文章目录
- 一、机器学习做什么
- 二、机器学习的基本术语
- 2.1、数据相关
- 2.1.1、数据集
- 2.1.2、特征(Feature)
- 2.1.3、样本空间(Sample Space)
- 2.2、任务相关
- 2.2.1、分类
- 2.2.2、回归
- 2.2.3、聚类
- 2.2.4、监督学习和无监督学习
- 三、机器学习思想
- 3.1、泛化能力!
- 3.2、假设空间和版本空间!
- 3.3、归纳偏好!
- 3.3.1、解释
- 四、外话
- 4.1、泛化
- 4.1.2、泛化的关键
- 4.1.3、提高泛化能力
若考虑所有潜在的问题,则所有学习算法都一样好.要谈论算法的相对优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用.
一、机器学习做什么
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。机器学习所研究的主要内容是关于在计算机上从数据中产生“模型 " (model)的算法,即 “学习算法”(learning algorithm)。可以说机器学习是研究关于 “学习算法”的学问。
- 通俗来讲,例如经过我们的百般阅历,我们可以从一个人的行为可以判断一个人的好坏,是否是学霸,是否是神经病,这是我们通过不断的学习,认识获得的能力。
- 同样的,计算机通过数据 学习 产生 这种能够判断事物类别的模型,就属于一种机器学习。
- 机器学习是研究关于 “学习算法” 的学问。这里的学习并不是动词,而是一个形容词。可以理解为,机器学习这一领域是一种研究 用什么样的算法 能更好的学习到已有数据中的规律,从而产生模型 的学问,而这些算法都是学习算法,也叫作机器学习算法。具有学习性质的算法。
用“模型”泛指从数据中学得的结果。
二、机器学习的基本术语
2.1、数据相关
- 数据集
- 示例/样本/特征向量(同一概念)
- 属性/特征/属性空间/样本空间/输入空间
标记/标签/标记空间/输出空间- 通俗来讲,数据集就是你所拥有的全部数据,即全部样本(特征向量);
- 样本(特征向量)是这些数据中的某一项及其属性,比如这里的瓜1;
- 属性(特征)是这些样本中的某一特征,比如这里的色泽属于瓜的某一个特征,每个特征上有一个值,称为属性值(特征值);
- 而样本空间是所有属性可能取值构成的集合,张成的空间,这个空间上包含了瓜的所有可能性。就和随机数学里面的随机试验的样本空间差不多。
- 在一些“预测”模型中,需要一些标记,即这些瓜的类别,好瓜还是坏瓜,好人还是坏人,神经病还是正常人。所有标记的集合是标记空间。
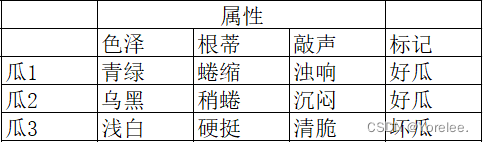
2.1.1、数据集
想象一下,我们站在一个充满各种西瓜的市场中:有的西瓜青绿色,有的乌黑;有的根蒂蜷缩,有的稍显蜷曲;敲击时,有的响声浑厚,有的则显得沉闷。如果我们将每一个西瓜的这些特征,连同我们对它是否为好瓜的评价或者价格,记录下来,那么这些记录的集合就构成了我们的数据集。在这个数据集中,每一条记录描述了一个西瓜的独特特征,称为一个样本。样本中关于是否是好瓜的判断,则是我们所说的标签,而所有可能的标签(如好瓜与不好瓜)构成了标签空间。
当我们把这些样本用来训练机器学习模型时,这些数据就被称为训练数据,而单个样本则成为一个训练样本。所有这些训练样本共同组成了我们的训练集。
2.1.2、特征(Feature)
在描述西瓜时,我们提到了“色泽”、“根蒂”和“敲声”。这些用来反映西瓜在某方面表现或性质的事项,就是所谓的特征。特征是我们用来描绘和区分每一个西瓜的工具,而特征的数量,即我们用来描述西瓜的属性数量,被称为样本(或特征向量)的维数。
2.1.3、样本空间(Sample Space)
如果我们将每个特征视为一维空间,那么所有的特征共同构成的空间,就是我们的样本空间。比方说,以“色泽”、“根蒂”和“敲声”为三个坐标轴,我们可以将它们想象成构建了一个三维空间,用以描述西瓜的世界。在这个空间中,每个西瓜都可以找到一个唯一的坐标位置,这个位置由其特征值组成的向量确定,我们称之为特征向量。
特征向量实际上就是将特征概念包含进去的样本,即样本实际上就是特征向量。
2.2、任务相关
2.2.1、分类
预测的是离散值的学习任务。
如果只涉及到两个类别,则称为二分类任务。两类一个称为正类,另一个称为负类(反类)。
如果涉及到多个类别,则称为多分类任务。
2.2.2、回归
预测的是连续值的学习任务。分类和回归的区别仅在此。

2.2.3、聚类

2.2.4、监督学习和无监督学习
根据是否有标记,机器学习大致划分为两大类:监督学习和无监督学习。
- 分类和回归是监督学习的代表,因为它们都是提前有标记的。
- 聚类是无监督学习的代表,因为它通常是没有标记的,并且我们是通过不同特征向量之间特征的潜在规律进行划分成簇的,划分之后的类别,并不为我们事先知晓,而是机器自动学习出来的规律类别。

三、机器学习思想
3.1、泛化能力!
机器学习的目标是使学得的模型能很好地适用于新样本而不是仅仅在训练样本上工作得很好。 机器学习需要有从已有样本中归纳学习的能力,以此来适用于没有见过的样本。学习的目的是泛化。
学得模型适用于新样本的能力,称为泛化能力。

