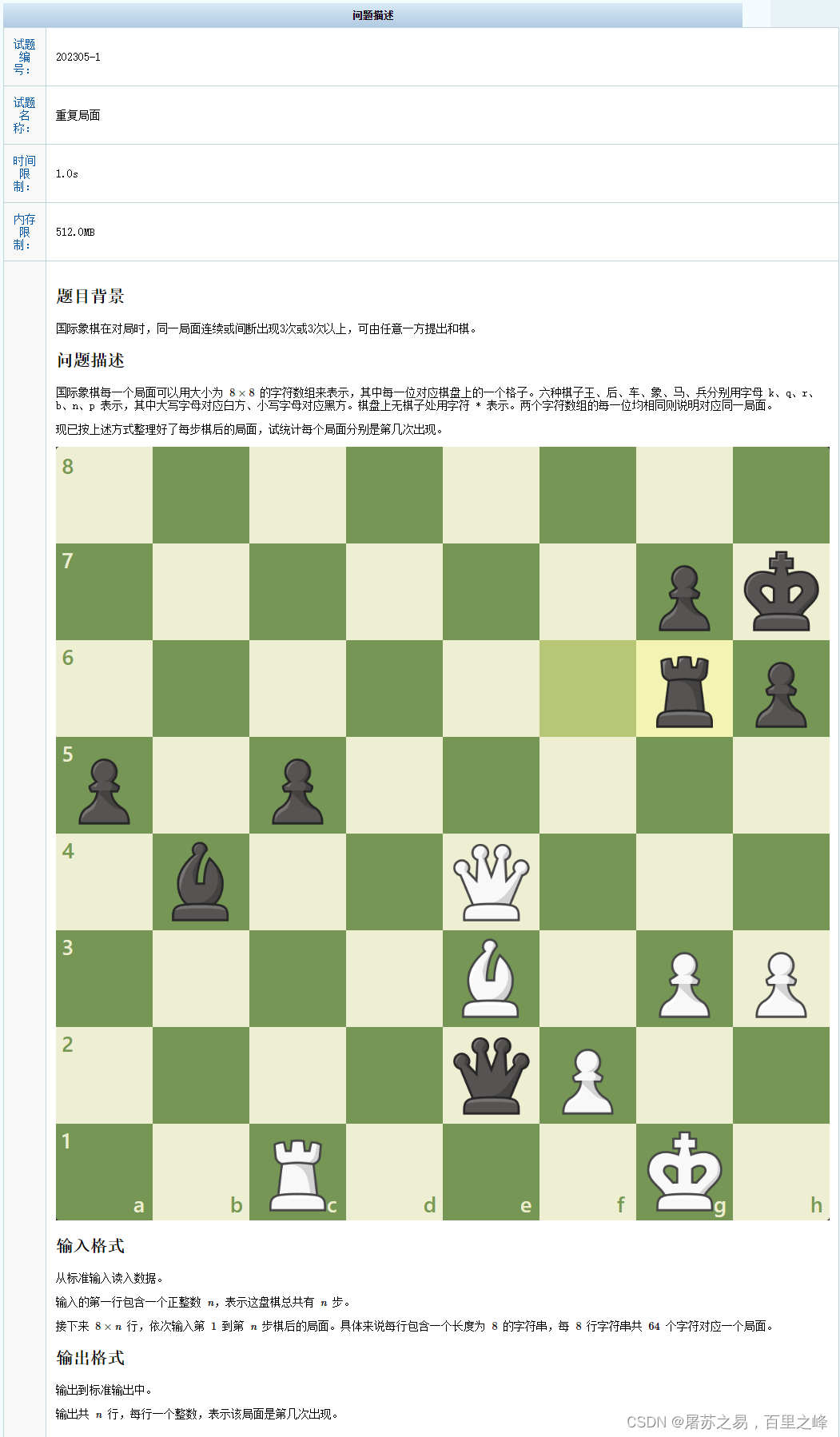
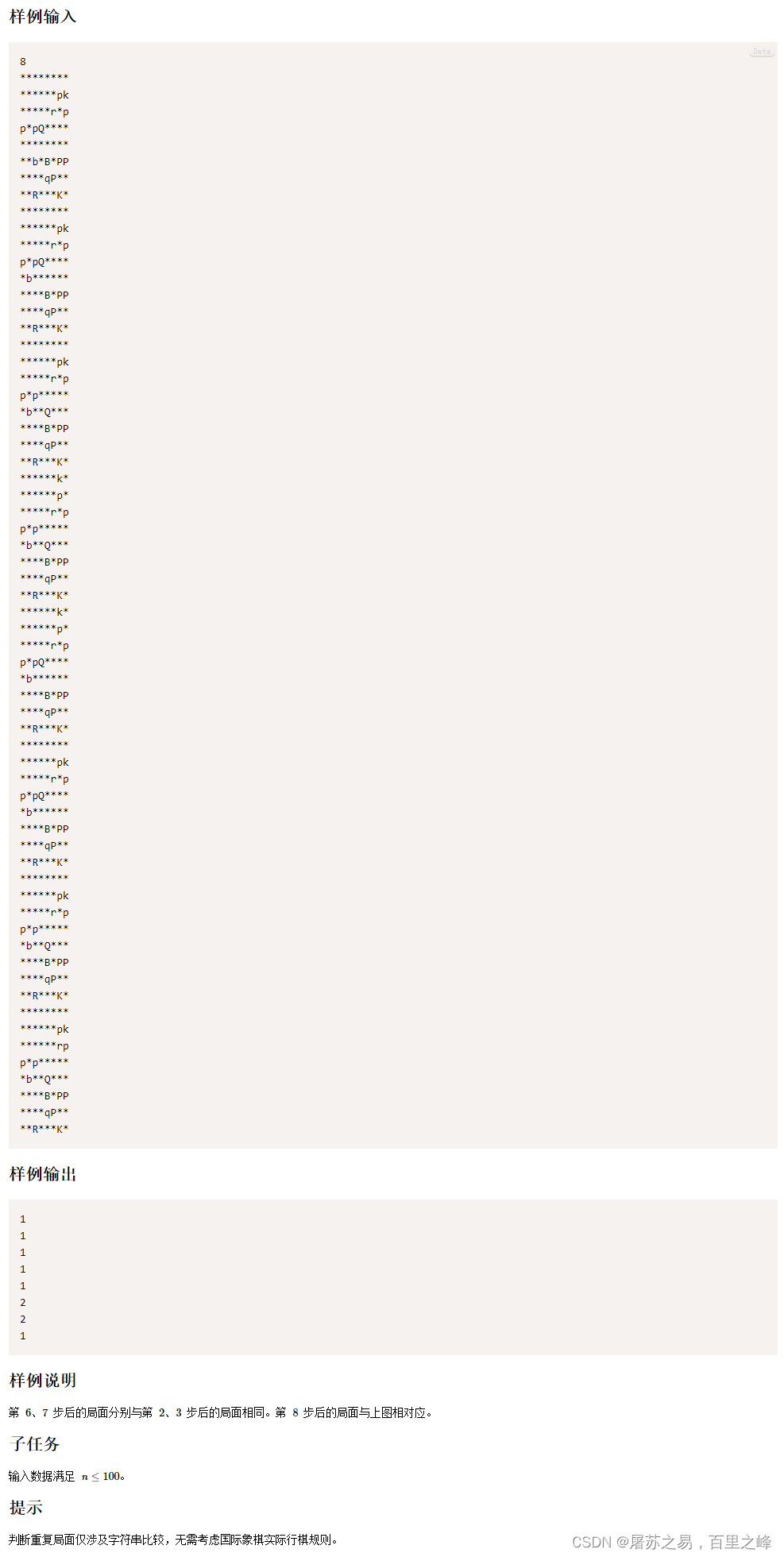
题目
题解1
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
int n = input.nextInt(); // 输入n,表示字符串数量
HashMap<String, Integer> strs = new HashMap<>(); // 创建一个HashMap,用于存储字符串及其出现次数
for (int i = 0; i < n; i++) {
String str = ""; // 初始化空字符串用于存储当前输入的字符串
// 依次输入8个字符串,并拼接成一个完整的字符串
for (int j = 0; j < 8; j++) {
String s = input.next();
str += s;
}
if (i == 0) {
// 如果是第一个字符串,直接输出1,并将该字符串放入HashMap中
System.out.println(1);
strs.put(str, 1);
} else {
if (strs.containsKey(str)) {
// 如果HashMap中已存在该字符串,更新其出现次数
strs.put(str, strs.get(str) + 1);
} else {
// 如果HashMap中不存在该字符串,将其放入HashMap,并设置出现次数为1
strs.put(str, 1);
}
// 输出该字符串出现的次数
System.out.println(strs.get(str));
}
}
}
}
题解2
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 输入n,表示字符串数量
String res[] = new String[n]; // 用于存储输入的字符串
