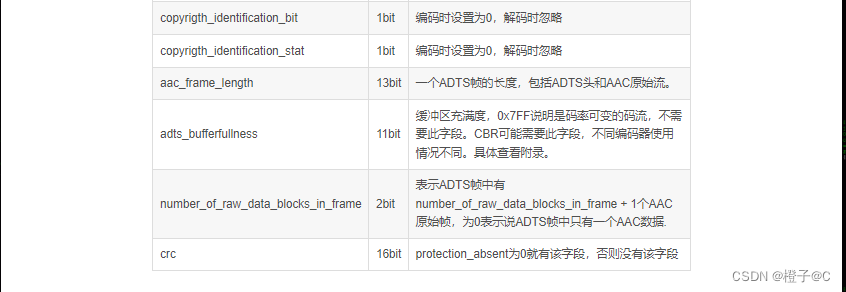
一、执行计划
MySQL 的执行计划(Execution Plan)是数据库查询优化器生成的一种指导性信息,它描述了 MySQL 执行查询时所采用的具体执行策略。执行计划通常由 MySQL 的查询优化器根据查询语句、表结构、索引等信息进行生成,并且用于指导 MySQL 数据库引擎执行查询操作。
下面是 MySQL 执行计划的一般生成过程和主要内容:
-
查询解析与语法分析:
- MySQL 首先对查询语句进行解析和语法分析,以确定查询的语义和语法是否正确。如果语句无法通过解析或语法分析阶段,MySQL 将返回相应的错误信息。
-
查询优化:
- 在确定查询语句的语法正确后,MySQL 的查询优化器开始优化查询。优化过程包括但不限于以下几个方面:
表的访问顺序:优化器决定查询中各个表的访问顺序,以尽可能减少查询中需要访问的数据量。(确定驱动表、被驱动表)索引选择:优化器确定是否使用索引以及使用哪个索引来执行查询,以加速数据检索。连接算法:对于连接查询(如 INNER JOIN、LEFT JOIN 等),优化器选择合适的连接算法来执行连接操作,以提高查询效率。子查询优化:对于存在子查询的查询语句,优化器会尝试将其转换为更高效的方式来执行。其他优化策略:优化器可能还会考虑一些其他的优化策略,如临时表的使用、排序策略等。
- 在确定查询语句的语法正确后,MySQL 的查询优化器开始优化查询。优化过程包括但不限于以下几个方面:
-
生成执行计划:
- 在完成查询优化后,MySQL 的查询优化器将生成执行计划。执行计划是一个执行查询的具体步骤序列,它描述了 MySQL 数据库引擎在执行查询时的具体策略和顺序。
-
执行查询:
- MySQL 数据库引擎根据生成的执行计划,执行查询操作。执行计划中的每一步都对应着一个具体的执行操作,如全表扫描、索引扫描、连接操作等。数据库引擎会按照执行计划中的步骤顺序执行查询,并且根据需要将中间结果暂存到临时表中。
-
返回结果:
- 当查询执行完成后,MySQL 数据库引擎将查询结果返回给客户端。客户端可以根据查询结果来进行相应的后续处理。
二、explain关键字——查询执行计划
EXPLAIN 是 MySQL 中用于查看查询执行计划的关键字,通过执行 EXPLAIN 可以获取查询的执行计划信息。EXPLAIN 输出的结果是一组记录,每条记录包含一些字段,这些字段提供了关于查询执行计划的详细信息。下面是 EXPLAIN 输出结果中每种字段的作用和分类:
-
id:
- 这是每个查询操作在执行计划中的唯一标识符。如果查询中包含子查询或联合查询等复杂结构,可能会有多个 id。
-
select_type:
- 表示查询的类型,常见的有:
SIMPLE:简单的 SELECT 查询,不包含子查询或 UNION。PRIMARY:主查询(外层查询)。SUBQUERY:子查询。UNION:UNION 查询。DERIVED:派生表查询,表示从 FROM 子句中派生出的临时表。UNION RESULT:UNION 查询的结果。
- 表示查询的类型,常见的有:
-
table:
