开源地址:https://gitee.com/paddlepaddle/PaddleNLP.git
PaddleNLP是一款简单易用且功能强大的自然语言处理开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。
一键预测:
PaddleNLP提供一键预测功能,无需训练,直接输入数据即可开放域抽取结果:
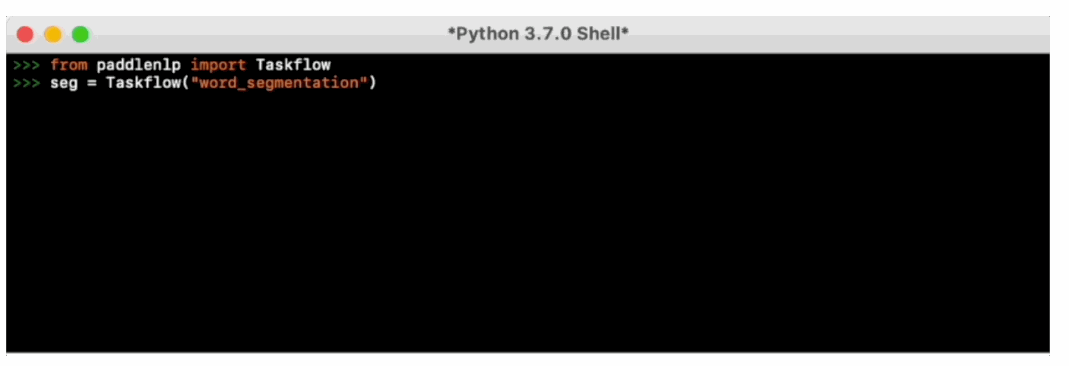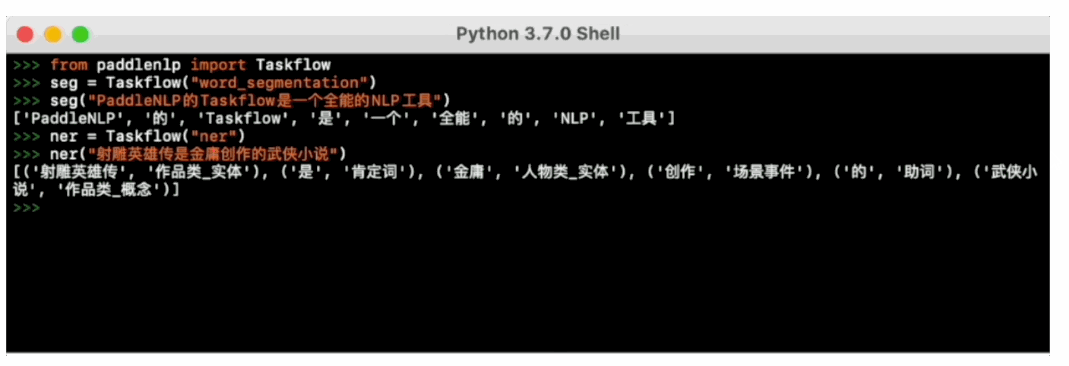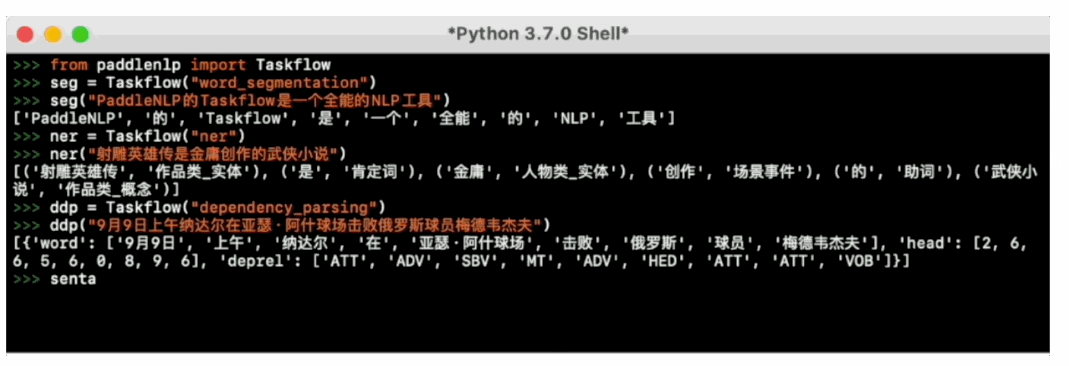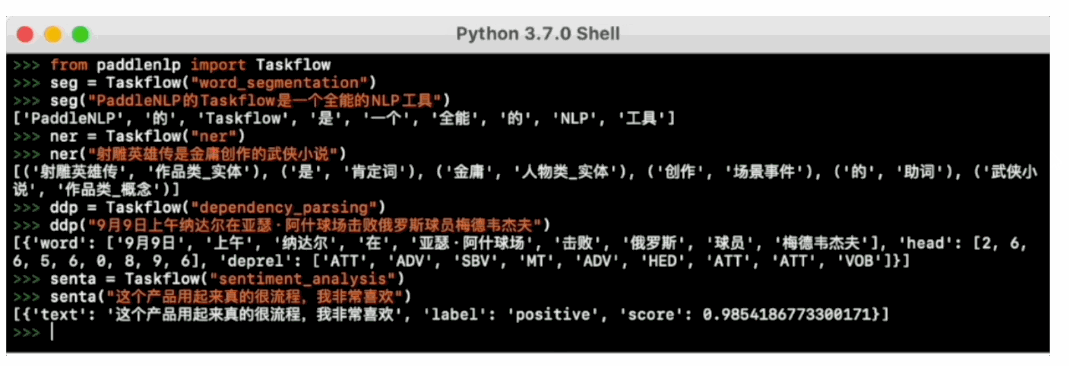
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
>>> ie = Taskflow('information_extraction', schema=schema)
>>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!"))
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503089953268272,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]
2023.6.12 发布 PaddleNLP v2.6rc 预览版
🔨 大模型全流程范例:全面支持主流开源大模型BLOOM, ChatGLM, GLM, LLaMA, OPT的训练和推理;Trainer API新增张量训练能力, 简单配置即可开启分布式训练;新增低参数微调能力PEFT, 助力大模型高效微调
2023.1.12 发布 PaddleNLP v2.5
🔨 NLP工具:发布 PPDiffusers 国产化的扩散模型工具箱,集成多种 Diffusion 模型参数和模型组件,提供了 Diffusion 模型的完整训练流程,支持 Diffusion 模型的高性能 FastDeploy 推理加速 和 多硬件部署(可支持昇腾芯片、昆仑芯部署)