int j = -1, count = 1;
// 获取输入
for (int i = 0; i < 8 * n; i++) {
if (i % 8 == 0) {
j++; // 每8个字符换行存储到res数组中
}
res[j] += sc.next(); // 读取下一个字符串,并拼接到对应位置
}
System.out.println(1); // 第一个字符串输出1,因为第一个肯定是唯一的
j = 0;
// 判断输出
for (int i = 1; i < n; i++) {
for (j = 0; j < i; j++) {
if (res[i].equals(res[j])) {
count++; // 如果与之前的字符串相同,计数加1
}
}
System.out.println(count); // 输出该字符串出现的次数
count = 1; // 重置计数器为1,准备下一个字符串的判断
}
}
}
区别:
数据存储方式:
题解1中使用了HashMap,将每个字符串作为键,出现次数作为值,实现了O(1)时间复杂度的查找和更新。
题解2中使用了一个String数组,每个位置存储一个字符串,通过比较字符串的方式来统计出现次数。这样的方法比较低效,因为每次查找都需要遍历整个数组。
时间复杂度:
题解1中使用HashMap,查找和更新的时间复杂度都是O(1),因此整体时间复杂度是O(n)。
题解2中使用了两个嵌套的循环来比较字符串,时间复杂度为O(n^2),效率较低。
空间复杂度:
题解1中HashMap的空间复杂度取决于不同的字符串数量,最坏情况下是O(n)。
题解2中使用了一个String数组,空间复杂度也取决于不同的字符串数量,最坏情况下也是O(n)。
总结:
题解1使用HashMap的方式更加高效,可以快速统计每个字符串出现的次数,而且代码相对简洁。
题解2虽然实现了相同的功能,但由于字符串比较的方式导致时间复杂度高,适用于数据量较小的情况。