- 表示查询操作涉及的表名。如果查询使用了别名,则显示别名。
-
type:
- 表示访问表的方式,常见的有:
const:通过常量条件进行检索,通常是主键或唯一索引的等值查询。eq_ref:使用索引进行连接,且连接条件是唯一索引。ref:使用非唯一索引进行连接。range:通过范围查找,通常出现在带有范围条件(如 BETWEEN、IN)的查询中。index:全索引扫描,访问全表索引,但不需要读取实际的数据行。all:全表扫描,需要遍历整张表。
- 表示访问表的方式,常见的有:
-
possible_keys:
- 表示可能应用到查询中的索引列表,这是一个提示性信息,不一定实际使用到了所有的索引。
-
key:
- 表示实际使用到的索引。如果该值为 NULL,则表示没有使用到索引。
-
key_len:
- 表示索引使用的长度。如果使用了复合索引,该字段表示索引使用的总长度。
-
ref:
- 表示对索引的哪个列进行了引用。常见的有列名、常量等。
-
rows:
- 表示 MySQL 估计需要扫描的行数。这是一个估算值,不一定与实际扫描的行数完全相符。
-
filtered:
- 表示在某个表上执行条件过滤的百分比。越大,数据越精确
-
Extra:
- 表示额外的信息,常见的有:
Using index:表示使用了覆盖索引,查询只用到了索引而不需要访问表。Using where:表示使用了 WHERE 条件过滤。Using temporary:表示使用了临时表。Using filesort:表示使用了文件排序。
- 表示额外的信息,常见的有:
通过分析 EXPLAIN 输出的结果,可以了解查询的执行计划、访问方式、是否使用了索引、是否存在性能瓶颈等信息,从而优化查询语句和索引设计,提高查询性能。
三、使用explain案例
假设有以下表结构:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
email VARCHAR(100),
INDEX idx_age (age),
INDEX idx_name_email (name, email)
);
现在我们来分析几个查询语句的执行计划:
- 简单的等值查询:
EXPLAIN SELECT id,name,age FROM users WHERE id = 1;
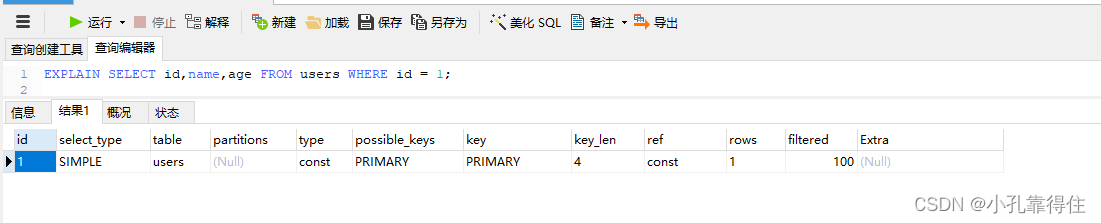
type是 const,表示使用了常量条件进行检索,因为是根据主键等值查询,所以性能很高。key是 PRIMARY,表示使用了主键索引。rows是 1,表示 MySQL 只需扫描 1 行数据。
- 使用索引的范围查询:
EXPLAIN SELECT id,name,age FROM users WHERE age > 30;

type是 ALL,表示使用了全表查找,这里理论上type=range,但是优化器也会将数据量作为参考的标准,数据量小,走索引便没有必要了,毕竟索引维护也需要成本。possible_key是 idx_age,表示可供选择的索引:有 age 列的索引。rows是 估算的行数,表示 MySQL 需要扫描的行数。
