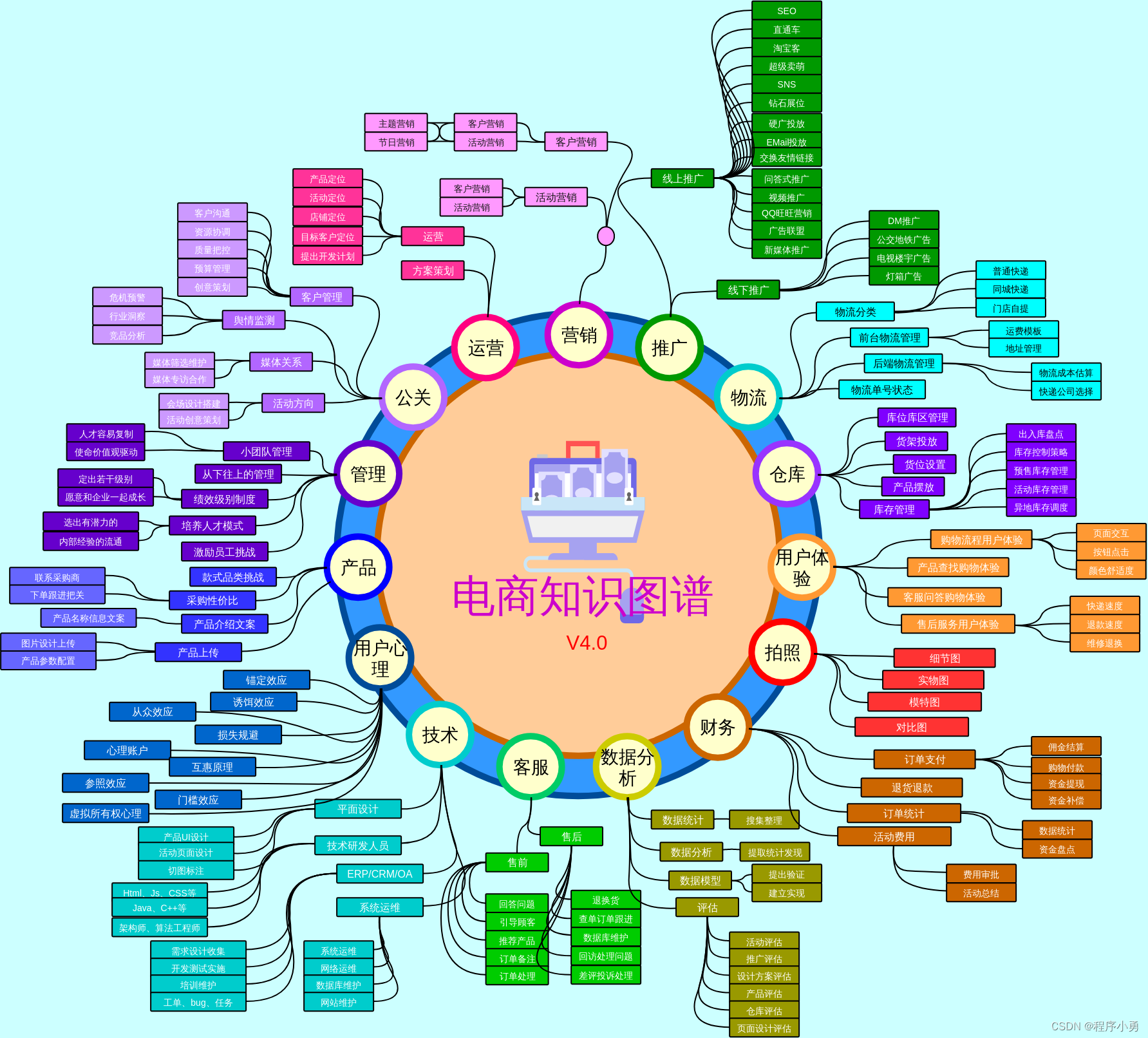
随着大型语言模型(LLM)的发展,人工智能世界取得了巨大的飞跃。经过大量数据的训练,LLM可以发现语言模式和关系,使人工智能工具能够生成更准确、与上下文相关的响应。
但LLM也给人工智能工程师带来了新的挑战,从LLM基准测试到监控。工程师可以求助的最佳选择之一是检索增强生成(RAG)。 RAG 系统通过检索和总结 LLM 最初未接受过培训的上下文相关信息来增强(即增强)LLM 表现。
