目录
- 前期准备
- 一、制作数据集
- 1. excel表格数据
- 2. 代码
- 二、手写数字识别
- 1. 下载数据集
- 2. 搭建模型
- 3. 训练网络
- 4. 测试网络
- 5. 保存训练模型
- 6. 导入已经训练好的模型文件
- 7. 完整代码
前期准备
必须使用 3 个 PyTorch 内置的实用工具(utils):
⚫ DataSet 用于封装数据集;
⚫ DataLoader 用于加载数据不同的批次;
⚫ random_split 用于划分训练集与测试集。
一、制作数据集
在封装我们的数据集时,必须继承实用工具(utils)中的 DataSet 的类,这个过程需要重写__init__和__getitem__、__len__三个方法,分别是为了加载数据集、获取数据索引、获取数据总量。我们通过代码读取excel表格里面的数据作为数据集。
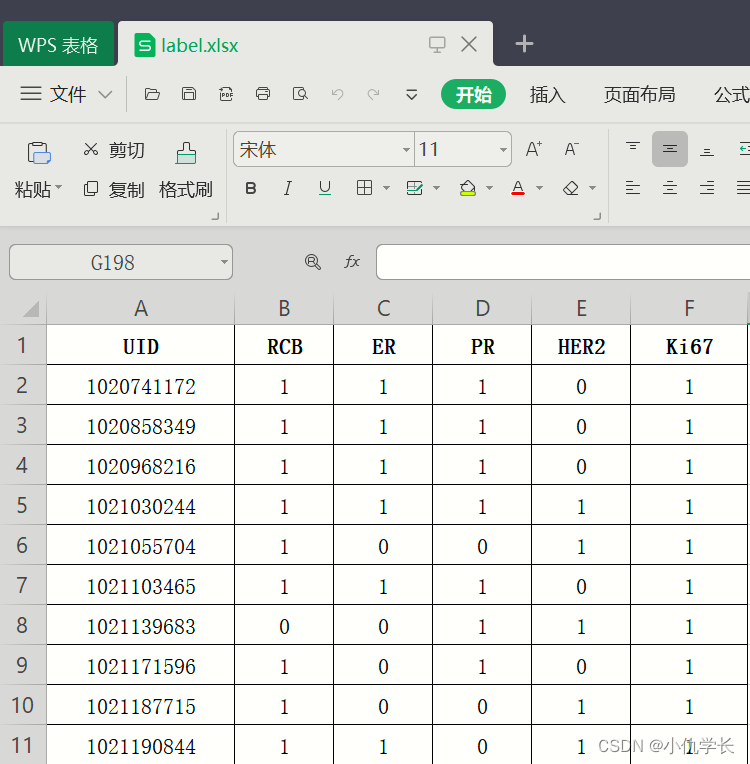
1. excel表格数据
2. 代码
为了简单演示,我们将表格的第0列作为输入特征,第1列作为输出特征。
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
import matplotlib.pyplot as plt
# 制作数据集
class MyData(Dataset): """继承 Dataset 类"""
def __init__(self, filepath):
super().__init__()
df = pd.read_excel(filepath).values """ 读取excel数据"""
arr = df.astype(np.int32) """转为 int32 类型数组"""
ts = torch.tensor(arr) """数组转为张量"""
ts = ts.to('cuda') """把训练集搬到 cuda 上"""
self.X = ts[:, :1] """获取第0列的所有行做为输入特征"""
self.Y = ts[:, 1:2] """获取第1列的所有行为输出特征"""
self.len = ts.shape[0] """样本的总数"""
def __getitem__(self, index):
return self.X[index], self.Y[index]
def __len__(self):
return self.len
if __name__ == '__main__':
"""获取数据集"""
Data = MyData('label.xlsx')
print(Data.X[0]) """输出为:tensor([1020741172], device='cuda:0', dtype=torch.int32)"""
print(Data.Y[0]) """输出为:tensor([1], device='cuda:0', dtype=torch.int32) """
print(Data.__len__()) """输出为:233 """
"""划分训练集与测试集"""
train_size = int(len(Data) * 0.7) # 训练集的样本数量
test_size = len(Data) - train_size # 测试集的样本数量
train_Data, test_Data = random_split(Data, [train_size, test_size])
"""批次加载器"""
""" 第一个参数:表示要加载的数据集,即之前划分好的 train_Data或test_Data 。"""
""" 第二个参数:表示在每个 epoch(训练周期)开始之前是否重新洗牌数据。在训练过程中,通常会将数据进行洗牌,以确保模型能够学习到更加泛化的特征。而测试数据不需要重新洗牌,因为测试集仅用于评估模型的性能,不涉及模型参数的更新"""
""" 第三个参数:表示每个批次中的样本数量为 32。也就是说,每次迭代加载器时,它会从训练数据集中加载128个样本。"""
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)
"""打印第一个批次的输入与输出特征"""
for inputs, targets in train_loader:
print(inputs)
print(targets)
二、手写数字识别
1. 下载数据集
在下载数据集之前,要设定转换参数:transform,该参数里解决两个问题:
⚫ ToTensor:将图像数据转为张量,且调整三个维度的顺序为 (C-W-H);C表示通道数,二维灰度图像的通道数为 1,三维 RGB 彩图的通道数为 3。
⚫ Normalize:将神经网络的输入数据转化为标准正态分布,训练更好;根据统计计算,MNIST 训练集所有像素的均值是 0.1307、标准差是 0.3081
"""数据转换为tensor数据"""
transform_data = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)
])
"""下载训练集与测试集"""
train_Data = datasets.MNIST(
root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist/', """下载路径"""
train = True, """训练集"""
download = True, """如果该路径没有该数据集,就下载"""
transform = transform_data """数据集转换参数"""
)
test_Data = datasets.MNIST(
