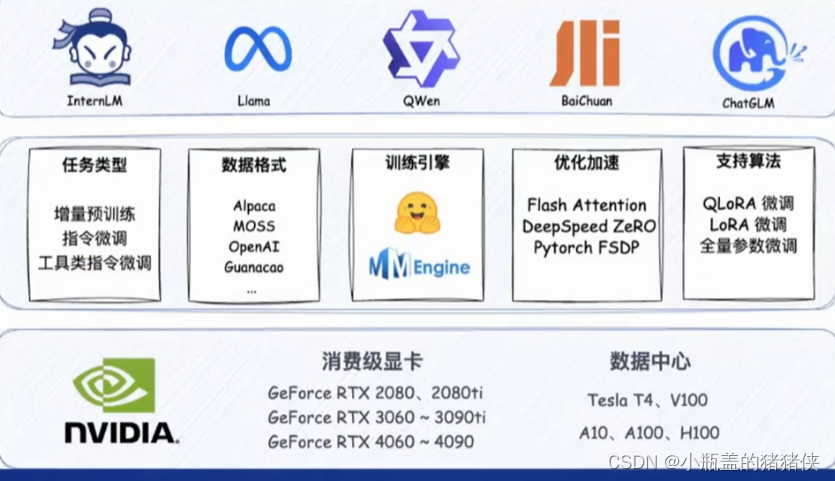
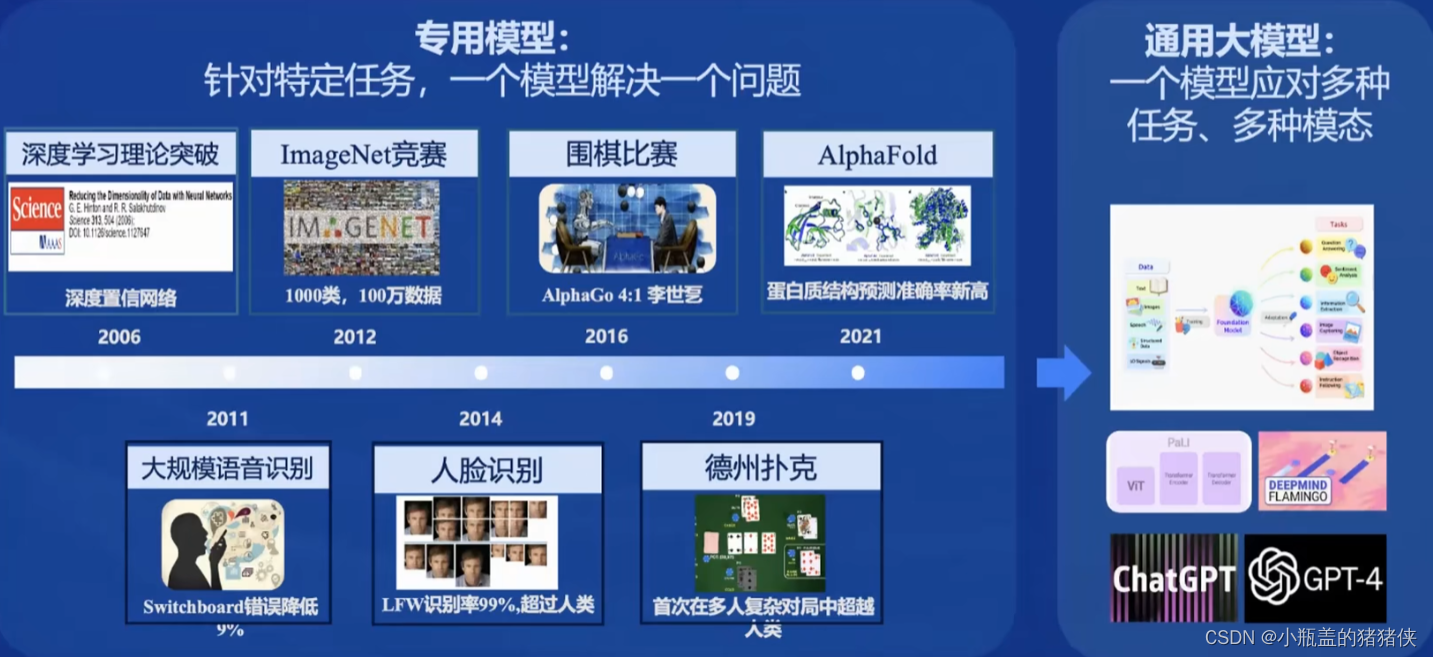
模型的发展
从专业模型到通用模型
书生·浦语大模型全链路开源体系
2023.06.07 -> InternLM千亿参数语言大模型发布
2023.07.06 -> InternLM千亿参数语言大模型全面升级,支持8K语境、26种语言。全面开源、免费商用:InternLM-7B、全链条开源工具体系
2023.08.14 -> 书生·万卷1.0多模态预训练语料库开源发布