这很重要,因为培训使LLM具备世界知识、一些常识和来自互联网文档的一般信息。LLM的一个经典应用是聊天机器人或更高级的对话式人工智能助手,它们可以响应有关特定领域信息的查询,而不会出现幻觉(创造不正确或与上下文无关的答案)。
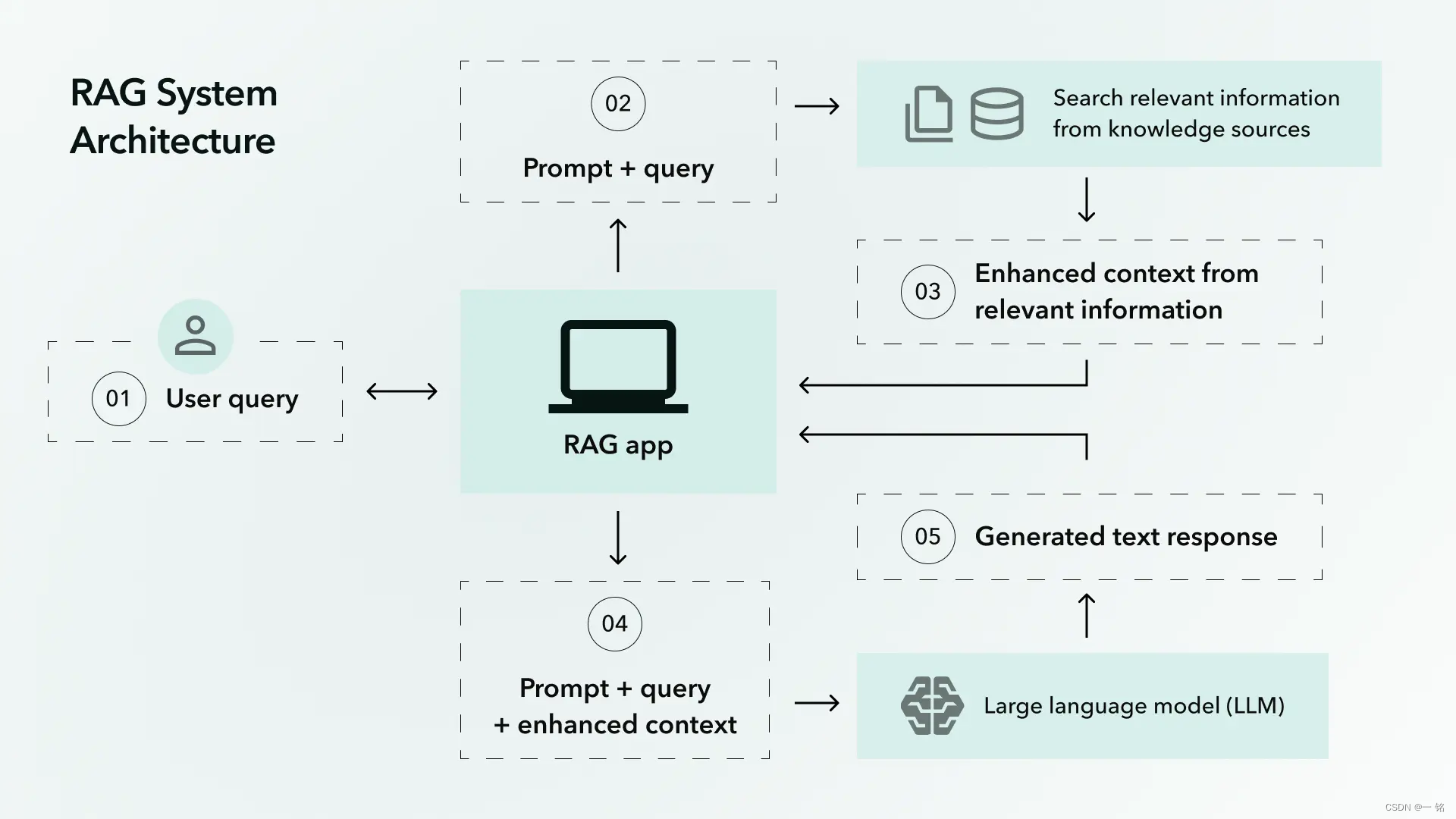
但这种训练过程有时意味着LLM无法接触到他们所需的所有信息。知识也会随着时间而改变。那么,LLM如何回答有关其尚未观察到的不断变化的信息的问题呢?在这些情况下,我们如何减少人工智能产生幻觉的可能性?