root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist_test/', """下载路径"""
train = False, """非训练集,也就是测试集"""
download = True, """如果该路径没有该数据集,就下载"""
transform = transform_data """数据集转换参数"""
)
"""批次加载器"""
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)
2. 搭建模型
class DNN(nn.Module):
def __init__(self):
''' 搭建神经网络各层 '''
super(DNN,self).__init__()
self.net = nn.Sequential( # 按顺序搭建各层
nn.Flatten(), # 把图像铺平成一维
nn.Linear(784, 512), nn.ReLU(), # 第 1 层:全连接层
nn.Linear(512, 256), nn.ReLU(), # 第 2 层:全连接层
nn.Linear(256, 128), nn.ReLU(), # 第 3 层:全连接层
nn.Linear(128, 64), nn.ReLU(), # 第 4 层:全连接层
nn.Linear(64, 10) # 第 5 层:全连接层
)
def forward(self, x):
''' 前向传播 '''
y = self.net(x) # x 即输入数据
return y # y 即输出数据
3. 训练网络
"""实例化模型"""
model = DNN().to('cuda:0')
def train_net():
"""1.损失函数的选择"""
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
"""2.优化算法的选择"""
learning_rate = 0.01 # 设置学习率
optimizer = torch.optim.SGD(
model.parameters(),
lr=learning_rate,
momentum=0.5 # momentum(动量),它使梯度下降算法有了力与惯性
)
"""3.训练"""
epochs = 5
losses = [] """记录损失函数变化的列表"""
for epoch in range(epochs):
for (x, y) in train_loader: """从批次加载器中获取小批次的x与y"""
x, y = x.to('cuda:0'), y.to('cuda:0')
Pred = model(x) #将样本放入实例化的模型中,这里自动调用forward方法。
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
"""4.画损失图"""
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
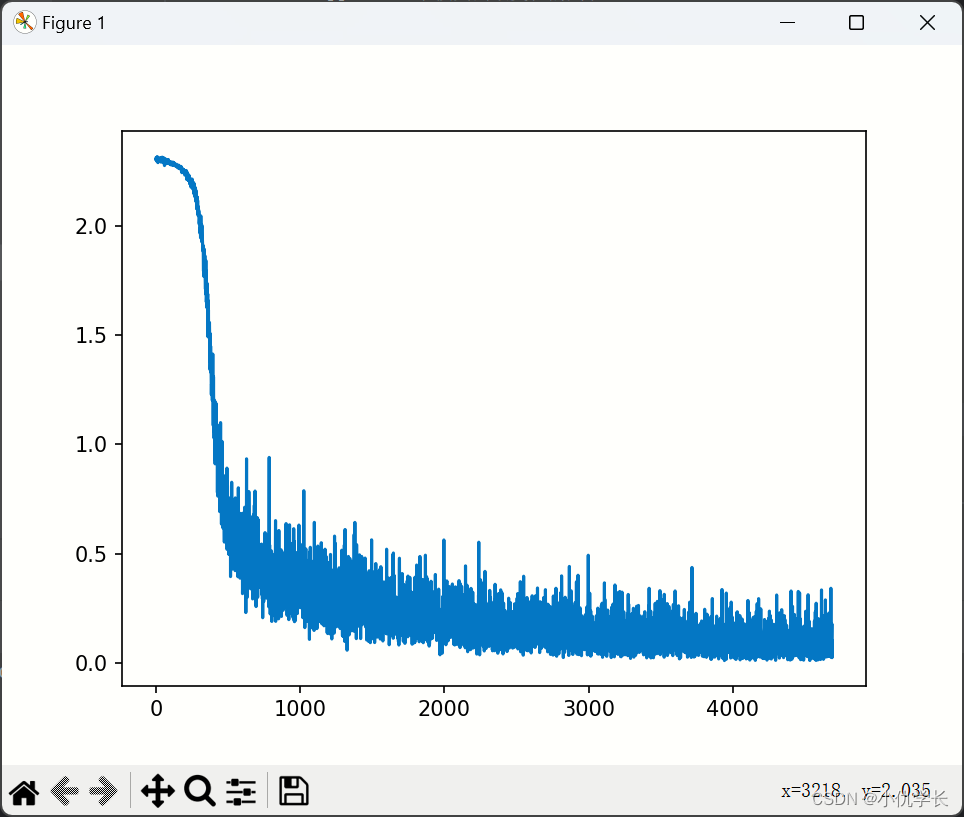
损失图如下:
4. 测试网络
测试网络不需要回传梯度。
"""实例化模型"""
model = DNN().to('cuda:0')
def test_net():
correct = 0
total = 0
with torch.no_grad(): #该局部关闭梯度计算功能
for (x, y) in test_loader: #从批次加载器中获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0')
Pred = model (x) #将样本放入实例化的模型中,这里自动调用forward方法。
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum((predicted == y))
total += y.size(0)
print(f'测试集精准度: {100 * correct / total} %')

5. 保存训练模型
在保存模型前,必须要先进行训练网络去获取和优化模型参数。
if __name__ == '__main__':
model = DNN().to('cuda:0')
train_net()
torch.save(model,'old_model.pth')
6. 导入已经训练好的模型文件
导入训练好的模型文件,我们就不需要再进行训练网络,直接使用测试网络来测试即可。
new_model使用了原有模型文件,我们就需要在测试网络的前向传播中的模型修改为 new_model去进行测试。如下:
""" 假设我们之前保存好的模型文件为:'old_model.pth' """
def test_net():
correct = 0
total = 0
with torch.no_grad(): #该局部关闭梯度计算功能
for (x, y) in test_loader: #从批次加载器中获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0')
Pred = new_model (x) #将样本放入实例化的模型中,这里自动调用forward方法。
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum((predicted == y))
total += y.size(0)
print(f'测试集精准度: {100 * correct / total} %')
if __name__ == '__main__':