💎 产业应用:信息抽取、文本分类、情感分析、智能问答 四大应用全新升级,发布文档信息抽取 UIE-X 、统一文本分类 UTC 、统一情感分析 UIE-Senta 、无监督问答应用;同时发布ERNIE 3.0 Tiny v2 系列预训练小模型,在低资源和域外数据效果更强,开源 模型裁剪、模型量化、FastDeploy 推理加速、边缘端部署 端到端部署方案,降低预训练模型部署难度
💪 框架升级:预训练模型参数配置统一,自定义参数配置的保存和加载无需额外开发;Trainer API 新增 BF16 训练、Recompute 重计算、Sharding 等多项分布式能力,通过简单配置即可进行超大规模预训练模型训练;模型压缩 API 支持量化训练、词表压缩等功能,压缩后的模型精度损失更小,模型部署的内存占用大大降低;数据增强API 全面升级,支持字、词、句子三种粒度数据增强策略,可轻松定制数据增强策略
🤝 生态联合:🤗Huggingface hub 正式兼容 PaddleNLP 预训练模型,支持 PaddleNLP Model 和 Tokenizer 直接从 🤗Huggingface hub 下载和上传,欢迎大家在 🤗Huggingface hub 体验 PaddleNLP 预训练模型效果
2022.9.6 发布 PaddleNLP v2.4
🔨 NLP工具:NLP 流水线系统 Pipelines 发布,支持快速搭建搜索引擎、问答系统,可扩展支持各类NLP系统,让解决 NLP 任务像搭积木一样便捷、灵活、高效!
💎 产业应用:新增 文本分类全流程应用方案 ,覆盖多分类、多标签、层次分类各类场景,支持小样本学习和 TrustAI 可信计算模型训练与调优。
🍭 AIGC :新增代码生成 SOTA 模型CodeGen,支持多种编程语言代码生成;
💪 框架升级:模型自动压缩 API 发布,自动对模型进行裁减和量化,大幅降低模型压缩技术使用门槛;小样本 Prompt能力发布,集成 PET、P-Tuning、RGL 等经典算法。