这些都是 RAG 帮助我们解决的困境。
什么是检索增强生成(Retrieval Augmented Generation)?
检索增强生成(RAG)是一种生成式人工智能方法,通过将世界知识与定制或私人知识相结合来提高LLM的表现。这些知识集正式分别称为参数记忆和非参数记忆[1]。 RAG 中知识集的这种组合很有帮助,原因如下:
- 向LLM提供最新数据:LLM培训数据有时不完整。随着时间的推移,它也可能变得过时。 RAG 允许添加新的和/或更新的知识,而无需从头开始重新培训LLM。
- 防止人工智能幻觉:LLM掌握的上下文信息越准确和相关,他们编造事实或断章取义的可能性就越小。
- 维护动态知识库:可以随时更新、添加、删除或修改自定义文档,从而使 RAG 系统保持最新状态,而无需重新培训。
了解了 RAG 的用途后,让我们更深入地了解 RAG 系统的实际工作原理。
RAG 系统的关键组件及其功能
RAG系统通常由两层组成:
- 由嵌入模型和向量存储组成的语义搜索层
- 由 LLM 及其相关提示组成的生成层(也称为查询层)
这些层帮助 LMM 检索相关信息并生成最有价值的答案。
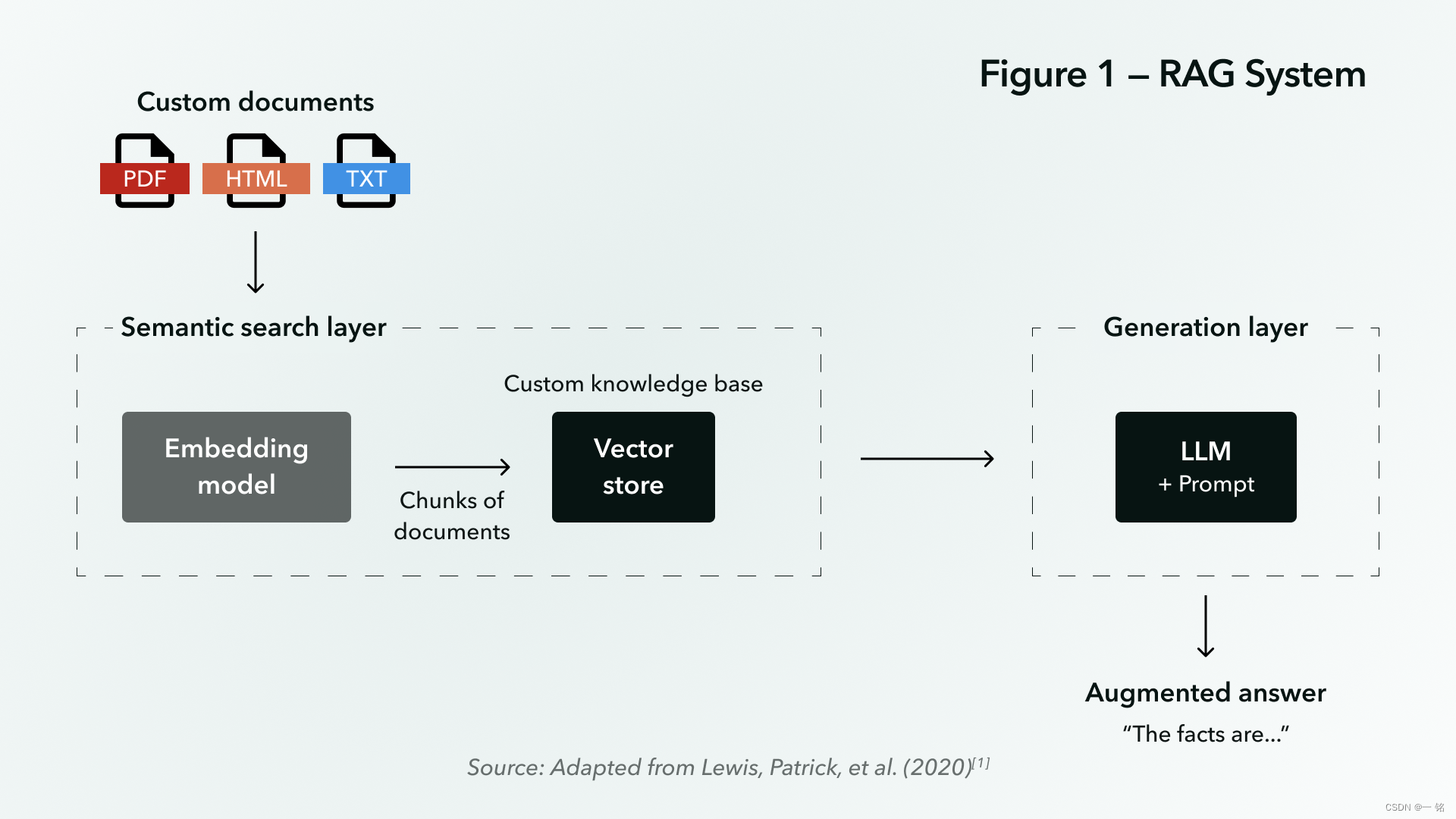
图 1 显示了 RAG 系统如何将新信息分层到LLM已知的世界知识中。要查看 RAG 应用于实际用例的示例,请查看我们如何为金融服务公司构建安全的 AI 助手。
语义搜索层
语义搜索层包含两个关键组件:嵌入模型和向量存储或数据库。这些组件共同使语义搜索层能够:
- 通过收集自定义或专有文档(例如 PDF、文本文件、Word 文档、语音转录等)来构建知识库。