new_model = torch.load('old_model.pth')
test_net()
7. 完整代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
"""------------1.下载数据集----------"""
"""数据转换为tensor数据"""
transform_data = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)
])
"""下载训练集与测试集"""
train_Data = datasets.MNIST(
root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist/', """下载路径"""
train = True, """训练集"""
download = True, """如果该路径没有该数据集,就下载"""
transform = transform_data """数据集转换参数"""
)
test_Data = datasets.MNIST(
root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist_test/', """下载路径"""
train = False, """非训练集,也就是测试集"""
download = True, """如果该路径没有该数据集,就下载"""
transform = transform_data """数据集转换参数"""
)
"""批次加载器"""
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)
"""---------------2.定义模型------------"""
class DNN(nn.Module):
def __init__(self):
''' 搭建神经网络各层 '''
super(DNN,self).__init__()
self.net = nn.Sequential( # 按顺序搭建各层
nn.Flatten(), # 把图像铺平成一维
nn.Linear(784, 512), nn.ReLU(), # 第 1 层:全连接层
nn.Linear(512, 256), nn.ReLU(), # 第 2 层:全连接层
nn.Linear(256, 128), nn.ReLU(), # 第 3 层:全连接层
nn.Linear(128, 64), nn.ReLU(), # 第 4 层:全连接层
nn.Linear(64, 10) # 第 5 层:全连接层
)
def forward(self, x):
''' 前向传播 '''
y = self.net(x) # x 即输入数据
return y # y 即输出数据
"""-------------3.训练网络-----------"""
def train_net():
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.01 # 设置学习率
optimizer = torch.optim.SGD(
model.parameters(),
lr=learning_rate,
momentum=0.5
)
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):
for (x, y) in train_loader: # 获取小批次的 x 与 y
x, y = x.to('cuda:0'), y.to('cuda:0')
Pred = model(x) # 一次前向传播(小批量)
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
"""Fig = plt.figure()"""
"""plt.plot(range(len(losses)), losses)"""
"""plt.show()"""
"""--------------------4.测试网络-----------"""
def test_net():
correct = 0
total = 0
with torch.no_grad(): #该局部关闭梯度计算功能
for (x, y) in test_loader: #获取小批次的 x 与 y
x, y = x.to('cuda:0'), y.to('cuda:0')
Pred = new_model(x) #一次前向传播(小批量)
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum((predicted == y))
total += y.size(0)
print(f'测试集精准度: {100 * correct / total} %')
if __name__ == '__main__':
""" ------- 5.保存模型文件------"""
""" model = DNN().to('cuda:0') """
""" train_net() """
""" torch.save(model,'old_model.pth') """
""" ------- 6.加载模型文件 ----- """
new_model = torch.load('old_model.pth')
test_net()









![绝地求生:[更新周报] 4/3 不停机更新:无上新、众多物品和活动即将下架!](https://img-blog.csdnimg.cn/direct/6523f522944c442cad9b6d65dc30db0a.png)