计算机视觉入门
文章目录
- 计算机视觉入门
- 一、 从卷积到卷积神经网络
- 1.图像的基本表示
- 2. 卷积操作
- 3.卷积遇见深度学习
- 3.1 通过学习寻找卷积核
- 3.2 参数共享:卷积带来参数量骤减
- 3.3 稀疏交互:获取更深入的特征
- 二、手撕卷积代码
- 三、经典CNN模型介绍
- 四、CNN模型的实际应用
- 参考
一、 从卷积到卷积神经网络
1.图像的基本表示

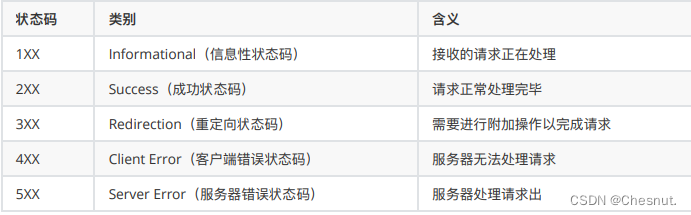
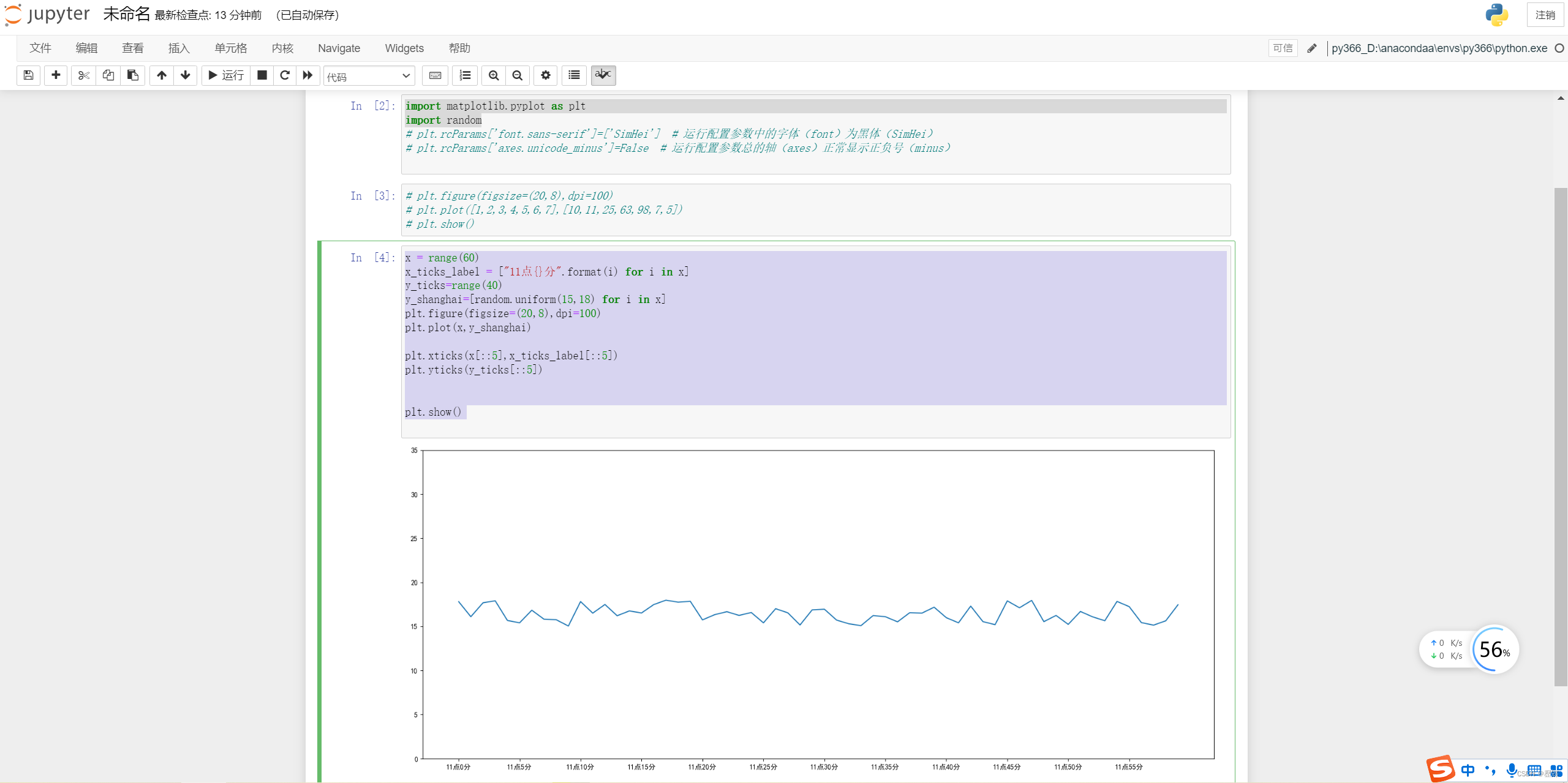
每张图像都是以一个三维 Tensor或者三维矩阵表示,其三个维度分别是(高度 height,宽度 width,通道 channels)。高度和宽度往往排列在一起,一般是先高后宽的顺序,两者共同决定图像的尺寸大小。如上图,高度 1707为则说明图像在竖直方向有1707个像素点(有1707列),同理宽度则代表水平方向的像素点数目 (有2560行),因此如上的孔雀图总共有1707*2560 = 4,369,920个像素点。
通道是单独的维度,通常排在高度宽度之后,但也有可能是排在第一位。它决定图像中的轮廓、线条、 色彩,基本决定了图像中显示的所有内容,尤其是颜色,因此又叫做色彩空间(color space)。
怎么理解通道呢?你可能在很年幼的时候就学过一些基本的色彩知识,例如,自然界中的颜色都是由“三原色”红黄蓝构成的,将红色和蓝色混在一起会得到紫色,将红色和黄色混在一起会得到橙色,白色的阳光可以经由三棱镜分解成七彩的光谱等等。计算机的世界中的颜色也是由基本颜色构成的,在计算机的世界里,用于构成其他颜色的基础色彩,就叫做“通道”。