- 使用覆盖索引的查询:
EXPLAIN SELECT name, email FROM users WHERE age > 30;
type是 index,表示使用了索引扫描。key是 idx_age,表示使用了 age 列的索引。Extra中有 Using index,表示查询只使用了索引而不需要访问表数据。
- 多列索引的查询:
EXPLAIN SELECT * FROM users WHERE name = 'Alice' AND email = 'alice@example.com';

type是 ref,表示使用了非唯一索引进行连接。key是 idx_name_email,表示使用了 name 和 email 列的联合索引。rows是 估算的行数,表示 MySQL 需要扫描的行数。
- 联合查询:
EXPLAIN SELECT id,name,age,email FROM users WHERE age > 30 UNION SELECT * FROM users WHERE name = 'Alice';
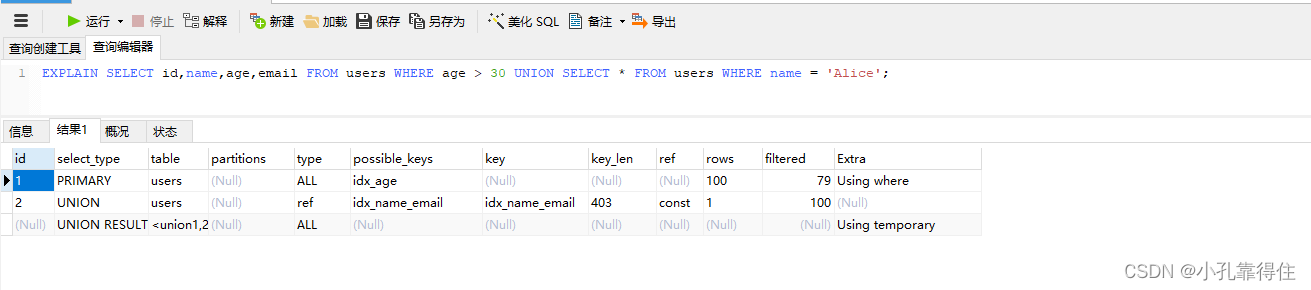
select_type是 union,表示使用了 UNION 查询。key和Extra字段显示的信息与各个子查询类似。
- 带有连接条件的联合查询:
EXPLAIN SELECT u1.name,u1.age,u1.email FROM users u1 INNER JOIN users u2 ON u1.age = u2.age WHERE u1.name = 'Alice';
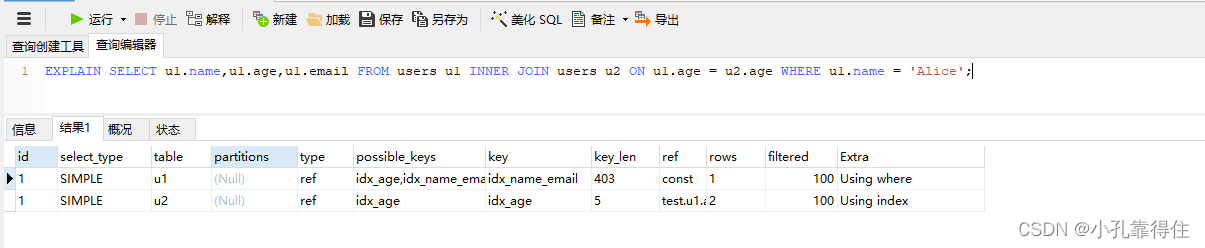
type是 ref,表示使用了非唯一索引进行连接。key是 idx_age,表示使用了 age 列的索引。rows是 估算的行数,表示 MySQL 需要扫描的行数。
- 子查询:
EXPLAIN SELECT id,name,age,email FROM users WHERE age > (SELECT AVG(age) FROM users);
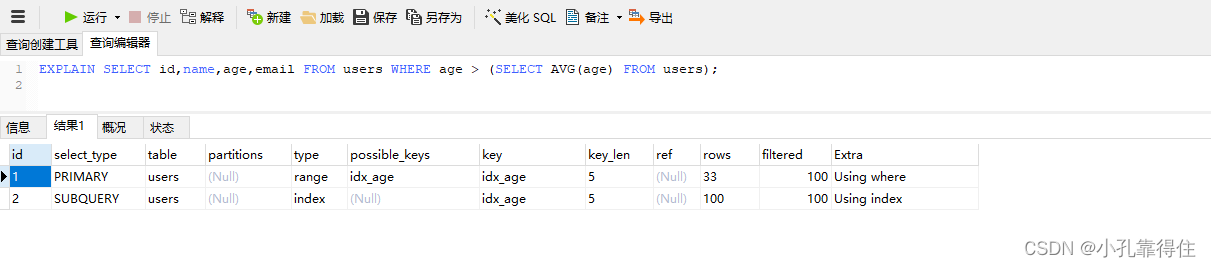
- 主查询的
type是 range,表示使用了范围查找。 - 子查询的
type与具体情况有关,可能是 subquery 或 derived。 key和rows字段显示的信息与主查询类似。
- 使用函数的查询:
EXPLAIN SELECT id,name,age,email FROM users WHERE SUBSTRING(name, 1, 1) = 'A';
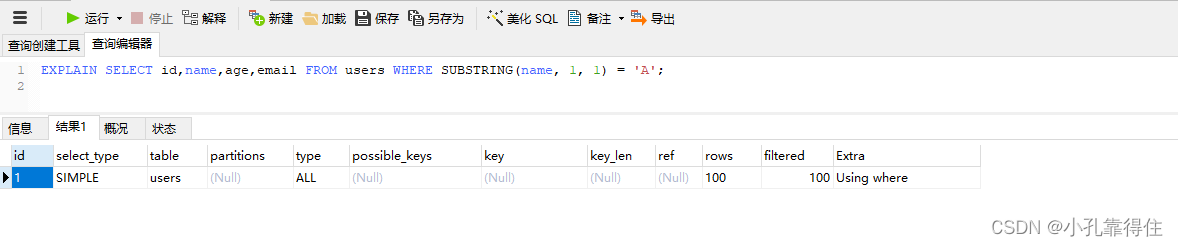
type是 ALL,表示使用了全表扫描。Extra中有 Using where,表示查询使用了 WHERE 条件过滤。- 使用了函数对值或者格式进行修改了,不走索引
通过分析这些查询语句的 EXPLAIN 输出,我们可以了解到更复杂查询的执行计划、访问方式、是否使用了索引等信息。这些信息可以帮助我们优化查询语句、索引设计以及数据库结构,从而提高查询性能。