- 阅读这些文档并将其分割成较小的部分,通常称为“块”。
- 将块转换为嵌入向量,并将向量与原始块文本一起存储在向量数据库中。
值得研究一下嵌入模型和向量存储如何使语义搜索成为可能。通过理解查询的意图和上下文含义(即语义)而不是仅仅寻找字面关键字匹配来丰富搜索。
嵌入模型(Embedding model )
嵌入模型负责对文本进行编码。他们将文本投影为相当于原始文本语义的数字表示形式[2],如图 2 所示。例如,句子“嗨,你好吗?”可以表示为 N 维的数值(嵌入)向量 [0.12, 0.2, 2.85, 1.33, 0.01, ..., -0.42]。
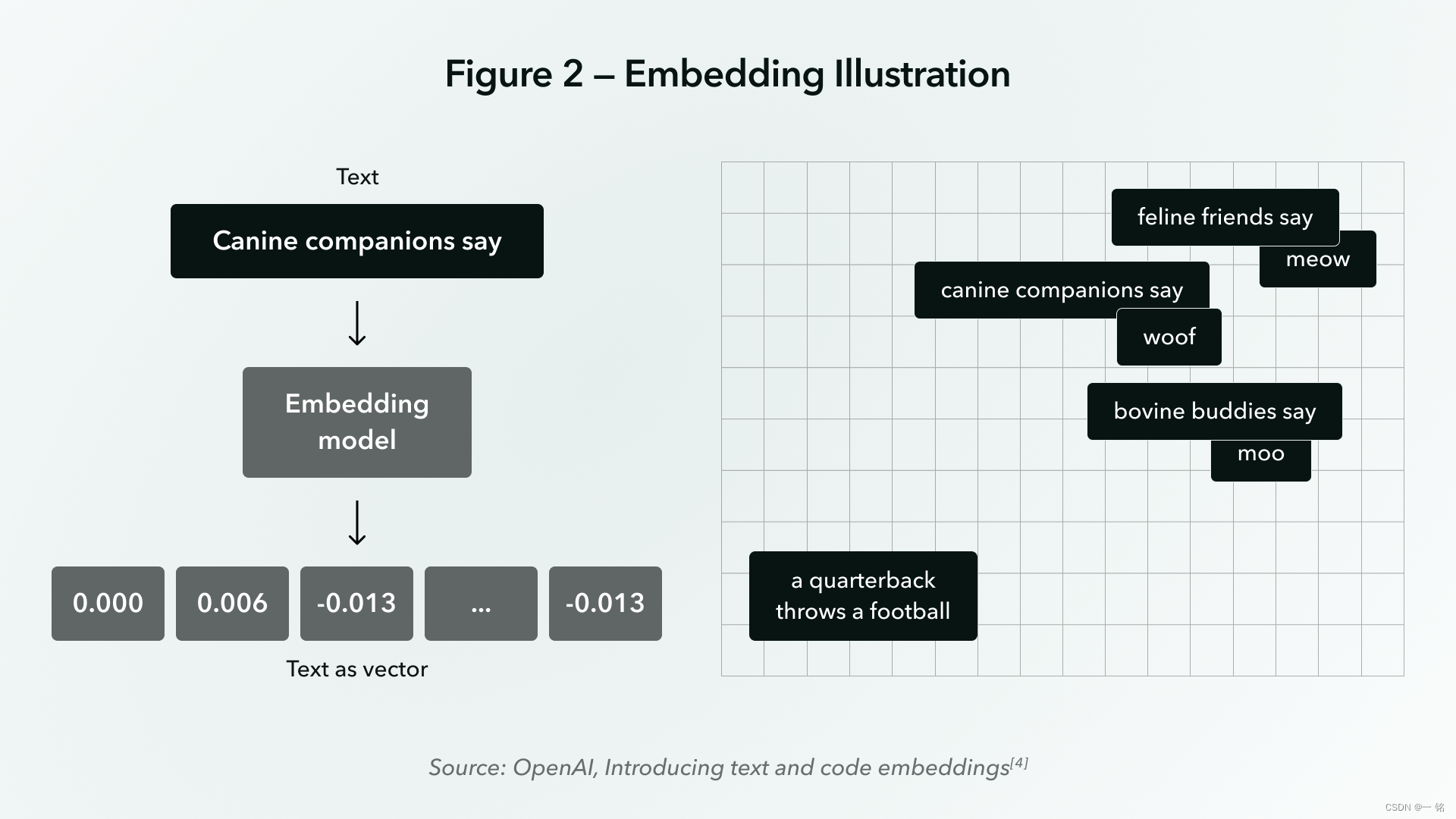
这说明了关于嵌入的一个关键要点:表示具有相似含义的文本的嵌入向量倾向于在 N 维嵌入空间内聚集在一起。
嵌入模型的一些示例包括 OpenAI 的 text-embedding-ada-002、Jina AI 的 jina-embeddings-v2 和 SentenceTransformers 的多 QA 模型。
向量存储
向量存储是用于处理高维数据表示的专用数据库。它们具有针对向量的高效检索而优化的特定索引结构。
开源向量存储的一些例子包括 Facebook 的 FAISS、Chroma DB,甚至带有 pgvector 扩展的 PostgreSQL。向量存储可以位于内存中、磁盘上,甚至可以完全托管,例如 Pinecone 和 Weaviate。
生成层
生成层由LLM及其相关提示组成。生成层将用户查询(文本)作为输入并执行以下操作:
- 执行语义搜索以查找与查询最相关的信息。