我们最常用的三种基本颜色是红绿蓝(Red, Green, Blue, 简写为RGB),所以最常用的通道就是RGB通道。我们通过将红绿蓝混在一起,创造丰富的色彩。
在通道的每一个像素点上,都有[0,255]之间的整数值,这些整数值代表了“该通道上颜色的灰度”。在图像的语言中,“灰度”就是明亮程度。数字越接近255,就代表颜色明亮程度越高,越接近通道本身的颜色,数字越接近0,就代表颜色的明亮程度越弱,也就是越接近黑色。
在图像的矩阵中,我们可以使用索引找出任意像素的三个通道上的颜色的明度,例如,对于第0行、第0 列的样本而言,可以看到一个三列的矩阵,这三列就分别代表着红色、绿色、蓝色的像素值。当三个值都不为0时,这个像素在三个通道上都有颜色。相对应的,最纯的红色会显示为(255,0,0),最纯的蓝色就 会显示为(0,0,255),绿色可以此类推。当像素值为(0,0,0)时,这个像素点就为黑色,当像素值为 (255,255,255),像素点就为白色。通道上像素的灰度,也就是矩阵中的值几乎100%决定了图像会呈现 出什么样子。
灰度通道:灰度在计算机视觉中是指“明暗程度”,而不是指“灰色”,因而灰度通道也不是指图像是灰色的 通道,而是只有一种颜色的通道,同理,灰度图像是只有一个通道的图像。所以RGB通道中的任意一个 通道单独拿出来之后,都可以用灰度(明暗)来显示。
2. 卷积操作
这里有两个长度为9的列表,我们让对应位置的元素相乘,之后再相加:

如果我们把数字列表看作是权重,那以上式子就可以被看做一个加权求和的过程。现在,我们将九个数 整理成如下的矩阵:

左侧的矩阵我们称之为字母矩阵,而右侧的矩阵称之为数字矩阵(也就是权重矩阵)。当表示成矩阵之后,我们可以求解两个矩阵的点积,也就是将对应位置的元素相乘再相加等到一个标量,这与我们刚才实现的加权求和运算本质一致。但此时我们发现,在变成矩阵之前,a对应的是9,i对应的是1,而现在a对应的是1,i对应的是9。如果我们还想实现刚才的加权求和,就需要将数字矩阵在平面上顺时针旋转 180度,得到旋转矩阵:

现在,将旋转矩阵与字母矩阵求点积,就可以得到与之前的加权求和一样的结果了:
d
o
t
s
u
m
=
a
∗
9
+
b
∗
8
+
c
∗
7
+
d
∗
6
+
e
∗
5
+
f
∗
4
+
g
∗
3
+
h
∗
2
+
i
∗
1
dotsum = a*9+b*8+c*7+d*6+e*5+f*4+g*3+h*2+i*1
dotsum=a∗9+b∗8+c∗7+d∗6+e∗5+f∗4+g∗3+h∗2+i∗1
现在,dotsum的结果就是字母矩阵与原始数字矩阵的卷积:

卷积操作是一种常见的数学计算,二维矩阵的卷积表示其中一个矩阵在平面上旋转180°后,与另一个矩阵求点积的结果。其中“卷”就是旋转,“积”就是点击,也就是加权求和。本质上来说,卷积就是其中一个 矩阵旋转180°后,两个矩阵对应位置元素相乘再加和的结果。这个过程可以使用数学公式表示:

其中表示其中一个矩阵的值, 表示另一个矩阵的值, 与分别是两个矩阵的行数和列数。在其他说明中,你可能会见到使用其他符号的二维矩阵的卷积表示,但其本质都与我们所说的“旋转再 求内积”一致。你也可能会见到卷积的代数表示(就是带积分的那个)、甚至是离散卷积的表示方式。
之前我们说过,只要我们对图像数据进行任意数学运算,且得出的结果不超出图像的像素范围[0,255], 就可以生成新的图像。而卷积是一种从两个矩阵中得出新数值的方式,这个操作正好可以用于图像的变换。
事实上,就连OpenCV中的sobel和Laplacian函数都没有进行“旋转”,而是直接定义了旋转后矩阵。或许是最初的研究者尝试了“卷积”操作,就这样流传下来,或许是原始权重矩阵的逻辑可能来源于某些理论,不旋转将会使边缘检测失效,但在今天的计算机视觉技术中,尤其是深度学习中,大部分时候我们都不再进行“旋转”这个步骤了。甚至在许多卷积相关的讲解中,会直接忽略旋转这个步骤,导致许多人无法理解“卷积”的“卷”从何而来。
没有旋转,我们也无需在关心最初的矩阵。现在我们只关心与图像相乘的旋转矩阵,我们把旋转矩阵的值称为权重,将该矩阵称为过滤器(filter,意为可以过滤出有效的特征),也被叫做卷积核 (Convolution Kernel),每个卷积核在原图上扫描的区域(被标注为绿色的区域)被称为感受野 (receiptive field),卷积核与感受野轮流点积得到的新矩阵被叫做特征图(feature map)或激活图 (activation map)。当没有旋转,只有点积的时候,图像与矩阵之间的运算就不是数学上的“卷积”,而 plt.subplot(2,2,4),plt.imshow(sobely,cmap = ‘gray’) plt.title(‘Sobel Y’),plt.axis(‘off’) 数与教育是“互相关”(cross-correlation)了,但是基于历史的原因和行业习惯,我们依然把整个过程称为“卷积操作”,这个名字沿用到今天,也影响了深度学习中对卷积神经网络的称呼。
3.卷积遇见深度学习
检测边缘、锐化、模糊、图像降噪等卷积相关的操作,在图像处理中都可以被认为是在从图像中提取部 分信息,因此这部分图像处理技术也被叫做“特征提取”技术。卷积操作后所产生的图像可以作为特征被 输入到分类算法中,在传统计算机视觉领域,这一操作常常被认为可以提升模型表现并增强计算机对图 像的识别能力。计算机视觉是研究如何让计算机从图像或图像序列中获取信息并理解其信息的学科,理 解就意味着识别、判断甚至是推断,因此识别在计算机视觉中是非常核心的需求,卷积操作在传统计算 机视觉中的地位就不言而喻了。数十年来,计算机视觉工程师们使用前人的经验与研究不断提取特征, 再送入机器学习算法中进行识别和分类。然而,这样做是有极限的。
在边缘检测中,我们看到拉普拉斯和索贝尔算子的检测是很明显的。但是,如果使用我们之前导 入的孔雀图像,就会发现边缘检测的效果有些糟糕。
为什么会这样呢?这是因为,sobel和拉普拉斯算子对边缘抓取的程度较轻(从图像处理的原理上来看, 他们只求取了图像上的一维导数,因此效果不够强),这样的抓取对于横平竖直的边缘、以及色彩差异 较大的边缘有较好的效果,对于孔雀这样色彩丰富、线条和细节非常多的图像,这两种算子就不太够用 了。所以在各种边缘检测的例子中,如果你仔细观察原图,你就会发现原图都是轮廓明显的图像
这说明,不同的图像必须使用不同的权重进行特征提取,同时,我们还必须加深特征提取的深度。那什 么样的图像应该使用什么样的权重呢?如何才能够提取到更深的特征呢?同时,如果过去的研究中提出 的算子都不奏效,应该怎么找到探索新权重的方案呢?即便有效地实现了边检检测、锐化、模糊等操 作,就能够提升最终分类算法的表现吗?其实不然。这些问题困扰计算机视觉工程师许久,即便在传统 视觉中,我们已提出了不少对于这些问题的解决方案,但从一劳永逸的方向来考虑,如果计算机自己能 够知道应该使用什么算子、自己知道应该提取到什么程度就好了。此时,深度学习登场了。
3.1 通过学习寻找卷积核