2023.08.21 -> 升级版对话模型InternLM-Chat-7B v1.1发布,开源智能体框架Lagent,支持从语言模型到智能体升级转换
2023.08.28 -> InternLM 千亿参数模型的参数两升级到123B
2023.09.20 -> 增强版InternLM-20B开源,开源工具链全线升级
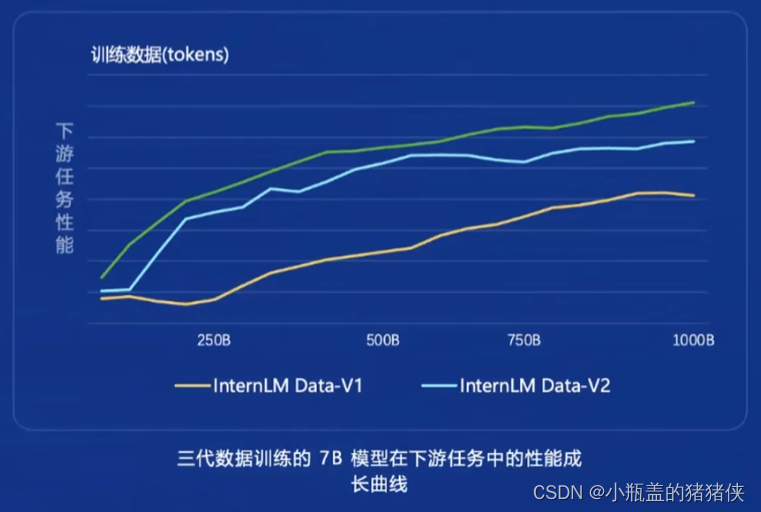
回归语言模型本质
1、多维数据价值评价
基于文本质量、信息质量、信息密度等维度对数据简直进行综合评估和提升
2、高质量预料驱动的数据富集