- 将最相关的文本块与用户的查询一起插入到 LLM 提示中,并调用 LLM 为用户生成响应。
以下是对 LLM 和提示如何与 RAG 系统交互的更深入的了解。
LLM(大模型)
大型语言模型建立在 Transformer 架构之上,它使用注意力机制技术来帮助模型决定在句子或文本中增加或减少注意力。LLM接受来自公共来源(主要在互联网上)的大量数据的培训。
LLM在 RAG 系统中变得更加聪明,能够根据通过语义搜索检索到的上下文生成改进的答案。现在,LLM可以更改其答案,以更好地符合每个查询的意图和含义。
托管LLM的一些例子包括 OpenAI 的 ChatGPT、Google 的 Bard 和 Perplexity AI 的 Perplexity。一些 LLM 可用于自我管理的场景,例如 Meta 的 Llama 2、TII 的 Falcon、Mistral 的 Mistral AI 和 Databricks 的 Dolly。
提示(Prompt)
提示是提供给LLM的文本输入,LLM通过定制、增强或强化其功能来有效地对其进行编程[3]。使用 RAG 系统,提示包含用户的查询以及从语义搜索层检索的相关上下文信息,模型可以使用这些信息来回答查询。
“You are a helpful assistant, here is a users query: ``` ${query}```. Here is some relevant data to answer the user’s question: ``` ${context}```. Please answer the user’s query concisely."