在深度神经网络中,层与层之间存在着链接上层与下层的权重系数 。深度学习的核心思想之一,就是 给与算法训练目标,让算法自己朝着目标函数最小化的方向进行学习,并自动求解出权重系数 的最佳 组合。在深度网络的在DNN中,我们输入的是特征矩阵,让特征矩阵与权重系数相乘后,传入下一层进 行加和与激活,并通过从后向前的方式训练网络自己找出权重。在计算机视觉领域,我们输入的特征变 成了一张张图像的一个个通道,我们让通道上的像素值与卷积核进行卷积操作后,得出输入下一层的图 像(特征图 feature map)。而卷积操作本质就是感受野与卷积核点积,其操作与DNN中的权重与特征 相乘非常相似。
顺着这样的思路,卷积层(Convolutional layer)诞生了,任意使用卷积层的神经网络就被称为是卷积 神经网络(Convolution Neural Network),卷积网络一族有相当多的经典模型。每当卷积层被建立 时,卷积核中的值就会被随机生成,输入图像的像素点与卷积核点积后,生成的特征图被输入到下一层 网络,并最终变成预测标签被放入损失函数中进行计算。在使用优化算法进行迭代、损失足够低后,卷 积核中的权重值就被自动学习出来了,这就实现了“自动找出最佳权重,并提取出对分类最有利的特征”。

这样学习出的卷积核的值以分类效果为最终目标,可以选择出最恰当的特征,因此理想状况下,可以完 美避免人工进行特征提取的这个步骤。剩下的问题就是,通过深度学习自动学习得出的特征,能够比人 手提取的特征更好吗?这个问题耗费了学术界数十年的时间,最终被现代神经网络的数个经典架构所验 证。但现在,我们暂且不谈这个,继续来看深度学习与卷积的碰撞所带来的改变。
3.2 参数共享:卷积带来参数量骤减
从传统计算机视觉的角度而言,将卷积操作引入神经网络是一个绝妙的操作,但不止如此,对研究神经 网络的学者们而言,卷积的到来也解决了众多深度学习中的关键问题。比如——卷积可以极大程度地减 少参数量。
深度学习的模型总是需要大规模计算和训练来达到商业使用标准,计算量一直都是深度学习领域的痛, 而巨大的计算量在很多时候都与巨量参数有关。在卷积神经网络诞生之前,人们一直使用普通全连接的 DNN来训练图像数据。对于一张大小中等,尺寸为(600,400)的图像而言,若要输入全连接层的DNN, 则需要将像素拉平至一维,在输入层上就需要600*400 = 24万个神经元,这就意味着我们需要24万个参 数来处理这一层上的全部像素。如果我们有数个隐藏层,且隐藏层上的神经元个数达到10000个,那 DNN大约需要24亿个参数( 个)才能够解决问题。
然而,卷积神经网络却有“参数共享”(Parameter Sharing)的性质,可以令参数量骤减。一个通道虽然 可以含有24万个像素点,但图像上每个“小块”的感受野都使用相同的卷积核来进行过滤。卷积神经网络 要求解的参数就是卷积核上的所有数字,所以24万个像素点共享卷积核就等于共享参数。假设卷积核的 尺寸是5x5,那处理24万个像素点就需要25个参数。假设卷积中其他需要参数层也达到10000个,那 CNN所需的参数也只有25万。由于我们还没有介绍卷积神经网络的架构,因此这个计算并不是完全精 确,但足以表明卷积有多么节省参数了。参数量的巨大差异,让卷积神经网络的计算非常高效。在第一 堂课时我们说到,深度学习近二十多年的发展,都围绕着“让模型计算更快、让模型更轻便”展开,从全 连接到卷积就是一个很好的例子。预测效果好,且计算量小,这是卷积神经网络在计算机视觉领域大热 的原因之一。
3.3 稀疏交互:获取更深入的特征
卷积操作是为了提取特征而进行的数学计算,它能够根据损失函数的指导而自动提取出对分类或其他目 标更有效的特征。然而,卷积神经网络是如何保证提取到的特征比传统方法,如sobel算子等方法“更深” 的呢?
这需要从“神经元”的层次来看待。在CNN中,我们都是以“层”或者“图”、“通道”这些术语来描述架构,但 其实CNN中也有神经元。在任何神经网络中,一个神经元都只能够储存一个数字。所以在CNN中,一个 像素就是一个神经元(实际上就是我们在类似如下的视图中看到的每个正方形小格子)。很容易理解, 输入的图像/通道上的每个小格子就是输入神经元,feature map上的每个格子就是输出神经元。在DNN 中,上层的任意神经元都必须和下层的每个神经元都相连,所以被称之为“全连接”(fully connected),但在CNN中,下层的一个神经元只和上层中被扫描的那些神经元有关,在图上即表示 为,feature map上的绿格子只和原图上绿色覆盖的部分有关。这种神经元之间并不需要全链接的性质 被称为稀疏交互(Sparse Interaction)。人们认为,稀疏交互让CNN获得了提取更深特征的能力。