利用高质量语料的特征从物理世界、互联网以及语料进一步富集耕读类似语料
针对性数据补齐
3、针对性补充语料
重点加强世界知识、数理、代码等核心能力
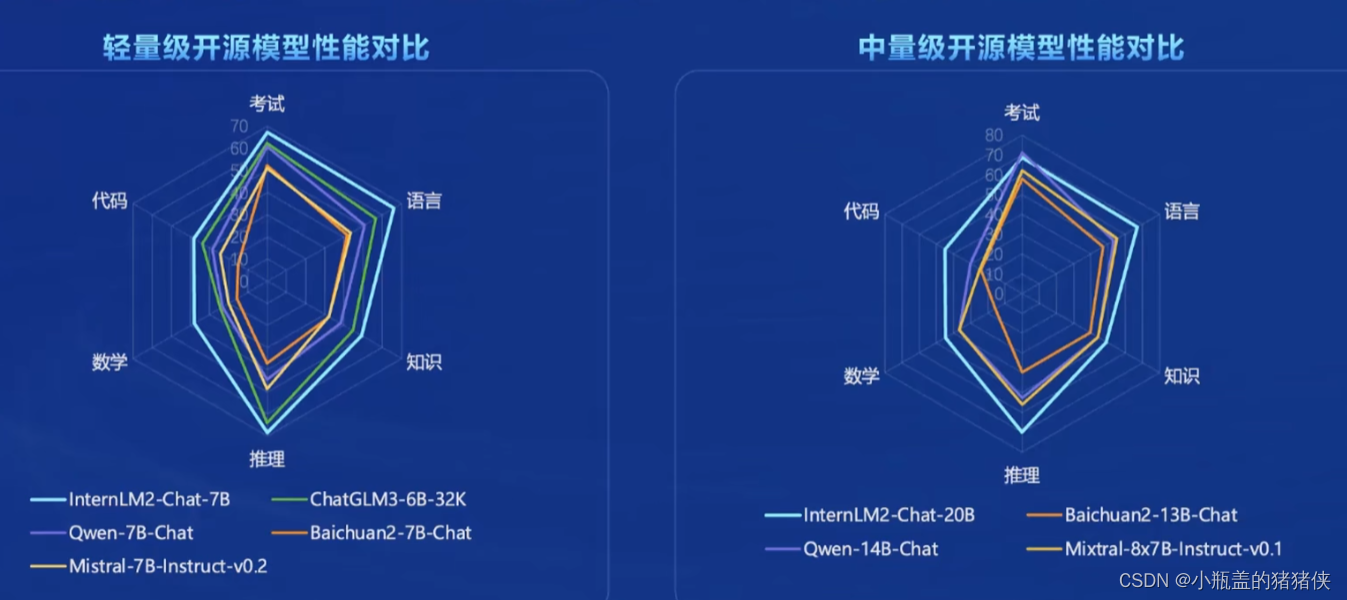
书生浦语特点
- 超长上下文
- 综合性能全面提升
- 优秀对话和创作体验
- 工具调用能力整体提升
- 突出的数理能力和使用的数据分析能力
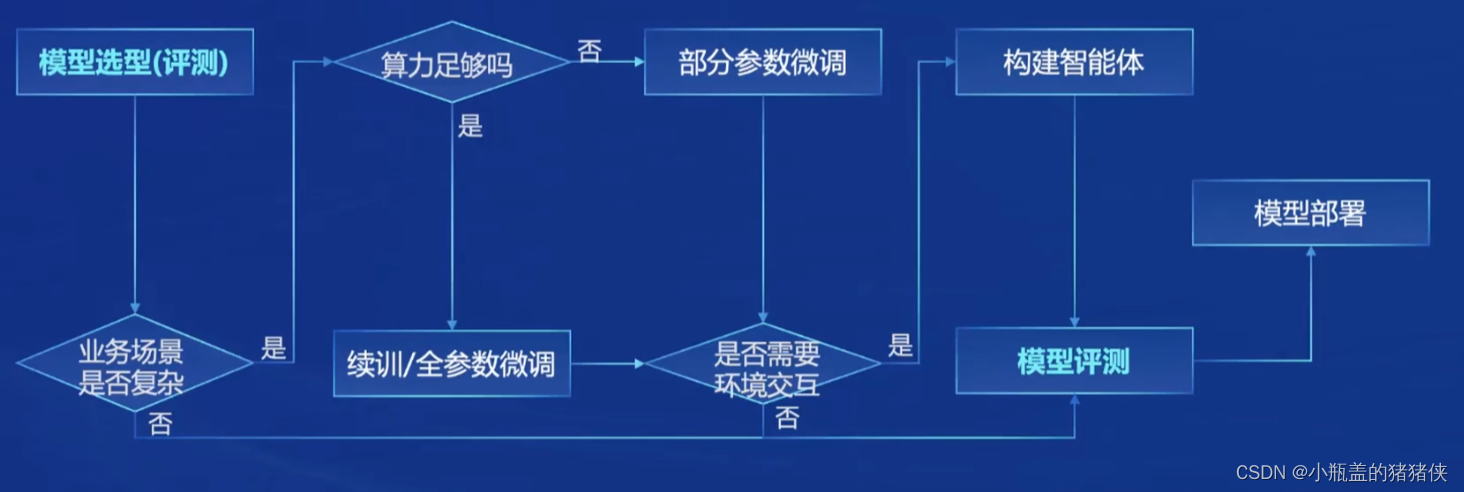
模型到应用流程
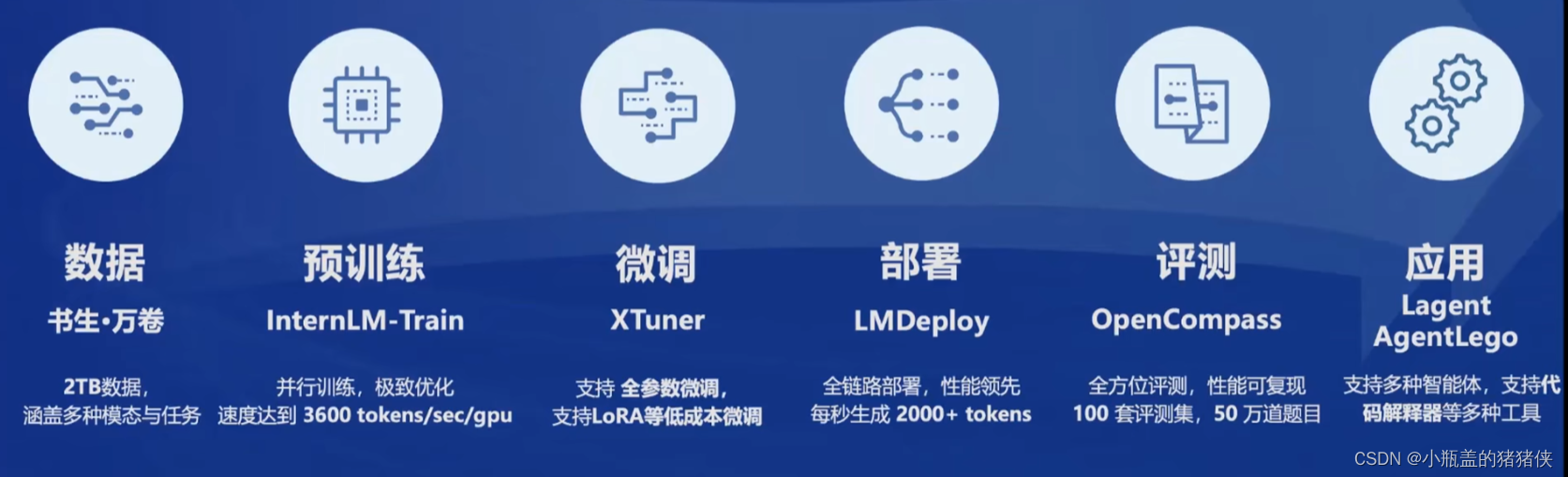
书生浦语体系
- 数据
- 预训练
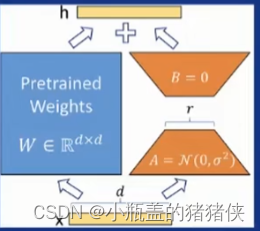
- 微调
- 全参微调和LORA微调
- 部署
- 评测
- 应用
微调
增量续训
使 用 场 景 : 让 基 座 模 型 学 习 到 一 些 新 知 识 , 如 某 个 垂 类 领 域 知 识 训 练 数 据 : 文 章 、 书 籍 、 代 码 等
有监督微调
使 用 场 景 : 让 模 型 学 会 理 解 各 种 指 令 进 行 对 话 , 或 者 注 入 少 量 领 域 知 识 训 练 数 据 : 高 质 量 的 对 话 、 问 答 数 据
微调框架