上图显示了通过考虑从语义搜索层检索的上下文来回答查询的朴素提示的示例。
其中context是从向量数据库中获取到的相关知识。
考虑 RAG 时需要了解的基本事项
除了 RAG 的实际和理论应用之外,人工智能从业者还应该意识到随之而来的持续监控和优化承诺。
RAG评估
应在 RAG 系统发生变化时对其进行评估,以确保行为和质量不断改进,而不是随着时间的推移而降低。 RAG 系统还应该进行红队评估,以评估其在遇到越狱提示或其他恶意或低质量输入时的行为。
RAG 知识的质量和数量
RAG 系统与知识数据库中可用的内容一样好。此外,即使知识数据库具有正确的信息,如果语义搜索没有检索到它或在搜索结果中将其排名足够高,LLM将看不到该信息,并且可能会做出不满意的反应。
此外,如果检索到的内容信息密度低,或者完全不相关,那么LLM的回应也会令人不满意。在这种情况下,使用具有更大上下文窗口的模型是很诱人的,以便可以向LLM提供更多语义搜索结果。但这需要权衡——即增加成本以及用不相关信息稀释相关信息的风险——这可能会“混淆”模型。
RAG成本
由于如今嵌入模型的成本通常微不足道,因此 RAG 的主要成本来自矢量数据库托管和 LLM 推理。 RAG 系统中 LLM 推理成本的最大驱动因素可能是插入提示中的语义搜索结果的数量。具有更多语义搜索结果的更重要的LLM提示可能会产生更高质量的响应。尽管如此,它也会导致更多的令牌使用和可能更严重的响应延迟。
然而,包含更多信息的更大提示并不一定能保证更好的响应。对于每个系统,插入到提示中的最佳结果数量都不同,并且受到块大小、块信息密度、数据库中信息重复程度、用户查询范围等因素的影响。评估驱动的开发方法可能是确定系统最佳流程的最佳方法。
RAG 适合您的生成式 AI 应用吗?
检索增强生成系统标志着人工智能的重大进步,通过减少幻觉并确保知识库信息是最新的、准确的和相关的来提高LLM的表现。平衡信息检索与成本和延迟,同时维护高质量的知识数据库对于有效使用至关重要。未来的进步,包括假设文档嵌入 (HyDE) 等技术,有望进一步改进 RAG 系统。
尽管成本高昂,但 RAG 无可否认地改善了用户交互,为客户和员工创造了更具粘性、更令人愉悦的生成式 AI 体验。
参考
[1] Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
[2] Neelakantan, Arvind, et al. "Text and code embeddings by contrastive pre-training." arXiv preprint arXiv:2201.10005 (2022).
[3] White, Jules, et al. "A prompt pattern catalog to enhance prompt engineering with chatgpt." arXiv preprint arXiv:2302.11382 (2023).
[4] Introducing text and code embeddings [WWW Document], OpenAI. URL Introducing text and code embeddings
[5] 原文链接:RAG: How Retrieval Augmented Generation Systems Work