深度学习中的许多方法来源于对其他学科的借鉴,卷积的结构也不例外。为了研究大脑是如何理解人眼 所看到的内容,神经学家们对人眼成像系统进行了丰富的研究。人类的眼球中含有一系列视觉细胞,但 这些细胞不是等价的,他们之中的一部分是简单细胞,只能捕捉到简单的线条、颜色等信息,这些简单 细胞捕捉到简单信息后,会将信息传导至复杂细胞,复杂细胞会将这些信息重组为轮廓、光泽等更高级 的信息,之后再将信息传导至更高级的细胞,形成完整的图像。神经学家认为,人眼的细胞有着“提取浅 层特征,合成高级特征”的能力。CNN的“稀疏交互”的属性允许神经元只包含上一层图像“局部”的信息, 这就与人眼的简单细胞只提取简单线条的属性很相似。因此我们有理由相信,当图像被输入网络后,前 端的卷积神经网络提取到的特征都是浅层的(和sobel算子等方法一样),将这些浅层特征继续输入后续 的网络,再次进行提取和学习,就能够将浅层特征逐渐组合成深层特征。而图像天生就可以通过不断变 换、被提取出更多的特征(相对的,自然语言就没有这个性质,所以NLP领域的CNN往往没有CV领域的 CNN深),因此位于卷积神经网络架构后端的卷积层们,一定是捕捉到了更深层的特征的。 虽然“稀疏交互”是客观的,但是否依赖于这个属性来提取出更深的特征确实有争议的。

这张图可视化了在人脸识别中各层卷积层所提取到的特征图。从左至右,神经网络越来越深,从最开始 的只能提取到一些简单的线条,到最后可以提取出一整张人脸,似乎能够证明CNN的确拥有和人眼细胞 一样的能力。然而当我们真正去可视化一些经典卷积神经网络的结构时,随着卷积层的加深,可视化出 来的效果往往是这样的

不难发现,我们很难直接看出“从局部到整体”这样一个特性。从CNN的预测效果来看,我们有理由相信 它的确提取到了更深的特征,但绝不是以我们认为的,“先提取细节、再拼接成局部、最后组成图像”的 方式。
无论如何,卷积与深度学习碰撞所带来的变革是革命性的。通过学习的方式改进卷积核、再通过深层网 络不断提纯特征、以及大幅度降低参数量,卷积神经网络的作用已经不言而喻。
二、手撕卷积代码
未完待续
三、经典CNN模型介绍
未完待续
四、CNN模型的实际应用
未完待续
参考
菜菜的深度学习课堂