泛化(Generalization)是指模型对未见过的新数据的处理能力,即模型学习到的规律在新数据上的适用性。一个好的机器学习模型不仅能够在训练数据上表现良好,更重要的是能够在新的、未见过的数据上也能保持这种良好表现。泛化能力强的模型能够从训练数据中学习到普遍适用的规律,而不是仅仅记住训练数据的特点和噪声,后者的现象被称为过拟合(Overfitting)。
3.2、假设空间和版本空间!
为了理解3.3,我们需要先理解假设,假设空间,版本空间的概念。
- 假设(Hypothesis):在机器学习中,假设是根据训练集归纳出的一种规律或模式。这种规律是模型用来对新数据做出预测的依据。简单来说,假设就是模型认为最可能描述数据真实关系的规则。而这个特定问题真正潜在的规律称为真实,机器学习 从训练集中学习到的规律称为假设。
- 假设空间(Hypothesis Space):假设空间包含了所有可能的假设。*这些假设是根据模型的结构和我们选择的特征而定义的,它包括了所有模型可能采用的规则或模式来解释数据。假设空间的大小和复杂度取决于模型的复杂性和特征的数量。这里的假设空间是抛开训练集不管的,所有可能数据集中存在的规律。
- 版本空间(Version Space):是在假设空间中能够使得与训练集一致的规律集合,这里的规律抽象为一个假设。同一个训练集,可能不同机器学习算法可以学习出不同假设,也是因为同一个训练集存在一个版本空间。

3.3、归纳偏好!
既然同一个训练集可能有多种规律和它匹配,那我们该怎么做呢?
对于一个具体的学习算法而言,它必须要产生一个模型.这时,学习算法本身的“偏好”就会起到关键的作用。 机器学习算法在学习过程中对某种类型假设的偏好,称为 “归纳偏好”(inductive bias),或简称为“偏好”。(之前说过归纳 即学习规律)。并且我们的学习算法必须有某种偏好,才能产出它认为“正确”的模型.

3.3.1、解释
归纳偏好(Inductive Bias)是机器学习算法在面对同一个训练集时倾向于选择某种特定假设的倾向性或偏好。由于训练数据通常无法完全确定目标函数,所以机器学习算法必须利用归纳偏好来做出选择,决定它认为最可能的假设是什么。这种偏好影响着模型的泛化能力,即模型对未见过数据的预测能力。
-
为什么存在归纳偏好? 因为在实践中,对于给定的训练数据集,可能有多个或者无数个假设与训练数据一致,但这些假设对于未见过的数据的预测可能完全不同。归纳偏好帮助算法在这些可能的假设中做出选择。
-
归纳偏好的例子:假设我们有两种算法,一种是梯度提升树(Gradient Boosting),另一种是随机森林(Random Forest)。尽管两者都是决策树的集成方法,但它们的归纳偏好不同。梯度提升树通过逐步减少模型误差的方式构建树,倾向于更加关注错误分类的样本;而随机森林通过构建多个独立的树并对它们的结果进行平均或多数投票来工作,倾向于提高整体的稳定性和减少过拟合。这两种方法因其不同的偏好,在不同的数据集和问题上表现出不同的效果。
-
归纳偏好的重要性:选择哪种机器学习算法,并不仅仅是技术上的选择,实际上也是基于对问题本身先验知识的一种假设。因为不同的算法由于其内在的归纳偏好,可能在某些类型的数据上表现更好,在其他数据上则不然。因此,理解并选择与你面对的问题相匹配的算法的归纳偏好,是提高模型性能的关键。
四、外话
4.1、泛化
在机器学习领域,泛化(Generalization) 是指模型对未见过的新数据的处理能力,即模型学习到的规律在新数据上的适用性。一个好的机器学习模型不仅能够在训练数据上表现良好,更重要的是能够在新的、未见过的数据上也能保持这种良好表现。泛化能力强的模型能够从训练数据中学习到普遍适用的规律,而不是仅仅记住训练数据的特点和噪声,后者的现象被称为过拟合(Overfitting)。
4.1.2、泛化的关键
- 泛化误差(Generalization Error):通常指模型在新的数据集上的预测误差。理想情况下,我们希望模型的泛化误差尽可能小,这意味着模型对未知数据的预测能力较强。
- 过拟合(Overfitting)与欠拟合(Underfitting):过拟合是指模型在训练数据上表现异常良好,但在新数据上表现不佳的现象;而欠拟合则是指模型在训练数据上就表现不佳,导致在新数据上的表现也不理想。泛化的目标是在这两者之间找到平衡点。
4.1.3、提高泛化能力
为了提高模型的泛化能力,研究人员和工程师可能会采用以下一些策略:
- 数据增强(Data Augmentation):通过对训练数据进行变换和扩充,增加模型训练过程中的数据多样性。
- 正则化(Regularization):通过引入额外的信息(如权重的大小或复杂度)来限制模型的复杂度,防止过拟合。
- 交叉验证(Cross-validation):通过将数据集分为多个小组,然后使用其中一部分进行训练、另一部分进行验证,可以更准确地评估模型的泛化能力。
- 模型简化:简化模型的复杂度,例如减少网络层数或参数的数量,有时可以防止过拟合,从而提高泛化能力。
- 集成学习(Ensemble Learning):通过组合多个模型的预测来提高整体模型的泛化能力。









![[ruby on rails] ruby使用vscode做开发](https://img-blog.csdnimg.cn/direct/40aea98db16944baa4f5ba521698d97d.png)


